@77qingliu
2018-05-16T13:31:45.000000Z
字数 1670
阅读 2107
变量选择的方法
信用评分
信贷发放机构的分析人员能够获得大量的可以用于建立信用评分卡的变量。因此,选择模型中,也就是评分卡中使用的变量,不仅是一项分析任务,还与业务流程和评分卡的实施过程密切相关。
从分析的角度,模型中使用的变量迭代选择方法有许多种,这些方法的基本原理都是用模型和变量的统计量判断模型中包含和不包含每个变量时的模型质量。
选择方法概述
所有变量选择算法的基本原理都是在模型中增加或者从模型中移出变量,知道发现最优模型。
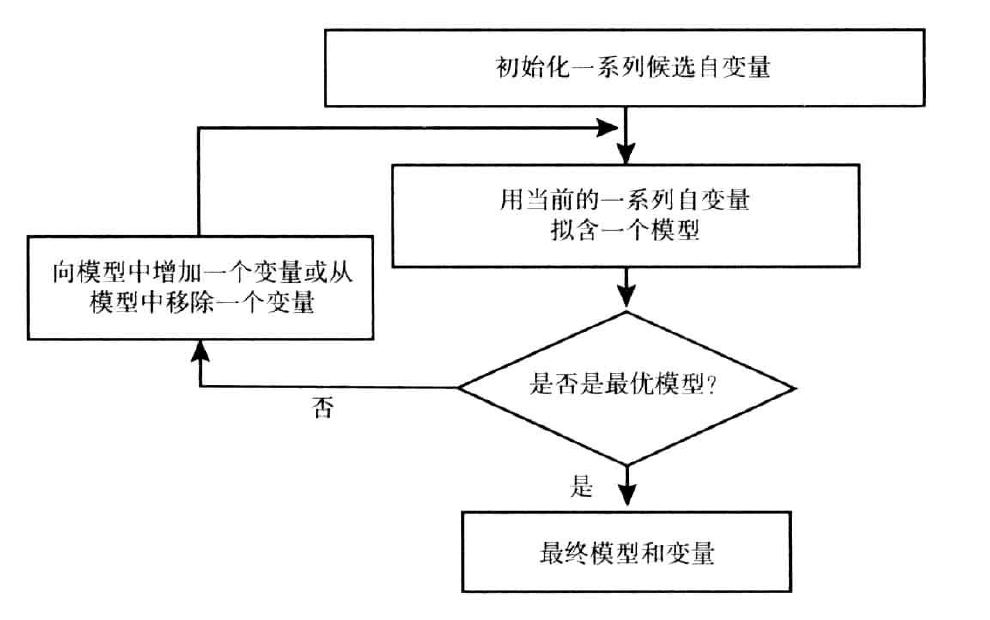
proc logistic提供了五种变量选择的方法,这些方法可以通过指定选项selection的值在model语句中调用。
- 使用所有变量:
selection = NONE,这些拟合模型的最简单,也是默认的方法,它将model语句中列出的所有变量都纳入模型。 正向选择:
selection = FORWARD,这种方法通过几个步骤得到模型。- 只用一个截距项对模型进行拟合
- 接下来,在每一步中,检验没有纳入模型的变量并选择卡方统计量最大、符合条件的变量,这个条件可以通过选项
SLE确定,SLE的值指定允许一个变量进入模型的最大p值。
正向选择的有点在于其只允许显著变量进入模型。然而,一旦某个变量在某个阶段被纳入模型,在接下来的某个阶段,即使其显著性降低也仍会保留在模型中。
- 逆向选择:
selection = BACKWARD,可以看作是正向选择的逆。先对所有自变量进行拟合,然后每一步中移除中Wald卡方统计量的p值最大的量,如果其大于选项SLE设定的值。
逆向选择法的优点在于,给所有变量一个被纳入模型的机会。但如果某个变量一旦被移除,即使其在接下来的某个阶段变得显著,也不会有第二次机会被纳入模型。 - 逐步选择:
selection = STEPWISE,每一步都是正向选择和逆向选择的结合。最初,模型只有截距项,然后在每一步中,用正向选择增加最优的变量,用逆向选择移除最差的变量。选择SLE和SLS的值来分别被用来控制纳入或移除模型的变量的p值。
这是评分卡开发中最常用的方法,因为它同时结合了正向选择和逆向选择的优点。它既给了每个变量被纳入模型的机会,即使其在早期阶段就被移除模型;又允许在前期阶段被纳入模型的显著变量被移出模型。
需要注意的是,逐步选择法并不能保证一定会获得最优模型。 - 最优得分统计模型:
selection = SCORE,与逐步选择发有些相似,他们都是经过多个步骤反复增加或移除变量以改进模型。然而,它使用著名的分支定界算法以找出使得模型的分数统计量(SC)最高变量的子集。
除了上述选择方法,proc logistic还提供了下列选项,允许在上述方法中进一步对变量选择进行控制:
SEQUENTIAL——强制算法按照model语句设定的顺序考虑变量,无论是将变量纳入还是移除模型。START=n——强制模型从MODEL语句列出的前n个变量开始STOP=n——规定最终模型中包含的最大(对于正向选择)或最小(对于逆向选择)变量数INCLUDE=n——强制将前n个变量包含在所有模型中。该选择与START选择的区别在于,INCLUDE=N强制将n个变量包含在所有模型中;而START=N仅仅是从包含前n个变量的模型开始整个过程,某些变量可能在后续阶段被移除。
由于不同变量选择方法控制选择的特殊功能,所以有些在特定的选择方法中无效。下表总结了MODEL语句中使用的方法:

逐步变量选择
逐步选择发是评分卡模型开发中最常用的变量选择方法。与其他变量选择方法相比,它有两项明显的优势。
- 它允许模型中的每个变量在任意一步中被纳入。
- 它用参数估计的
Wald卡方显著性决定哪个变量将被保留在模型中,因此,最终模型中的所有变量都是显著的。
通过将selection的值设定为STEPWISE,就可以在model语句中调用逐步选择法。选项SLE=P和SLS=P分别设定了允许变量进入和保留在模型中的显著性水平。例如,设定SLE=0.05,将允许Wald卡方的p值等于或小于0.05的变量进入模型。
信用评分卡开发的最优实践建议用于设定参数SLE和SLS的显著性水平的值如下:

