@77qingliu
2018-05-23T00:07:31.000000Z
字数 4842
阅读 1364
EDA和数据描述
信用评分
EDA包括对以下部分的探索:
- 每个候选变量的统计特征和分布
- 变量之间的相关性
- 检查缺失值和极端值
- 调查预测变量中的违约和正常情况
单变量统计
大多数统计量可以用proc univariate计算,这些统计量可以分为一下5组:
- 矩,如均值、众数和标准差
- 位置和变化率的基本统计指标
- 均值位置的检验
- 分位数,如第一、第三分位数
- 极端值,包括极大和极小值
下面例子计算这些基本统计量
data Test1;input x @@;datalines;1.45 0.73 2.43 3.89 3.86 3.96 2.41 2.292.23 2.19 0.37 2.71 0.77 0.83 3.61 1.711.06 3.23 0.68 3.15 1.83 3.37 1.60 1.173.87 2.36 1.84 1.64 3.97 2.23 2.21 1.93;run;/*******************************************************//* Use proc univariate to analyze the variable x *//*******************************************************/proc univariate data=Test1 mu0=2.2 loccount;var x;run;
输出结果为:
- 平均值,众数等等

- 位置和变化率

- 均值检验

- 分位数

- 极端值

变量分布
除了进行单变量统计分析,对潜在变量的分布的检查也能揭示出有趣的特征。通常,直方图用来绘制连续变量的分布图,而饼图和条形图则用于名义变量和顺序变量
这里用宏%EqWBinn将连续变量分为等宽的区间,然后用PROC CHART计算并绘制直方图
宏的参数如下:

分段并绘图
data Test1;input x @@;datalines;1.45 0.73 2.43 3.89 3.86 3.96 2.41 2.292.23 2.19 0.37 2.71 0.77 0.83 3.61 1.711.06 3.23 0.68 3.15 1.83 3.37 1.60 1.173.87 2.36 1.84 1.64 3.97 2.23 2.21 1.93;run;/* Call the macro */%let DSin=Test1;%let DSout=Test1b;%let XVar=x;%let Nb=5;%let XBvar=x_b;%let DSMap=test1map;%EqWBinn(&DSin, &XVar, &Nb, &XBvar, &DSout, &DSMap);/* Print the binning map dataset to the output window */proc print data=test1map;run;/* Plot the histogram data */proc chart data=test1b;vbar x_b;run;
输出直方图

特征分析
所谓特征分析是指评分卡开发过程中对变量进行广泛分析。这种分析包括对连续变量的分段并对每段中正常和违约的分布进行检查。
特征分析的目的是揭示违约率和预测变量之间的关联。
分段方法通常有两种:
- 每段中都包含等量的观测
- 等宽分段
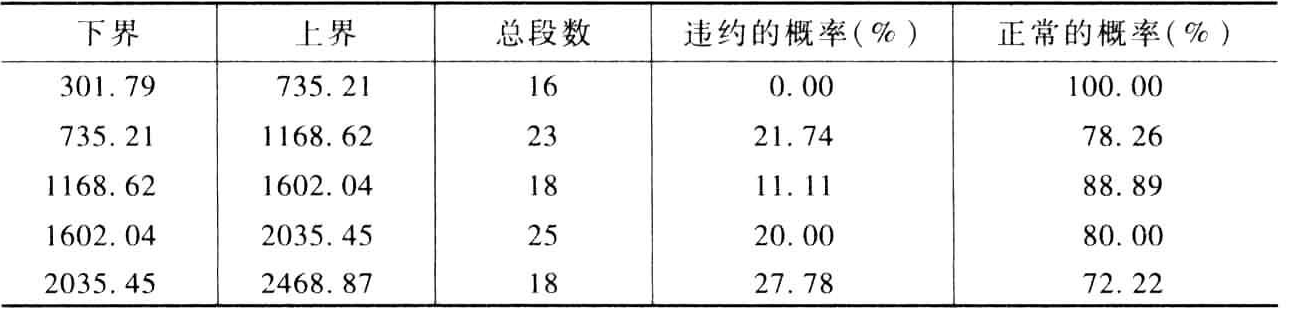
宏ChcAnalysis可以执行上述两种分段,并计算状态类别变量的分布。下表描述宏的参数:

程序
data Customers;input Status Income @@;datalines;0 1923.78 0 754.04 0 934.12 1 830.36 0 1749.90 1903.87 0 1835.18 1 2419.84 0 771.56 0 1945.690 1475.22 1 1117.34 0 1537.49 1 1141.03 0 733.040 870.65 0 2088.48 0 590.5 0 1509.77 1 1843.160 1380.64 0 662.58 0 301.79 0 1627.66 0 603.680 1022.61 0 2240.7 0 1401.81 1 1797.92 0 1933.540 2046.81 0 2204.92 0 1022.64 0 1411.42 1 1449.860 1615.16 0 1517.89 0 1812.05 0 1172.78 0 2296.671 865.35 0 310.7 0 1524.75 0 1039.29 0 596.350 1680.61 0 2104.21 0 1103.94 0 2239.71 0 1889.270 1007.24 1 1586.02 0 565.35 0 1720.2 1 2398.760 482.73 0 2247.51 0 1555.7 1 1869.64 0 724.540 621.16 0 356.17 0 1663.88 0 955.77 0 2024.460 822.99 0 554.11 0 1867.84 1 2468.87 0 893.190 630.12 0 1876.82 0 1436.33 0 1832.13 0 1157.210 1690.42 0 2141.84 1 1932.7 0 2298.38 0 1293.890 1035.24 0 981.24 0 2163.58 0 675.95 0 1216.150 2220.74 1 2153.51 0 901.71 1 1122.39 0 1801.040 1003.79 0 1510.24 0 898.5 0 1537.91 1 1635.870 1826.32 0 1247.07 0 2078.9 1 2310.28 0 456.06;run;/* Call the macro */%let DSin=Customers;%let DVVar=Status;%let VarX=Income;%let NBins=5;%let Method=2;%let DSChc=Income_chc;%ChcAnalysis(&DSin, &DVVar, &VarX, &NBins, &Method, &DSChc);/* Print the cresults dataset to the output window */proc print data=Income_chc;run;
输出
列联表
列联表就是2个或以上变量建立的频率表。SAS里面用proc freq和proc tabulate可以快速实现。
下面用两个实例展示使用方法
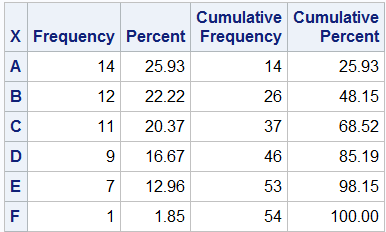
对单个变量计算频率
程序
DATA Nominal1;input X $ @@;datalines;A B B A B A C A B C C D D C E E A BA B C C D E E D D E C C E C D D C AB B B B A A A A F A E C D A A B B D;run;/* Invoke PROC FREQ on the variable X */PROC FREQ DATA=Nominal1;TABLES x;run;
输出
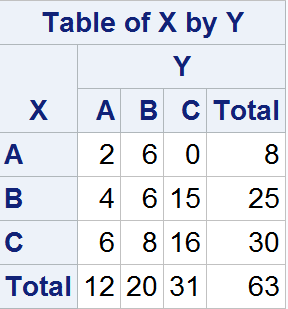
对两个分类变量进行交叉制表
程序DATA Nominal2;input X $ Y $ @@;datalines;A B B A B A C A B C C C C C B B A BA B C C C B B C C B C C B C C C C AB B C C B C C B C C C C C B B C C BC C B C C A B C C C C C B B A B B CC B C C B C C A B C C C B B B A B CB B B B A A A A B A B C C A A B B CA B C C C B B C C B C C B C C C C A;run;/* Cross tabulation of X by Y */PROC FREQ DATA=Nominal2;TABLES X * Y / NOPERCENT NOROW NOCOL;run;
其中
NOPERCENT NOROW NOCOL分别指定忽略总百分比,每行合计数,每例合计数输出
极端值识别
信用评分开发过程中有两个隐含的假设:
- 违约变量是预测变量的函数
- 建模数据集中使用的自变量由一个过程生成,该过程可以表现为一个单一的分布。
而来源于这个过程之外的观测值为极端值
极端值通常有两个来源:
- 与大多数数据之间存在很大差异的观测值
- 数据差错
大多数情况下,被认定为极端值的观测或被删除,或者将其取值重置为总体中看起来更为典型的某个值。然而,当极端值占比很大时,比如超过10%,需要考虑将总体分群(segments),并针对每个群开发评分卡。
识别极端值的常用方法分为一下四类:
- 为每个变量设定一个正常的取值范围,例如均值±3倍标准差
- 假设生成数据建立在特定的函数形式上,如线性模型,可以用已知数据拟合该模型,严重偏离模型的观测被视为极端值
- 用聚类算法将数据分为较小的子集,只包含较小数量的观测,被视为极端值
- 依靠决策树发现包含少量观测值的持续结点
下面示例展示识别极端值的方法
根据取值范围识别极端值
如果一个变量服从正态分布,则99.7%的观测在均值的±3倍标准差之间。可以尝试通过这个寻找离群值。
宏%Extremes输出超出均值±3倍标准差的观测,宏的参数如下图:

程序
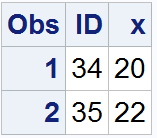
data Test1;input ID x @@;datalines;1 1.45 2 0.73 3 2.43 4 3.89 5 3.866 3.96 7 2.41 8 2.29 9 2.23 10 2.1911 0.37 12 2.71 13 0.77 14 0.83 15 3.6116 1.71 17 1.06 18 3.23 19 0.68 20 3.1521 1.83 22 3.37 23 1.60 24 1.17 25 3.8726 2.36 27 1.84 28 1.64 29 3.97 30 2.2331 2.21 32 1.93 33 19.0 34 20.0 35 22.0;run;/* Identifying outliers using the mean and threestandard deviations */%Extremes(Test1, x, ID, 3, Test1_out1);/* Print the cresults dataset to the output window */proc print data=test1_out1;run;
输出
使用聚类识别极端值
聚类法中最常用的是K-means算法。K-means算法可以通过proc fastclus实现。宏ClustOL用proc fastclus创建总计NClust簇,找出低频率的簇,并将他们的观测值标记为极端值。宏的参数如下:
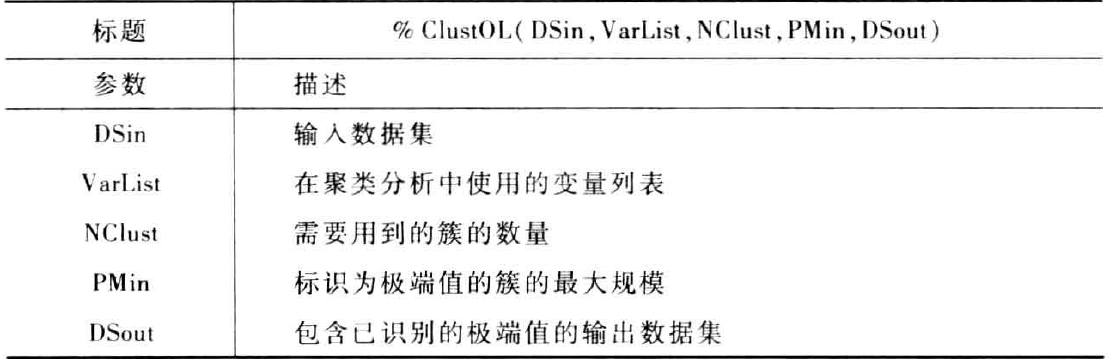
程序
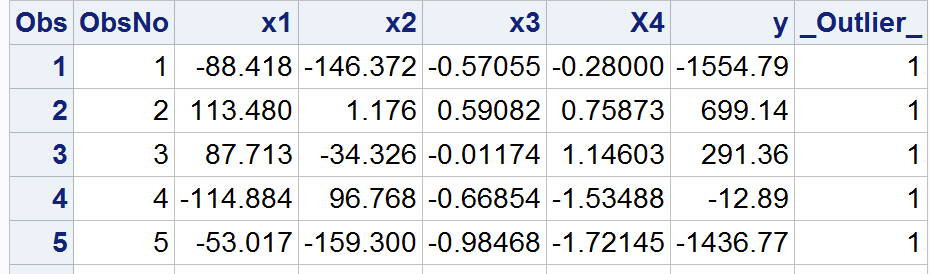
/* Generate a dataset */data TestOL ;/* Create 1000 observations from three distributions */do ObsNo=1 to 1000;/* Generate four varibles x1-X4*/x1=rannor(0); x2=rannor(0);x3=rannor(0); X4=rannor(0);/* In the first 50 observations, inflate x1, x2 variables 100 times */if ObsNo <= 50 then do;x1=100 * rannor(0);x2=100 * rannor(0);end;/* Create a dependent variable y */y= 5 + 6*x1 + 7*x2 + 8*x3 + .4 * X4;/* The last 50 observations y=100 */if ObsNo > 950 then y=100;output;end;run;/* Call the macro */%let DSin=TestOL;%let VarList=x1 x2 x3 y;%let NClust=50;%let Pmin=0.05;%let DSout=OL_CLusters;%ClustOL(&DSin, &VarList, &NClust, &Pmin, &DSout);/* Sort the data by ObsNo to restore original order */proc sort data=&DSout;by ObsNo;run;data outliers;set OL_clusters;if _Outlier_;run;proc print data=outliers;run;
输出
多级识别极端值
上面两种方法都可以识别极端值。在尝试找出极端值的过程中,同时使用多种方法是很常见的做法。例如,首先采用基于取值范围的方法,然后在多元变量中使用聚类的方法。
极端值的处理
处理极端值的最常用方法是用特定的值替代他们,只有在用单变量法识别极端值时,这些方法才能使用。对不同的变量类型,有不同的替代方法,常用的方法如下:
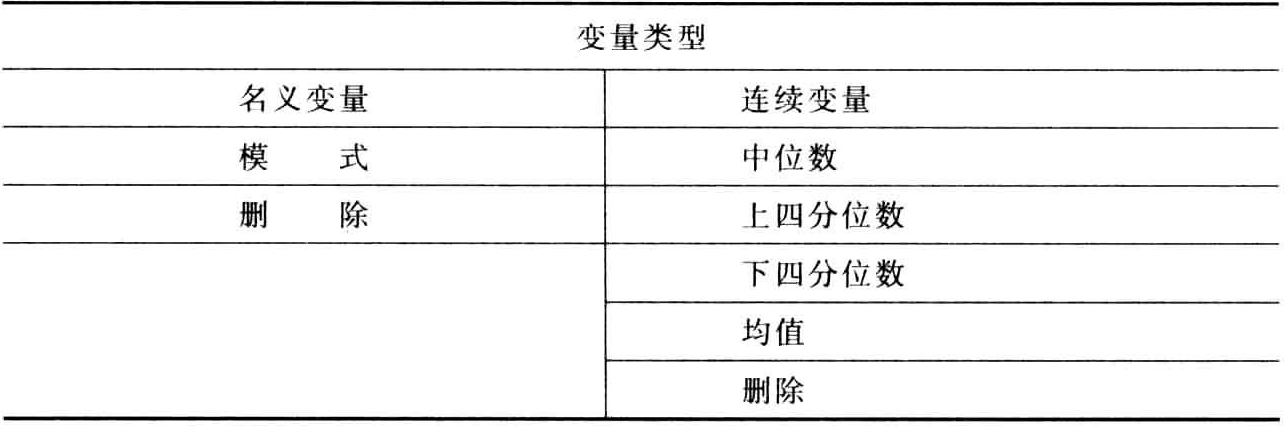
另外一种办法是将极端值转变成缺失值。
除了以上方法,还可用一些特定的统计量替代极端值。
