@1234567890
2017-05-22T13:22:28.000000Z
字数 1899
阅读 1938
Lucene索引实现
索引 ES
Lucene的索引不是B+Tree组织的,而是倒排索引,Lucene的倒排索引由Term index,Team Dictionary和Posting List组成。

有倒排索引(invertedindex)就有正排索引(forwardindex),正排索引就是文档(Document)和它的字段Fields正向对应的关系:
| DocID | name | sex | age |
|---|---|---|---|
| jack | 男 | 18 | 2 |
| lucy | 女 | 17 | 3 |
| peter | 男17 |
倒排索引是字段Field和拥有这个Field的文档对应的关系:
Sex字段:
| 性别 | 文档 |
|---|---|
| 男 | [1,3] |
| 女 | [2] |
Age字段:
| 年龄 | 文档 |
|---|---|
| 18 | [1] |
| 17 | [2,3] |
Jack,lucy或者17,18这些叫做term,而[1,3]就是posting list。Posting list就是一个int型的数组,存储了所有符合某个term的文档id。那么什么是Term index和Term dictionary?
如上,假设name字段有很多个term,比如:Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的term一定很慢,因为term没有排序,需要全部过滤一遍才能找出特定的term。排序之后就变成了:Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样就可以用二分查找的方式,比全遍历更快地找出目标的term。如何组织这些term的方式就是 Term dictionary,意思就是term的字典。有了Term dictionary之后,就可以用比较少的比较次数和磁盘读次数查找目标。但是磁盘的随机读操作仍然是非常昂贵的,所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个Term dictionary本身又太大了,无法完整地放到内存里。于是就有了Term index。Term index有点像一本字典的大的章节表。比如:
A开头的term ……………. Xxx页
C开头的term ……………. Xxx页
E开头的term ……………. Xxx页
如果所有的term都是英文字符的话,可能这个term index就真的是26个英文字符表构成的了。但是实际的情况是,term未必都是英文字符,term可以是任意的byte数组。而且26个英文字符也未必是每一个字符都有均等的term,比如x字符开头的term可能一个都没有,而s开头的term又特别多。实际的term index是一棵trie 树:

上图例子是一个包含 "A", "to", "tea", "ted", "ten", "i", "in", 和 "inn" 的trie树。这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(想了解更多,搜索 Lucene Finite State Transducers),Term index的尺寸可以只有所有term的尺寸的几十分之一,使得用内存缓存整个term index变成可能。整体上来说就是这样的效果:
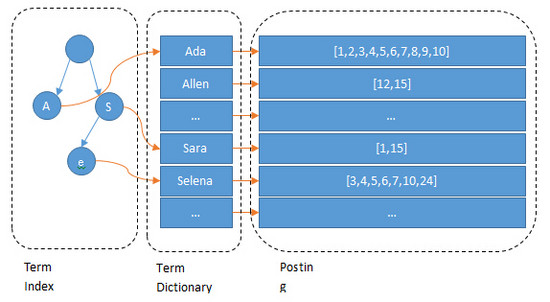
由Term index到Term Dictionary,再到Posting List,通过某个字段的关键字去查询结果的过程就比较清楚了,通过多个关键字的Posting List进行AND或者OR进行交集或者并集的查询也简单了。
对比MySQL的B+Tree索引原理,可以发现:
Lucene的Term index和Term Dictionary其实对应的就是MySQL的B+Tree的功能,为关键字key提供索引。Lucene的inverted index可以比MySQL的b-tree检索更快。
Term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。所以Lucene搜索一个关键字key的速度是非常快的,而MySQL的B+Tree需要读磁盘比较。
Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样Term dictionary可以比B-tree更节约磁盘空间。
Lucene对不同的数据类型采用了不同的索引方式,上面分析是针对field为字符串的,比如针对int,有TrieIntField类型,针对经纬度,就可以用GeoHash编码。
在 Mysql中给两个字段独立建立的索引无法联合起来使用,必须对联合查询的场景建立复合索引,而Lucene可以任何AND或者OR组合使用索引进行检索。
