@pluto-the-lost
2019-06-28T06:53:12.000000Z
字数 2960
阅读 215
Dual Learning
machine-learning deep-learning NLP

Problem
- Neural machine translation (NMT) needs large amount data to train
- Human labeling is costly, which leads to lack of labeled data. However, unlabeded data is enormous
- How to take advantage of these unlabeled data to train a NMT model
Inspiration
- Translation is a bi-direction task. English-to-French and French-to-English are dual tasks
- Dual tasks can form a loop and get feedback from each other
- These feedback signals can be used to train the model, without a human labeler
Introduction
1. State-of-the-art machine translation methods
- Phrase-based statistical translation
- Neural networks based translation
- both heavily rely on aligned parallel training corpora
2. Neural Machine Translation
RNN & LSTM/GRU
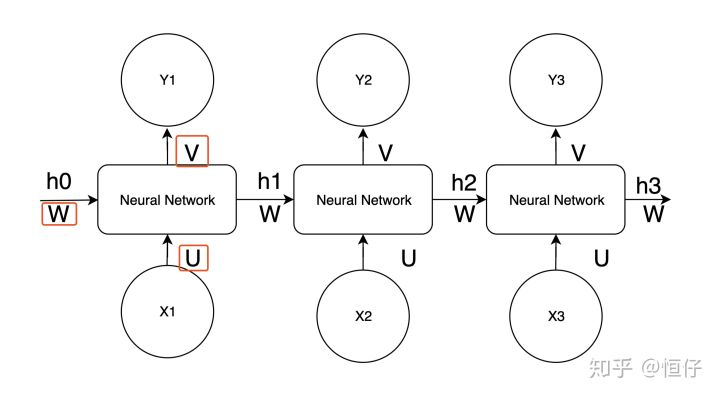
- has problem of gradient vanish/exploding
- if using LSTM, have problem when target sentence is longer then the source
Seq2Seq
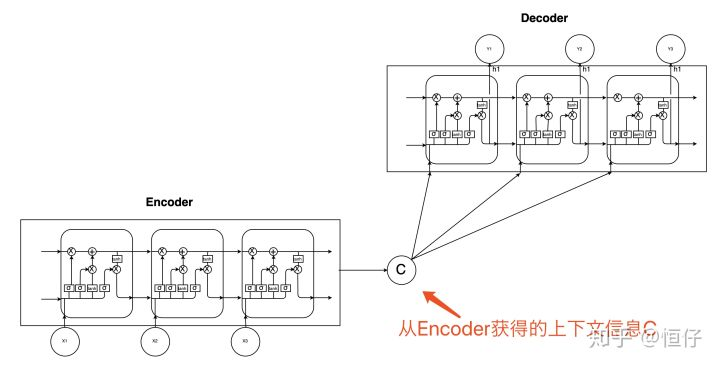
- for , it can use information before the time step
- if is all parameters in this model, there should be:
3. About corpora
- parallel data are usually limited in scale
- alomse unlimit monolingual data in the Web, which are used in two ways:
- training a language model
- is not a real address of the shortage of training data
- generating pseudo bilingual sentences, enlarging the training set
- no guarantee on the quality
- training a language model
Method

The main idea is clear: for any sentence in language A, first use translator to translate it to in language B. Then language model evaluate the quality of . Note that the evaluation is only linguistic instead of the meaning of the sentence. Then is translated back to language A, which is kind of "supervised" cause we already know the original sentence.
Here we will have two parts of reward:
- is the language model reward, rewarding the translation from A to B,
- is the communication reward, rewarding the back translation, r_1r_2$
Although it is intuitive to understand its idea, some of details in the algorithm may be unfamiliar to us:
- beam search
- we want to maximize
- however, the target sentence comes out word by word
- It is too costly to compute every combination of , and a strict greedy search will be likely to have a local maximum.
- A beam search computes the joint likelihood of all combination in each time step, but only keep candidates with the largest likelihood for search afterward. This method is less computationally expensive and more unlikely to have a local maximum.
- policy gradient
- it is not possible to gradient a sentence, since it is a discrete variable
- in Reinforcement Learning, people use policy gradient to solve these problems
- construct a loss function , where is the status in time point t, is the action that is taken in t. r(a_t,s_t) is the final reward, for example, wining or losing a board game
- it come from a simple intuition: if the result is good, the action is right, and vice versa
- in this case, is , subsequent derivation will be obvious
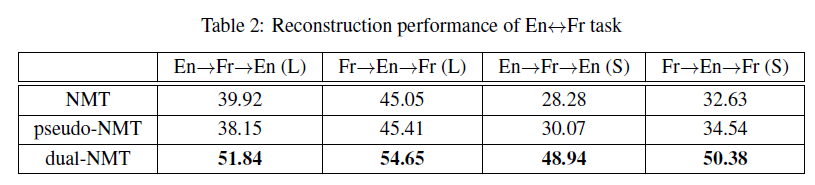
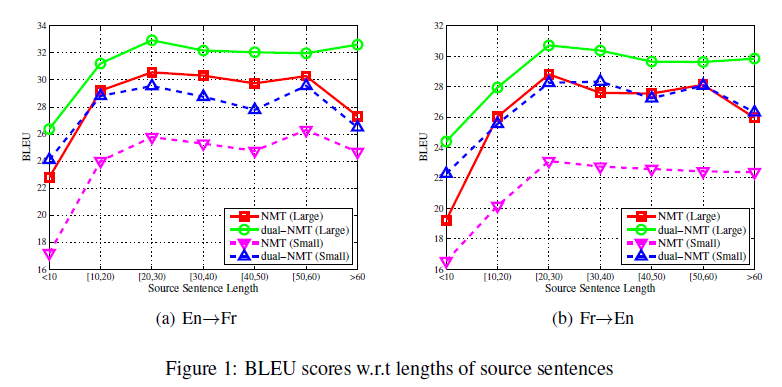
Experiment
I don't want to talk about this part, they just claimed that they are good