@jtong
2017-07-19T08:40:52.000000Z
字数 2779
阅读 4703
像机器一样思考(四)—— 一图抵千言
教学 Graphic-Language
当我们把一个完整的功能拆解为一个个输入输出穷尽,互相独立的任务后,它是容易转化为代码了,可是这种方式并不容易思考规模更大的问题(光从哪来到哪去就够我们绕的)。把我们的大脑看成一台电脑,我们就是那种内存很低的电脑,问题规模一大,我们就会死机,然后就只能重启了。具体表现为我们思考时会觉得晕。每次晕的时候可能都重启了一下:)。
怎么办呢?其实也很简单,内存不够硬盘来凑。对我们的大脑来说,最常见的“硬盘”就是纸。而正如电脑的硬盘传输速度总是不如内存的,加了硬盘计算效率不一定快。我们需要一种对传输友好的编码方式,这种方式就是画图。
画图的规则
我们的画图方法受时序图启发而发明,具体的规则如下:
- 本图基本元素由方块和带箭头的线组成
- 一个方块只代表一个函数或一个代码块,通常是函数,方块中可以写字,可以表达函数是属于哪个类或哪个实例等信息。
- 指向方块的线代表该函数的输入,背离方块的线代表函数的输出。
- 数据流动的时间轴遵守先从左到右,再从上到下的顺序。
- 每一对输入输出(输入在上,输出在下)加一个方块,表达了一次函数调用。
举例:
比如下列代码:
function c(){}function b(){c();}function a(){b();}a();
画成图是这个样子的

在这个图上我们可以清晰的看出来,函数a调用了函数b,函数b调用了函数c。而函数a自己,是在最顶层调用的,也就是所谓的程序入口。
整张图是从左往右表示时间顺序。
什么情况下既有从左到右,也有从上到下呢?比如下面这个代码:
function b(){// b codes}function c(){// c codes}function a(){b();//a codes;c();//a codes;}
函数a先调用了函数b,然后再执行一段a里面的代码,再调了函数c,然后再执行了一段a里面的代码,然后返回。
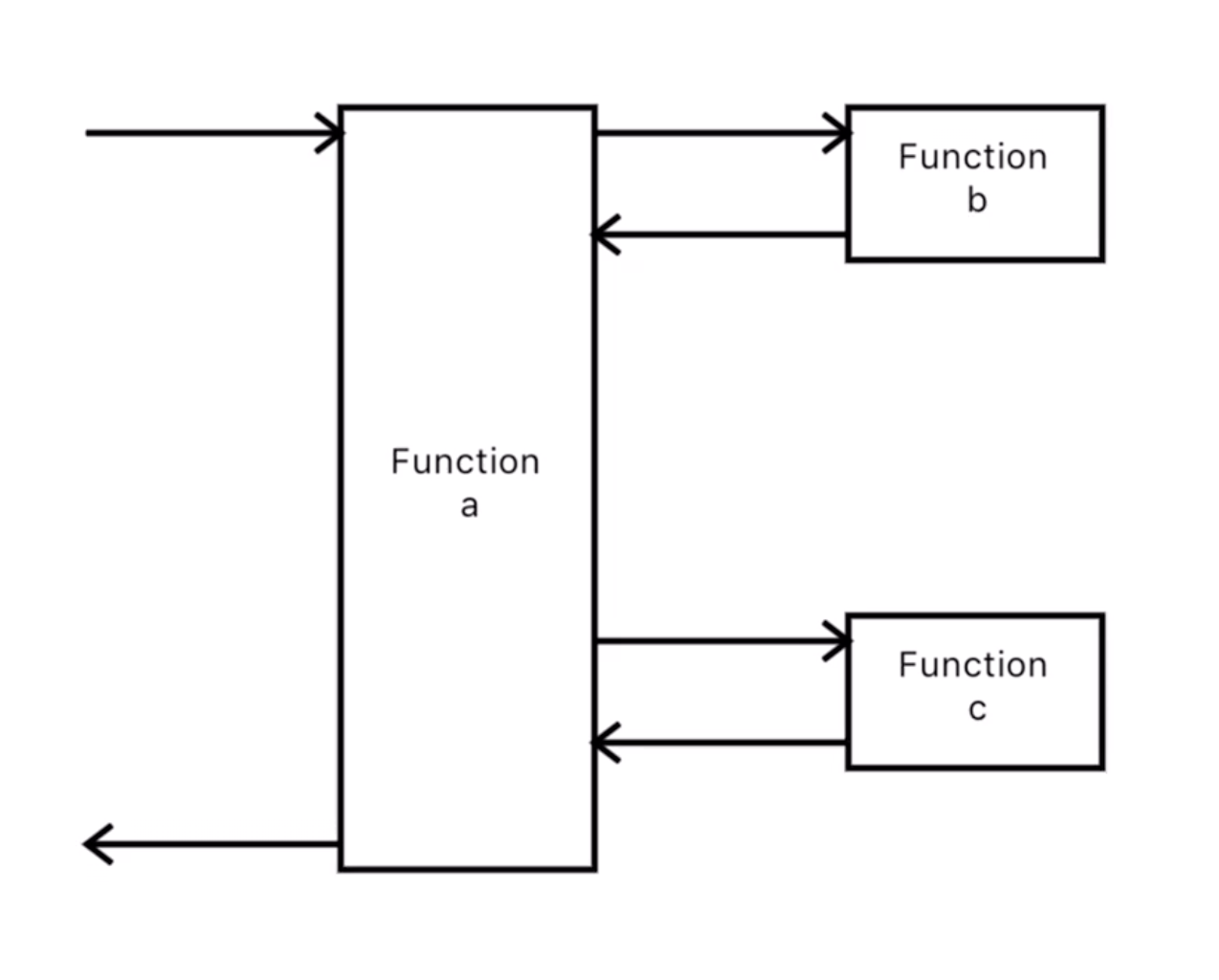
正常的使用方式
我们正常使用这个实践的时候,这个过程是反过来的,我们可能先看画出了上面这张图。不过这回,我们要画的认真一点,为了后面可以导出任务列表,我需要加上标号,如下图:
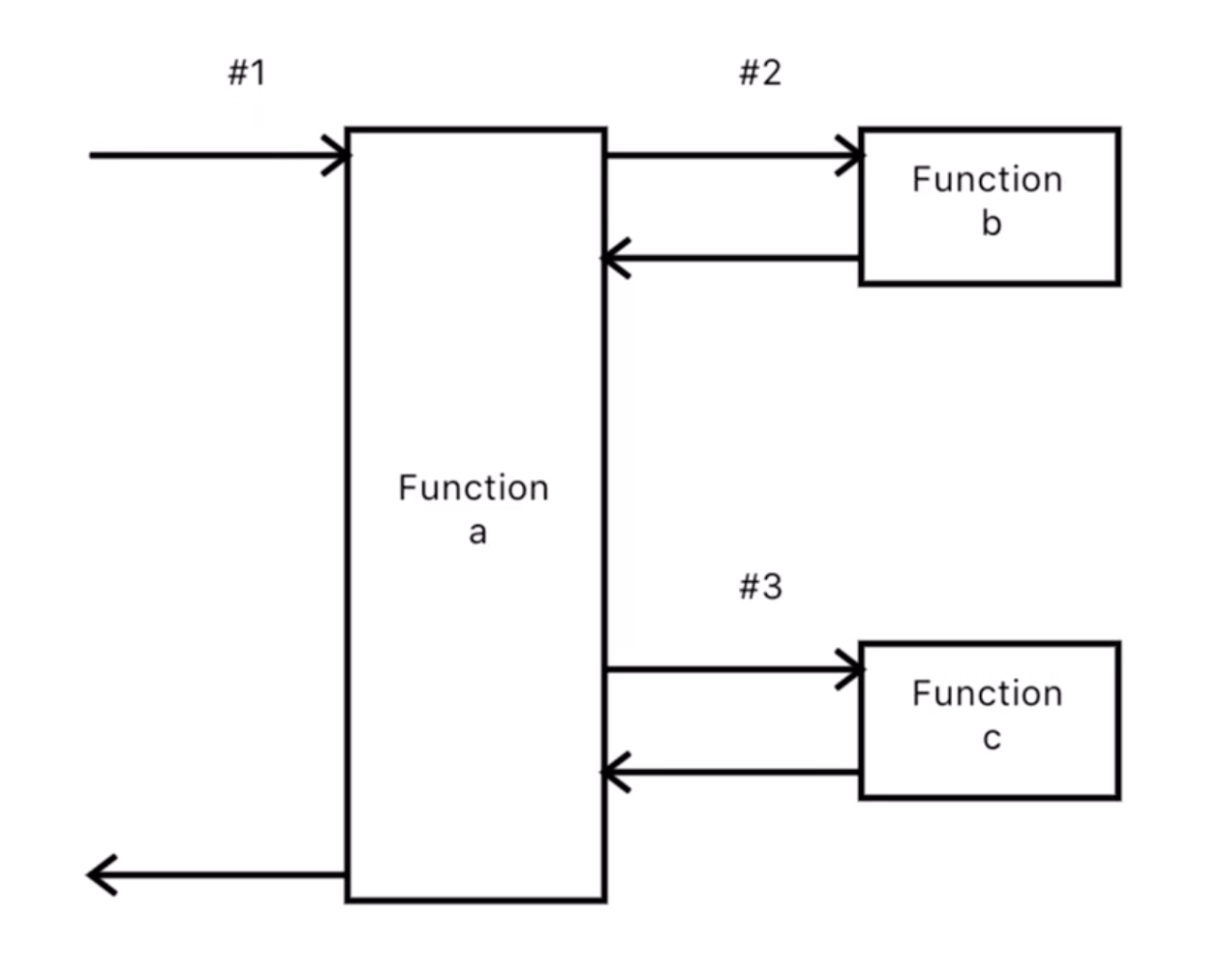
然后从这张图里按照标号导出任务列表,如下:
#1 函数a输入:paramX: TypaX输出:bValue: TypeA#2 函数b输入:paramY: TypeY输出:cValue: TypeB#3 函数c输入:paramZ: TypeZ输出:aValue: TypeC
然而这里有个问题,对于函数b和函数c来说,输入输出倒是很正确,对于函数a来说,难道函数b和函数c的返回值不是它的输入吗?相应的,函数b和函数c的参数也是它的输出。
所以真正完善的IO是这样的
#1 函数a输入:paramX: TypaXcValue: TypeB: 函数baValue: TypeC: 函数c输出:bValue: TypeAparamY: TypeY: 函数bparamZ: TypeZ: 函数c#2 函数b输入:paramY: TypeY输出:cValue: TypeB#3 函数c输入:paramZ: TypeZ输出:aValue: TypeC
写出的代码大概如下所示:
function b(){// b codesreturn result;}function c(){// c codesreturn result;}function a(){let bValue = b(paramX);//a codes;let cValue = c(paramZ);//a codes;return result;}
在在真正的工作中,函数b和函数c这样的函数是非常少的,大部分都是函数a这样既被调也调别人的函数。如果每一个都按照这样去切分,恐怕就不是一个高效的方法了,即便列出来也很乱。不但不能帮助思考,反而会阻碍思考。
当按照模块的角度去拆分task不work的时候,我们就要按照测试的角度来切分task了,这个思维的切换是TDD的核心。我们需要按照测试的视角来切分任务,从一个函数的实现视角转为一个函数的调用视角。
这样做的好处有三个:
1. 封装复杂性,当我们按照模块去拆分的时候,如前文所说,复杂性会变高,思考负担会加大。而按照测试的视角来切分呢,复杂性当然不会消失,但是被封装了,方便我们在分析的时候减少思考负担。
2. 跳出盒子外来看盒子的视角。我们在画前面的图的时候,实际上是在我们要实现的这个程序内在看,完全没有使用者的视角,也就是所谓的在盒子内,。当我们站在测试的视角看的时候,我们就跳出了盒子外,他更容易让我们发现哪里可能设计上有问题,比如设计出的接口是不是好用。
3. 在ThoughtWorks,我们有一个观点:叫做任务不是步骤。当我们按步骤来考虑问题的时候,对怎么算做完这个问题的答案往往是模糊的(往往只落在行为上,而不是结果上)。当我们只考虑函数实现的时候,也会有类似的问题,因为一个数据类型包含的情况太多了,想到某种类型的数据我们就会停止思考当前问题转而去想其他问题,于是我们很容易漏掉一些情况,以测试角度看待任务会让我们更容易看清楚我们的工作是不是真的做完了。
最棒的是,我们可以照着任务列表写出测试
it("test case 1 for function b", () =>{let paramX = // TypeX的测试数据let actualBValue = b(paramX); // 调用b函数的实际返回值let exceptedBValue = // 调用b函数的期望的返回值expect(actualBValue).is(expectedBValue); //断言})// 以此类推...
所以,我们是在以测试驱动的方式做任务划分,你可以叫它测试驱动的任务切分。
如果要映射到测试,我们的任务列表就缺了一些东西,那就是所谓的测试用例。因为同一个函数可能有不同的测试用例,所以加上用例我们的任务列表应该长成这个样子:
#1 场景一输入:paramX: TypaX输出:bValue: TypeA测试用例:用例1:inputValue1----outputValue1用例2:inputValue2----outputValue2// 以此类推...
我们看到因为输入输出的顺序已经定好了,为了书写的速度,我们就省略了名字。如果你觉得不舒服也可以写上名字。如果你觉得这样太浪费时间,你可以把每组用例用一句话描述。毕竟一切为了实用嘛。
是不是感觉后面讲的很抽象啊,不知道具体怎么做啊?不要着急,后面有例子。
练习
- 请把上一篇的任务列表,画成图
- 试着按照测试用例的方式画,没有思路可以阅读完第五篇和第六篇再来画。
题外话
题外话-1
视角的切换对于软件开发来说是至关重要的一个能力。为了说明这个的价值,我们甚至发明了一个概念——数字化人才
然而大多数人都不具备,所以对于大多数人来说,具备这个能力,最起码的好处就是变成了一种稀缺性人才,对于获得高薪是有帮助的。
