@cdmonkey
2018-08-06T07:36:28.000000Z
字数 10729
阅读 1425
Heartbeat(2)搭建
Heartbeat&DRBD
一、前期准备
1. 实施架构
Official Site:http://www.linux-ha.org
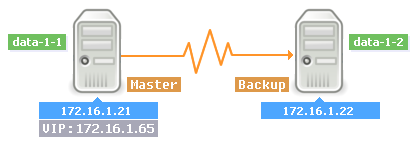
如图所示,高可用系统中共有两台服务器,我们的目标是,两台服务器都启用了Heartbeat服务后,VIP地址处于主设备上,备节点处于实时热备状态。当主节点宕机后,虚拟地址就会切换到备节点上,实现IP资源的自动接管,从而实现高可用的目的。
http://professor.blog.51cto.com/996189/1630151?utm_source=tuicool
http://www.thinksaas.cn/group/topic/163311/
http://www.360doc.com/content/14/1013/11/18924983_416502827.shtml
http://edu.51cto.com/lesson/id-53808.html
http://www.cnblogs.com/chinacloud/archive/2010/11/18/1881056.html
2. 场景配置
创建高可用集群有几点注意事项:
- 高可用集群中的各个节点因为需要传递集群事务信息,而信息的传递需要使用各个几点的名称,且该名称能够被正确的解析为相应的地址,所以要求对本地的
hosts文件进行正确的设置(非常不建议使用DNS进行名字解析),而且要求该文件在集群中各个节点上保持一致。 - 节点名称应该与
uname -n所输出的主机名称保持一致。 - 需要停掉及启动高可用集群中的某个节点时,不能在该节点上进行服务的关停及启动,而应该在一个健康的节点上来关闭及启动该节点,因此需要各个节点间能够进行
SSH免密码登录(作为根用户)。 - 高可用集群中的各节点要能检测其他节点的心跳信息,所以不允许时间上的偏差,所以要求各节点的时间要同步。
主机资源规划(注意,此地址规划适合为外网直接提供服务的业务场景,虚拟地址VIP与外网地址处于同一个网段,心跳连接处于独立的网段中):
| 名称 | 接口 | IP | 用途 | IP | 接口 | 名称 |
|---|---|---|---|---|---|---|
| MASTER | eth0 | 172.16.1.21 | 外网管理地址,用于外网数据传输。 | 172.17.1.22 | eth0 | BACKUP |
| eth1 | 10.0.0.21 | 内网管理地址,用于内网数据传输。 | 10.0.0.22 | eth1 | ||
| eth2 | 192.168.10.21 | 用于服务器间心跳线直连。 | 192.168.10.22 | eth2 |
这里建议大家把上述的三块网卡的地址设置为后八位相同的方式,这样容易记忆,便于管理。另外存储服务器之间、存储服务期和交换机之间可配成双千兆网卡绑定(bonding),从而提升传输性能。
虚拟机网络配置:

第一步,是设定主备节点的网络地址(下面所示是主节点的IP,备节点与之相对应):
# data-1-1:[root@data-1-1 ~]# ifconfigeth0 Link encap:Ethernet HWaddr 00:0C:29:E5:58:26inet addr:172.16.1.21 Bcast:172.16.1.255 Mask:255.255.255.0...eth1 Link encap:Ethernet HWaddr 00:0C:29:E5:58:3Ainet addr:10.0.0.21 Bcast:10.0.0.255 Mask:255.255.255.0...eth2 Link encap:Ethernet HWaddr 00:0C:29:E5:58:30inet addr:192.168.10.21 Bcast:192.168.10.255 Mask:255.255.255.0...# data-1-2:[root@data-1-2 ~]# ifconfigeth0 Link encap:Ethernet HWaddr 00:0C:29:75:1C:C9inet addr:172.16.1.22 Bcast:172.16.1.255 Mask:255.255.255.0...eth1 Link encap:Ethernet HWaddr 00:0C:29:75:1C:DDinet addr:10.0.0.22 Bcast:10.0.0.255 Mask:255.255.255.0...eth2 Link encap:Ethernet HWaddr 00:0C:29:75:1C:D3inet addr:192.168.10.22 Bcast:192.168.10.255 Mask:255.255.255.0...
第二步,我们还需要修改下主备节点的hosts文件:
注意:这里的解析条目是针对心跳网卡的。
[root@data-1-1 ~]# echo "192.168.10.21 data-1-1" >>/etc/hosts[root@data-1-1 ~]# echo "192.168.10.22 data-1-2" >>/etc/hosts# 备节点上进行同样的修改。# 注意:要去掉主机名同127.0.0.1之间的对应解析,而要将主机名解析为实际的IP地址。[root@data-1-1 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.10.21 data-1-1192.168.10.22 data-1-2# 注意:由于心跳网络要使用普通网卡,所以这里将主机解析到了心跳地址上,如果采用串口作为心跳线路,那么解析到内网地址即可。-----------------------# 修改完之后需要主备节点双方互相的ping一下主机名:[root@data-1-1 ~]# ping data-1-2
# 特别强调:主机名必须是下面指令显示的结果:[root@data-1-1 ~]# uname -ndata-1-1
对于hosts文件的设定,于“heartbeat”服务中会用到,于后面的DRBD以及存储的高可用服务中都会用到。于实际的生产场景中,我们会把所有的主机名对应上其IP地址,然后进行分发。当有新的服务器增加时,就会通过分发工具统一分发到所有的主机上。
第三步,为收发心跳消息的网卡设置路由,设置路由的目的是希望两台主机之间的心跳消息的接收与发送都通过我们设置的直连心跳线路来传输:
# Master:[root@data-1-1 ~]# route add -host 192.168.1.11 dev eth2[root@data-1-1 ~]# echo "route add -host 192.168.1.11 dev eth2" >>/etc/rc.local# Backup:[root@data-1-2 ~]# route add -host 192.168.1.10 dev eth2[root@data-1-2 ~]# echo "route add -host 192.168.1.10 dev eth2" >>/etc/rc.local
二、安装
首先要设置下EPEL软件源,普通的源无法下载到heartbeat的。
# 这里有一个细节需要注意,默认情况下,yum安装后的rpm包会被清除,此步骤的作用是保留安装的软件包到系统的目录。[root@Node-A1 ~]# sed -i 's#keepcache=0#keepcache=1#g' /etc/yum.conf-----------------------wget http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm[root@Node-A1 tools]# rpm -ivh epel-release-6-8.noarch.rpm[root@Node-A1 tools]# rpm -qa|grep epelepel-release-6-8.noarch
1. Install heartbeat
[root@Node-A1 ~]# yum install -y heartbeat*# The installation method will be installed at the same time several key components:# heartbeat、cluster-glue、resource-agents-----------------------# 因为我们上面通过设置使软件于安装后保留软件包,所以能够于下面的目录中查找到刚刚下载的所有软件包:[root@Node-A1 ~]# tree /var/cache/yum/x86_64/6/epel/packages/# Configuration file:[root@Node-A1 ~]# ll /etc/ha.d/total 20-rw-r--r-- 1 root root 692 Dec 3 2013 README.config-rwxr-xr-x 1 root root 745 Dec 3 2013 harcdrwxr-xr-x 2 root root 4096 Oct 11 11:30 rc.d # Configuration file directorydrwxr-xr-x 2 root root 4096 Oct 11 11:30 resource.d # Resource control directory (which containsthe control resources of the script)-rw-r--r-- 1 root root 2082 Jul 24 15:17 shellfuncs
提示:把脚本放到资源控制目录,或者是/etc/init.d目录中,然后在haresources设定文件中设定脚本名称就能够调用到该脚本,进而控制资源及服务的启动及关闭。
2. Configure File
设置文件模板的路径为:
[root@Node-A1 ~]# ll /usr/share/doc/heartbeat-3.0.4/total 144-rw-r--r-- 1 root root 3701 Dec 3 2013 AUTHORS-rw-r--r-- 1 root root 17989 Dec 3 2013 COPYING-rw-r--r-- 1 root root 26532 Dec 3 2013 COPYING.LGPL-rw-r--r-- 1 root root 58752 Dec 3 2013 ChangeLog-rw-r--r-- 1 root root 2935 Dec 3 2013 README-rw-r--r-- 1 root root 1873 Dec 3 2013 apphbd.cf-rw-r--r-- 1 root root 645 Dec 3 2013 authkeys-rw-r--r-- 1 root root 10502 Dec 3 2013 ha.cf-rw-r--r-- 1 root root 5905 Dec 3 2013 haresources
默认的设定文件目录为/etc/ha.d,其常用的设置文件有三个,显而易见,其文件名就表示其实际的功能:
| 文件名 | 作用 | 备注 |
|---|---|---|
ha.cf |
参数设定文件 | 于这里设置一些“heartbeat”的基本参数。 |
authkeys |
节点之间的认证文件 | 高可用节点间根据对方的该文件,相互进行认证。注意该文件的权限为600。 |
haresources |
资源设定文件 | 如设定启动IP资源及脚本程序以及服务等。 |
如果是自行开发的应用需要被“heartbeat”所接管,则需要将服务控制程序放置于/etc/ha.d/resource.d目录下,再使用haresources设定文件进行调用。
对于上述文件,常规的使用方法是将其拷贝到设定文件目录下面,但是这里我们直接使用的是老师提供的设定文件,其中的内容虽然不是全部是设置参数项目,但都是实际工作中最为常用的。
一般情况下要将所需的设定文件拷贝到工作目录/etc/ha.d:
[root@Node-A1 ~]# cd /usr/share/doc/heartbeat-3.0.4/[root@Node-A1 heartbeat-3.0.4]# cp ha.cf authkeys haresources /etc/ha.d/# Change the file permissions of authkeys:[root@Node-A1 heartbeat-3.0.4]# chmod 600 /etc/ha.d/authkeys
ha.cf
该文件为“heartbeat”的主要设定文件(注意:下面的内容为实际工作中最为常用的一些参数值,更详细的说明请查阅相关文档。另外,设定文件是逐行读取的,并且设定项的顺序是会影响最终结果的):
[root@data-1-1 ~]# vim /etc/ha.d/ha.cf# Log setting:debugfile /var/log/ha-debug # Debug log storage pathlogfile /var/log/ha-log # Common log storage pathlogfacility local1 # Settings are received by using the local1 device in the rsyslog service# If you do not log in to rsyslog, you need to set it to "None"#keepalive 2 # 指定心跳信息发送间隔为2秒钟。deadtime 30 # 若备节点于30秒内没有收到主节点的心跳信号,则立即接管主节点的服务资源。warntime 10 # 指定心跳延迟的时间为10秒。# 当10秒内备节点没有收到主节点的心跳信号时,就会于日志中写入一个警告日志,但并不会进行服务资源的接管。initdead 60 # 指定于高可用服务首次运行后,需要等待60秒才启动主节点的服务资源。# 该选项用于解决这种情况产生的时间间隔。取值应至少为“deadtime”的两倍。单机启动时会遇到VIP绑定很慢,为正常现象,这也是该值要设置长一些的原因。udpport 694 # 节点之间使用单播或多播通信(心跳信息)时所使用的UDP端口。#serial serialportname ... # Set the Serial port Device.#serial /dev/ttyS0 # 设定串行通信设备,用于双机使用串口线连接的情况。如果双机使用以太网连接,则需关闭该选项。...#bcast eth1mcast eth2 225.0.0.7 694 1 0 # 设置使用一个多播心跳信息监听设备,默认端口为649。# Class D multicast address 224.0.0.0-239.255.255.255auto_failback on # 用来定义当主节点恢复后,是否重新抢占资源并恢复服务。node data-1-1 # 主节点的主机名。node data-1-2 # 备节点的主机名。crm no # 是否开启集群资源管理功能。
注意:两台高可用服务器对的配置文件内容要一模一样。
authkeys
该文件用于设定双方的认证方法,可使用:crc、md5、sha1,三种认证方法的安全性依次提高,但占用的系统资源也依次增加。如果高可用集群运行于安全的网络上,可使用crc,如果每个节点的硬件性能很高,则建议使用sha1,这种方法的安全级别最高。折中的方法为md5。
默认的认证算法采用的是“CRC”,但它为未加密的,不安全。设置为加密的认证信息其实很简单,就是两行(同样,高可用服务器对两端的认证文件的内容也是相同的):
# The first need to generate an encrypted message:[root@data-1-1 ha.d]# echo "cdmonkey"|sha1sum037cdde840e74414b4f43f281119a04bf92fe37c -[root@data-1-1 ha.d]# cat authkeysauth 11 sha1 037cdde840e74414b4f43f281119a04bf92fe37c--------------------# Note that the file permissions must be 600![root@data-1-1 ~]# chmod 600 /etc/ha.d/authkeys
注意:无论
auth后面指定的是什么数字,于下一行必须作为关键字再次使用。
haresources
该文件用于指定双机高可用系统的主节点、集群IP地址、子网掩码、广播地址以及启动的服务等集群资源,文件每一行可以包含一个或多个资源脚本名。资源之间使用空格隔开,参数之间使用两个冒号隔开。此文件的一般格式为:
它不一定是当前机器的名称。
node-name network <resource-group>
注意:在高可用集群中的所有节点上,该文件的内容必须保持一致!
| 字段 | 说明 |
|---|---|
node-name |
该字段表示主节点的主机名,必须和ha.cf文件中指定的节点名一致。 |
network |
用于设定集群的IP地址、子网掩码以及网络设备标识等。需要注意的是,该处指定的IP地址就是集群对外服务的地址。 |
<resource-group> |
用来指定需要“Heartbeat”托管的服务,就是说这些服务可以由它来启动和关闭。 |
如果要对最后一个字段所指定的服务进行托管,就必须将服务写成能通过“start/stop”参数来启动和关闭的脚本,同时需要放到/etc/init.d或者/etc/ha.d/resource.d这两个目录下,它会根据脚本的名称自动去这两个目录下找到相应脚本文件进行启动、关闭等操作。
服务可托管的条件:服务脚本能通过“start/stop”参数启停;置于两个指定目录中的一个;并且是可执行的。
# MySQL+DRBD+Heartbeat:data-1-1 IPaddr::172.16.1.65/24/eth0 drbddisk::data Filesystem::/dev/drbd0::/data::ext3 rsdata#挂载操作相当于执行:mount -t ext3 /dev/drbd0 /data

这里请注意:上面的这行配置内容是有先后顺序的,其生效顺序是从左到右依次生效。
我们当前的实验场景需要进行下面的设定内容:
# Both the master node and the backup node have the same configuration:[root@data-1-1 ~]# cat /etc/ha.d/haresourcesdata-1-1 IPaddr::172.16.1.65/24/eth0
上面的设定实际就是执行了下面的脚本(该脚本的主要功能就是增加VIP):
[root@data-1-1 ~]# /etc/ha.d/resource.d/IPaddr 172.16.1.65/24/eth0 startINFO: Adding inet address 172.16.1.65/24 with broadcast address 172.16.1.255 to device eth0INFO: Bringing device eth0 upINFO: /usr/libexec/heartbeat/send_arp -i 200 -r 5 -p /var/run/resource-agents/send_arp-172.16.1.65 eth0 172.16.1.65 auto not_used not_usedARPING 172.16.1.65 from 172.16.1.65 eth0INFO: SuccessINFO: Success
3. Start Service
要于两台高可用服务器对上同时启动服务。
[root@data-1-1 ~]# /etc/init.d/heartbeat startStarting High-Availability services: INFO: Resource is stoppedDone.--------------------# Check the VIP address on the master node and the backup node:[root@data-1-1 ~]# ip add|grep 172.16.1.65inet 172.16.1.65/24 brd 172.16.1.255 scope global secondary eth0[root@data-1-2 ~]# ip add|grep 172.16.1.65--------------------# Check the service port:[root@data-1-1 ~]# lsof -i:694COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEheartbeat 32716 root 7u IPv4 54492 0t0 UDP 225.0.0.7:ha-clusterheartbeat 32717 root 7u IPv4 54492 0t0 UDP 225.0.0.7:ha-cluster
能够看到,主节点上已经绑定了VIP,而备节点并未绑定,所以高可用服务正常启动,没有发生裂脑。我们此时停掉主节点的服务:
[root@data-1-1 ~]# /etc/init.d/heartbeat stopStopping High-Availability services: Done.--------------------# Check the VIP address on the backup node:# VIP has been moved from the mastr node to the backup node[root@data-1-2 ~]# ip add|grep 172.16.1.65inet 172.16.1.65/24 brd 172.16.1.255 scope global secondary eth0
若不是直接停掉服务,而是将主机关机,那么故障转移的时间可能会稍长一些。而主节点一旦从故障中恢复,并且重新启动高可用服务,那么VIP又会切换回主节点,当然能够通过设定阻止复活的主节点抢夺资源服务。
故障切换的实质就是备节点无法接收主节点发送的心跳信息后,执行相应的脚本,以接替主节点继续工作。
6. 释放和接管
除了主节点有问题使得备节点接管服务资源外,还可手动直接让某一方释放服务资源,而让另一方接管服务资源。
# Complete release:[root@data-1-1 ~]# /usr/share/heartbeat/hb_standby# Complete take over:[root@data-1-1 ~]# /usr/share/heartbeat/hb_takeover
7. Check Log
我们首先清空日志,然后主节点主动释放服务资源,查看日志内容,了解高可用工作原理。
[root@data-1-1 ~]# > /var/log/ha-log#主节点释放资源:[root@data-1-1 ~]# /usr/share/heartbeat/hb_standbyGoing standby [all].Apr 09 18:56:50 data-1-1 heartbeat: [34596]: info: data-1-1 wants to go standby [all]Apr 09 18:56:50 data-1-1 heartbeat: [34596]: info: standby: data-1-2 can take our all resourcesApr 09 18:56:50 data-1-1 heartbeat: [36096]: info: give up all HA resources (standby).ResourceManager(default)[36109]: 2015/04/09_18:56:50 info: Releasing resource group: data-1-1 IPaddr::172.16.1.65/24/eth0ResourceManager(default)[36109]: 2015/04/09_18:56:50 info: Running /etc/ha.d/resource.d/IPaddr 172.16.1.65/24/eth0 stopIPaddr(IPaddr_172.16.1.65)[36172]: 2015/04/09_18:56:50 INFO: IP status = ok, IP_CIP=/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.1.65)[36146]: 2015/04/09_18:56:50 INFO: SuccessApr 09 18:56:50 data-1-1 heartbeat: [36096]: info: all HA resource release completed (standby).Apr 09 18:56:50 data-1-1 heartbeat: [34596]: info: Local standby process completed [all].Apr 09 18:56:51 data-1-1 heartbeat: [34596]: WARN: 1 lost packet(s) for [data-1-2] [18172:18174]Apr 09 18:56:51 data-1-1 heartbeat: [34596]: info: remote resource transition completed.Apr 09 18:56:51 data-1-1 heartbeat: [34596]: info: No pkts missing from data-1-2!Apr 09 18:56:51 data-1-1 heartbeat: [34596]: info: Other node completed standby takeover of all resources.
备节点的日志内容(略,反正就是和主节点释放资源相对应的接管资源的若干信息)。另外需要注意,每次VIP进行切换的时候,接管资源服务的节点都会有一个清空内网ARP缓存的动作,这是必须的。
此时,由于主节点主动释放资源,所以备节点顺理成章的进行了接管。如果这时主节点相重新夺取资源服务,需要手动执行接管命令。
[root@data-1-1 ~]# /usr/share/heartbeat/hb_takeover --helpusage: /usr/share/heartbeat/hb_takeover [all|foreign|local|failback]#进行接管:[root@data-1-1 ~]# /usr/share/heartbeat/hb_takeover
