@EggGump
2020-05-19T05:53:14.000000Z
字数 10164
阅读 769
Active Defense-Based Resilient Sliding Mode Control Under Denial-of-Service Attacks
security
Wu C, Wu L, Liu J, et al. Active Defense-Based Resilient Sliding Mode Control Under Denial-of-Service Attacks[J]. IEEE Transactions on Information Forensics and Security, 2020, 15(1): 237-249.
2020-5-15
这篇,看错方向了。
本篇目的:针对网络物理系统的遭遇DoS攻击时的弹性控制问题提出用0和博弈来构建混合防御机制。
Introduction
对于CPS的攻击防御策略的工作有:【4-10】,本文提出如何建立在CPS被DoS攻击时的一种弹性控制架构。基于DoS攻击的的有效控制工作有【14-17】,针对于DoS攻击的博弈论防御策略工作有【20-27】。本文贡献:将物理过程表示成一个基于攻击频率和攻击持续时间的转换过程;使用滑动弹性转换模型使得当DoS攻击发生时物理过程仍然稳定;提出一个有效的防御策略控制转换逻辑。
System Formulation and Preliminaries
控制蓝图如图1。
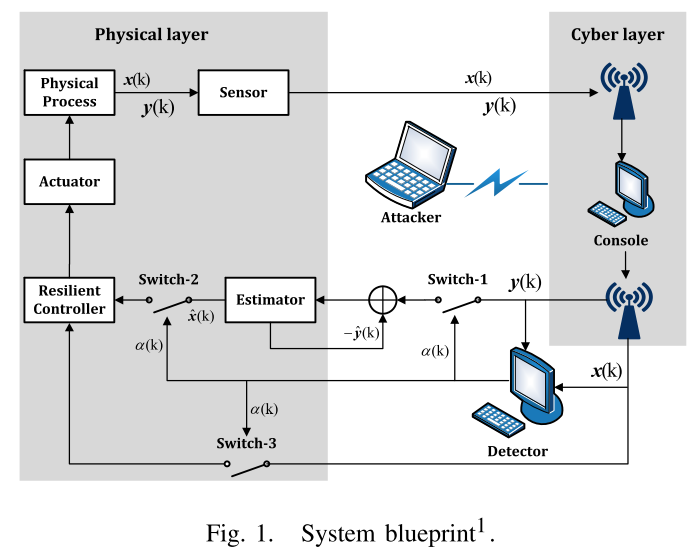
CPS由物理层和网络层组成,物理层有传感器和执行器,其估计器和弹性控制器可通过观测损失信号来保证DoS发生时物理过程能有可靠性能,检测器可以得知是否数据包被接收并基于此决定switch的状态。
A. Physical Proces Description
物理过程可由离散模型表示,如式(1)。
""
分别表示状态向量和控制输入,测量输出表达为,这里的A,B,C为相应的矩阵,B列满秩。本文这里考虑的均为线性物理过程。
B. DoS Attack
本文只考虑恶意传感DoS攻击,定义为攻击发生的时间点,则第j个时间点攻击发生表示为:"
假设1. 攻击频率:存在,有
假设2. 攻击持续时间假设:存在,有:
假设1类似平均持续时间,为DoS攻击次数。
Resilient Sliding Mode Control Design
A. Estimator Design
估计器设计:为补充被攻击而损失的信号,估计器估计状态信号如式(2)。
这里为对x(k)的估计。""为switching的收益,取{0,1},分别表明在攻击情况和未攻击情况下的switching。,其中为估计器的测量输出,。取决于攻击是否发生,"",""。为简单表达,记
B. Sliding Mode Approach
滑动模型函数定义如式(3).
为矩阵,因此等价控制如式(4)。
定义误差:,则结合式(1,2,3)可得式(5)
这里: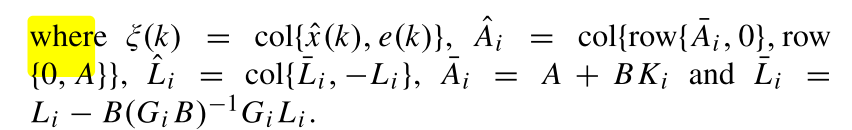
因此我们可以通过Lyapunv函数分析式(5)系统,定义:为Lyapunov函数,其中为正定对称矩阵,分析过程如下三步:
step1:持续攻击情况,则式(5)可写作
step2:无攻击情况,则有:
这里的,可得式(7):
step3: switching 情况发生在和之间。此时为为保证过程的稳定性收益应有如下限制,如式(8):
这里的为正标量,属于(1,无穷大).
定义,将schur complement应用到(8)中可得:"",这里,"","".收益的计算如算法1。

C. Stability Analysis
物理系统(1)遭受的DoS攻击满足假设1,2时,当给定,若存在"",正定矩阵和矩阵使得算法1有可行解且满足:
"
则式(5)则可保证指数稳定,稳定率为""。
Resilient Sliding Mode Controller Design
滑动模型函数如式(3),则系统(1)的轨迹可通过如下控制来获得预测轨迹,控制如式(9)
其中为调节矩阵,""
- 下面例子不解释了,相当于实验总分,其通过实验证明算法一可使得在遭受攻击时能保证状态指数平滑。
Active Defense-Based Resilient Control
本部分通过博弈论找最优防御机制,为表示额外动荡衰减,这里将系统(1)重写为式(10):
""
E为已知矩阵为额外衰减。攻击发生率定义为"",其由博弈论决定。
A. Optimal Dfense Strategy
将防御和攻击方看作0和博弈的两方,最优防御策略可通过计算博弈矩阵获得。攻击者的攻击行为选自库:,防御库为:"",定义为防御库所有可的子集,并定义:""为防御者先择的策略。再定义: and 为分别为攻击与防御在状态选择相应策略的概率,,,。当前状态是否改变取决于双方的策略,本文使用马尔可夫链来表示的改变,转换概率记为:"",其中""。
定义状态中的代价映射:"",防守方需要最小化代价,而攻击方则要最大化代价,因双方为0和博弈,因此我们有:
对于所有的网络状态则有:
定义代价折扣函数:,其中,定义:""
则通过定理:
则最优策略可通过下式获得:
获得最优策略中的一个重要步骤就是计算博弈矩阵.当给定矩阵,可通过下列线性过程获得平衡鞍点:
B. Defense Scheme-Based Estimator
估计器用于估计由于攻击而损失的信号,表达式如式(11)。
为收益,为估计误差。估计器其实取决于具体的防御机制,不同的策略会使网络状态和子模型i不同。
C. Sliding Dynamic Analysis
设计带有攻击信息的滑模曲面函数如下:
这里""为预定义矩阵,非单,为设计的矩阵。由此可得等价控制如式(12)。
这里""。将式(12)代入式(10)并将估计误差记为""可得两个case
case1,攻击成功,则有式(13)
这里""
case2,无攻击则有式(14)
""
这里""
可见攻击无法一直持续,因为防御措施会使动态切换一直处于式(13)和式(14)之间,切换模型如式(15)。
其中参数具体如下: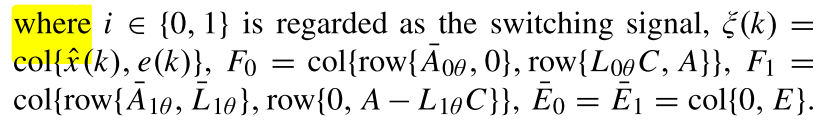
结论:式(15)中的系统一定可以指数平滑,且消退率为""
D. Resilient Sliding Mode Control Design With Defense Strategy
恶意攻击者通过DoS攻击来破坏系统,让数据丢失从而使系统不稳定,设计好防御机制后应该测试其有效性。定义映射:来表示服务质量,则DoS攻击在状态的攻击率可由如下映射一表示
这里""
因为性能取决于当前的action pair,定义映射: and ,则性能可被表示为如下映射二:
这里有""
结合以两个映射便可获得最优收益""和最优策略"",如算法2:

Example2
对于系统(10)和给定参数,如下图:

系统响应如图7
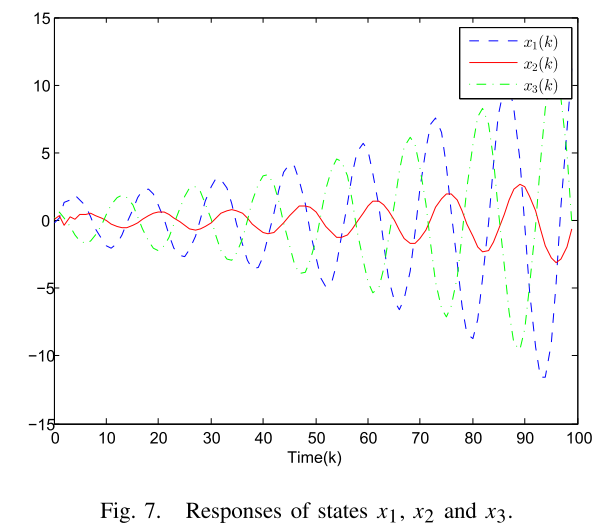
可知轨迹无法收敛。
当防御策略和攻击策略如表1,2,转换概率如表3时
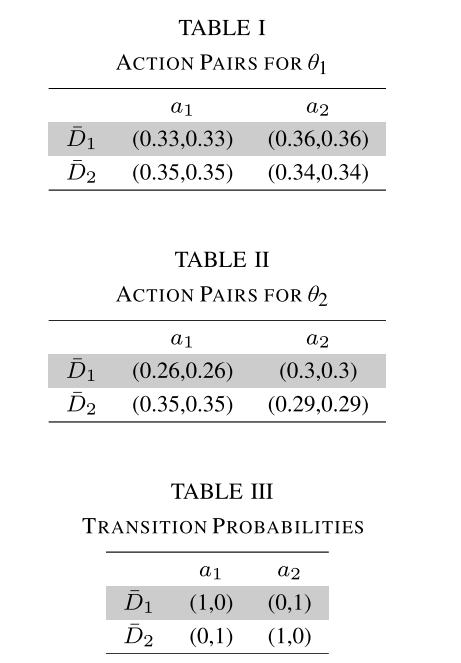
通过应用算法2,博弈值的迭代过程如图8所示
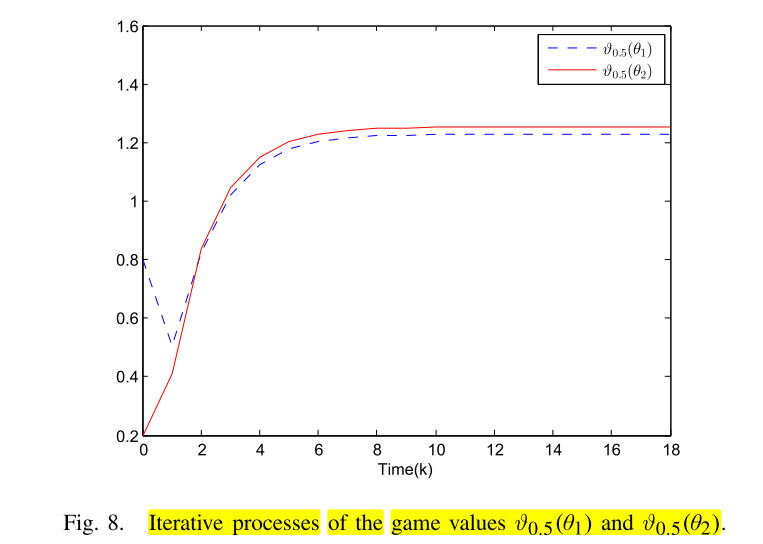
的进化过程如图9和图10
从这些图中可得知损失的数据可被有效地observed,且当DoS攻击发生时本文提出的弹性控制算法能有效地维护系统的稳定性。
