@Dounm
2018-08-30T11:52:17.000000Z
字数 3321
阅读 3234
分布式数据库BigTable调研
Blog 分布式
1 分布式数据库(Distributed Database)
分布式数据库是使用计算机网络将物理上分散的多个数据库单元连接起来组成一个逻辑上统一的数据库。多个数据库单元被称为站点或节点,有一个分布式数据库管理系统(DDBMS)来管理。
与分布式数据库相对而言的数据库被称为集中式数据库。集中式数据库的数据操纵和处理都集中在一个处理设备上,因此面临当前的大数据的快速发展所带来的对于海量数据的处理的需求时,就显得有些力不从心了。而且,应用程序集中在一台计算机上,一旦该计算机发生故障,整个系统就会受到影响,系统的可靠性较差。
而相对而言,分布式数据库系统的特点则是如下:
- 物理分布性与逻辑整体性:物理分布性体现为数据并不是存储在一个整体上,而是存储在计算机网络的多个场地上,而逻辑整体性则是指这些数据节点有一个统一的DDBS管理,在逻辑上呈现给用户的是一个整体。
- 场地自治性:各场地上的数据由本地的DBMS管理,具有自治处理能力,完成本场地的应用(局部应用)。
而相对于集中式数据库而言,分布式数据库的优点则体现为体系结构较为灵活;系统管理费用低;可以随时针对各区域用户作出调整;局部应用相应速度快;系统的可扩展性和可靠性都较高。
2 BigTable分布式数据库
2.1 BigTable概述
众所周知,Google的用户量巨大,那么产生的数据也必然是相当惊人。如果使用传统的集中式数据库例如MySQL无法满足Google对于数据规模以及操作时延的要求,因此Google的工程师们自己设计了一个专门为了管理大规模结构化数据的分布式管理系统:BigTable。
Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers.
以上引用自Google于2006年发表的关于Bigtable的论文[1]。
BigTable使用了很多数据库的实现策略,但是并不支持完整的关系型数据模型,因此并不是关系型数据库。BigTable将数据统统看为无意义的字符串,所以客户端需要将结构化和非结构化的数据串行化之后再存入BigTable。
2.2 BigTable数据模型
本质上来说,BigTable是多维键值(key-value)映射。论文里的说法:A Bigtable is a sparse, distributed, persistent multidimensional sorted map。其中,持久化(persisitent)和分布式(distributed)体现为Google将把Bigtable的数据以文件的形式存储到Google文件系统GFS(Google File System)中去,而GFS采用的是分布式存储的技术。而稀疏(sparse)则表示在一个表的不同行里,列可能完全不一样。而关于multidimensional sorted map则体现在BigTable的数据模型中。
Bigtable有三维,分别是行键(row key),列键(column key)以及时间戳(timestamp),其中行键和列键都是字符串,时间戳是64位整型。而值得话也是字符串。我们可以用 (row:string, column:string, time:int64) → string 来表示一条对应的键值记录。
2.2.1 行(row)
Bigtable的行是任意字节串,长度不超过64KB,但是通常10-100字节已经够用了,行键按照字典序来存储数据。Bigtable会自动根据行键将表划分为片(tablet),片是负载均衡的单元。开始时表只有一个片,后来随着表的不断增加,片会自动分裂,片的大小控制在100MB-200MB以内。
table{
"asdfsa" : "daf",//一行
"fff" : "sdfa",
}
如上图,将后面的列键、时间戳以及值看做一个整体。
2.2.2 列(column)
列是Bigtable的第二级索引,而列的话以列族(column family)进行分类。列族是访问控制的单元,一个列族拥有相同的数据类型。一行的列族很少变化,但是列族里的列可以随意的删减。
列键的格式为faimily:qualifier的格式。
table{
"first_row"{ //一行
"A":{ //一个列族
"hhh" : "adsfa"; //列族里的列(或称qualifier)
"aaa" : "ddd";
}
"B":{
"ad" : "daf";
"da" : "fda";
}
}
}
以上代码将时间戳(timestamp)和值看做了行键和列键对应的值。
2.2.3 时间戳(timestamp)
Bigtable用时间戳来对应数据的多个版本。时间戳的值可以由Bigtable来赋值,代表数据进入Bigtable的准确时间,或由客户端进行设置。Bigtable按照降序来排列,因此先读到的数据便是最近版本的数据。
除此之外,Bigtable还支持垃圾回收机制(grabage-collect),用户可以对每个列族(column family)设置该列族里的列最多保留几个版本。
查询的时候如果未给出具体的时间戳,那么返回的就是最新版本的数据;如若给出了时间戳,那么返回的就是小于等于改时间戳的数据。
table{
"first_row"{ //一行
"A":{ //一个列族
"hhh":{ //列族里的列(或称qualifier)
15 : "adsf"; //一个版本
6 : "sdf"
}
"aaa"{
40 : "ddd";
}
}
"B":{
"ad" : "daf";
"da" : "fda";
}
}
}
2.2.4 example: webpage
Google在讲述Bigtable的论文[2]中给出了一个例子来帮助读者更加形象的理解Bigtable的数据模型。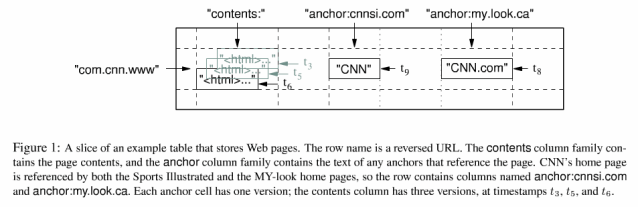
如图,可以看到,Webtable里每一行存储一个网页,以反转的URL"com.cnn.www"作为行键。之所以使用反转的URL是为了使得在同一域名上的网页在Bigtable中的存储位置相邻。每一行有两个列族contents和anchor。其中contents列族里只有一列,保存了网页的三个版本,t3,t5,t6。而anchor列族里存储的是别的网页中指向该网页的超链接的文本内容。如图中所示,有两个网页"cnnsi.com"和"my.look.ca"中拥有超链接指向"www.cnn.com"。其中"cnnsi.com"中的超链接文本是"CNN",而"my.look.ca"中的超链接文本是"CNN.com"。
2.3 Bigtable的支撑技术
2.3.1 SSTable
SSTable全称Sorted String Table,是一种文件存储格式。Bigtable将日志和数据文件以SSTable的格式存储在GFS中。
SSTable包含一系列的块(block)以及块索引(block index)。其中块通常为64KB大小(可修改)。块索引则存储在SSTable的尾部,并且当访问到SSTable的时候会将整个块索引装载入内存中。
2.3.2 Chubby
Chubby是一种分布式锁服务。一个Chubby服务包括5个活跃的副本,其中一个副本被选为主副本(master)然后用来相应客户端的请求。副本之间采用Paxos算法来维持一致性。
