@Dounm
2018-08-30T11:48:46.000000Z
字数 7293
阅读 3458
Spark上手指南
Blog 分布式
本问旨在给初学者一个对于Spark快速上手的指南。
目的:在读完本文后可以写出简单的Spark Application,并在本地或集群上运行。
1 Spark介绍
Apache Spark 是一个开源计算框架(open source cluster computing framework).最初由加州伯克利大学的AMPLab开发。
1.1 Spark计算框架
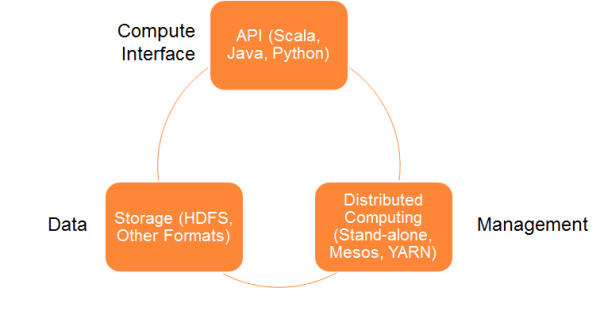
运行Spark计算框架需要一个cluster manager和一个distributed storage system
支持如下的cluster manager(包括但不仅限于):
- standalone(native Spark cluster)
- Hadoop YARN
- Apache Mesos
支持如下的distributed storage system(包括但不仅限于):
- Hadoop Distributed File System(HDFS)
- MapR File System(MapR-FS)
- Cassandra
- OpenStack Swift
- Amazon S3
- Kudu
- Spark还支持伪分布式模式,即用本地文件系统来假装分布式存储(通常这种模式是用来进行开发和测试)
1.2 Spark Vs MapReduce
| 框架 | 特点 |
|---|---|
| MapReduce | 一路计算的优秀解决方案。但是对于多路计算来说,数据数据处理流程中的每一步都需要一个Map阶段和一个Reduce阶段。在下一步开始之前,上一步的作业输出数据必须要存储到分布式文件系统中。因此,复制和磁盘存储会导致这种方式速度变慢 |
| Spark | 将中间结果缓存在内存中,而非写入磁盘。Spark会尝试在内存中存储尽可能多的数据然后再将其写入磁盘。它可以将某个数据集的一部分存入内存而剩余部分存入磁盘。 |
1.3 Spark包含的组件
- Spark Core:整个Spark框架的基石,通过基于RDD抽象的编程接口提供
- distributed task dispatching
- scheduling
- basic I/O functions等功能
Spark MLlib:基于Spark Core的分布式机器学习框架。因为数据都存在内存中,所以会比数据存在磁盘上的框架快很多。
包括了很多机器学习和统计学习算法,如下:- summary statistics, correlations, stratified sampling, hypothesis testing, random data generation[10]
- classification and regression: support vector machines, logistic regression, linear regression, decision trees, naive Bayes classification
- collaborative filtering techniques including alternating least squares (ALS)
- cluster analysis methods including k-means, and Latent Dirichlet Allocation (LDA)
- dimensionality reduction techniques such as singular value decomposition (SVD), and principal component analysis (PCA)
- feature extraction and transformation functions
- optimization algorithms such as stochastic gradient descent, limited-memory BFGS (L-BFGS)
Spark SQL:使用数据抽象DataFrames来对结构化或半结构化的数据提供SQL查询支持。
Spark SQL is a component on top of Spark Core that introduces a new data abstraction called DataFrames,[a] which provides support for structured and semi-structured data.
- Spark Graphx: 基于Spark的分布式图像处理框架
- Spark Streaming:
Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics.
2 Scala语法简介
3 RDD(Resulient Distributed Dataset)
RDD is a read-only collections of elements distributed over a cluster of machines, that is maintained in a fault-tolerant way.
Spark's RDDs function as a working set for distributed programs that offers a (deliberately) restricted form of distributed shared memory.
- 具有容错性:RDD知道如何重新创建和重新计算数据集
- 可以帮助重新安排计算并优化数据处理过程
- 不可变性:用Transformation修改RDD得到的是一个全新的RDD,而原有RDD保持不变
3.1 创建RDD
有两种方式创建RDD数据集:
- 将driver程序中已经存在的一个collection(如Array, List)并行化
- 引用外部存储系统的一个数据集文件,例如本地文件系统,HDFS
3.1.1 并行化collection
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data) //sc是SparkContext类型的变量,用于访问cluster
3.1.2 引用文件系统
默认路径的是HDFS上。
如果想要访问本地的文件的话,需要加上file://前缀,使用绝对路径。(如 file:///home/me/spark/README.md)
//Spark-shell
scala> val distFile = sc.textFile("data.txt")
distFile: RDD[String] = MappedRDD@1d4cee08
scala> val distFile = sc.textFile()
//支持读取整个目录,压缩文件,通配符
sc.textFile("/my/directory")
sc.textFile("/my/directory/*.txt")
sc.textFile("/my/directory/*.gz")
3.2 Transformations&Actions
3.2.1 Transformations
Transformation会获取一个RDD作为参数,然后返回一个新的RDD,而非单个值。
Transformations are lazy. 他们不是立刻计算新的RDD,而是等待action向dirver program返回值的时候才会计算
常用Transformation:
map(func):把RDD中的每个元素都传入func函数,将返回值形成一个新的RDD并返回filter(func):把RDD每个元素传入func,将func返回值为true的元素形成一个新的RDD返回
3.2.2 Actions
Action计算并返回一个新的值给driver program。
当在一个RDD对象上调用Action时,会在这一时刻计算全部的数据处理查询并返回结果值。
常用Action:
reduce(func):aggregate整个RDD数据集。func函数输入两个参数,返回一个参数。count():返回数据集中元素的个数first():返回数据集的第一个元素take(n):返回一个包含了RDD前n个元素的array
3.2.3 示例代码
val lines = sc.textFile("data.txt") //此时还没有将data.txt里的内容读入内存,Lines是RDD[Sting]类型的变量,但此时实质上只是指向文件的一个指针,
val lineLengths = lines.map(s => s.length) //LineLengths是RDD[Int]类型的变量,此时也没有立刻计算
val totalLength = lineLengths.reduce((a, b) => a + b) //开始计算,并且返回计算出来的结果给totalLength这个变量,totalLength是Int型变量,而非RDD[Int]
3.3 Save&Print RDD
myRDD.saveAsTextFile("/path") //对RDD中的每个元素都调用toString()函数,然后按照每个element一行的格式输出到文件中
myRDD.take(100).foreach(println) //用于Spark-shell中,将RDD的前100个元素在控制台输出
4 Spark Self-contained Application
即提交到集群上运行的应用程序(用Scala或Python等编写)。
每个Spark Application都有一个driver program来运行用户的main函数,然后在计算集群上运行并行操作。
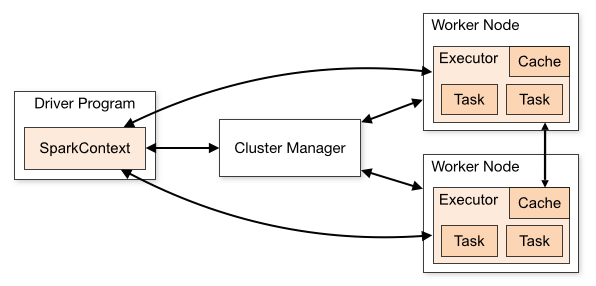
4.1 如何编写Spark App
首先需要先创建SparkConf 对象来配置Application的一些信息。
然后使用SparkConf对象来创建SparkContext对象来告诉Spark如何access集群。
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._ //Before Spark 1.3.0, you need to explicitly import org.apache.spark.SparkContext._ to enable essential implicit conversions.
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application") //AppName就是在集群监控页面现实的名字
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
4.2 Build Tool
默认的Scala语言支持的打包工具是SBT和Maven,我们仅介绍下Maven
4.2.1 Maven
Maven is a build automation tool used primarily for Java and Scala projects
Maven编译的项目目录下要形成这种类型的文件结构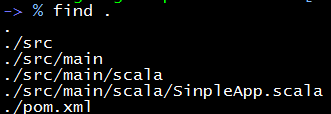
其中pom.xml(全称Project Object Model)是用来存储Maven在编译时的配置,配置包括了项目名称,项目依赖。
配置好了之后就是开始编译,我们使用mvn package的命令,就会把源码打包成jar,存放在target目录下。
因为Maven在编译源码时会动态下载repository内最新版本lib和plug-ins,有时候会很慢,
我们可以通过–offline参数来加快编译速度。
mvn package //首次编译
mvn package --offline //后续编译
4.3 提交Application:spark-submit
spark-submit可执行文件位于SPARK_HOME/bin文件夹内,用于提交Application并且运行。
命令详情:
/bin/spark-submit \
--class <main-class> //就是所编写的Application的类名,上例中就是SimpleApp
--master <master-url> \ //cluster管理程序的URL,可选值:local, yarn, spark://HOST:PORT
--deploy-mode <deploy-mode> \
--conf <key>=<value> \ //application的配置,像--number-executors = 10就是设置10个executors来执行文件
... # other options
<application-jar> \ //将源码利用maven打包出来的jar文件
[application-arguments] //编写类的参数输入
其中,参数-master有如下几种常用取值:
| Master URL | 含义 |
|---|---|
| local(default) | 在本地而非集群跑Spark作业,并且只有一个worker thread(所以,并事实上没有并行) |
| local[k] | 在本地跑Spark Application,有k个worker thread |
| spark://HOST:PORT | 连接到指定URL的standalone集群 |
| mesos://HOST:PORT | 连接到指定的Mesos集群 |
| yarn | 连接到默认的YARN集群。yarn集群在SPARK_HOME/conf/yarn-site.xml中指定 |
4.3.1 作业参数的配置
spark中有三个地方可以配置作业的提交参数,优先级由高到低如下:
- 源代码中使用SparkConf对象配置:
val conf = new SparkConf().setMaster(yarn).setAppName("") - spark-submit中的提交参数:
--master = yarn - SPARK_HOME/conf中的spark-default.conf文件的值:
spark.master yarn
SPARK_HOME/conf中的各种配置文件的作用如下:
- core-site.xml:配置默认的文件系统(即HDFS的相关信息)
- yarn-site.xml:yarn集群相关的配置
- spark-defaults.conf:包含一些spark常用的配置
4.4 spark-shell
spark-shell是和Python的交互式解释器类似的程序。
内在的原理是调用spark-submit脚本,因此spark-shell也可以使用spark-submit的一些参数。
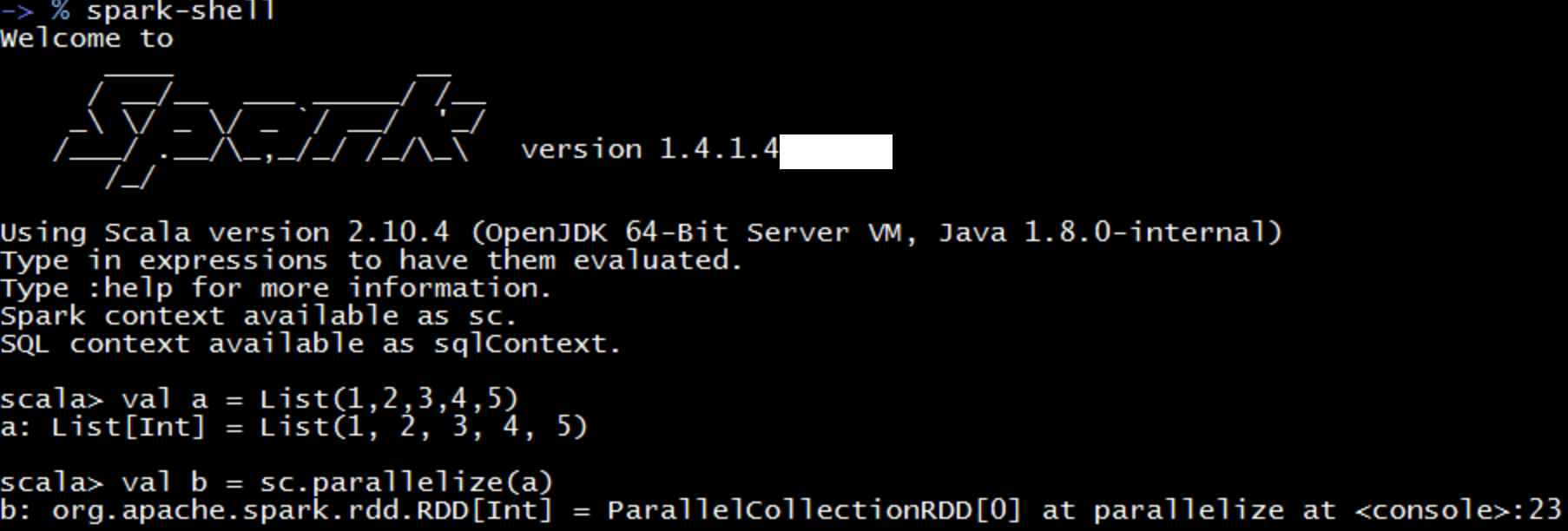
由上图可知,spark-shell已经创造了一个SparkContext对象并命名为sc,因此我们无法再手动创建SparkContext对象了。
但是可以在调用spark-shell命令时通过参数来设置sc连接哪个master。
$ ./bin/spark-shell --master local[4]
$ ./bin/spark-shell --master yarn
5 MLlib
5.1 MLlib的基本数据结构
5.1.1 LocalVector
LocalVector是存储在单台机器上的向量。以0为下标起始,值为double。分为两种格式:dense, sparse
import org.apache.spark.mllib.linalg.{Vector, Vectors}
// Create a dense vector (1.0, 0.0, 3.0)
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
val dv: Vector = Vectors.dense(Array(1.0, 0.0, 3.0))
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its indices and values corresponding to nonzero entries.(3 is the size of vector)
val sv1:Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its nonzero entries (3 is the size of vector).
val sv2: Vector = Vectors.sparse(3, List((0, 1.0), (2, 3.0)))
5.1.2 LabeledPoint
LabeledPoint主要用于监督学习,即为一个LocalVector配上一个label。
label为Double类型的:
- 回归问题为任意double值
- 二分类只能是0或1
- 多分类为0,1,2,,,
举例:
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.regression.LabeledPoint
// Create a labeled point with a positive label and a dense feature vector.
val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
// Create a labeled point with a negative label and a sparse feature vector.
val neg = La beledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
