@Dounm
2018-08-26T03:16:55.000000Z
字数 17484
阅读 12391
LDA算法理解
Blog MachineLearning
1 LDA(Latent Dirichlet Allocation)概述
隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)算法由David Blei, Andrew Ng, Jordan Michaell于2003年提出,是一种主题模型。
作用是:将文档集中每篇文档的主题以概率分布的形式给出。
在获得了每篇文档上的隐含主题的概率分布后,我们就可以根据主题分布对文本进行处理(例如主题聚类和文本分类)。
其中一篇文档可以包含多个主题,文档中的每个词都由其中的某个主题生成。
1.1 基本术语解释
| 名词 | 含义 |
|---|---|
| 文档Document | 非传统意义上的文档。LDA是词袋(bag of words)模型。将文档看作是是一组词,词与词之间没有先后顺序。 |
| 文档集(设共有M个文档) | 训练集中所有文档的集合 |
| 词word | 英文中即一个单词,中文中即独立意义的中文词 |
| 词表(设共有V个词) | 文档集中所有出现过的词的集合(不重复)。 |
| 主题Topic | 一个主题表现为该主题相关的一些词的集合,我们可以用V维的词表向量来表示主题k。向量的第i个元素表示的就是word i在该主题k下的概率,不出现在该主题k的词值就为0。向量的所有元素取值纸盒为1。 |
| 主题分布(设共有K个主题) | 对于一篇文档而言,LDA认为其包含了多个主题。举例而言,对于某文档而言,主题1占20%的可能,主题2占50%的可能等等。主题分布即K个主题在文档上的分布 |
1.2 LDA的目的(一)
LDA的使用情景是:
对于一个文档集,我要在文档集中提取出K个主题来(K大小可以随意指定),
然后我想知道文档集中每篇文档在相对于这K个主题的主题分布,从而根据这些主题分布来对文档集中的文档进行一些处理(求解文本之间的相似度,对文本自动打标签)。
为了完成这个目标:
1. 我们首先得确定这K个主题都是啥(即这K个主题对应的V维词表向量分布)
2. 然后得确定这K个主题在每个文档上的主体分布(即M个文档对应的K维主题分布)
所以LDA的程序最终需要求解出的结果即为两个矩阵:
| 矩阵符号 | 维度 | 含义 |
|---|---|---|
| 代表的篇文档,每篇文档上的主题分布。代表的是第i篇文档上的主题向量。 | ||
| 代表个主题,每个主题上的词频。代表的是第k个主题上的词表向量 |
2 数学基础
LDA从生成模型的角度来看待文档和话题。
举例而言,通常人类写文章的步骤如下:
- 选择一些与该文章相关的主题,例如军事和农业
- 然后基于选定的主题遣词造句等等。
在LDA模型中,一篇文档生成的方式如下:
- 从狄利克雷分布中取样生成文档的主题分布
- 从狄利克雷分布中取样生成主题的词表分布
- 对于文档i中的每个单词位置来说,执行下列操作:
- 从主题的多项式分布 中取样生成文档的第个词的主题
- 从词语的多项式分布采样生成最终词语
2.1 多项式分布Multinomial Distribuition
注意上面所描写的文档的生成方式中,暗示了无论是主题分布还是词表分布 其形式都是多项式分布。
多项式分布定义如下:
设为某一试验的完备事件群,即事件两两互斥,其和为完备事件群。
其中的概率分别是。
将该事件独立地重复N次,以记为这N次试验中事件出现的次数,则是一个维随机向量(的取值范围为都是非负整数,且和为)。
多维随机变量的概率分布即为多项分布:
我们来就多项式分布的定义分析下主体分布和词表分布:
| 多项式分布定义 | 主题分布 | 词表分布 |
|---|---|---|
| 基本事件 | 对于当前文档的某个空白位置选择主题 | 对于当前文档的某个空白位置,在该空白位置主题已定的情况下,选择该空白位置填充词 |
| 基本事件的执行次数 | 当前文档空白位置的个数 | 当前文档被分配给主题k的空白位置的个数 |
| 完备事件群 | 个主题构成完备事件群 | 个词构成完备事件群 |
| 多维随机变量 | 。:当前文档的空白位置中,分配给的空白位置的个数 | 。:当前文档的空白位置中,分配给的空白位置中,的个数 |
| (设当前文档有个空白位置) | (设当前文档被分配给主题的空白位置的个数为) |
注意:对于LDA而言,我们最终所要求的两个矩阵,就是由主题分布和词表分布两个多项式分布的参数的参数构成。
所以,我们要求的就是多项式分布的参数。
2.2 Gamma函数
普通的阶乘仅适用于正整数域,而Gamma函数即为阶乘的一般形式,将阶乘拓展到正实数域。
Gamma函数形式:
Gamma函数具有如下性质:
Gamma函数是定义在实数域上的阶乘运算,将阶乘这个操作从离散扩展到了连续。
任何用到离散阶乘的地方,都可以借助Gamma函数将概念从离散扩展到连续。
2.3 二项分布与Beta分布
2.3.1 二项分布
二项分布即是重复了次的伯努利分布,其概率密度函数为
注意:二项式分布是离散概率分布,并且其中也出现了阶乘。
2.3.2 Beta分布
Beta分布,指的是定义在区间上的连续概率分布,他有两个参数和。
其概率密度函数如下所示:
对于上式而言,我们观察可以得出,分母部分是一个归一化参数。因为对于连续概率分布而言,其概率密度函数必然要保证在定义域内的基本为1(否则不能称之为概率密度函数)。
因此,我们可以假设Beta分布其实是我们为了某个目的认为构造出来的概率分布(仅为了帮助理解):
我们先构造了Beta分布概率密度函数的一部分,即分子。然后为了使得概率密度函数积分为1,给概率密度函数添加了一个分母。
上面公式通常会写作以下形式,即将分母部分利用来显示:
注意,我们可以证明[1]。
对比一下二项式分布和Beta分布,我们可以发现他们的概率密度函数在剔除掉系数之后很相似。而且二项式分布的系数是,带有阶乘;Beta分布的系数是,带有Gamma函数。
因此,这其实就相当于二项式分布借由Gamma函数从离散扩充到了连续。
2.3.3 Beta分布的期望
如果,则
对于式子而言,我们联想到的概率密度函数为
将上式带回到中,并根据函数的性质可得
因此,Beta分布的均值就可以用来估计。
2.3.4 多项式分布与狄利克雷分布
对比一下上述所提到的四个分布,如下表所示
| 分布名称 | 概率密度函数 | 参数 |
|---|---|---|
| 二项分布 | 参数为和,参数约束为: | |
| 多项分布 | 参数为,参数约束为: | |
| 分布 | ,其中 |
参数为和 |
| 分布 | 其中, |
参数为 |
由上述表格内容可以看出:
- 多项分布是二项分布在多维变量上的推广
- 分布式分布在多维变量上的推广
2.3.5 Dirichlet分布的期望
参见Beta分布的期望,因为分布是Beta分布在多维变量的推广,所以我们可以得出如下结论(证明参考Beta分布的期望证明,略):
2.4 共轭先验分布
2.4.1 贝叶斯定理
这个公式中:表示参数,是已观测到的数据。
- :后验概率,在已经观测到了数据的情况下,参数为的概率。
- :先验概率,在没有观测到数据x的情况下,参数为的概率。
- :似然函数,参数为的情况下,产生观测数据为的概率。
- :归一化常数,通常不会直接求,而是忽略掉,最后利用归一化(概率密度函数积分必须为1)来处理,例如上式中所示。
由贝叶斯定理可知,后验分布似然函数*先验分布。
而共轭先验分布的定义如下:
如果先验分布和似然函数可以使得先验分布和后验分布具有相同的形式,则称先验分布是似然函数的共轭先验分布
2.4.2 Beta分布是二项式分布的共轭先验分布
因为多项式分布和分布式二项式分布和分布的多维推广,所以我们在此只证明分布式二项分布的共轭先验分布。
要证明分布式二项分布的共轭先验分布,则根据共轭先验分布的定义,似然函数是二项分布的形式,先验分布是分布的形式,我们想要让后验分布也是分布的形式。
证明:
1. 似然函数是二项分布,即为二项分布的参数,似然函数即为
2. 先验分布是分布,即是分布以和为参数的结果,先验分布即为
3. 根据后验分布似然函数*先验分布可得:
因此,我们会发现后验分布也是Beta分布。
而且先验分布是,后验分布则是。
超参数和在基于观测到的数据和后发生了改变,变成了和,但形式上仍然是分布。
如果以后再有新的数据的话,我们仍然可以在了和的基础上继续更新超参数。
2.4.3 Dirichlet分布是多项式分布的共轭先验分布
先验分布是,后验分布就变成了。
注意:
- :多项式分布的参数,同时也是分布的结果/随机变量。
- :分布的参数。
- :观测到的数据。第维代表事件发生的次数(如果将分布看做是二维的分布的话,那么)。
这三个向量维度相同。
2.5 LDA的目的(二)
我们在LDA的目的(一)中提到,LDA目的最终要求出的是两个矩和,这两个矩阵又都是多项式分布的参数。而根据共轭先验分布,多项式分布的参数即为分布的结果/随机变量,因此我们可以用分布随机变量的期望来估计多项式分布的参数。
结合上面所提到的,分布的期望公式如下:
根据共轭先验分布的结论,分布的参数有最开始的变成了,其中是我们预先设定好的参数,则是训练数据中隶属于每个主题词的个数(如果将分布看做是二维的分布的话,为二维,值分别是)。因此我们只需要识别出对于文档中的每个词来说,该词属于哪个隐含主题,然后就可以按照上述公式来计算出来两个矩阵。
因此,我们所要求解的就是,即文档集中的每个词背后所隐含的主题。
注意:是文档集中的词向量,是文档集中与词向量所对应的每个主题值。
举例而言,如果对于文档集,只有一个文档,该文档分词后有5个词,"aaa bbb ccc ddd aaa"。
然后我们要从文档集中提取出来3个主题。
词"aaa"被赋予的隐含主题为,词"bbb"被赋予的隐含主题为,词"ccc"被赋予的隐含主题维,词"ddd"被赋予的隐含主题为。
则。
和的维度都是整个文档集中词的个数(重复词不合并)。
根据条件概率公式
但是对于该公式而言,对其分母利用离散概率分布求解边缘概率的方法进行展开。
其中是文档集中所有词的个数,也即为和的维度(对于前面所举出的文档集的例子,),是索要提取出的隐含主题的个数(前面例子中)。
因此对于分母而言,其计算量高达,难以计算。
所以我们采用Gibbs Sampling的方法来计算。
3 Gibbs Sampling吉布斯采样
吉布斯采样是马尔科夫链蒙特卡罗法(Markov Chain Monte Carlo, MCMC)的一种。
3.1 Monte Carlo蒙特卡罗法
蒙特卡罗法即通过模拟采样的方式来让你获得想要的值。
举个例子,在一个正方形内,以正方形的中心为原点,边长为直径画一个圆(即正方形的内切圆)。
向正方形内均匀撒米,那么按道理来说圆内的米粒C与正方形内的米粒S满足:
因此对于参数来说,我们可以用来对它进行估计。
3.2 Markov Chain马尔科夫链
马尔科夫链即根据转移矩阵去转移的随机过程(马尔科夫过程)。
如下图就是一个典型的马尔科夫过程
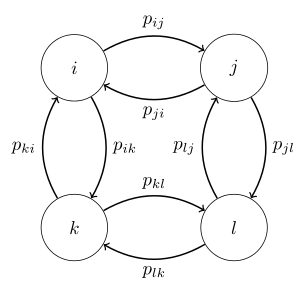
该状态转移图的转移矩阵如下图所示:
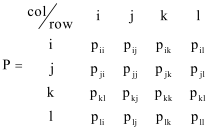
其中,表示的马尔科夫链上的状态。表示从状态到状态转移的可能性。
现在利用向量表示当前所处的状态。开始的时候表示最开始处于状态。
那么下一次转移后变为,此处向量其实就是第一次转移之后的状态分布,即有的概率身处状态,有的概率身处状态。
3.2.1 平稳状态分布Stationary Distribution
有一种情况,即向量在经过大量的转移后达到一个稳定状态,之后即使再怎么转移的值也不会改变了。此时即成为平稳状态分布。(如果在平稳状态下我们继续在马尔科夫链中转移次,那么即次转移中位于状态的次数为)。
要达到这个平稳状态分布需要满足一些条件,即(也即,这两个条件等价)。
举例而言,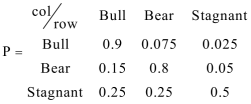
如果初始状态的话,在多次乘以转移矩阵之后,最终等于。这也就意味着如果我们在收敛后继续转移状态的话,我们10000次转移,大约有6250次位于Bull状态,3125次位于Bear状态,625词位于Stagnant状态。
其实就是一个概率分布,而我们构造出某个马尔科夫链(即转移矩阵)使得收敛到平稳状态分布后采样出来的结果满足这个概率分布。
因此如果我们想求某个概率分布的话,我们就可以构造一个马尔科夫链来使得最终平稳状态分布就是概率分布,从而在无需明显求出表达式的情况下获取其采样结果。
3.3 Metropolis-Hasting算法
MH算法目的:根据一个需求的概率分布生成(采样)一系列的样本状态点。
为达到这一目的,MH算法通过构造马尔科夫链来使得该马尔科夫链最终的平稳分布为,然后再进行采样即可。
对于平稳状态分布的条件而言:
将转移概率分解为建议概率和接受概率,即。建议概率是我们给出状态后转移到状态的条件概率,而接受概率则是接受状态的条件概率。
则整理可得,
这样我们得到了接受率,代表的含义是:从状态到状态的接受概率与从状态到状态的接受概率的比率。对于来说,如果它大于1,就寿命下次要转移的状态X'比当前状态Xi可能性更大,那么我们就按照建议概率所建议的,转移到。如果它不大于1,例如为0.7,那么我们就有0.7的概率接受建议概率的建议转移到,有0.3的概率拒绝建议概率的建议仍然留在处。
所以最终的话,我们倾向于留在高概率密度的地方,然后仅偶尔跑到低概率状态的地方(这也就是MH算法直观上的运行机理)。
MH算法将接受率添加了个上界1,得到如下的公式:
因此,MH算法的步骤为:
1. 选择任意一个状态点作为初始状态。
2. 选择任意一个概率分布作为建议概率(建议概率是条件概率,而且必须满足。通常会选择以点为中心的正态分布)
3. 根据生成下次状态点,计算接受率
4. 如果,则说明比更有可能,因此就接受这次转移,下次状态点的状态就是X'
5. 如果,则以的概率接受这次转移。
6. 继续循环3-5步即可。
3.4 Gibbs Sampling算法
MH默认的流程是任意选择转移概率,然后利用接受率来使得采样最终收敛于。但是如果我选择足够好的,使得每次发出的建议都是符合分布的建议,那么我就一直接受就行了(此时即接受率恒为1)。Gibbs Sampling采用的就是这种方式。
对于多维随机变量的概率分布而言,选择完全条件概率full conditionals 作为建议概率,
此时可以证明的是接受率恒等于1,即每次发出建议都是符合联合概率分布的,因此我们只需要一直接受建议即可。
证明如下:

所以,对于多维随机变量的概率分布而言,一旦其完全条件概率full conditionals 可用,则可以采用维向量轮流每个维度循环的方式来迭代达到平衡。

3.5 LDA模型的Gibbs Sampling应用
由2.5节可知,LDA模型所要计算的是。
其中是文档集中的单词,是已知的可观测变量,所以我们把它当做已知值,则LDA想要的概率分布就是。而又因为是多维随机变量,结合前面Gibbs Sampling的思想,所以我们选取其完全条件概率作为马尔科夫链的转移概率。此时考虑的因素,所以我们要用作为转移概率。
3.5.1 整个文本训练集生成的联合概率
要得到完全条件概率,我们必须得到整个文本集生成的联合概率分布。
即
我们将两个因子分开处理。
对于第一项因子来说,先考虑(先不考虑的因素,将看做常数),则
注意是文档集中的所有词的个数(并非词表中的词个数),是文档集中的词向量,是文档集中与词向量所对应的每个主题值。
我们将这一项分解成两个连乘,一个相对于词表,一个相对于topic。
首先,对于topic确定的情况下,。表示的是整个文档集中隶属于topic k的词t的个数。
又因为同一个词可能被不同的topic生成(只是生成的概率不同而已,例如topic "农业"生成词"小麦"的概率可能为0.5,但topic“军事”生成词"小麦"的概率就可能只是0.01),那么我们在添上对于topic的连乘,即
所以
而
所以
所以
其中。
对于因子2来说,同理可得:
同样积分可得:
其中
所以,文档集中生成的联合分布为
3.5.2 Collapsed Gibbs Sampling公式
为清晰起见我们更改下联合分布式子的符号表示,将改为。则
其中:
- ,表示的是整个文档集中隶属于topic k的词t的个数。
- ,表示的是第m个文档中属于第k个主题的词的个数。
我们所要求的完全条件概率如下:
注意,对于这个公式而言,
- 因为当前仅处理文档集中的第个单词(若该单词位于第篇文档,且其隐含主题为第个主题,该单词是词表中的第个词),因此与和无关的均被视为常数忽略,因此消去了符号。
- 而分母的也由于分子分母都有而消去了。
则因此
首先我们来看第一个因子的分母部分,
上面公式中,V为字典中词的个数。
同理,分子部分的话,
因此,第一个因子即如下:
同理,第二个因子为:
所以,最终我们得到了如下结果:
其中,
- 即,表示第k个topic的第i个单词个数-1
- 即,表示第m个文档的第k个主题词数-1
3.5.3 计算隐含主题的概率分布
上一节中我们已经的出来采样公式,所以在多次循环采样后,我们就能得到文档集中的每个词的主题赋值。
然后根据2.5节LDA的目的(二)所说,知道了每个词的主题,我们利用Dirichlet分布的期望公式,就可以得到隐含主题的两个概率分布矩阵和了。
则第m篇文章的第k个主题:
同理,
第k个主题的第w个词:
到此为止,LDA算法的所要达到的目的我们已经获取到了,LDA算法的大致流程也已经都写了下来。另外,LDA的计算方法除了Gibbs Sampling之外还有一种方法是变分贝叶斯,大家有兴趣可以去了解一下思想。
4 参考资料
- LDA漫游指南-马晨
- Gibbs Sampling for the Uninitiated
- 通俗理解LDA主题模型
- 机器学习-周志华
- Metropolis-Hasting algorithm-Wikipedia
- Introduction to Stationary Distribution
- Probabilistic Topic Models
