@Dounm
2018-12-11T03:15:40.000000Z
字数 5722
阅读 4351
CUDA程序调优指南(一):GPU硬件
1. GPU的硬件结构与执行原理
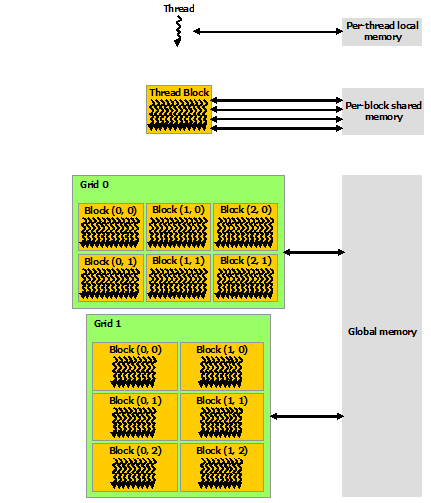
1.1 GPU Thread的层次
在逻辑上,threads分为如下三个层次:
- thread:每个thread都会运行一次kernel function,threads之间平等无优先级。
- block:一组线程,通常放在SM上执行。
- grid:一组blocks。通常一次kernel function调用的所有thread都放在一个grid中。
而在硬件上,threads仅有两个层次:
- core:真正执行一个thread的硬件
- warp:硬件上并行执行的32个线程,同一warp的thread执行同一条指令
1.2 Streaming Multiprocessor
GPU由多个multithreaded Streaming Multiprocessos(SMs)构成。以1080显卡为例(Compute Capability 6.1)为例,其有20个SM。每个SM包括128个CUDA cores和4个warp scheduler。
当要执行一个kernel grid时,该grid中的blocks会被分配给可用的SM。
一个block中的所有threads都是【并发的,concurrently】在一个SM上执行的
多个block的threads也可以并发的在一个SM上执行
如果一个block执行完毕,那么新的block会被放到空出来的SM上执行。
SM的设计目的时并发执行几百个线程,因此使用了**SIMT, Single Instruction Multi Thread **的架构。
在SM内部有两种级别的并行:
- 指令级别:单线程(单core)内部的instruction-level parallelism。(芯片内部的指令流水线)。
- 线程级别:硬件上的多个core的thread-level parallelism(通过硬件上的多线程)
1.3 SIMT:Single Instruction Multi Thread
在SM内部,threads以warp为单位被创建/管理/调度和执行,每个warp包括32个threads。
当将一个或多个blocks分配给SM时,它会首先将其分成多个warp。(每个warp所包含的thread都是按threadID有序递增的),然后使用warp scheduler来调度执行每个warp。
一个warp内的32个threads在同一时间执行同一条指令,所以当32个thread的执行路径完全一致时效率最高。
如果有data-dependent的分支,那么warp会分别执行每一个分支路径,不在当前分支的threads会被停用。
1.4 Hardward Multithreading
每个warp的执行上下文execution context(program counters, registers, etc.)在整个生命周期里都是被保存在on-chip mem上的。
因此从一个execution context切换到另一个execution context是无消耗的,在每个instruction issue time里,一个warp scheduler都会选择一个warp,该warp中的threads需要做好准备执行下个instruction,然后给向这个warp里的threads发出指令。
具体而言,每个Multiprocessor都有
- 一组32-bit registers(按照warp数来分配)
- 一个【parallel data cache/shared memory】(按照thread blocks数来分配)
这两个条件就决定了一个SM上能同时【并发的】存在多少个warps和blocks。(同时也有最大值限制)
如果一个block需要的registers/shared mems都无法满足,那么kernel就会失败。
更细节一些,即在每个instruction issue time,一个warp scheduler都会选择一个准备好的warp发出指令。等待warp准备好的这段时间(number of clock cycles)就是【latency】。要达到完全的利用率,就需要所有的warp scheduler在latency这段时间的每个clock cycles都可以发出指令给其他warp,即掩盖掉latency。
因此,一个SM内越多的warp通常就会带来越高的利用率,性能越高。(后续会详细讨论)
2. GPU的内存层次Memory Hierarchy
在了解GPU的内存层次之前,我们先了解下如下术语:
| 术语 | 解释 |
|---|---|
| Cache Line | 每次读或写内存时,即使只操作一个值,也是会把一小块内存读取到Cache里的。这一小块被读取到Cache的内存就叫【Cache Line】,其大小称之为【Cache Line Size】 |
| Memory Transaction | a transaction is the movement of a unit of data between two regions of memory。例如,从Mem到L2 Cache的一次拷贝就是一次Mem Transaction。 |
| Register Spilling | 某些应该放到register的变量,由于register不够大,而放到了mem中(GPU中是放在Local Mem) |
| Natrually Aligned | any item is aligned to at least a multiple of its own size。例如4Byte的对象的地址必须能整除4;8Byte的对象的地址必须能整除8 |
粗略来看,GPU的内存层次如下
2.1 Global Memory
Global Memory就是我们在书写CUDA程序时最常使用的内存,cudaMemcpy也是从CPU 内存拷贝到Global Memory。
Global Mem能被所有thread访问,其在GPU的位置和Cache如下:
- 位置:device memory
- Cache:L1/L2
2.1.1 device memory
device memory并非位于SM内部,而是由所有SM共享。因此访问速度较慢,需要Cache缓存加速。
除此之外,device memory必须通过32/64/128-byte的【memory transaction】访问,并且要求这些memory transaction是aligned to their size。
举例而言,即读取32-byte的memory transaction时,地址必须是32的倍数;读取64-byte的mem transaction时,地址必须是64的倍数
当一个warp执行指令(load/store)来访问Global mem时,它会根据【每个thread访问的word的大小】和【每个thread访问的地址关系】来把该访存指令聚合成一个或多个memory transaction。
举例而言,如果每个thread访问4byte的word,则一个warp(32个thread)就需要访问32*4=128byte的内存。
- 如果这32个word时连续且对齐的,那么只需要 一个128-byte memory transaction 或 四个32-byte mem transaction即可。
- 如果连续,但起始地址并未对齐128byte,那么需要 两个128-byte memory transaction 或 五个32-byte mem transaction。
- 如果不连续,那么SM会将能放在一个128-byte mem transaction的thread的访存操作聚合成一个128-byte mem transaction,因此会产生多个128-byte memory transaction。(32-byte mem trans同理)
针对于每个thread所读取的word,若word size是1/2/4/8/16 byte,且是https://d.docs.live.net/606463c833bea118/Documents/Distribute%20Computing/GPU.one">Naturally Aligned,则会被编译成一个memory instruction。(后续同一个warp的memory instruction会进行聚合)
如果不满足size和alignment的条件,那么当前thread的该次mem access就会被编译为多个mem instruction,因此变慢。
2.1.2 L1/L2 Cache
Global Memory的读取会被缓存到L2(有时也会缓存到const cache),通过可配置选项可以选择是否缓存到L1。
如果Mem Access同时缓存在L1/L2上,那么是通过128-byte mem transaction来实现的
如果Mem Access仅缓存在L2上,那么是通过32-byte mem transaction来实现的
(因此,仅缓存在L2对分散的内存读取有好处,可以减少over-fetch)
即,L1的Cache Line Size = 128 byte,L2的Cache Line Size = 32 byte。所以当L1/L2共存时,取最大的Cache Line Size。
L2 Cache有如下特点:
所有的SM共享一个L2 Cache
用来缓存对global/local memory的读取。
- 有时也会用来处理https://d.docs.live.net/606463c833bea118/Documents/Distribute%20Computing/GPU.one">Register Spilling
(可以通过device property中的l2CacheSize来查看其大小)
2.2 Local Memory
每个thread都拥有自己私有的local memory,负责存储一些局部变量(automatic variable)。
对于局部变量而说,一些小型的局部变量会被放到register里,当register不够用时,则会被放到Local Mem中。
Local Mem的位置和Cache如下:
- 位置:device memory
- Cache:L1/L2
由于local mem也是放在device memory上,所以其和global mem很像。即access latency和bandwidth都和global mem一样低,一些内存对齐的约束也得满足。
有一点local mem独有的优化是:如果warp内的threads同时访问相同的local mem里的relative address(e.g. same index in an array variable, same member in a structure variable),memory access are fully coalesced。
这应该和Local Mem在device memory的排列相关。
2.3 Shared Memory
shared memory位于thread block这一层,即每个block共享一块shared mem,这块shared mem对该block内的所有threads可见,且当该block执行结束时,其所占用的shared mem也会被释放。
shared mem的位置和cache如下:
- 位置:on-chip memory
- cache:无,因为是on-chip的,读取速度够快不需要cache
shared mem本身位于芯片上,所以读取速度很快,可以作为software-managed cache来加速的执行。
L1/L2 cache上存储什么数据无法由程序来直接控制,但我们可以控制shared mem上存储什么数据。
在硬件上,shared memory 被分成32(对应warp中的thread个数)个相等大小的【bank 内存块】。
- 每个bank的带宽是32 bits per clock cycle
- 连续的32-bit words是放在连续的32个banks中
这32个内存块们可以同时被访问:
若32个thread各自访问32个bank的word,就只需要一次内存传输就行。
若不同thread访问同一个bank的不同32-bit word,就产生了【bank conflict】,access就会被序列化,需要多次内存传输。
若不同thread访问同一个bank的相同word,不会产生bank conflict,仅需要一次内存传输,此时触发【broadcast】,word会被广播给多个thread。
关于shared memory的32个bank的图示见H.4.3. Shared Memory
2.4 Constant Memory
Constant Memory,顾名思义是用来存储只读数据的内存。
此处的【只读】针对的是device code的只读,我们可以通过Host向Constant Memory写入数据(通过cudaMemcpyToSymbol()的接口),然后在device code中读取。
常见的Constant Memory大小为64KB,其位置和Cache如下:
- 位置:device memory
- Cache:constant cache(比L1/L2快)
2.5 Register
Register位于SM上,每个SM都有固定数目的一组threads。每个thread使用的register越少,就有越多的block/threads可以并发的位于同一SM上,进而提高性能。
每个thread使用的register的数目由编译器【启发式】的决定。但我们也可以通过Launch Bounds提供一些信息协助编译器更好的决定。
