@zero1036
2019-03-25T10:41:35.000000Z
字数 4640
阅读 1723
Mysql事务与锁
Mysql
事务满足4大条件
首先,最重要是事务用来管理 insert,update,delete 语句
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
执行事务方法
console
1、用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT=0 禁止自动提交
- SET AUTOCOMMIT=1 开启自动提交
@Trans显式指定事务隔离级别
注意事项:
- 需要调用spring容器中bean对象中的方法,事务注解才能生效
- 需要显式指定
rollbackFor需要捕获Exception,否则如果抛出Exception可能不会触发回滚 - 异常情况下,建议显式回滚
@Transactional(propagation = Propagation.REQUIRES_NEW,rollbackFor = Exception.class, isolation = Isolation.READ_COMMITTED)public void fn(){var ok = mapper.update();if(!ok){//显式回滚TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();}}
显式回滚语句:TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
事务隔离级别
事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)(mysql默认级别)和串行化(Serializable)。
- read uncommitted : 读取尚未提交的数据 :哪个问题都不能解决
- read committed:读取已经提交的数据 :可以解决脏读 ---- oracle、sqlserver默认的
- repeatable read:重读读取:可以解决脏读 和 不可重复读 ---mysql默认的
- serializable:串行化:可以解决 脏读 不可重复读 和 虚读---相当于锁表
查询全局和会话事务级别
你可以用下列语句查询全局和会话事务隔离级别:
SELECT @@global.tx_isolation;SELECT @@session.tx_isolation;SELECT @@tx_isolation;
设置事务隔离级别:
set session transaction isolation level read uncommitted;set session transaction isolation level read committed;set session transaction isolation level repeatable;set session transaction isolation level serializable;
锁的类型
| 锁类型 | 描述 | 粒度 |
|---|---|---|
| 共享锁(S Lock) | 允许事务读一行数据 | 行锁 |
| 排他锁(X Lock) | 允许事务删除或更新一行数据 | 行锁 |
| 意向共享锁(IS Lock) | 事务想要获得一张表中某几行的共享锁 | 表锁 |
| 意向排他锁(IX Lock) | 事务想要获得一张表中某几行的排他锁 | 表锁 |
兼容性:列为已有所,行为期望获得锁
| 。 | IS | IX | S | X |
|---|---|---|---|---|
| IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 不兼容 | 兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 兼容 | 不兼容 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
查看锁情况
命令show engine innodb status查看当前锁情况
Innodb 1.0版本以后,建议通过information_schema架构下的表查询事务与锁的状态:information_schema innodb详解
- INNODB_TRX
- INNODB_LOCKS
- INNODB_LOCK_WAITS
共享锁与排他锁
如果一个事务T1已经获取的行r的共享锁,那么另外的事务T2可以立即获得行r的共享锁,因为读取并没有改变行r的数据,称为锁兼容。但若其他事务T3想获得行r的排他锁,则必须等待T1、T2释放行上的共享锁。
select语句的上锁方式:
| 语句 | 锁类型 | amount |
|---|---|---|
| select | 没有上锁 | |
| select ... for update | 排他锁(X LOCK) | Mysql会对查询结果中的每行都加排他锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请排他锁,否则会被阻塞。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁。行级锁的缺点是:由于需要请求大量的锁资源,所以速度慢,内存消耗大! |
| select ... lock in share mode; | 共享锁(S LOCK) | Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。 |
意向锁
意向锁:若将上锁的对象看成一棵树,那么对最下层的对象(粒度最小的行锁)上锁,首先需要对粗粒度的对象上锁。形成一个从上至下的上锁流程。设计目的是为了在一个事务中揭示下一行将被请求的锁类型。
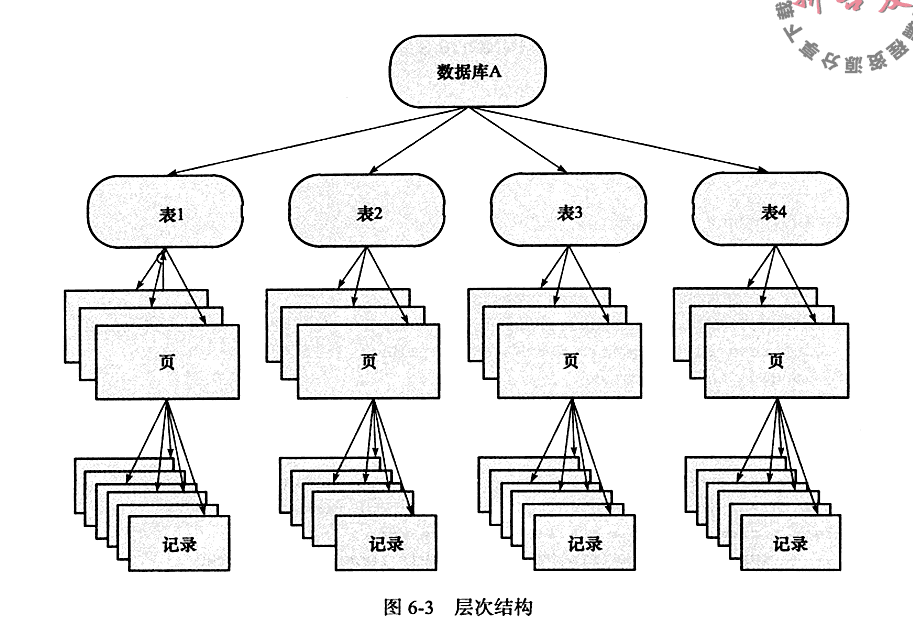
如果需要对页上的记录r上X锁,那么分别需要对数据库A、表、页上意向锁IX,最后对记录r上X锁。如果任何一个部分导致等待,那么该操作需要等待粗粒度锁的完成。
| A会话 | B会话 |
|---|---|
| 对表T的行r上S锁 | |
| 计划对行r上X锁 | |
| 先对表T上IX锁 | |
| IX与S不兼容,阻塞 |
行锁的算法
- Record Lock:单个记录上的锁
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
- NextKey Lock:Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身
NextKey Lock降级为Record Lock的3种场景
1、查询条件命中唯一索引,NextKey Lock会自动降级为Record Lock
| A会话 | B会话 |
|---|---|
| select * from account where id = 5 for update | |
| insert into account (id, name ,amount) values (4,'tgtg',300); 不会阻塞 |
在会话A中,首先对id=5进行X锁定,由于id是主键且唯一,因此锁定的仅是5这个值,而不是(2, 5)这个范围;
2、
gap lock场景
一致性非锁定读
一致性的非锁定读是指InnoDB存储引擎通过行多版本控制(multi versioning)的方式来读取当前执行时间数据库中的行数据。如果读取的行正在执行Delete或Update操作,这是读取操作不会因此去等待行上锁的释放。相反,InnoDB存储引擎会去读取行的一个快照数据。
快照数据本身是没有额外的开销。同时,读取快照数据是不需要上锁的,因为没有事务需要对历史数据进行修改操作。
隔离级别Read Commited和Repeatable read下,InnoDB存储引擎使用非锁定的一致性读,但读取的快照数据不同。
- Read Commited:非一致性读总是读取被锁定行的最新一份快照数据
- Repeatable read:非一致性读总是读取事务开始时的行数据版本
repeatable read示例
| A会话 | B会话 |
|---|---|
| begin; | |
| select * from account; ## amount = 100 | |
| begin; | |
| update account set amount = 200 where amount = 100; | |
| commit; | |
| select * from account; ## amount = 100 | |
| commit; |
read commited示例
| A会话 | B会话 |
|---|---|
| begin; | |
| select * from account; ## amount = 100 | |
| begin; | |
| update account set amount = 200 where amount = 100; | |
| commit; | |
| select * from account; ## amount = 200 | |
| commit; |
一致性锁定读
用户需要显示地对数据库读取操作进行加锁以保证数据逻辑的一致性。要求数据库支持加锁语句。
select语句支持两种一致性锁定读(locking reading):
select ... for update;
select ... lock in share mode;
insert语句支持:
insert ... xxx select xxxx;
locking reading两者区别:
| 语句 | 锁类型 | amount |
|---|---|---|
| select ... for update | 排他锁(X LOCK) | Mysql会对查询结果中的每行都加排他锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请排他锁,否则会被阻塞。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁。行级锁的缺点是:由于需要请求大量的锁资源,所以速度慢,内存消耗大! |
| select ... lock in share mode; | 共享锁(S LOCK) | Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。 |
外键与锁
对于外键值的插入与更新,首先需要查询父表的select操作,要求使用一致性锁定读。
如下例子,有主表account及其子表account_detail
account
| id | name | amount |
|---|---|---|
| 1 | tg | 600.00 |
| 2 | mark | 200.00 |
account_detail
| id | account_id |
|---|---|
| 1 | 1 |
会话执行:
| A会话 | B会话 |
|---|---|
| begin; | |
| delete from account where id = 2; | |
| begin; | |
| insert account_detail (account_id) (select id from account where id = 2); | |
| 堵塞 |
根据以上例子,B会话执行insert时会堵塞,因为会话A获得X锁,insert select为一致性读,无法获取与X不兼容的S锁。设想,如果外表的插入结果,是通过一致性非锁定读的读取结果,会出现数据不一致的情况。
| A会话 | B会话 |
|---|---|
| begin; | |
| delete from account where id = 2; | |
| begin; | |
| select id = @accountId from account where id = 2; | |
| insert account_detail (account_id) value (@accountId); | |
| commit; | |
| commit; |
结果:account表中,id = 2的记录已被删除,但子表account_id = 2的记录却并被插入。
