@wxf
2019-08-24T13:37:44.000000Z
字数 7248
阅读 1566
Redis相关问题整理
面试系列
Redis 特点
1. 高速读写,所有数据存储在内存中
2. 提供丰富多样的数据类型:string、hash、list、set、sorted set、bitmap、hyperloglog
3. 提供了AOF和ROB两种数据持久化方式,保证Redis重启后数据不丢失
4. Redis的所有操作都是原子性的,还支持对几个操作合并后的原子性操作,支持事务
Redis常用数据类型及其应用场景
string数据类型的应用场景
- 简介
string类型是Redis中最基本的数据类型,最常用的数据类型。string类型在Redis中是二进制安全的,这意味着该类型可以接受任何格式的数据,如图像数据或Json对象描述信息等。string类型的value最多可容纳的数据长度为512M。
数据模型
string类型是基本的Key-Value结构,Key是某个数据在Redis中的唯一标识,Value是具体的数据。
Key Value 'name' 'redis' 'type' 'string' 应用场景
存储MySql中某个字段的值
把 key 设计为表名:主键名:主键值:字段名
如:set user:id:1:name wangxf
存储对象
string类型支持任何格式的字符串,应用最多的就是存储json或者其他对象格式化的字符串。(这种场景推荐使用hash数据类型 )
如:set user:id:1 [{"id":1,"name":"wangxf"},{"id":2,"name":"fenglx"}]
生成自增id
当Redis的string类型的值为整数形式时,redis可以把它当做整数进行自增(incr)自减(decr)操作。由于所有的操作都是原子性的,所以不用担心多客户端连接时可能出现的事务问题。
- 常用命令
- 赋值取值:
set、get - 递增递减:
incr、incrby、decr、decrby - 尾部追加值:
append(返回值为追加后字符串的总长度) - 获取字符串的长度:
strlen - 设置多个K/V键值对:
mset、mget - 设置生存时间:
expire(设置)、ttl(获取) - 清除生存时间:
persist(注意:重新设置值也会清除生存时间)
- 赋值取值:
hash数据类型的应用场景
- 简介
hash类型很像一个关系型数据库的数据表,hash的Key是一个唯一值,Value部分是一个hashmap结构。
数据模型
假设有一张数据库表如下:id name type 1 redis hash 如果要使用Redis的hash结构存储,数据模型如下:
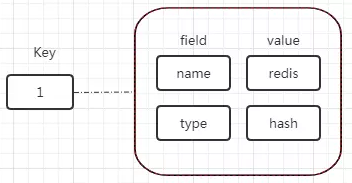
hash数据类型在存储上述数据时具有比string类型更灵活、更快的优势。应用场景
hash类型十分适合存储对象数据,相对于在string中介绍的把对象转化为json字符串存储,hash的结构可以任意添加或删除‘字段名’,更加高效灵活。
hset user:1 name wangxf phone 183***
常用命令
赋值获取:
hset、hget、hmset、hmget、hgetall如:hset user username zhangsan
hset命令不区分插入和更新操作,当执行插入操作时hset命令返回1,当执行更新操作时返回0。
- 判断字段是否存在:
hexists - 当字段不存在时赋值:
hsetnx(如果存在则不进行任何操作)
- 增加数字:
hincrby - 删除字段:
hdel - 只获取字段名或字段值:
hkeys、hvals - 获取字段数量:
hlen
- 增加数字:
list数据类型的应用场景
简介
list是按照插入顺序排序的字符串链表,可以在头部和尾部插入新元素(双向链表实现,两端添加元素的时间复杂度为O(1))。插入元素时,如果key不存在,redis会为该key创建一个新的链表,如果链表中所有的元素都被移除,该key也会从Redis中移除。
数据模型
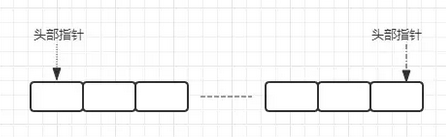
使用lpush命令在list头部插入元素,用rpop命令在list尾取出数据。应用场景
- 消息队列
Redis的list数据类型是实现队列服务最简单、最经济的方式。 - 实现"最新内容"功能
因为list结构的数据查询两端附近的数据性能非常好,所以适合一些需要获取最新数据的场景,比如新闻类应用的“最近新闻”。
- 消息队列
- 常用命令
set数据类型的应用场景
简介
- set数据类型是一个集合(没有排序,不重复),可以对set类型的数据进行添加、删除、判断是否存在等操作(时间复杂度是O(1))
- set集合不允许数据重复,如果添加的数据在set中已经存在,将只保留一份。
- set类型提供了多个set之间的聚合运算,如求交集、并集、补集,这些操作在redis内部完成,效率很高。
数据模型
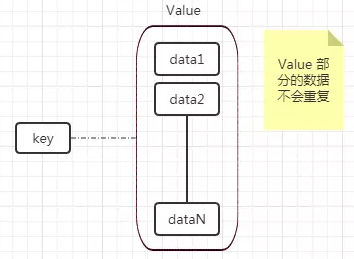
应用场景
set类型的特点是——不重复且无序的一组数据,并且具有丰富的计算功能,在一些特定的场景中可以高效的解决一般关系型数据库不方便做的工作。
- 实现"共同好友列表"功能
在社交类应用中,会有查找两个人或多个人的共同好友,两个人或多个人共同关注的微博等类似的功能。那么在Redis中使用set数据类型的取交集命令就可以搞定。
# 这里为了方便阅读,把 id 替换成姓名sadd user:wade james melo paul kobesadd user:james wade melo paul kobesadd user:paul wade james melo kobesadd user:melo wade james paul kobe# 获取 wade 和 james 的共同好友sinter user:wade user:james/* 输出:* 1) "kobe"* 2) "paul"* 3) "melo"*/
- 实现"共同好友列表"功能
- 常用命令
sorted set数据类型的应用场景
简介
在 set 的基础上给集合中每个元素关联了一个分数,往有序集合中插入数据时会自动根据这个分数排序。
应用场景
- 实现好友“亲密度”列表功能
在集合类型的场景上加入排序就是有序集合的应用场景了。比如根据好友的 “亲密度” 排序显示好友列表。
# 用元素的分数(score)表示与好友的亲密度zadd user:kobe 80 james 90 wade 85 melo 90 paul# 根据“亲密度”给好友排序zrevrange user:kobe 0 -1/*** 输出:* 1) "wade"* 2) "paul"* 3) "melo"* 4) "james"*/# 增加好友的亲密度zincrby user:kobe 15 james# 再次根据“亲密度”给好友排序zrevrange user:kobe 0 -1/*** 输出:* 1) "james"* 2) "wade"* 3) "paul"* 4) "melo"*/
- 实现好友“亲密度”列表功能
- 常用命令
【相关推荐】
Redis内存使用优化与存储
Redis复制与可扩展集群搭建
Redis 设计与实现
SpringSource发布Spring Data Redis 1.0.0
Redis内存存储结构分析
redis数据类型详解 以及 redis适用场景场合
Redis的五种存储类型和其应用场景
Redis 数据类型及应用场景呈现
Redis的那些最常见面试问题
Redis持久化
RDB方式
RDB方式是通过快照方式完成的。它是Redis的默认持久化方式。
AOF方式
它是将发送到Redis服务器端的每一条命令都记录下来,并且保存到硬盘中的AOF文件。
Redis主从复制(读写分离)
Redis主从复制环境搭建
主从复制的好处:
1. 避免redis单点故障
2. 构建读写分离架构,满足读多写少的应用场景
注意:因为是在一台机器上进行测试,这里的Redis主从复制架构实际上是安装一个Redis启动三个实例。
Redis有两种架构模式,分别是:主从架构、主从从架构
架构模型
架构模型 模型图 优缺点 主从架构 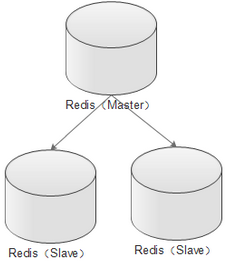
缺点:主Redis压力大,需要同步多个从Redis 主从从架构 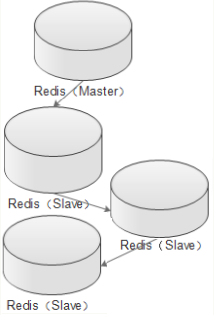
优点:主Redis同步压力小;可以将主Redis持久化工作交给从Redis 配置主从架构
- 启动三个redis实例

设置主从
在redis中设置主从有2种方式
在从Redis的redis.conf中设置slaveof
slaveof <masterip> <masterport>
使用redis-cli客户端连接到redis服务,执行slaveof命令。但是,该方式在redis重启后将失去主从复制关系
slaveof <masterip> <masterport>
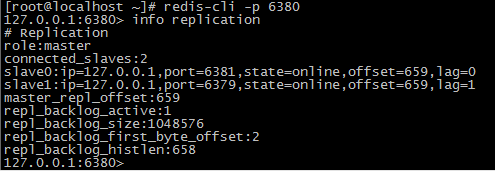
查看主从信息
命令:INFO replication
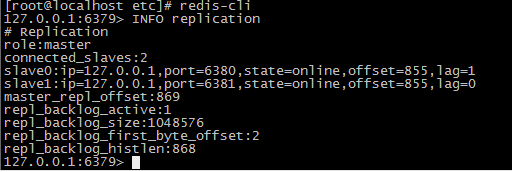
- 启动三个redis实例
- 配置主从从架构
- 启动三个redis实例
- 设置主的从
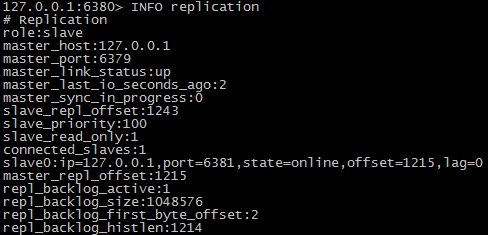
- 设置从的从
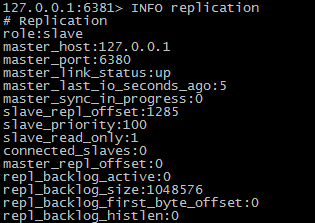
- 启动三个redis实例
Redis主从复制原理
- 当从Redis和主Redis建立Master-Slave关系后,从Redis会向主Redis发送同步命令(SYNC);
- 主Redis接收到同步命令后会开始在后台保存快照(RDB持久化过程),并将快照期间接收到的写命令缓存起来;
- 当快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis;
- 从Redis接收到后,会载入快照文件并且执行收到的主Redis缓存的命令;
- 之后,主库每当接收到写命令时都会将命令发送从Redis,从而保证数据的一致性。
当Redis主从结构中出现宕机时,该如何处理?
如果出现宕机情况需要分情况来看:
- 从Redis宕机
- 这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据;
- 疑问
问:如果从库在断开期间,主库的变化不大,从库再次启动后,主库依然会将所有的数据做RDB操作吗?还是增量更新?(从库有做持久化的前提下)
答:不会的,因为在Redis2.8版本后就实现了,当主从断线后恢复时进行增量复制。
- 主Redis宕机
- 这个相对而言就会复杂一些,需要以下2步才能完成
- 第一步,在从数据库中执行
SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务; - 第二步,将主库重新启动后,执行
SLAVEOF <masterip> <masterport>命令,将其设置为其他库的从库,这时数据就能更新回来;
- 第一步,在从数据库中执行
- 这个手动完成恢复的过程其实是比较麻烦的并且容易出错,有没有好办法解决呢?当然有,Redis提供了哨兵(sentinel)机制。
- 这个相对而言就会复杂一些,需要以下2步才能完成
哨兵(sentinel)
顾名思义,哨兵的作用就是对Redis的运行情况进行监控,它是一个独立的进程。其主要功能有两个:
1. 监控主Redis和从Redis是否运行正常;
2. 主Redis出现故障后自动将从Redis转化为Master;
哨兵的原理
模式 结构 作用 单哨兵 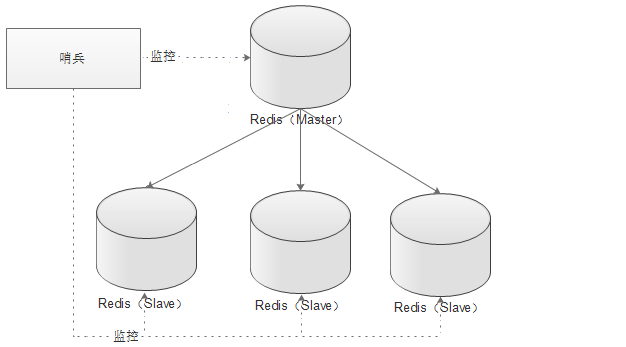
双哨兵 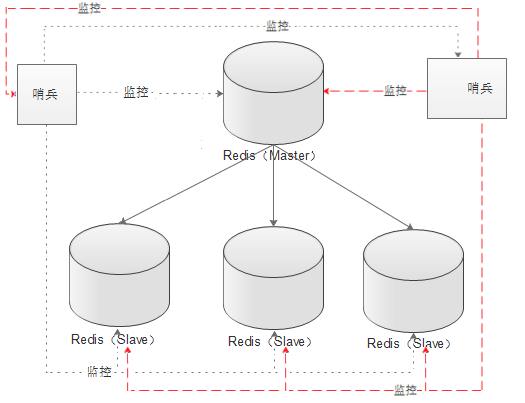
双哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控 配置单个哨兵
- 环境
当前处于一主多从环境
创建哨兵配置文件
# 启动哨兵进程首先需要创建哨兵配置文件(在etc文件夹下)vim redis-sentinel.conf# 编辑内容sentinel monitor wxf-master 127.0.0.1 6379 1【wxf-master】:监控主Redis的名称,自定义即可,可以使用大小写字母和“.-_”符号【127.0.0.1】:监控的主Redis的IP【6379】:监控的主Redis的端口【1】:最低通过票数
启动哨兵进程
命令:redis-sentinel /etc/redis-sentinel.conf
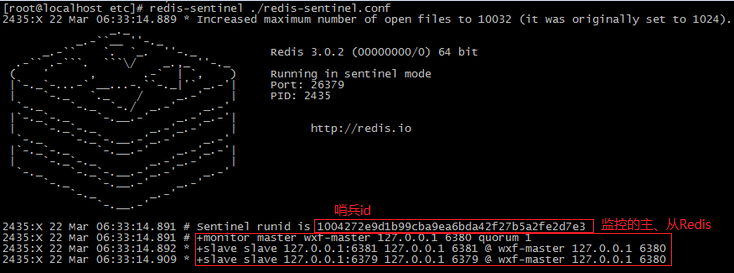
哨兵测试
从Redis宕机

主Redis宕机

恢复6380服务后,查看哨兵状态

- 环境
配置多个哨兵
- 创建哨兵配置文件
# 启动哨兵进程首先需要创建哨兵配置文件(在etc文件夹下)vim redis-sentinel.conf# 编辑内容sentinel monitor wxf-master 127.0.0.1 6379 2sentinel monitor wxf-master2 127.0.0.1 6379 1
- 创建哨兵配置文件
Redis集群
在Redis主从复制架构中,每个数据库都要保存整个系统中的所有数据(主库有多少数据从库就有多少数据),容易形成木桶效应。
集群架构
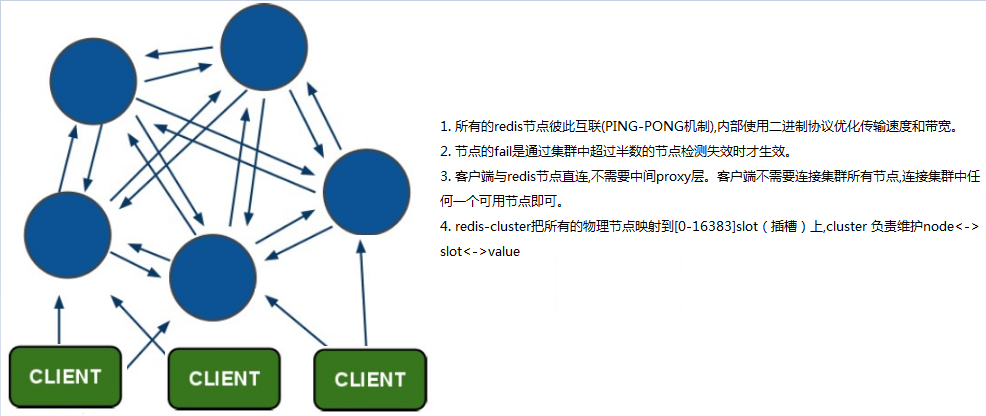
集群配置
- 修改配置文件
- 设置不同的端口:6379、6380、6381(因为在一个机器上进行测试)
- 开启集群:cluster-enabled yes
- 指定集群的配置文件:cluster-config-file "nodes-<端口>.conf"
配置完成后启动redis,此时并没有创建集群关系。

安装ruby环境与创建集群
安装ruby环境
因为要使用ruby脚本,所以需要安装ruby环境。
redis接口支持:redis-gem-3.2.1.rar 密码:62kc# 安装环境yum -y install zlib ruby rubygems# 安装接口支持(命令安装)gem install redis -- 此方法会报错 redis requires Ruby version >= 2.2.2.# 安装接口支持(手动方式)上传redis-3.2.1.gemgem install -l redis-3.2.1.gem
创建集群
首先,进入redis的安装包路径的src,如:/opt/redis-3.0.2/src。然后执行如下命令./redis-trib.rb create --replicas 0 <主机>:<端口> <主机>:<端口> ...【--replicas 0:指定了从库的数量为0】【注意:ip不能使用127.0.0.1,否则Jedis客户端使用时无法连接】
测试
- 完成集群环境搭建
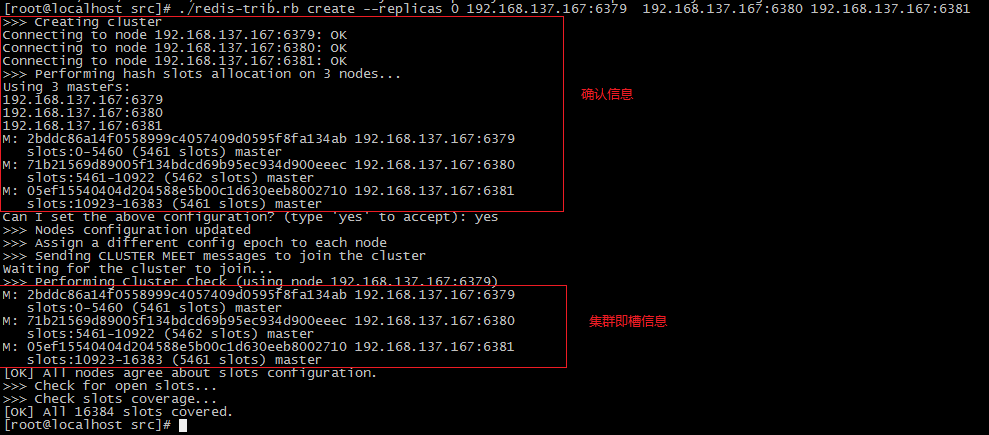
- 测试
连接到6379,并添加数据进行测试
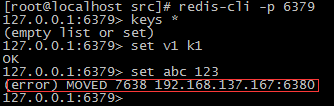
因为‘abc’的hash槽信息是在6380上,现在使用redis-cli连接的6379,无法完成set操作,需要客户端跟踪重定向:redis-cli -c。
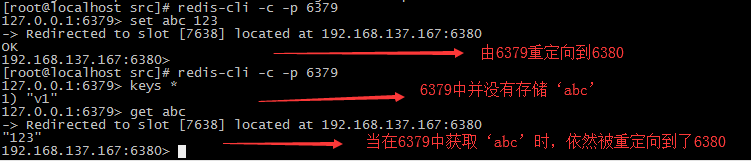
- 完成集群环境搭建
- 修改配置文件
使用Jedis连接到集群
引入jar包
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.7.2</artifactId></dependency>
- 核心API
集群中插槽的分配
- 查看插槽信息
通过cluster nodes命令查看redis集群中的插槽信息。其信息包括集群中的每个节点的id、身份、连接数、插槽值等。

- 当我们执行
set abc 123命令时,redis是如何将数据保存到集群中的?
执行步骤:
- 接收命令
set abc 123 - 通过key值计算出插槽值,根据插槽值找到对应的节点(abc的插槽值为:7638)。然后重定向到该节点执行命令。
- 接收命令
- 插槽说明
- 整个redis集群提供了16384个插槽,也就是说集群中的每个节点分得的插槽数总和为16384。
- ./redis-trib.rb 脚本实现了是将16384个插槽平均分配给了N个节点。
- 注意:如果插槽数有部分是没有指定到节点的,那么这部分插槽所对应的key将不能使用。
- 查看插槽信息
集群中插槽和key的关系
- 计算key的插槽值:
根据key的有效部分使用CRC16算法计算出哈希值,再将哈希值对16384取余,得到插槽值。 - 什么是有效部分?
- 如果key中包含了
{符号,且在{符号后存在}符号,并且{和}之间至少有一个字符,则有效部分是指{和}之间的部分;
a) key={hello}_tatao的有效部分是hello - 如果不满足上一条情况,整个key都是有效部分;
a) key=hello_taotao的有效部分是全部
- 如果key中包含了
- 计算key的插槽值:
新增集群节点(也就是加入集群中,分配插槽值。)
- 开启一个新实例

执行加入命令
./redis-trib.rb add-node <新主机>:<端口> <已存在的主机>:<端口>
查看插槽信息
在新加入的节点中没有发现插槽信息。

重新分配插槽值
./redis-trib.rb reshard <新的主机>:<端口>
分配方式如下:
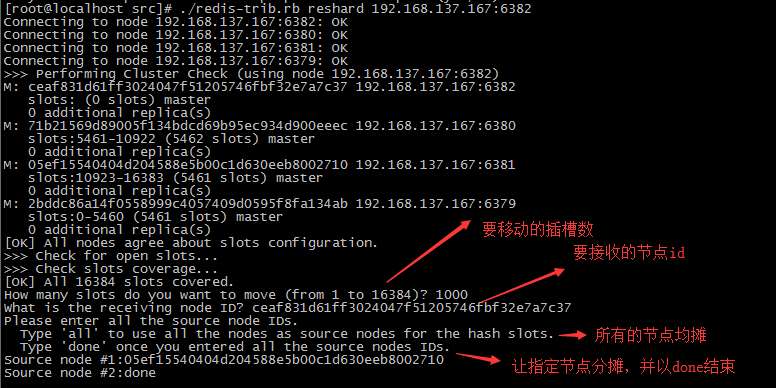
- 开启一个新实例
删除集群节点(与新增相反,先移动插槽,再移除节点)
想要删除集群节点中的某一个节点,需要严格执行如下两步:
先移动插槽
./redis-trib.rb reshard <要移动的主机>:<端口>
移动方式如下:
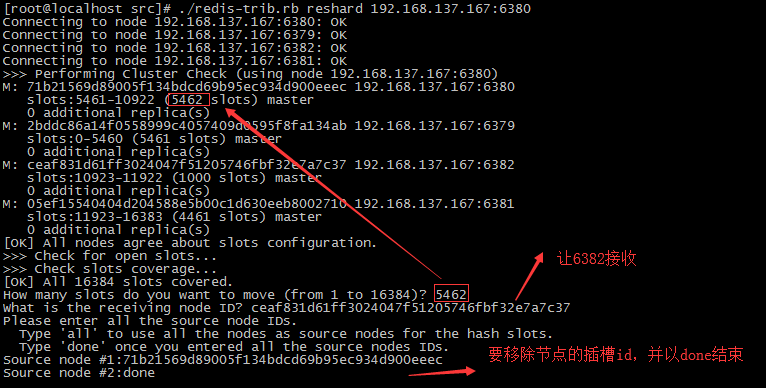
移动后,再次查看插槽信息。

- 移除节点

移除后,再次查看插槽信息。

故障转移
- 集群中的故障机制
- 集群中的每个节点都会定期的向其它节点发送PING命令,并且通过有没有收到回复判断目标节点是否下线;
- 如果一定时间内目标节点都没有响应,那么该节点就认为目标节点疑似下线;
- 当集群中的节点超过半数认为该目标节点疑似下线,那么该节点就会被标记为下线;
- 当集群中的任何一个节点下线,就会导致插槽区有空档,不完整,那么该集群将不可用;
- 如何解决上述问题?
a) 在Redis集群中可以使用主从模式实现某一个节点的高可用
b) 当master节点宕机后,集群会将master节点的slave转变为master继续完成集群服务
- 集群中的故障机制
主从集群架构
- 主从集群结构模型
正常运行 宕机 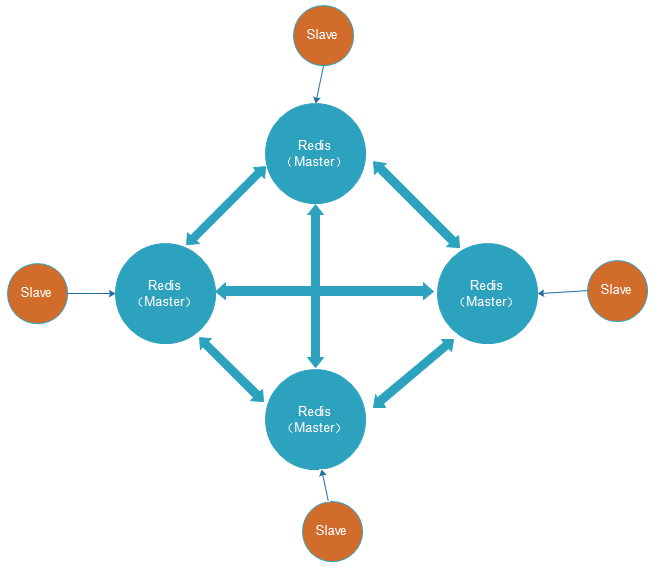
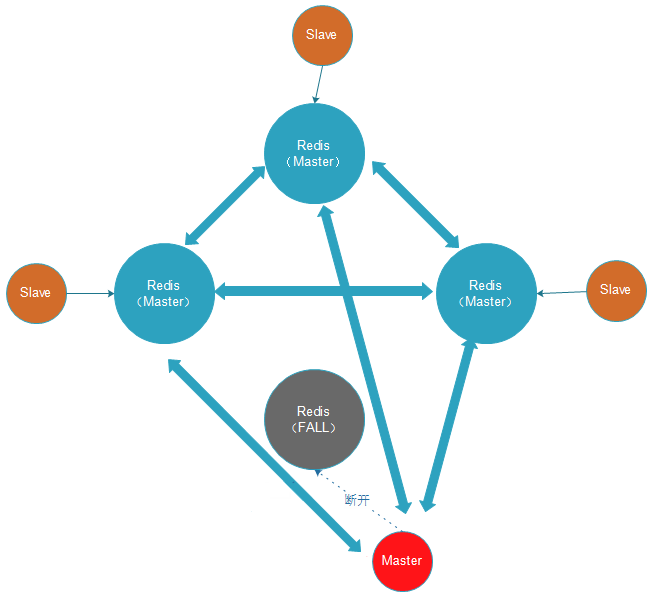
启动redis实例:
6379(主) 6479(从)
6380(主) 6480(从)
6381(主) 6481(从)
6382(主) 6382(从)创建主从集群
指定从库数量为1,创建顺序为主库(3个)、从库(3个)./redis-trib.rb create --replicas 1 <主库1>:<端口> <主库2>:<端口> <主库3>:<端口> <从库1>:<端口> <从库1>:<端口> <从库1>:<端口>
测试
- 保存、读取数据
- slave节点宕机
- master节点宕机
使用Redis集群需要注意的事项
- 多键命令(如MGET、MSET),如果每个键都位于同一个节点,则可以正常支持,否则会提示错误。
- 集群中的节点只能使用0号数据库,如果执行SELECT切换数据库会提示错误。
在项目汇总使用缓存
- 封装RedisService
- Jedis和Spring整合
- 添加缓存的原则
缓存不能影响原有的业务逻辑的执行
执行数据库查询前,进行缓存命中,如果命中,返回;
try{String value = redisService.get(REDIS_KEY);if(StringUtils.isNotBlank(value)){return MAPPER.readValue(value, ItemCatResult.class);}} catch(Exception e){// ...}
查询到结果后,需要将数据缓存到Redis中。
try{redisService.set(REDIS_KEY,MAPPER.writeValueAsString(result), REDIS_TIME);} catch(Exception e){//...}
