@tsihedeyo
2014-09-11T05:57:19.000000Z
字数 2202
阅读 3433
Solr Relevancy
solr egeio
当前权重设置
现在使用的dismax中,在查询['qf'] = 'name^3 text^2 user_name^3'.
qf在web工程文件application/config/solr.php中设置。
dismax支持多个字段查询,且可设定字段匹配的权重。
使用示例
defType = dismax
mm = 50%
qf = features^2 name^3 (即权重比feature:name = 2:3)
q = +"apache solr" search server
edismax是dismax的扩展。现在当前需求的功能不多,因而在search中使用的是dismax。
edismax有更多的配置参数,对语法的容忍度更高。
详细看 [solr dismax][5],对dismax的详细解释。
现在权重的在查询中对field进行权重比,对某个field(索引字段)来说,搜索相关度应该是于这个权重线性相关的。
参见filedNorms公式
Field norms : 索引字段比重 ,公式如下
norm(t,d) = d.getBoost() · lengthNorm(f) · f.getBoost()
详细的相关度算法见下面。
Solr排序算法
Solr的相关度计算基于Similarity类,可在schema.xml中进行配置(第5章)。Similarity是个Java类,你可以选择在多个派生Similarity类中选择,甚至可以自定义Similarity类。但首先要去理解下Solr雀神的Similarity的实现,理解其机制。
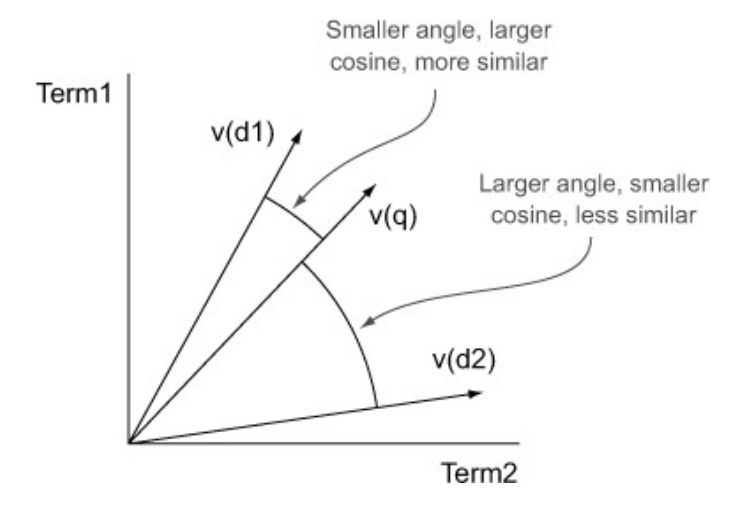
默认下,Solr使用Lucene的DefaultSimilarity类,DefaultSimilarity类使用了2个model来计算相似度。首先,使用Boolean model(第3.1章)过滤掉不符合查询的文档,之后使用空间向量model计算相关度score。空间向量model会将query以及文档都描述成2个向量,而score即使基于这两个向量的一个余弦cosine函数,如图3.6。
图3.6 词向量的cos相似度。较之文档2的词向量v(d2)查询词向量v(q)更接近文档1的词向量v(d1),以他们之间的夹角余弦判断。夹角越小,相近度越高
整个算法的挑战在于如何将query和document描述成合适的向量,下面查看DefaultSimilarity类的复杂相关度计算公式。
给定查询q以及文档d,相近度score如图3.7计算。
图3.7 DefaultSimilarity类的score算法

你需要重写该类时,才需要去仔细研究公式,这里过一遍公式中各个项目的意思。公式中的几个部分:term frequency(tf),inverse document frequency (idf), term boosts (t.getBoost),field normalization (norm),coordination factor (coord),and query normalization (queryNorm).
tf
即term frequency,某个搜索term在该文档中出现的频率
idf
即inverse document frequency,原文描述:
The term frequency elevates terms that appear multiple times within a document, whereas the inverse document frequency penalizes those terms that appear commonly across many documents.
理解比如搜索the cat in hat,对于某些分词情况下,可能发现termthe和in在文档中出现频率很高(tf很高),但是这是无意义的词匹配,idf计算term在所有文档那个中出现的次数对这种高tf值的无意义词进行削弱。
Boost
原文描述:
It is not necessary to leave all aspects of your relevancy calculations up to Solr. If you have domain knowledge about your content—you know that certain fields or terms are more (or less) important than others—you can supply boosts at either indexing time or query time to ensure that the weights of those fields or terms are adjusted accordingly。
即可以自定义权重比例,有 Index-time 和 Query-time
Normalization factors
有三个Query norms,Field norms,The coord factor
Query norms: 公式中queryNorms , 查询参数中q的影响,例如 q = solr^3 java^2(现在没用到)
The coord factor : 公式中coord(q,d),与查询参数q相关
Field norms : 索引字段比重 ,公式如下
norm(t,d) = d.getBoost() · lengthNorm(f) · f.getBoost()
