@tsihedeyo
2014-08-01T11:39:07.000000Z
字数 4069
阅读 2797
Solr_in_Action 2.2
solr_in_action 翻译
2.2. 全部都是为了搜索
Time to see Solr shine。Solr 的优势在于高效的查询处理,如果返回的查询结果根本不精确,谁还管你的搜索引擎是不是够快,支持可伸缩。本节中,你会了解Solr是如何处理查询的,这会帮助你理解为什么说Solr是个高效的搜索技术。
本节的重点会放在执行的查询与返回的文档关系上,特别是返回结果的排序。思考这些有助于让你开始像搜索引擎那样思考,而在第3章中我们将会讨论这些搜索引擎的核心概念。
2.2.1. Solr的查询表单
之前已经试过用Solr来执行全部查询,下面过一遍所有的查询,对Solr支持的查询类型全部走一遍。图2.6给Solr的查询表单的主要部分都标上了注解,花点时间过一遍这张图。
图2.6 搜索表单的注解图,注解包括filters、results format、sorting、paging、search components
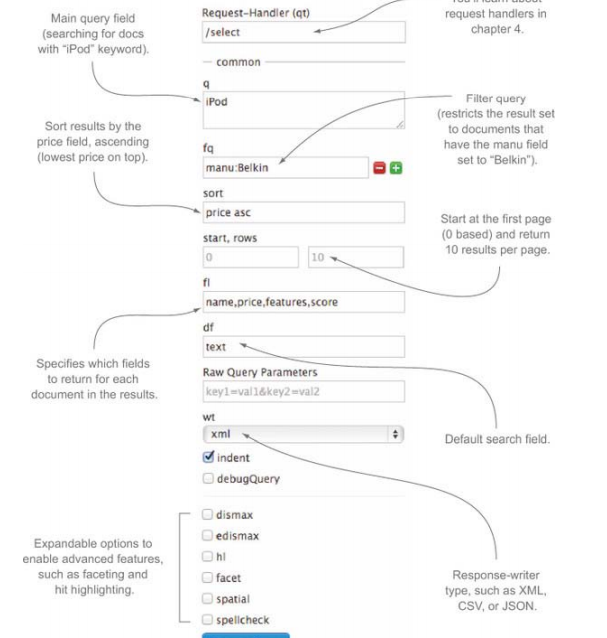
表2.1 显示了上图的表单内容。
| 表单字段 | 值 | 描述 |
|---|---|---|
| q | iPod | 主要查询参数;文档根据与这个参数的相关度排序 |
| fq | manu:Belkin | 过滤查询;限定结果要匹配这个过滤项,但不影响排序。本例中表示返回的结果必须有manufacturer字段值为Belkin |
| sort | price asc | 排序字段以及方式;本例即结果按照price字段降序(asc)返回,这样价格最低的排在返回列表的前面 |
| start | 0 | 查询的起始页;本例表示从page 0 查询,start的增量应该按照页面大小增加,确保是从下一页开始查询 |
| rows | 10 | 页面大小;限定每页返回的结果数目,本例为10 |
| f1 | name,price,features,score | 结果的返回字段;socre字段是内置字段,表征与查询的相关度。若需要返回该字段必须像本例一样对其显示的声明 |
| df | text | 缺省查询字段;text对于服务器来说意味着每个字段都要查询 |
| wt | xml | 结果返回的格式; |
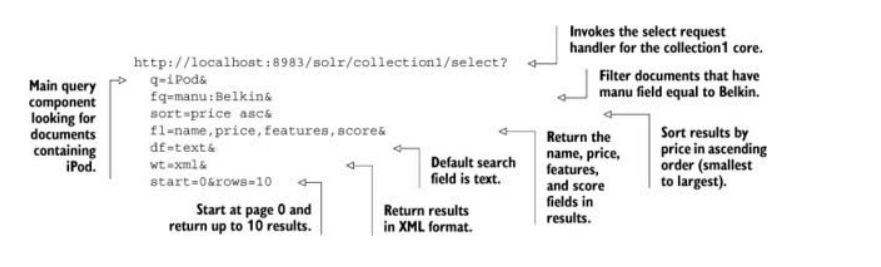
在第一章(章节1.2.3)已经说过,所有的Solr核心服务都是以HTTP请求形式触发的。你填完查询表单后,执行查询,即一个HTTP GET请求被创建并发送至Solr。表2.1中的表单字段都是GET请求的参数,列表2.1显示了发送的HTTP GET请求,注意实际中参数并不是像列表2.1中一样拼接在请求的URL中,列表2.1只是为了方便你查看参数而已。
列表2.1. HTTP GET请求
扩展-更多的查询示例
略
也不需要明说,Solr的这种查询表单并不是非终端用户使用的,Solr提供的这个表单只是为了方便开发者以及管理者测试用的,你需要自己去构建UI,在章节2.2.5中我们会介绍Solr提供的示例查询UI——Solritas,Solritas可以帮助你构建你的搜索应用原型。
2.2.2. 搜索后Solr的返回
我们已经知道了get请求发送了什么给Solr,那么Solr返回了什么呢?本小节将关注Solr返回的匹配文档,以及其他一些你可以用的附加信息。
图2.7显示了章节2.2.1的查询返回的结果。你可以看到结果以XML格式返回,且按照price的降序排列,每个返回的文档都包含了iPod字段,由于只有2个结果,因而分页功能没有被显示出来。
图2.7 Solr的XML返回结果

我们看到上图中返回结果格式为XML,Solr还支持的返回格式有CSV,JSON以及特定语言的某些特定格式。比如Solr还可以返回Python-specfic格式,这种格式下使用eval函数即可转化为Python对象。
2.2.3. 排序检索
第一章讲过,Solr的查询与数据库查询的关键区别在于排序检索,即与查询项目相关度对文档排序,使得最相关的文档放在返回首位。
从章节2.1.4中查看排序,在q输入框中输入'iPod',fl中填入'name,features,score',提交查询。应该有3个结果,降序排列返回,看一下结果,感受下这个结果的排序是否合理。
直观得来说,这个排序是合理的。iPod在第一个文件中的name里出现了2次,feature里出现了1次,而其他文件中只出现了1次。score字段的数值并不是绝对有意义的,score字段主要用来给Lucene对这次结果进行排序,只针对某次特定查询,不能跨越查询比较。在某次查询中,score越大,表示该文档与此次查询更相关。
更改q字段为'iPod power',可以看到还是按照原顺序返回了那三个结果,其中第一个结果与第二个结果的score差值减少了。由于'iPod power'在第二个文件中出现了两次,所以它与'iPod power'的相关度是要高于'iPod'。
q字段改为 iPod power^2,这表示本次查询中,power字段的重要性是iPod字段的2倍。这次还是返回了那三个文件,但是顺序变了。排在第一的文件是 Belkin Mobile Power Cord for iPod w/ Dock,因为它在name,feature中都有power字段,而power字段比iPod字段更重要。
至此,你大概明白排序的意义,在第3、7、16章中你会了解更多。下面学习查询处理的其他特性,开始喜用paging以及sorting获取更多的查询结果。
2.2.4. Paging 和 sorting
示例Solr程序只有32个文件,但是真正产品的Solr示例可能有千万的文档。设想用于电子超市的Solr服务器,iPod的查询可能匹配上千个产品和配件。为了保证查询结果的快速返回,你不会希望以此返回上千条数据。
分页(Paging)
解决方案即每次返回一部分结果,称之为页,同时为用户提供工具获取更多的结果。Paging在Solr中属于first-class概念,每个查询中都带有控制页大小(row)以及其实位置(start)两个参数。若在参数中没有显式声明,那么Solr使用页面大小缺省值10。想进行下一页的查询,则start参数按照页面大小为增量增加,比如开始查询结果从0开始(start = 0),想获取下一页的结果,则把start参数加上页面大小(row),比如缺省下start = 10。
鉴于Lucene的索引并没有对以此返回许多文件进行优化,所以设定一个适合你的应用的合适小的page size十分重要。而且Lucene优化了查询过程,所以其底部的数据结构最大化支持匹配文件以及为文件评分。一旦搜索结果确定了,Solr则需要重构造结果文件,一般这需要从硬盘读取数据。即使使用了缓存来提高效率,这个过程相较于查询来说还是十分缓慢的,更别说一次返回很多的文件(很大的page size)。所以,使用Solr最好设定个小的page size。
排序(Sorting)
之前2.2.3章节中查询结果是按照相关度score降序排列的,你可以可以设定Solr对其他字段进行排序。
排序和分页是密不可分的,因为排序的结果决定了文件在此页中的位置。试想如何没有指定字段的排序,Solr返回的分页结果排列会是确定的么?你可能觉得反正结果按照相关度score排序了,那么分页结果应该还是确定的。但是如果这一页的相关度score都相同呢?
事实上却是是确定的,这是因为Solr找到所有的结果之后,会按照设定的sorting 以及 page offset进行排序。很偶然的,如果搜索到的搜索文档的score一致,那么他们会按照索引的顺序返回,索引的顺序则是基于Lucene的文档ID。Lucene文档ID的排序基本与文档的索引创建时间一致,但是你最好不要依赖于这个排序,只要索引一变,这个顺序就变了。
2.2.5. 扩展的搜索特性
搜索表单下面有一串单选框来支持查询的一些高级特性。图2.6中所示,底部的单选框分别代表了如下特性:
- dismax—Disjunction Max query parser (see chapter 7)
- edismax—Extended Disjunction Max query parser (see chapter 7)
- hl—Hit highlighting (see chapter 9)
- facet—Faceting (see chapter 8)
- spatial—Geospatial search, such as sorting by geo distance (see chapter 15)
- spellcheck—Spell-checking on query terms (see chapter 10)
输入http://115.29.173.222:8983/solr/collection1/browse,可以看看这些高级特性。图2.8为页面截图。
图2.8. Solritas的简单示例,展示如何使用不同的搜索控件,如切面(faceting)、高亮(highlighting)、空间(spatial)

如图2.8所示,Solr提供了3个例子:Simple,Spatial,Group By。在此我们简单介绍一下Simple,其他可以自行探索。
在Simple示例中,最有趣的搜索控件就是左侧标签头为Filed Facets的facet。facet控件将搜索集合中的字段值继续分类成一些子集,用来帮助用户重定义他们的搜索,发现新的信息。比方说我们搜索video,Solr返回了3个文件,facet组件将这三个结果划分为3个子集:电子类(3),图形卡片(2),音乐(1)。点击音乐facet链接,你会发现结果被过滤成了一个文件。facet的意义在于帮助用户分类组合以及过滤搜索结果。第8章中会详细讨论facet。
下面直接讨论在图2.8中我们看到的搜索组件,拼写检查组件(spellcheck component)。在搜索框输入vydeoh,找不到任何结果(如图2.9所示),但是Solr返回了一个链接,提醒用户要查询的是否是video,如果是的话他们可以点击链接重新查询。
图2.9. 拼写检查的示例,Solr找到video最接近vydeoh,提示用户是否要重新进行查找

在Solritas的三个示例还演示了很多很强大的功能,鼓励大家自己去花时间探索。
