@tsihedeyo
2014-08-01T10:36:32.000000Z
字数 4994
阅读 4104
Solr_in_Action 1.2
翻译 solr_in_action
作业部落编写,zybuluo地址,可见图片
1.2. Solr是什么
本节中从头开始设计一个搜索应用,以此来了解Solr的关键组件,更有助于理解Solr的特性以及他们存在的意义。深入之前,先来了解Solr不是什么。
- Solr不是像Google或者Bing这样的搜索引擎
- Solr与网页的搜索优化无关
设想现在为潜在的购房者设计一个房地产搜索的web应用,主要的用例就是用户通过浏览器搜索出售房.图1.1展示了这个虚拟软件的快照,不要过多关注于UI设计,这只是一个教学模型,重要的是去了解Solr可以支持的操作
图1.1 展示Solr特性的虚拟web搜索应用的教学模型快照
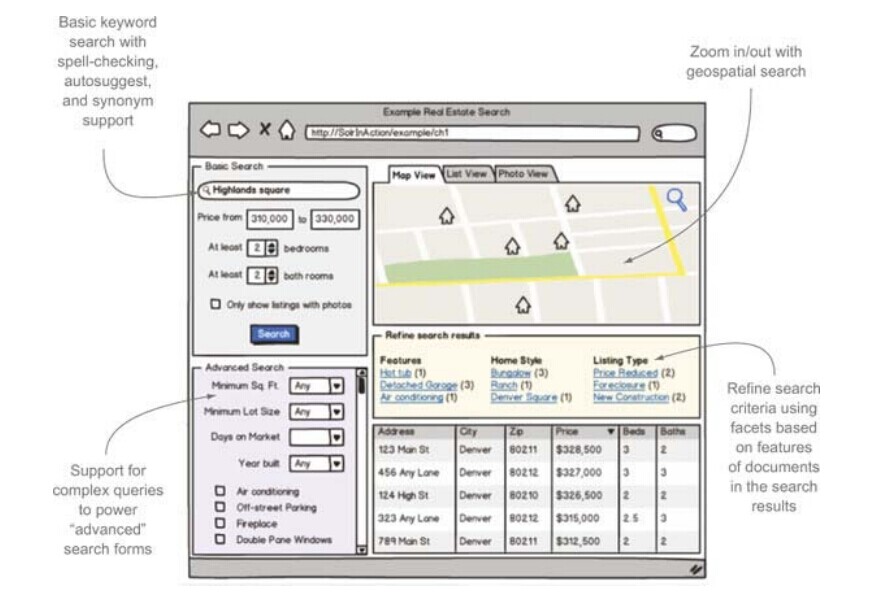
查看图1.1的快照来探索Solr的关键特性,从左上方开始,顺时针方向,Solr提供强力的关键字查询。如1.1.2所说,给用户提高良好的关键字查询也需要复杂的机制,Solr通过上图的查询框提供。同时Solr还提供拼写检查(实时输入建议)、词组查询、同义词,还有文本分析去处理查询项目的语言变异问题(如buying a house 和 purchase a home) 。
Solr还提供了基于地理的查询。图1.1中,根据用户虚拟的附近地理中心位置的经纬度,匹配的结果别标注在地图上。依赖于Solr的地理查询,你可以对返回文档进行地理位置的排序,限制特定地理距离内的结果查询,甚至是返回任意位置上搜索结果的地理距离。为了确保在UI操作上用户能够对地图进行缩放以及移动坐标等操作,基于地理的查询必须高效快速得响应。
用户执行了查询之后,使用Solr的分面查询可以进一步显示查询结果的特性。分面可以对搜索结果集合进行分类,方便了下一步的搜索和重查询。在图1.1中,查询结果又按照了特性、房型、列表类型进行分类。
至此我们已经了解房地产查询应用的基本需求,下面看看如何用Solr实现。首先我们必须了解Solr是如何根据用户的输入匹配房产信息索引的,这是所有查询应用的基础。
1.2.1. 信息检索引擎
Solr基于开源的Java信息检索库Apache Lucene,在章节3中会详细介绍信息检索引擎。目前我们只是简单得接触下信息检索的一些关键概念,先看现代搜索的主流学术对此的定义:
信息检索(IR)即从大量的数据集(通常存储在电脑上)中查询符合需要的非结构化的自然资源(通常是文本文档)[1]
在我们的示例房地产应用中,用户的首要需求是基于位置、房型、特性以及价格搜索房子。搜索的索引涵盖全美的房产信息,毫无疑问的大数据。一言以概之,Solr使用了Lucene实现索引文件的核心数据结构以及执行文档的查询。
Lucene是用户建立及管理反向索引的Java库,反向索引是用来匹配文本文档查询的特殊数据结构。图1.2展示了应用于我们的示例房产搜索应用的一个简单的Lucene反向索引。
图1.2 信息检索的关键数据结构式反向索引
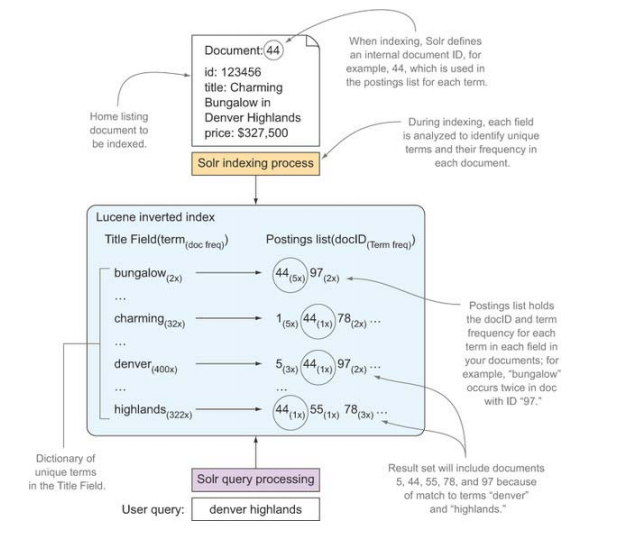
在第三节中你会了解反向索引的工作原理,现在只需要看看图1.2去大致了解下新文档是如何被加入索引以及如何使用反向索引进行搜索的。
你可能觉得使用SQL查询关系型数据库很快就能得到相同的结果,对于这个简单的例子来说是这样的。但Lucene和数据库查询的一个本质区别是数据库返回的结果只能按照一行或某几行进行排序,而Lucene则可以让结果按照查询相关度排序。换言之,按照相关度排序是信息检索的一个关键点,也是与其他类型查询的一个区分点。
扩展
建立web-scale反向索引
像Google这样的搜索引擎也是通过反向索引来查询网页的,其实正是因为需要建立web-scale级别的反向索引,才会有MapReduce的产生。
MapReduce是一种基于集群的可扩展的数据处理编程模型,其将算法分割成两步:map和reduce。Google使用了MapReduce来建立web搜索需要的海量反向索引。在MapReduce模型中,map将产生唯一的term以及出现过该term的文档那个id,reduce则依据term分类以确保一个term的所有term/docID键值对被送到了同一个reducer进程中进行处理。最后的reducer进程则会统计所有的term出现频率并更新反向索引。
Apache Hadoop 提供了MapReduce的开源实现,开源项目Apache Nutch使用Hadoop构建Solr里需要使用的web-scale的Lucene反向索引。本书不讨论Hadoop和Nutch,如果你需要构建web-scale的反向索引,那么推荐你去调研这些项目。
至此我们已经知道Lucene提供了搜索的核心架构,下面讨论Solr在Lucene之上做了什么。首先介绍你如何使用Solr灵活的schema.xml配置文件来定义你的索引结构。
1.2.2. 灵活的schema管理
虽然Lucene提供了索引以及查询文件的库,但却缺失了简单配置自定义索引结构的方法。在Lucene里,你需要自己写Java代码去定义索引字段(fileds)以及如何去解析这些字段。Solr提供了xml文档来配置索引结构以及字段的解析、呈现方式,即schema.xml。Solr使用schema.xml来给Lucene展示所有可能匹配文档所需要的字段及其数据类型,省时且可读性强。Solr构建的索引与内置的可编程的Lucene索引百分百兼容。
在Lucene核心索引功能之上,Solr还提供了良好的构造方法。同时,Solr还支持复制字段以及动态字段。复制字段即可以获取一个或多个字段的行文本内容再填充到一个不同的字段中去。动态字段即支持不需要在schema.xml中显示申明,就可将同一字段类型应用于多个不同的字段,这对于处理有多个字段的文档建模十分有用。在第5、6章中会深入介绍schema.xml。
回到示例房产应用,你会惊奇的发现即使不修改schema.xml,我们也可以不使用那个UI box就完成搜索。这说明Solr的schema十分灵活,示例中Solr 服务器被设计支持商品查询,但对房产查询也能很好的支持。
至此,我们知道Lucene是个强力的库,可用来索引文档、执行查询、结果排序。使用schema.xml配置,你不再需要去调用Lucene API去定义索引结构。现在,你需要从web中使用这些服务,下一节,我们将演示Solr作为Java web 应用是如何使用一些标准格式(如XML,Json,Http)与其他技术交互工作的。
1.2.3. Java web 应用
Solr是运行在现代Java Servlet容器(如Jetty,Tomcat)或J2EE应用服务器(JBoss,Oracle AS)中的Java web 应用,图1.3为Solr服务器的主要组件。
图1.3 Solr4的主要组件图
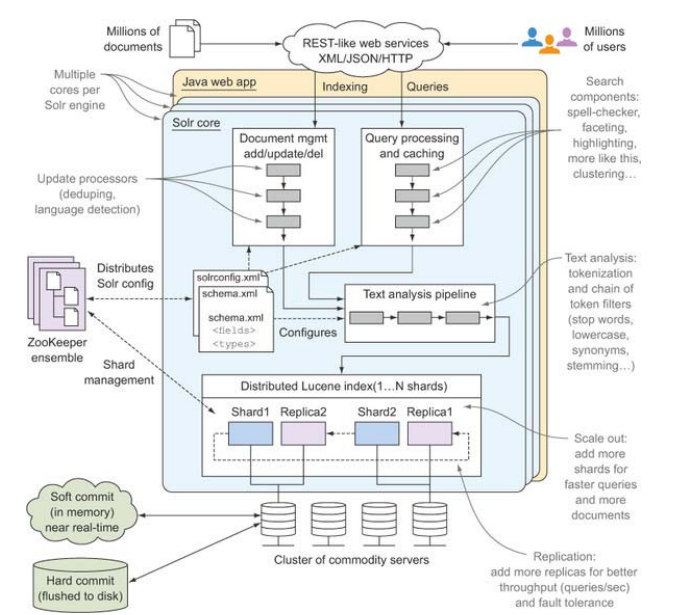
无可否认,图1.3第一眼看上去简直巨大。先扫一眼对感受一下这些术语,对其中的一些字段或者概念不熟悉这是很正常的。读完这边书后,你应该就对图1.3的这些概念应该都有很深的理解了。
在本章节介绍中已经提到过,Solr的设计者认为Solr最好是与已存在的其他架构都能互补。事实上,你很难找到不能使用Solr的环境。在第2章中,你会发现完成下载后,几分钟你就能启动Solr.
为了实现易植入的目的,Solr的核心服务都可以通过很多不同的应用以及语言获取。Solr提供基于XML、Json、Http标准的类REST服务。简单声明下,我们没用RESTful来描述Solr的HTTP api,因为Solr并没有严格遵循REST规则。比如,Solr使用HTTP POST而不是HTTP DELETE来删除文档。
类REST是个很好的底子,开发者更愿意现在自己的开发语言来抽象化一些固定的机械的web服务请求处理。现在大多数语言(包括Python、PHP、Java、.NET、Ruby)都有Solr客户端库。
1.2.4. 一台服务器的多个索引
现在软件架构的一个特点就是灵活性以应对迅速变化的需求。Solr提供的灵活性就是你的工作并不限定于一个索引,Solr支持在一个引擎里跑多个索引。图1.3中所示,在一个java web环境中我们跑了多个核心作为独立的层。
将每个核心有一个单独的索引以及配置,而在一个Solr实例中会有很多个核。这使得你可以再一台服务器上管理多个核,同时他们可以共享服务器资源以及管理员任务(如监控和维护)。Solr提供API来创建以及管理多个核,在章节12中将涉及这部分。
Solr多核的一个应用级数据的切分,比如一个核处理新的文档,而另一个处理旧的文档那个,也就是所谓的时间切分。另一个多核的用户是支持多用户的应用。
我们的房产应用中,我们可能会使用多核来处理不同类型的信息表,他们的差异大到足以需要不同的索引。考虑真实情况下的乡镇地产信息,乡下土地的买卖和城市里房产买卖十分不同,因此我们可能希望在另一个核心=里处理土地信息。
1.2.5. 扩展(插件)
图1.3 显示了Solr最主要的三个子系统:文档管理,查询处理,文本分析。每个子系统由模块化的“管道”来组成,也方便用户加入新功能。就是说为加新功能,你不需要重写Solr的整个查询-处理流程,只需要在已经存在的管道上插入新的搜索组件即可。Solr易扩展也更方便适配你自己的应用需求。
1.2.6. Scalable
Lucene是个很快的搜索库,Solr也充分利用了Lucene快速的优点。但无论Lucene有多快,单个服务器最终还是会受限于CPU和I/O,而限制了自身处理的不同用户的并发查询请求。
为达到可伸缩,Solr受限提供了灵活的cache管理以重用很耗费计算的数据结构。Solr还支持配置cache去保存一些很重的计算,比如缓存过滤查询结果。第4章中深入Solr的缓存管理。
Cache只能帮你这么多,最后你肯定是只能加服务器来处理更多的文档以及查询请求。现在来福按住Solr可扩展性的两个普遍的指标——查询吞吐量和索引的文档数。查询吞吐量即搜索引擎每秒支持的查询数,Lucene查询很快,但最后还是要受限于服务器支持并发数。为了更高的查询吞吐量,你需要复制索引使其他的服务器也能支持更多的请求。就是说如果你的索引复制在3台服务器上,那么你的吞吐量大概会提升到3倍,因为每个服务器可以处理1/3的查询请求。实际上很难得到线性的增长,加到3台服务器可能吞吐量是2.5倍。
另一个指标是索引的文件数目。如你在处理大量的数据,那单台服务器很可能由于过大的文件数目而达到查询的瓶颈。为了处理更多的文档,你需要将索引分块(称为shards),利用这些shards进行分布式的搜索。
扩展
虚拟硬件资源的可扩展
略...以后看看补上...
可扩展十分重要,对于现代系统来说容错性也十分重要。下一节讨论容错性。
1.2.7. 容错性
除了扩展性外,你还要考虑若果你的服务器挂了怎么办,特别是当你把Solr部署在虚拟资源或者商品资源时。答案的底线是你必须计划好应对失败。就算是最顶级的架构加上最高端的硬件也有可能会挂。
假设你的索引有4个shards,持有shard2的服务器宕机了,此时SOlr不能继续完成索引文档,也就不能支持索引查询,你的搜索引擎也就挂了。为了避免这种情况,你可以为每份shard进行冗余保存。这样shard2挂了,其他还能运转,只是由于少了个服务器,速度要慢了。章节12、13会详细讨论。
至此,你明白了Solrs具有可扩展性以及容错性的良好的现代软件架构。虽然以上已经够多了,但你还是不相信Solr,那就继续从各个层面上给你夸夸Solr.
1.3. 为什么选Solr
略
[1] Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze, Introduction to
Information Retrieval (Cambridge University Press, 2008)。 ↩
