@tsihedeyo
2014-09-10T01:58:08.000000Z
字数 1942
阅读 3846
Solr in Action 3.2
solr_in_action 翻译 chapter_3
3.2. 相关性
对于搜索应用来说,找到搜索结果只是第一步,大多数用户不喜欢去翻页寻找他们的目标文件。一般只有10%的用户愿意去翻页寻找,且只有1%的用户会一直翻到第三页。
Solr提供了良好的结果相关度排序,此节会大概告诉你相关度score是如何计算的,影响score的因素有哪些。通过一个直观的例子,深入Solr的相关度计算机制及其算法。
3.2.1 Default similarity
Solr的相关度计算基于Similarity类,可在schema.xml中进行配置(第5章)。Similarity是个Java类,你可以选择在多个派生Similarity类中选择,甚至可以自定义Similarity类。但首先要去理解下Solr雀神的Similarity的实现,理解其机制。
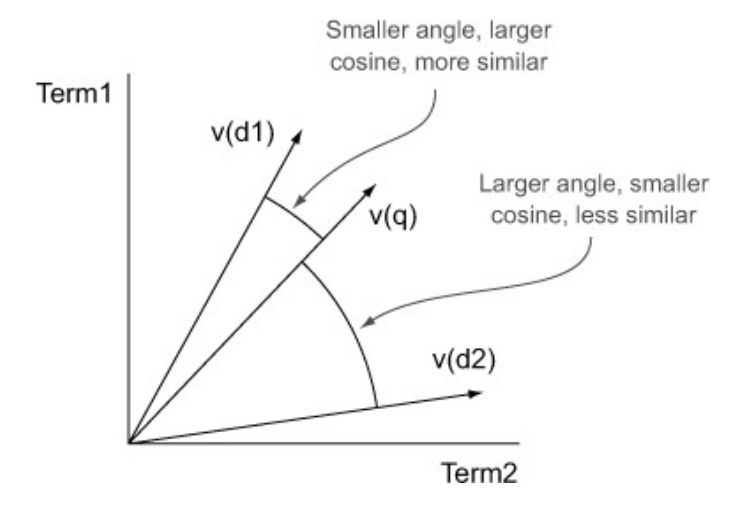
默认下,Solr使用Lucene的DefaultSimilarity类,DefaultSimilarity类使用了2个model来计算相似度。首先,使用Boolean model(第3.1章)过滤掉不符合查询的文档,之后使用空间向量model计算相关度score。空间向量model会将query以及文档都描述成2个向量,而score即使基于这两个向量的一个余弦cosine函数,如图3.6。
图3.6 词向量的cos相似度。较之文档2的词向量v(d2)查询词向量v(q)更接近文档1的词向量v(d1),以他们之间的夹角余弦判断。夹角越小,相近度越高
整个算法的挑战在于如何将query和document描述成合适的向量,下面查看DefaultSimilarity类的复杂相关度计算公式。
给定查询q以及文档d,相近度score如图3.7计算。
图3.7 DefaultSimilarity类的score算法

你需要重写该类时,才需要去仔细研究公式,这里过一遍公式中各个项目的意思。公式中的几个部分:term frequency(tf),inverse document frequency (idf), term boosts (t.getBoost),field normalization (norm),coordination factor (coord),and query normalization (queryNorm).
3.2.2 Term frequency
tf评判了匹配的文档中term的出现频度。总体来说,文档中term出现频度越高,应认为更相关。由于出现次数与相关度并不应该是线性相关的,所以取了开方。
3.2.3 Inverse document frequency
查询中并不是每个词的权重都是一样的,比方说你想查询数据Dr. Seuss写的The Cat in the Hat,而返回的前几本数据是包含了the最多的,而不是包含cat或hat最多的。直观得来说,在大多数文档那个中都会出现的词的权重应该要低一点。
idf即表征了搜索中的某个字段在全文本中的稀有程度,idf计算了term在全文本中的出现次数并取了倒数。
图3.8 图形化表针了查询词的rareness,越稀有,字越大

Term frequency 和 inverse document frequency 一起平衡score,tf估算了term在目标文档中的出现频度,idf标志了根据term在全部文档中的频度适当削弱score,这样使得英文中的一些介词如the,an的socre评分很低。
3.2.4.Boosting
如果你自己很清楚搜索字段的权重,你可以显式申明term的权重。示例如下:
- Query: title:(solr in action)^2.5 description:(solr in action)
上面的示例表示title中匹配到该短语的权重为2.5,而描述中匹配到权重为1。Solr缺省为1.
也可以显式的降低权重
* Query: title:(solr in action) description:(solr in action)^0.2
也可以分割到具体的词
- Query: title:(solr^2 in^.01 action^1.5)^3 OR "solr in action"^2.5
3.2.5.Normalization factors
默认Solr有三种标准化因素:field norms,query norms,coord factor
