@ltlovezh
2019-12-14T01:38:47.000000Z
字数 16338
阅读 3214
Android图形系统之VSync
图形系统 VSync
从Android4.1开始,Google引入了Project Butter,即“黄油计划”。目的是改善用户抱怨最多的系统缺陷:UI响应速度,Google希望这一新计划可以让Android系统摆脱UI交互上给人带来的滞后感,而能像黄油一样顺滑。
Project Butter对Android Display系统进行了重构,引入了三个核心元素:VSync、Triple Buffer和Choreographer。今天我们主要看下VSync信号的来龙去脉。
VSync信号的产生
VSync信号是由HWC硬件模块根据屏幕刷新率产生。DispSync是VSync事件核心类,根据HWC产生的硬件VSync信号,训练了一个模拟的VSync事件源,并且通过内部的DispSyncThread线程向外分发DispSync::Callback回调,DispSyncSource就是实现了该回调接口。
为了处理VSync信号,SurfaceFlinger启动了两个EventThread线程:
- mEventThread:服务于客户端APP UI渲染。
- mSFEventThread:服务于
SurfaceFlinger合成和上屏。
两个VSync线程在SurfaceFlinger::init中完成初始化,如下所示:
// start the EventThread vsyncSrc 表示渲染用的Vsyncsp<VSyncSource> vsyncSrc = new DispSyncSource(&mPrimaryDispSync, vsyncPhaseOffsetNs, true, "app");// 客户端UI渲染使用的VSync线程mEventThread = new EventThread(vsyncSrc, *this);// sfVsyncSrc表示SF合成用的VSyncsp<VSyncSource> sfVsyncSrc = new DispSyncSource(&mPrimaryDispSync, sfVsyncPhaseOffsetNs, true, "sf");// SF使用的VSync线程mSFEventThread = new EventThread(sfVsyncSrc, *this);//MessageQueue向SF的EventThread注册监听器mEventQueue.setEventThread(mSFEventThread);
DispSyncSource实现了DispSync::Callback回调接口,可以从DispSync接收VSync事件。上述代码创建了两个DispSyncSource对象,vsyncSrc是给CPU服务,驱动客户端APP UI线程渲染;sfVsyncSrc是给GPU服务,驱动SF主线程合成上屏。两个DispSyncSource分别指定了不同的时间戳偏移量(相对于标准的VSync时间戳),可以精细控制VSync的回调时机,通过adb shell dumpsys SurfaceFlinger可以查看这两个偏移量(后面详细介绍):
// app phase就是vsyncSrc偏移量,sf phase是sfVsyncSrc偏移量,refresh是主屏的刷新周期DispSync configuration: app phase 1000000 ns, sf phase 1000000 ns, early sf phase 1000000 ns, present offset 0 ns (refresh 16666666 ns)
每个DispSyncSource对象与一个EventThread相关联,DispSync的VSync事件会通过DispSyncSource传递到EventThread::onVSyncEvent,再通过EventThread::Connection向外分发。
基于DispSync的VSync架构如下所示:
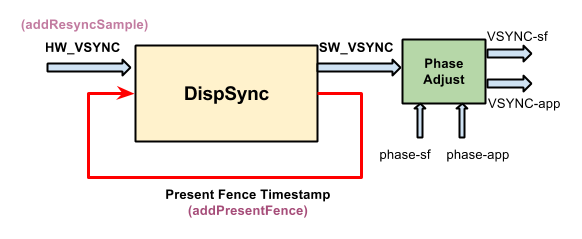
DispSync借助硬件VSync(HW_VSYNC)训练了一个模拟的VSync模型(SW-VSYNC)。- 模拟的VSync模型为驱动APP绘制的VSync信号添加了时间戳偏移(
phase-app),生成了Vsync-app事件。 - 模拟的VSync模型为驱动SF合成的VSync信号添加了时间戳偏移(
phase-sf),生成了Vsync-sf事件。 Vsync-app和Vsync-sf是外界真正接触到的VSync事件。addPresentFence用来检查模拟的VSync模型与硬件VSync之间是否超过了一定误差,若是,则需要重启硬件Vsync,训练新的VSync模型。
下面详细看下DispSync是如何训练出模拟的VSync事件?在Android图形系统系统篇之HWC一文中,我们提到HWC2::Device构造函数会通过Device::registerCallbacks向显示设备注册三个Display回调:热插拔,刷新和VSync信号,这里的显示设备就是hwc2_device_t。所以,VSync信号的起源是hwc2_device_t,然后经过一系列回调到达SurfaceFlinger.onVSyncReceived方法。onVSyncReceived通过addResyncSample方法把硬件VSync时间戳交给DispSync,训练一个模拟的VSync事件模型。addResyncSample主要逻辑:
- 几个关键变量:
mReferenceTime记录第一个硬件VSync时间戳;mResyncSamples存储所有硬件Vsync时间戳(数组长度为NUM_PRESENT_SAMPLES,目前为32);mNumResyncSamples表示参与计算的时间戳个数。在时间戳个数达到MIN_RESYNC_SAMPLES_FOR_UPDATE(常量,目前为6)时,会触发真正的模型计算updateModelLocked。 - 计算过程:首先,计算出相邻时间戳时间差的均值(排除了最大和最小值),作为模拟的Vsync的时间周期
mPeriod(这个值理论上等于16.66666...ms);然后根据每个硬件时间戳相比于mPeriod的偏差,计算出平均偏差mPhase,范围是(-mPeriod/2 , mPeriod/2];最后把mPeriod、mPhase和mReferenceTime设置给DispSyncThread线程。 DispSyncThread线程根据上面计算出的mPeriod、mPhase、mReferenceTime以及每个DispSync::Callback要求的Phase,定时回调每个Callback,其中Callback的时间戳参数,不是系统时间,而是基于第一个硬件Vsync时间戳mReferenceTime计算出来的。- 如果训练的模拟VSync时间戳与硬件VSync时间戳在一定的误差范围内,则
addResyncSample返回false,表示模拟的硬件VSync模型已经OK,不再需要硬件VSync时间戳了,否则返回true,表示需要更多的硬件VSync时间戳来训练模型。 - 如果
DispSync检测到硬件VSync与模拟的VSync模型之间存在较大误差,则会重新训练新的VSync模型。
核心代码如下所示:
// 收到HWComposer的Vsync信号void SurfaceFlinger::onVSyncReceived(int32_t type, nsecs_t timestamp) {bool needsHwVsync = false;{ // Scope for the lockMutex::Autolock _l(mHWVsyncLock);// type为0,表示主显示屏if (type == 0 && mPrimaryHWVsyncEnabled) {// 训练模型,返回false,则表示模型训练成功needsHwVsync = mPrimaryDispSync.addResyncSample(timestamp);}}if (needsHwVsync) {enableHardwareVsync();} else { // 关闭硬件VSyncdisableHardwareVsync(false);}}// DispSyncThread线程注册的监听器struct EventListener {const char* mName;nsecs_t mPhase; // 时间戳偏移量nsecs_t mLastEventTime; // 上次VSync事件的时间戳sp<DispSync::Callback> mCallback; // 对应的回调,即DispSyncSource};
为了控制硬件VSync的打开与关闭,专门提供了一个线程EventControlThread,当内部的mVsyncEnabled状态改变时,会调用到下面的SurfaceFlinger::setVsyncEnabled方法:
void SurfaceFlinger::setVsyncEnabled(int disp, int enabled) {// 打开 or 关闭HWC VSync,最终调用到下面的 Display::setVsyncEnabledgetHwComposer().setVsyncEnabled(disp,enabled ? HWC2::Vsync::Enable : HWC2::Vsync::Disable);}// 硬件模块Error Display::setVsyncEnabled(Vsync enabled){auto intEnabled = static_cast<int32_t>(enabled);// 打开 or 关闭HWC VSyncint32_t intError = mDevice.mSetVsyncEnabled(mDevice.mHwcDevice, mId, intEnabled);return static_cast<Error>(intError);}
此外,必须在屏幕亮着时,硬件VSync才能工作,否则只能依赖训练好的模拟硬件VSync,甚至需要在EventThread中通过软件方式进行VSync兜底(后面会介绍),下面是屏幕打开和关闭的逻辑:
void SurfaceFlinger::setPowerModeInternal(const sp<DisplayDevice>& hw, int mode){int32_t type = hw->getDisplayType();// current hwc power modeint currentMode = hw->getPowerMode();if (mode == currentMode) {return;}if (currentMode == HWC_POWER_MODE_OFF) {getHwComposer().setPowerMode(type, mode);if (type == DisplayDevice::DISPLAY_PRIMARY) {// 通知为客户端服务的EventThread:显示器打开了mEventThread->onScreenAcquired();// 显示器打开后,需要重新基于硬件VSync信号,训练软件VSyncresyncToHardwareVsync(true);}mHasPoweredOff = true;repaintEverything();} else if (mode == HWC_POWER_MODE_OFF) {if (type == DisplayDevice::DISPLAY_PRIMARY) {// 显示器关闭了,则关闭硬件VSync,停止软件VSync训练disableHardwareVsync(true); // also cancels any in-progress resync// 通知为客户端服务的EventThread:显示器关闭了mEventThread->onScreenReleased();}getHwComposer().setPowerMode(type, mode);// from this point on, SF will stop drawing on this display} else {getHwComposer().setPowerMode(type, mode);}}
为什么屏幕的打开与关闭只通知了mEventThread,而没通知mSFEventThread,因为前者是为客户端进程服务,即使主屏幕关闭了,客户端依然要依赖VSync事件做一些工作,所以在
mEventThread中必须通过软件的方式为VSync事件兜底(就是等待模拟的硬件VSync 16ms,若超时了,就使用系统时间戳)。而后者是为SurfaceFlinger的合成上屏服务,当对应的屏幕关闭后,就不再需要上屏了,所以mSFEventThread就可以不工作了。
adb shell dumpsys SurfaceFlinger可以查看mEventThread的dump信息,如下所示:
// 是否在使用VSync,可能是硬件VSync,也可能是EventThread的软件VSyncVSYNC state: enabled// 当屏幕亮着的,就是disabled,如果关闭屏幕,这里为enabledsoft-vsync: disabled// 表示感兴趣的Connection的个数numListeners=90,// 表示接收到的VSync的累加值(包括硬件VSync和EventThread的软件VSync)events-delivered: 181752// 下面是具体Connection的count,-1表示该Connection不会接收VSync信号,Connection->count的具体含义下面👇会详细介绍。0x76fa631480: count=-10x76fa633d00: count=-1......
如果模拟的硬件VSync事件(DispSyncThread产生)是正常的,那么EventThread::onVSyncEvent负责接收VSync事件,并更新vsync.count计数和header.timestamp时间戳。
// 接收到DispSyncSource传过来的VSync信号void EventThread::onVSyncEvent(nsecs_t timestamp) {Mutex::Autolock _l(mLock);// 表示VSync事件,也可能是热插拔事件mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;mVSyncEvent[0].header.id = 0;// 更新VSync时间戳mVSyncEvent[0].header.timestamp = timestamp;// VSync的累加计数,即dump信息中的events-delivered值mVSyncEvent[0].vsync.count++;mCondition.broadcast();}
如果屏幕关闭了,那么在EventThread::waitForEvent中通过Condition.waitRelative为VSync信号兜底,核心代码如下所示:
// SurfaceFlinger通知屏幕关闭了,模拟的硬件VSync信号可能不准,需要使用软件模拟,即16msvoid EventThread::onScreenReleased() {Mutex::Autolock _l(mLock);if (!mUseSoftwareVSync) {// disable reliance on h/w vsyncmUseSoftwareVSync = true;mCondition.broadcast();}}// SurfaceFlinger通知屏幕打开了,不再需要使用软件模拟VSyncvoid EventThread::onScreenAcquired() {Mutex::Autolock _l(mLock);if (mUseSoftwareVSync) {// resume use of h/w vsyncmUseSoftwareVSync = false;mCondition.broadcast();}}// 下面是EventThread::waitForEvent中产生软件VSync的地方bool softwareSync = mUseSoftwareVSync;// 如果屏幕没关闭,那么继续等待模拟的硬件VSync信号(超时时间为1S),否则等待时间为16ms。在waitRelative期间,如果模拟的硬件VSync信号到了,那么就继续使用模拟的硬件VSync,否则就自己更新vsync.count和`header.timestamp`时间戳。nsecs_t timeout = softwareSync ? ms2ns(16) : ms2ns(1000);if (mCondition.waitRelative(mLock, timeout) == TIMED_OUT) {// 这里的代码块是处理等待超时的情况,即模拟的硬件VSync信号在16ms内没到达,就需要软件模拟了if (!softwareSync) {// 硬件Vsync失效了,下面是模拟的Vsync信号ALOGW("Timed out waiting for hw vsync; faking it");}mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;mVSyncEvent[0].header.id = DisplayDevice::DISPLAY_PRIMARY;// 软件方式,更新为系统时间戳mVSyncEvent[0].header.timestamp = systemTime(SYSTEM_TIME_MONOTONIC);mVSyncEvent[0].vsync.count++;}
屏幕关闭后,DispSyncThread线程还在继续发送模拟的硬件VSync事件,所以正常情况下,还是通过EventThread::onVSyncEvent更新vsync.count计数和header.timestamp时间戳。只有在超过16ms,没有接收到模拟的硬件VSync时,系统才会主动更新vsync.count计数和header.timestamp时间戳。
针对服务于CPU的mEventThread,vsync.count计数和header.timestamp时间戳一般情况下都是通过EventThread::onVSyncEvent方法来更新,若屏幕关闭了,并且在16ms内EventThread::onVSyncEvent方法未更新VSync信息,那么就在EventThread::waitForEvent中主动更新VSync信息。
而针对服务于GPU的mSFEventThread,只会通过EventThread::onVSyncEvent方法更新vsync.count计数和header.timestamp时间戳。
总结下:不管是服务于CPU的
mEventThread,还是服务于GPU的mSFEventThread,都是通过DispSyncSource接收模拟的硬件VSync事件。差异点在于,当有EventThread::Connection请求了VSync事件,但是此时又没有VSync时,waitRelative等待超时的时间是不同的:在屏幕亮着的情况是1000ms,而屏幕关闭后则是16ms。而SurfaceFlinger只会通知mEventThread屏幕的打开与关闭。所以mSFEventThread等待超时的时间只能是1000ms。
上文中有提到vsync.count计数和EventThread::Connection.count值,它们主要是控制通知EventThread::Connection的频率,当VSync信号到来时,vsync.count会不断累加,比较简单。而EventThread::Connection.count的取值主要分为三类:
- count >= 1 :当vsync.count % count为0时,通知对应的EventThread::Connection
- count == 0 :可以通知对应的EventThread::Connection,但是立即赋值为-1,表示下次不再继续通知
- count ==-1 : 不会通知对应的Connection
核心代码在waitForEvent中,如下所示:
// 根据count决定对应的connection是否应该被通知,signalConnections是收集需要通知的connection列表。if (connection->count == 0) {// 此次通知,下次就不通知VSync事件了connection->count = -1;signalConnections.add(connection);added = true;} else if (connection->count == 1 || (vsyncCount % connection->count) == 0) {// continuous event, and time to report it 持续的VSync事件signalConnections.add(connection);added = true;}
EventThread::Connection提供了setVsyncRate和requestNextVsync方法修改这个count,最终会调用到EventThread对应的方法,如下所示:
// 设置指定Connection接收VSync事件的固定频率void EventThread::setVsyncRate(uint32_t count, const sp<EventThread::Connection>& connection) {if (int32_t(count) >= 0) {Mutex::Autolock _l(mLock);const int32_t new_count = (count == 0) ? -1 : count;if (connection->count != new_count) {// 更新connection->countconnection->count = new_count;mCondition.broadcast();}}}// 请求接收下一次的VSync事件,请求一次,接收下一次VSyncvoid EventThread::requestNextVsync(const sp<EventThread::Connection>& connection) {Mutex::Autolock _l(mLock);mFlinger.resyncWithRateLimit();// 更新connection->countif (connection->count < 0) {connection->count = 0;mCondition.broadcast();}}
- setVsyncRate只需要指定一次,后续根据
vsync.count % connection->count == 0来接收VSync事件- requestNextVsync则是请求下一次VSync事件,请求一次,接收一次,View.invalidate和SF合成,都是使用这种方式。
上文有提到,当模拟的VSync模型与硬件VSync在一定误差内时,会关闭硬件VSync。那么随着时间推移,如果误差越来越大,如何调整模拟的硬件VSync模型那?
原来,SurfaceFlinger在处理Layer合成的最后一步(handleMessageRefresh -> postComposition)会通过addPresentFence把Present Fence交给DispSync, DispSync会检查Present Fence与模拟的VSync周期之间的误差,若误差偏大就会打开HWCVSync,重新走addResyncSample训练逻辑。核心代码如下所示:
// handleMessageRefresh -> postCompositionvoid SurfaceFlinger::postComposition(){const HWComposer& hwc = getHwComposer();sp presentFence = hwc.getDisplayFence(HWC_DISPLAY_PRIMARY);if (presentFence->isValid()) {if (mPrimaryDispSync.addPresentFence(presentFence)) {// 打开HWC VSync,重新训练DispSync的VSync模型enableHardwareVsync();} else {// 关闭HWC VSyncdisableHardwareVsync(false);}}}// 添加Present Fence,检查VSync模型误差bool DispSync::addPresentFence(const sp<Fence>& fence) {// 保存Present Fence,最大长度为NUM_PRESENT_SAMPLES,目前是8mPresentFences[mPresentSampleOffset] = fence;mPresentTimes[mPresentSampleOffset] = 0;mPresentSampleOffset = (mPresentSampleOffset + 1) % NUM_PRESENT_SAMPLES;mNumResyncSamplesSincePresent = 0;for (size_t i = 0; i < NUM_PRESENT_SAMPLES; i++) {const sp<Fence>& f(mPresentFences[i]);if (f != NULL) {nsecs_t t = f->getSignalTime();if (t < INT64_MAX) {mPresentFences[i].clear();// 记录Present Fence的时间戳mPresentTimes[i] = t + kPresentTimeOffset;}}}// 检查误差updateErrorLocked();// 若误差超过一定阈值,则返回true,表示需要重启硬件VSyncreturn !mModelUpdated || mError > kErrorThreshold;}// 检查已经保存的Present Fence与现有VSync周期的均方误差void DispSync::updateErrorLocked() {// Need to compare present fences against the un-adjusted refresh period, since they might arrive between two events.nsecs_t period = mPeriod / (1 + mRefreshSkipCount);int numErrSamples = 0;nsecs_t sqErrSum = 0;for (size_t i = 0; i < NUM_PRESENT_SAMPLES; i++) {// mReferenceTime表示之前记录的第一个硬件VSync时间戳nsecs_t sample = mPresentTimes[i] - mReferenceTime;if (sample > mPhase) {// 相对于现有VSync周期的误差nsecs_t sampleErr = (sample - mPhase) % period;if (sampleErr > period / 2) {sampleErr -= period;}// 求取误差平方和sqErrSum += sampleErr * sampleErr;numErrSamples++;}}// 计算出均方误差if (numErrSamples > 0) {mError = sqErrSum / numErrSamples;} else {mError = 0;}}
当
DispSync收到addPresentFence添加的Present Fence时(目前最多8个),会计算出Present Fence与现有VSync周期的均方误差,若均方误差超过常量:kErrorThreshold = 160000000000,就会打开硬件VSync,重新训练DispSync模拟的硬件VSync模型。
最后,总结下VSync模型的运转流程:当HWC发出VSync信号时,SurfaceFlinger将会收到回调并且发送给DispSync。DispSync将会记录这些硬件VSync时间戳,当累计了足够的硬件VSync以后(目前是大于等于6个),就开始计算VSync周期和偏移:mPeriod和mPhase。DispSyncThread将会利用mPeriod和mPhase模拟硬件VSync,并且通知对VSync感兴趣的Listener,这些Listener包括SurfaceFlinger和客户端APP。这些Listener以Connection形式注册到EventThread。DispSyncThread与EventThread通过DispSyncSource作为中间人进行连接。EventThread收到模拟的硬件VSync后,将会通知所有感兴趣的Connection,然后SurfaceFlinger开始合成,APP开始渲染。当收到足够多的硬件VSync并且在误差允许范围内,将会通过EventControlThread关闭HWC的硬件VSync。
通过流程图表示如下:
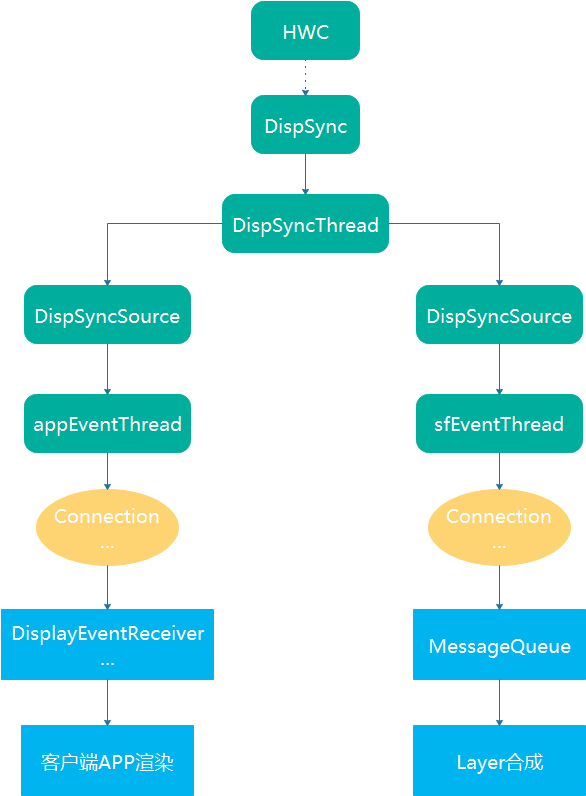
OK,上述分析了VSync事件的起源和分发逻辑,下面我们详细看下VSync事件的两种使用场景:一个是驱动SurfaceFlinger合成上屏;一个是驱动客户端APP UI渲染。
驱动SurfaceFlinger合成上屏
上文SurfaceFlinger::init代码中完成了MessageQueue与mSFEventThread的绑定,即MessageQueue向mSFEventThread注册了EventThread::Connection,并通过BitTube监听Connection写入的事件(通过EventThread::Connection::postEvent写事件到BitTube),例如:VSync和热插拔事件。核心代码如下所示:
// 主线程`MessageQueue`绑定`mSFEventThread`,void MessageQueue::setEventThread(const sp<EventThread>& eventThread){mEventThread = eventThread;// 创建EventThread::ConnectionmEvents = eventThread->createEventConnection();mEventTube = mEvents->getDataChannel();// 监听BitTube的方式(用Looper),一旦有数据到来则调用cb_eventReceiver(),this表示透传的参数mLooper->addFd(mEventTube->getFd(), 0, Looper::EVENT_INPUT,MessageQueue::cb_eventReceiver, this);}// 接收EventThread的VSync事件,分发到MessageQueue线程int MessageQueue::cb_eventReceiver(int fd, int events, void* data) {MessageQueue* queue = reinterpret_cast<MessageQueue *>(data);return queue->eventReceiver(fd, events);}// 创建的Connection在第一次被引用时,才会注册到EventThreadvoid EventThread::Connection::onFirstRef() {// 当第一次引用Connection时,就会把它添加到所属EventThread维护的Connection队列mEventThread->registerDisplayEventConnection(this);}
OK,MessageQueue向mSFEventThread注册EventThread::Connection后,就可以接收VSync事件了,那么SurfaceFlinger是一直接收VSync事件,还是按需请求的那?还记得上面介绍的connection->count吗?实际上是通过Connection::requestNextVsync按需请求的,这个“按需”就是指有Layer更新了。这里我们通过两个时序图详细看下:
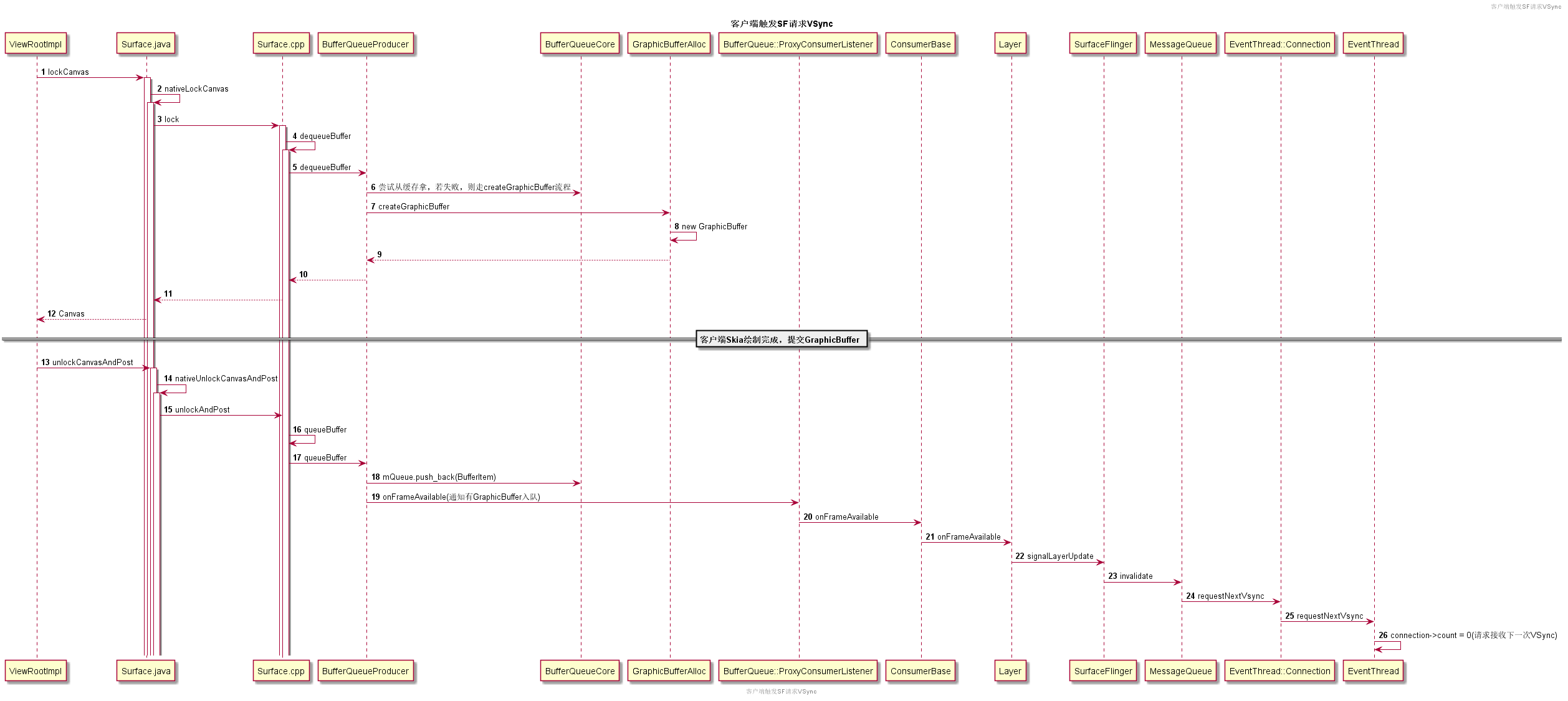
驱动SurfaceFlinger合成上屏的VSync是什么时候请求的:
SurfaceFlinger是怎么接收VSync信号的:
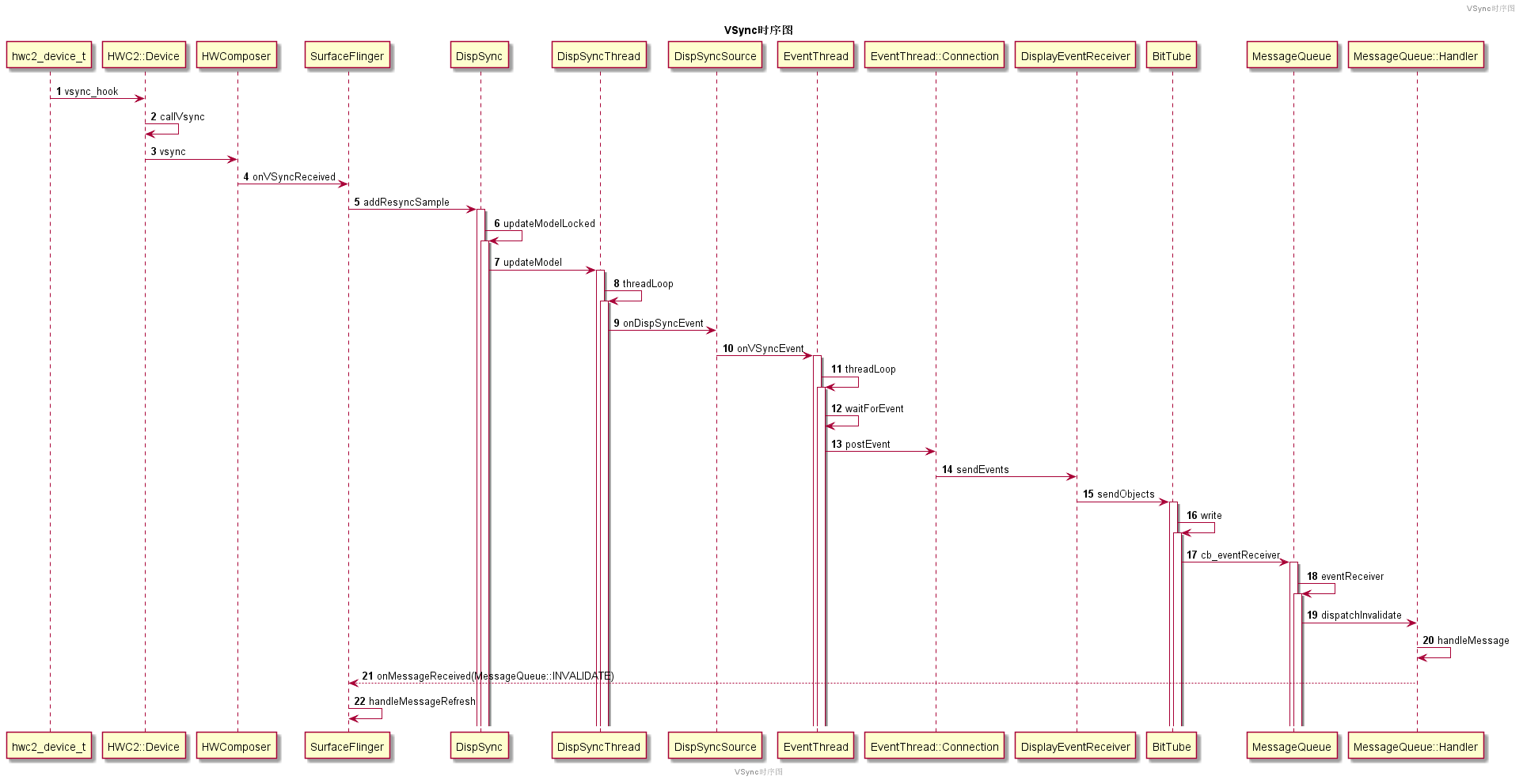
- 当View.invalidate调用后,最终会触发
ViewRootImpl向SurfaceFlinger的mEventThread请求接收下一次的VSync事件(后面详细介绍)。 - 客户端收到VSync事件后,最终通过
performTraversals触发View体系的绘制。 - 这里以软件绘制为例,通过
Surface拿到Canvas,Canvas底层实际对应的是从SurfaceFlinger申请的GraphicBuffer。当Canavs绘制完成后,通过Surface.unlockCanvasAndPost触发GraphicBuffer的入队流程,即通过BufferQueueProducer把GraphicBuffer入队到`BufferQueue。 - 入队后,通过
BufferQueueCore中的mConsumerListener回调一步步通知到SurfaceFlinger。 SurfaceFlinger通过MessageQueue向mSFEventThread请求下一次的VSync信号。- Vsync到来后,通过
MessageQueue分发到SurfaceFlinger主线程,并且最终通过handleMessageRefresh进行Layer的合成与上屏。
驱动客户端APP UI渲染
同样的,驱动客户端APP UI渲染的VSync逻辑,也可以分为客户端请求VSync信号和客户端接收VSync信号,一样可以通过两个时序图来看下:
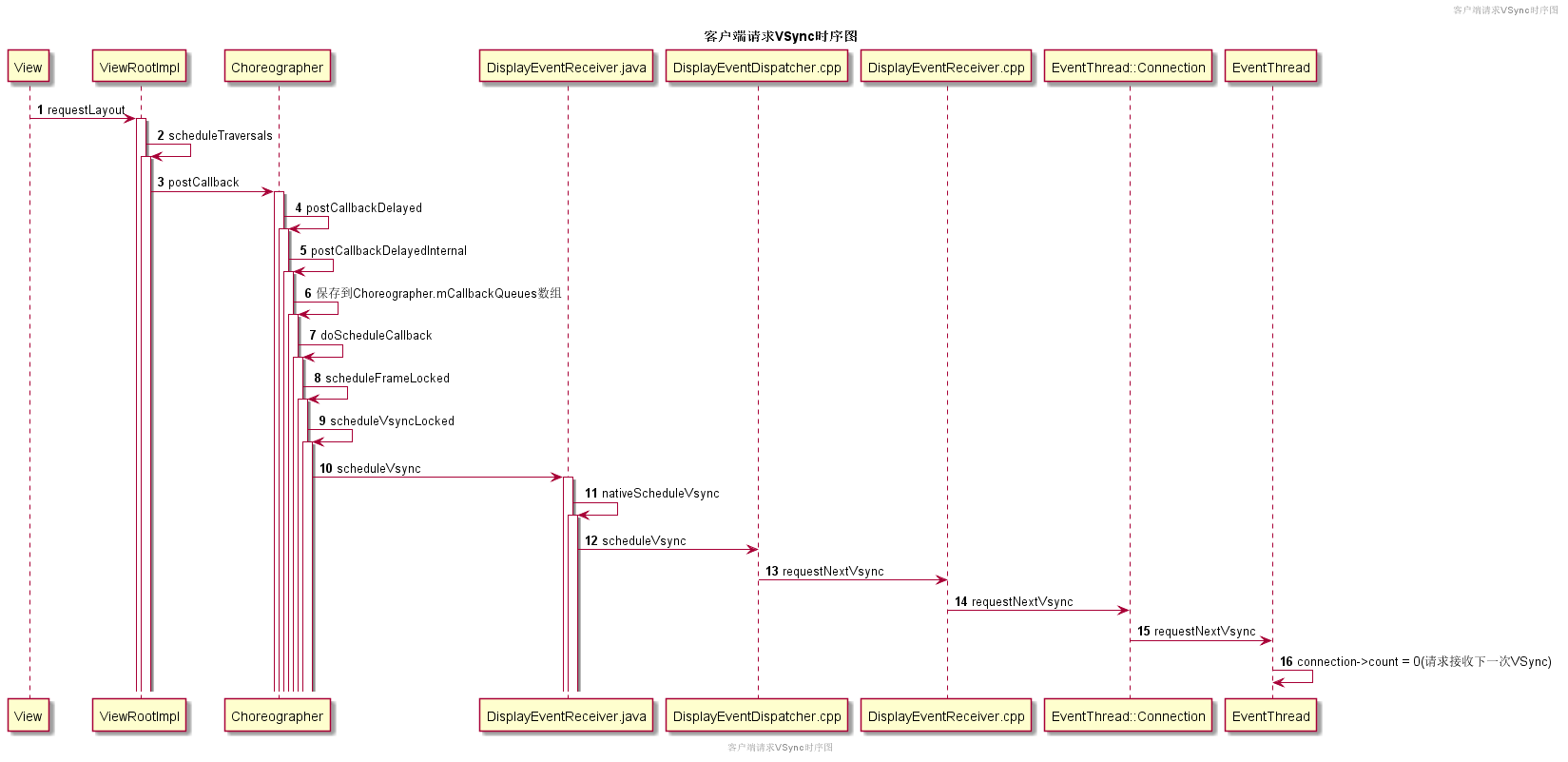
客户端请求VSync:
客户端接收VSync:
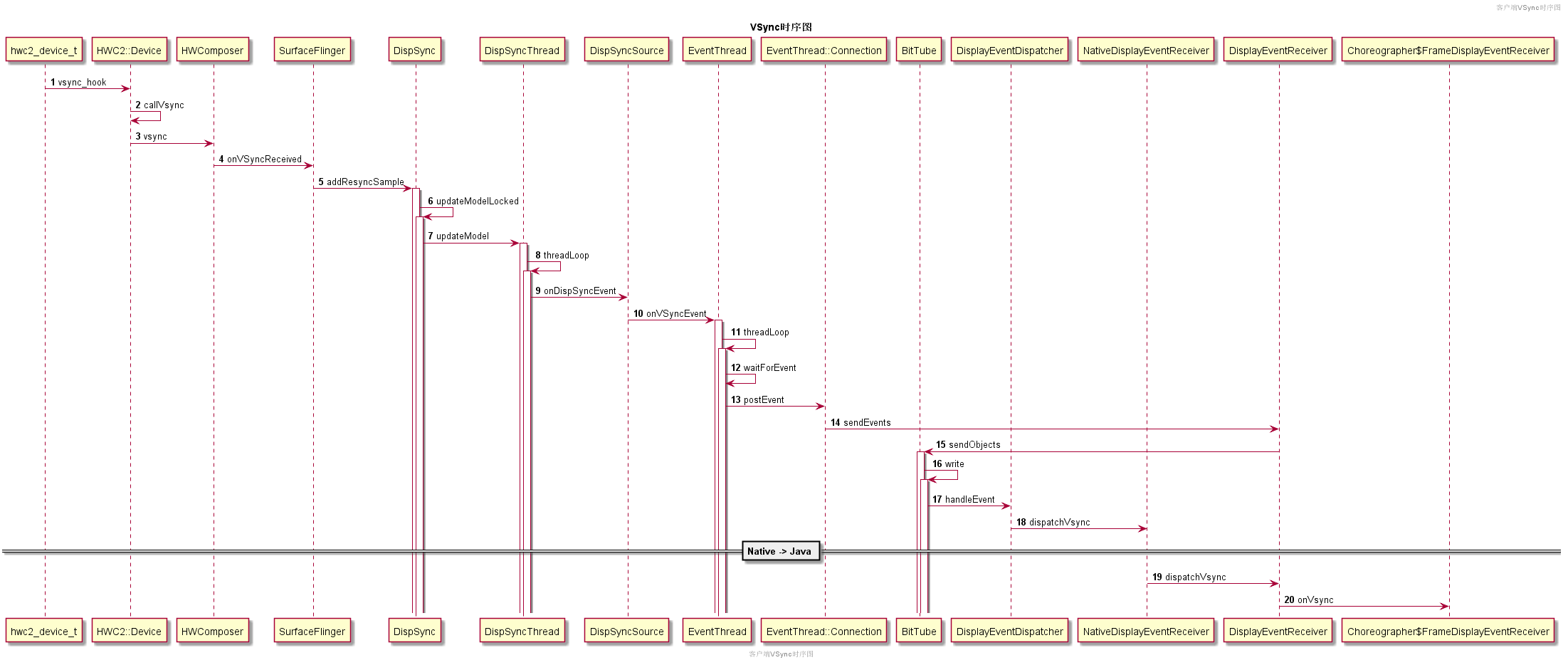
客户端APP怎么请求VSync事件那?实际是View请求重绘时,通过Choreographer向SurfaceFlinger的mEventThread线程请求接收下一次的VSync事件。
- 当View.invalidate调用后,最终会触发
ViewRootImpl向Choreographer注册一个TraversalRunnable。 Choreographer本地保存这个TraversalRunnable后,会通过DisplayEventReceiver.java调用到Native层,最终一步步调用到mEventThread线程,修改connection->count = 0(请求接收下一次VSync)。- Vsync到来后,会从
SurfaceFlinger进程一步步回调到客户端进程,最终触发ViewRootImpl之前注册TraversalRunnable,启动View树的渲染。
那么这里的EventThread::Connection是怎么注册到mEventThread线程的那?其实在创建DisplayEventReceiver就已经完成了注册,如下所示:
// DisplayEventReceiver的构造函数DisplayEventReceiver::DisplayEventReceiver() {// 跨进程获取SurfaceFlinger句柄sp<ISurfaceComposer> sf(ComposerService::getComposerService());if (sf != NULL) {// 向SurfaceFlinger的mEventThread线程注册ConnectionmEventConnection = sf->createDisplayEventConnection();if (mEventConnection != NULL) {// 需要监听的句柄mDataChannel = mEventConnection->getDataChannel();}}}// 添加感兴趣的Connection到mEventThread线程,用于通知客户端APP VSync事件sp<IDisplayEventConnection> SurfaceFlinger::createDisplayEventConnection() {return mEventThread->createEventConnection();}
VSync偏移
在基于VSync的渲染模型中,涉及到三个组件:APP、SurfaceFlinger和Display,它们都是在VSync到来时开始工作。假如我们请求了View重绘,那么整个渲染流程如下所所示:
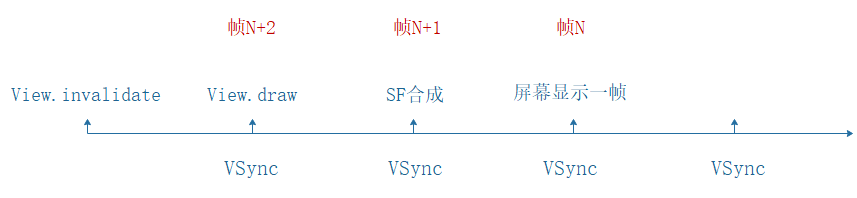
- View.invalidate请求重绘,通过
Choreographer请求接收下一个VSync信号。 - 第一个VSync信号到来时,View开始绘制,绘制完成后通过BufferQueue通知到SurfaceFlinger,
SurfaceFlinger通过MessageQueue请求接收下一个VSync信号。 - 第二个VSync信号到来时,
SurfaceFlinger开始合成Layer,并把结果交给HWC。 - 第三个VSync信号到来时,Display开始展示合成好的图像数据。
同时需要注意到:屏幕开始显示帧N时,SurfaceFlinger开始为帧N+1合成Layer,客户端开始处理View渲染并生成帧N+2,即:从View绘制到显示在屏幕上,延迟至少为两帧,大概33ms。
但是对大部分场景来说,APP渲染+SurfaceFlinger合成可能在16ms内就可以完成。为了缩短帧延迟,可以在设备的BoardConfig.mk文件中为驱动APP渲染和SurfaceFlinger合成的VSync信号分别配置时间戳偏移:VSYNC_EVENT_PHASE_OFFSET_NS 和SF_VSYNC_EVENT_PHASE_OFFSET_NS(即SurfaceFlinger::init中创建DispSyncSource时传入的vsyncPhaseOffsetNs与sfVsyncPhaseOffsetNs偏移)。若不设置,则默认都是0,即相对于模拟的硬件VSync信号,都没有时间戳偏移。
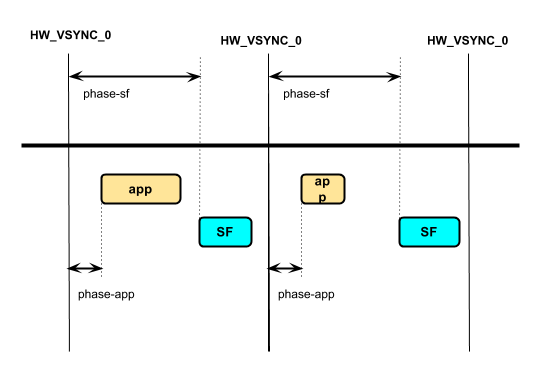
- VSync-App(驱动APP的VSync) = HW_VSync_0 + phase-app
- VSync-sf(驱动SurfaceFlinger的VSync) = HW_VSync_0 + phase-sf
理想情况下,App可以在phase-sf - phase-app时间内完成绘制,SurfaceFlinger可以在VSync周期 - phase-sf时间内完成合成,那么在下一个VSync信号时就可以上屏,即帧延迟为16ms。
但是若APP绘制耗时超过了phase-sf - phase-app,那就只能等到下一个VSync-sf信号才能开始合成,即等待SurfaceFlinger开始合成的时间由VSync周期变成了VSync周期 + phase-sf - phase-app,若同时SurfaceFlinger的合成耗时超过了VSync周期 - phase-sf,那么就要再等下一个VSync才能上屏,整体延迟了3帧,即将近50ms。所以一般情况下,系统都会将phase-sf - phase-app设置为VSync周期。
总结
本文主要介绍了VSync信号的来龙去脉,以及驱动客户端APP渲染和SurfaceFlinger合成上屏的逻辑。
