@lokvahkoor
2020-07-02T09:37:56.000000Z
字数 6103
阅读 1294
A Brief Summary of Activity Recognition
行为识别
研究背景
问题定义
目前,该领域中使用较多的数据集通常把行为识别问题简化为视频分类问题,即:给定一段裁剪好的视频片段,要求模型返回一个预定义的动作标签
传统解决方案
在深度学习应用于该领域之前,传统方法一般把该问题拆分成两个子问题进行处理:1. 行为表示(Action Representation) 2. 行为分类(Action Classification)。前者负责把一段视频转化为一个或一组特征编码,后者负责根据特征编码产生行为标签。
这类方案一般包含三个主要步骤:
- 通过密集或稀疏的兴趣点集来捕捉视频图片帧中的局部视觉特征
- 对各帧图片中提取到的视觉特征进行合并,得到整段视频的特征表示
- 训练分类器(如SVM或随机森林)针对视频特征进行分类
在传统方法中,效果最好的是improved Dense Trajectories算法(iDT算法)。该算法发表于2013年的ICCV,相关paper包括:
- Dense trajectories and motion boundary descriptors for action recognition
- Action recognition with improved trajectories
其中第一篇文章介绍了Dense Trajectories算法(DT算法),第二篇文章是针对DT算法的改进(iDT算法)
Dense Trajectories算法
DT算法的基本框架如图所示:
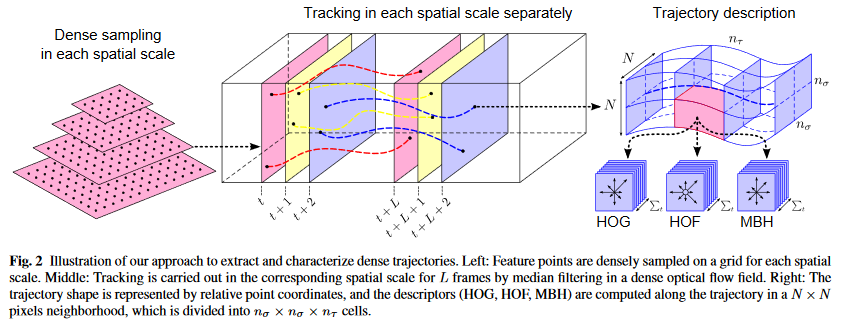
该算法的主要步骤包括:
- 对视频的每一帧图片进行不同尺度的缩放,然后在每个尺度的图片上通过网格划分的方式密集采样特征点
- 在时间序列上对之前采样得到的特征点进行跟踪,从而得到特征点的运动轨迹
- 对运动轨迹进行特征提取,把轨迹数据转化成特征向量
- 由于一段视频可以得到大量的轨迹,且每段轨迹都对应着一组轨迹特征。所以要对所有的轨迹特征进行汇总编码,整合成一段定长的视频特征编码序列
- 最后,使用SVM构建分类器对视频编码序列进行分类
improved Dense Trajectories算法
iDT算法是在DT算法基础上做出的改进,其基本流程与DT算法差异不大。最核心的优化是通过评估镜头运动轨迹,来区分图像中背景运动的光流和人物动作的光流,从而获取更具代表性的轨迹特征:

上图中第一行是视频中连续的两帧图像叠加在一起的图像;第二行是DT算法从两帧图像中抽取的光流;第三行的图像去除了运动镜头带来的背景光流;第四行展示了镜头运动与人物动作在光流特征上的区分,绿色轨迹是人物动作对应的光流,白色轨迹是镜头运动带来的光流
除了对光流特征的优化,iDT在轨迹特征的归一化方式和视频特征的编码方式上也采用了更先进的算法,最后使算法性能得到了显著的提升:在UCF50数据集上的准确率从84.5%提高到了91.2%,在HMDB51数据集上的准确率从46.6%提高到了57.2%
iDT算法存在的问题:
- 特征维度很高:特征文件大小远大于原始视频
- 计算时间消耗比较大
- 识别准确率难以进一步提升
因此该算法在真实场景中的应用较为困难,该领域的研究热点自2014年开始逐步转向深度学习模型
基于神经网络的方法
2014年,该领域出现了两篇极具前瞻性的研究工作,它们奠定了近几年行为识别网络模型的基本架构:
Approach 1: Single Stream Network
在这篇论文6中,作者探索了使用2D预训练卷积网络来捕捉视频(也就是图像序列)中连贯信息的多种架构:
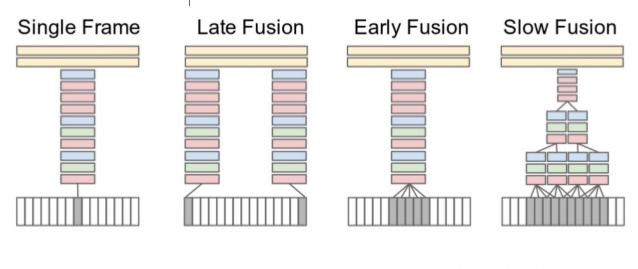
上图中,底部的灰白网格代表图像序列,中间彩色的堆叠方格是用来提取图像特征的卷积网络,顶部土黄色的长条方格代表产生最终预测结果的分类器。
经过了广泛的实验探索,最终学者们发现这类架构在效果上还是比不过传统方法。主要原因有两点:
- 模型学到的时空特征难以捕捉视频中的运动信息
- 当时的数据集缺乏类别多样性,该模型在洞察图像细节特征方面不具备优势
Approach 2: Two Stream Networks
在这篇论文7中,作者吸取了Single Stream Network的失败经验,提出用堆叠的光流来对视频的运动特征进行建模。与前文提到的单流模型不同,这篇文章使用了两个独立的网络模型,一个接收单张图片以捕捉空间信息,一个接收多张图片堆叠的光流特征以捕捉时间信息:

两个模型将独立地进行训练,最后通过SVM进行结果整合。该模式显著地提升了网络的性能,但仍存在一些缺陷:
- 难以捕捉时间跨度较长的视频片段中的运动特征信息
- 有时行为或动作实际上只发生在视频的某一个片段内,但该方案假设整段视频都在描述这个行为或动作(这意味着数据标注上的瑕疵,因为光流网络每次只能接收视频中一小部分的图片帧)
- 该方案采用了预先计算好的光流矢量(pre-computing optical flow vectors),因此离理想的end2end方案还有较大的差距
有代表性的深度网络模型
自上面两篇论文发表后,行为识别领域衍生出了一系列以深度神经网络为基础的算法模型,包括:
这些方法在结构上可大致分为以下几类9:
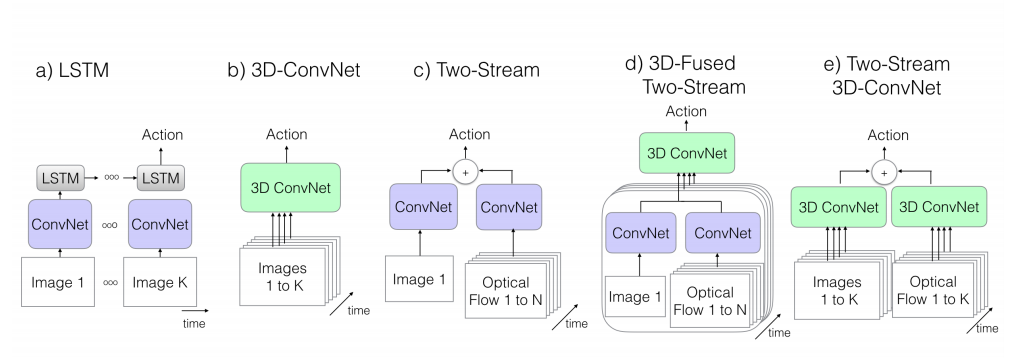
第一类方案:ConvNet+RNN
这类算法以LRCN为代表。由于2D卷积网络在图像特征提取上的出色性能,当时很多研究者用它来提取视频单帧图像中的特征,然后通过加权平均或Temporal Pooling10等方法整合出整个视频的特征向量。但这类算法很容易抹去图像特征组的时序信息,这意味着下游的分类模型可能无法区分事件或动作的前后关系(比如一扇门是由开到关还是由关到开)
LRCN提出先用2D卷积网络来提取视频每一帧图像中的空间特征,然后把2D卷积网络的输出作为RNN的输入,以捕捉视频中的时序特征:
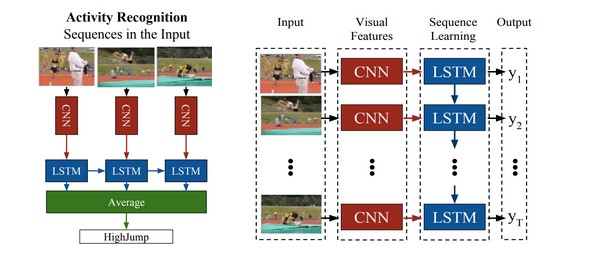
该方法在UCF101数据集上取得了当时较好的结果:

更进一步,可以在RNN模块中引入attention机制11,通过与NLP技术相结合,实现视频内容描述(Producing natural language descriptions of videos):
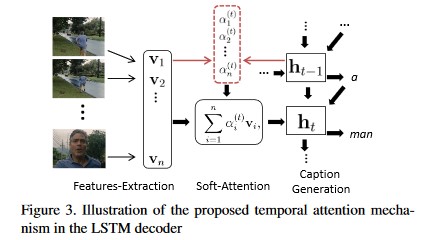
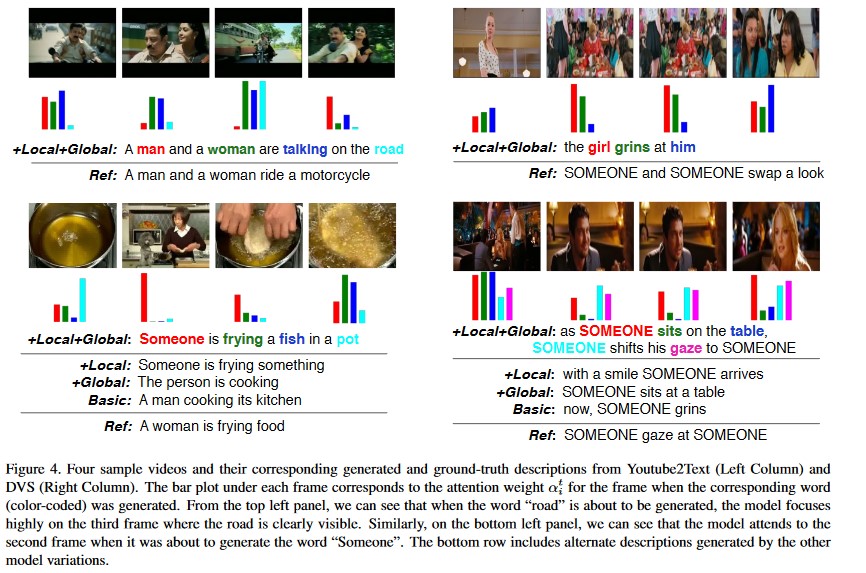
第二类方案:3D ConvNets
这类算法以C3D为代表,通过卷积网络的前两个维度来捕捉图像的空间特征,通过第三个维度来捕捉连续图像帧之间的时间特征:

在论文中,作者先用3D卷积网络在Sports1M数据集上进行训练,接着把训练好的网络作为特征抽取模块,用在其他的行为识别数据集上。作者发现,通过预训练模块进行特征抽取后,只需要再接一个线性分类器(如SVM),实现的整体效果就能超过当时最先进的行为识别算法:

第三类方案:Two-Stream Networks
双流网络是目前解决行为识别问题的主流架构,相比于CNN+RNN或C3D模型,双流网络拥有更高的训练效率和更快的测试速度。这类方案以Simonyan7的算法为基础,涵盖了一系列混合多种结构的网络模型,其中有代表性的方案包括:TwoStreamFusion,TSN,HiddenTwoStream,I3D等,接下来分别介绍其核心架构和性能表现:
TwoStreamFusion
TwoStreamFusion在经典双流模型的基础上提出了一个新的模型架构:通过融合图像和光流网络,使得模型在不显著增加参数量的前提下,获得了较为明显的性能提升
作者在论文中举例:假设模型需要区分洗头动作和刷牙动作,那么基于单张图像的颜色特征可以让模型辨认牙齿和头发,而基于多张图像的光流特征可以让模型确认整个过程中是否发生了周期性运动。作者认为:如果图像和光流网络提取的特征对彼此具有指导意义,那么就应该尽早地对两个网络的数据进行融合,而不是像经典双流模型那样放在最后来做
作者探索了两个网络相融合的多种架构,下图为其中的两个例子:
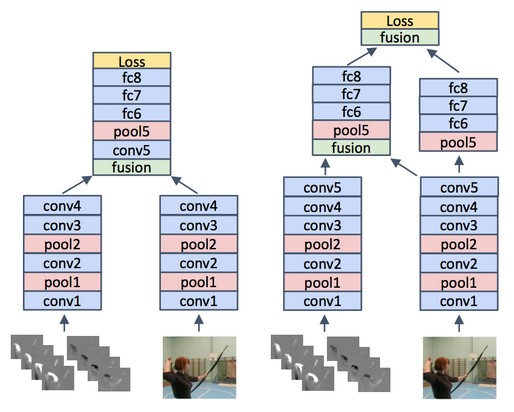
左边的模型在经过四个卷积层后进行融合,而右边的模型则进行了多次融合。实验中右边的模型结构能够取得更好的性能表现:
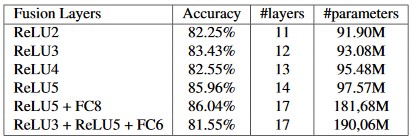
TSN
TSN主要针对是经典双流模型难以处理时长较长的视频样本的问题。该方案先将视频样本分割为等长的K段,然后在每一段视频片段中进行随机采样,接着把采样结果送入多个共享参数的卷积网络进行处理:
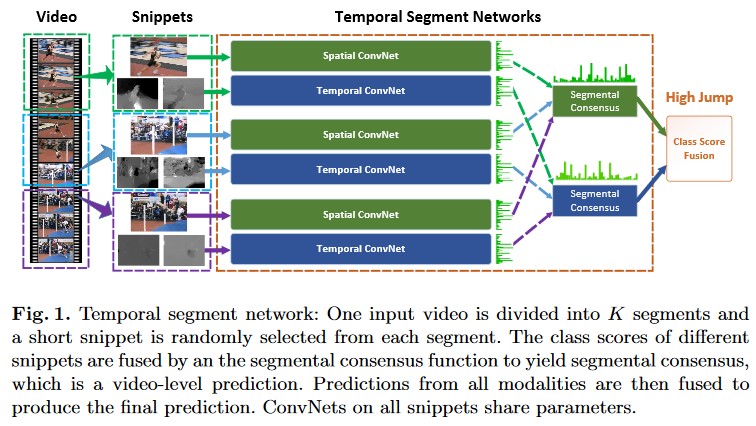
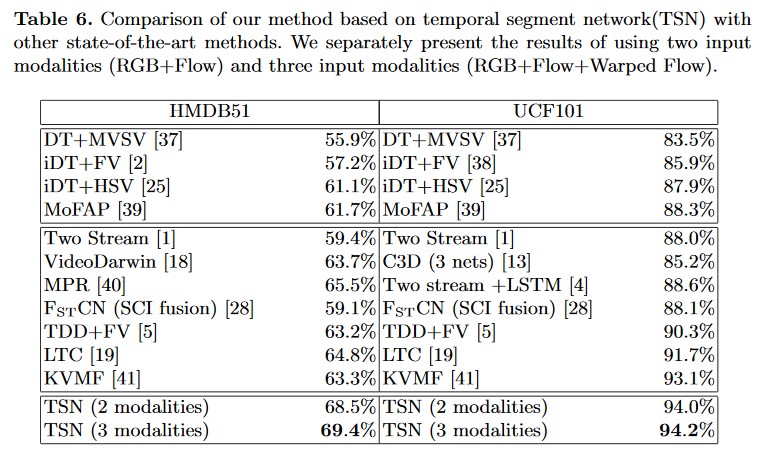
同时,作者在实验中还充分探索了当时较新的batch normalization, dropout和pre-training技术在双流模型中的应用,综合下来使该方案达到了当时基准数据集上最优的性能表现:
HiddenTwoStream
经典双流模型所依赖的光流数据一般都是预先计算好的,这个计算过程既消耗时间,也消耗大量的存储空间。HiddenTwoStream的作者找到了一个能够从图像中自动且无监督地提取光流特征的网络模型MotionNet,使双流模型不再依赖于手工计算的光流特征:
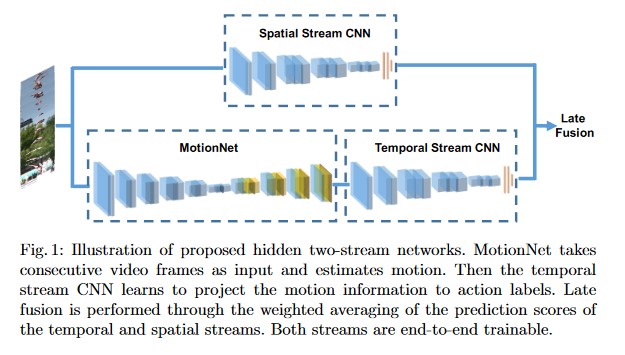
MotionNet是通过图像重建任务进行训练的:模型首先接收一对原始图像帧和,接着通过CNN产生一个光流场,然后用生成的光流场和图像帧来重建输入数据中的另一幅图像帧,并期望与之间的差异尽可能地小
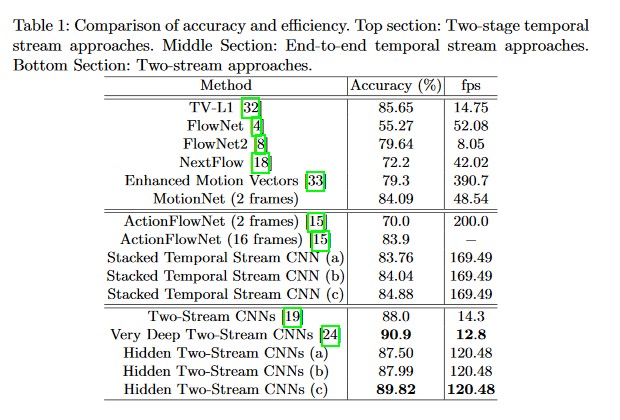
实验表明:MotionNet和HiddenTwoStream模型在极大地提升模型计算效率的同时,也很好地保持了识别精度的稳定:
I3D
I3D模型在经典双流模型的两个网络模块前各接了一个3D卷积层,使得以往接收单帧图像的空间网络(spatial stream)可以像光流网络那样,一次性接收一组图像帧。同时,为了利用2D预训练卷积模型的优异性能,作者探索了一种通过重复堆叠2D预训练模型的参数,来构造预训练卷积核的第三个维度的方法。该方案在UCF101数据集上展现了较好的性能:
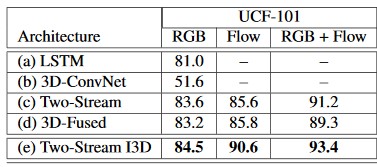
同时,论文作者提出了一个新的行为识别基准数据集Kinetics,结合该数据集进行预训练的I3D模型在UCF101上的准确率高达98%:
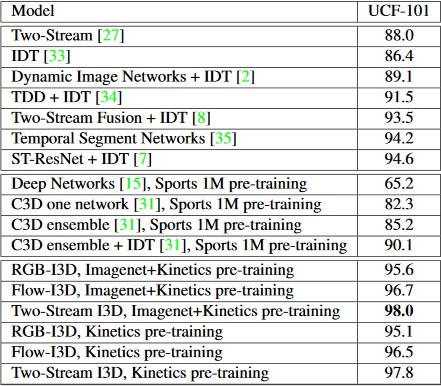
基准数据集与SOTA模型
目前,该领域使用人数较多的基准数据集包括:HMDB-51,UCF-101和Kinetics-400。三个数据集的基本参数对比如下:
| 名称 | 视频数目 | 行为类别数目 |
|---|---|---|
| HMDB-51 | 6,766 | 51 |
| UCF-101 | 13,320 | 101 |
| Kinetics-400 | 306,245 | 400 |
三个数据集上的SOTA方案排名如下:
HMDB-51
| 排名 | 方法名 | 准确率 | 论文标题 | 发布时间 |
|---|---|---|---|---|
| 1 | HAF+BoW/FV halluc | 82.4 | Hallucinating IDT Descriptors and I3D Optical Flow Features for Action Recognition with CNNs | 2019 |
| 2 | EvaNet | 82.1 | Evolving Space-Time Neural Architectures for Videos | 2018 |
| 3 | CCS + TSN | 81.9 | Cooperative Cross-Stream Network for Discriminative Action Representation | 2019 |
UCF-101
| 排名 | 方法名 | 准确率 | 论文标题 | 发布时间 |
|---|---|---|---|---|
| 1 | LGD-3D Two-stream | 98.2 | Learning Spatio-Temporal Representation with Local and Global Diffusion | 2019 |
| 2 | Two-stream I3D | 98.0 | Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset | 2017 |
| 3 | MARS+RGB+Flow | 97.8 | MARS: Motion-Augmented RGB Stream for Action Recognition | 2019 |
Kinetics
| 排名 | 方法名 | VIDEO HIT@1 | 论文标题 | 发布时间 |
|---|---|---|---|---|
| 1 | R(2+1)D-152 | 81.3 | Large-scale weakly-supervised pre-training for video action recognition | 2019 |
| 2 | SlowFast+NL | 79.8 | SlowFast Networks for Video Recognition | 2018 |
| 3 | ir-CSN-152 | 78.5 | Video Classification with Channel-Separated Convolutional Networks | 2019 |
References
- Deep Learning for Videos: A 2018 Guide to Action Recognition
- [行为检测|行为识别]调研综述
- Kong Y, Fu Y. Human action recognition and prediction: A survey[J]. arXiv preprint arXiv:1806.11230, 2018.
- Herath S, Harandi M, Porikli F. Going deeper into action recognition: A survey[J]. Image and vision computing, 2017, 60: 4-21.
- A Comprehensive Survey of Vision-Based Human Action Recognition Methods
- Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2014: 1725-1732.
- Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Advances in neural information processing systems. 2014: 568-576.
- Action Recognition with Improved Trajectories论文笔记
- Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
- Rank Pooling for Action Recognition
- Describing Videos by Exploiting Temporal Structure
- Action Recognition In Videos Leaderboards
