@lokvahkoor
2020-05-09T01:46:37.000000Z
字数 2301
阅读 2100
LSTM / GRU / Attention / Transform
NLP
LSTM
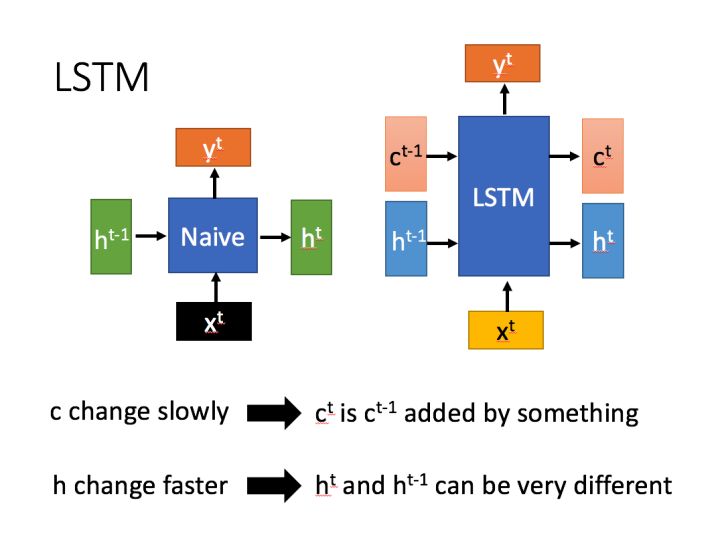
LSTM有两个传输状态,一个 (cell state),和一个 (hidden state)
保存模型的长期记忆,在训练过程中改变的速度较慢, 而在训练过程中变化的速度则比较快。
计算过程
首先使用LSTM的当前输入和上一个状态传递下来的拼接计算得到四个中间变量:
这里的分别代表input gate, foget gate, output gate。运算符表示把a和b拼接成一个大的矩阵。
接下来:
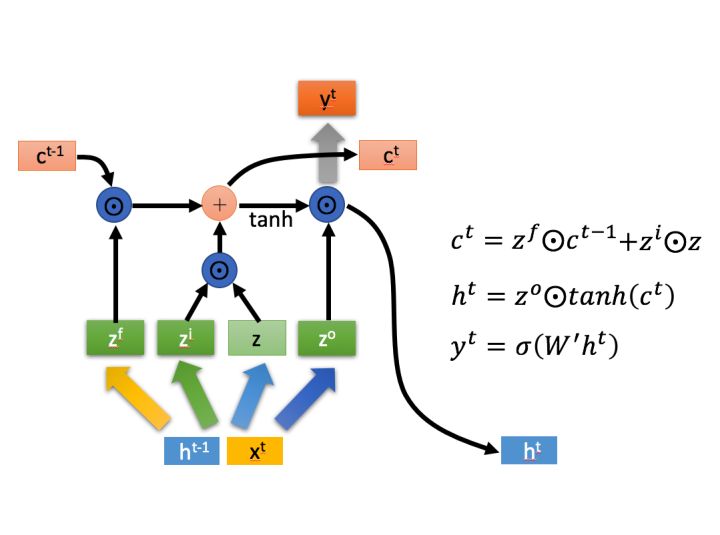
上图中 代表Hadamard Product,也就是操作矩阵中对应的元素相乘。 运算符 表示矩阵加法。
首先,作为遗忘门控,筛选上一个中哪些内容需要遗忘。
接着,作为输入门控,对模型输入 中的内容进行筛选,然后把筛选后的结果合并到中。
最后,使用 对进行放缩,然后经输出门控过滤,再通过一个全链接layer,得到模型输出。
peephole connections
在原本拼接的基础上,再拼上cell state,即:
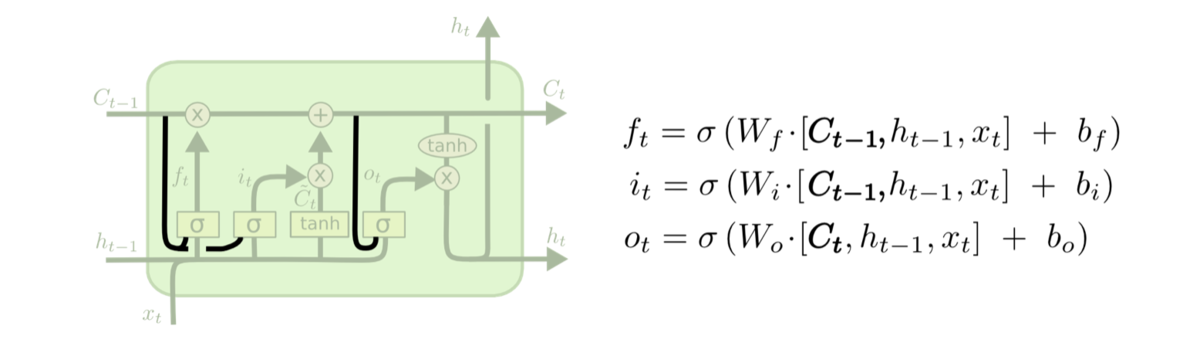
这样使得各个门结构可以看到cell state中的信息,在某些场景下提高了模型训练效果
GRU
由于LSTM的参数过多,所以其训练难度相对较大。因此,我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
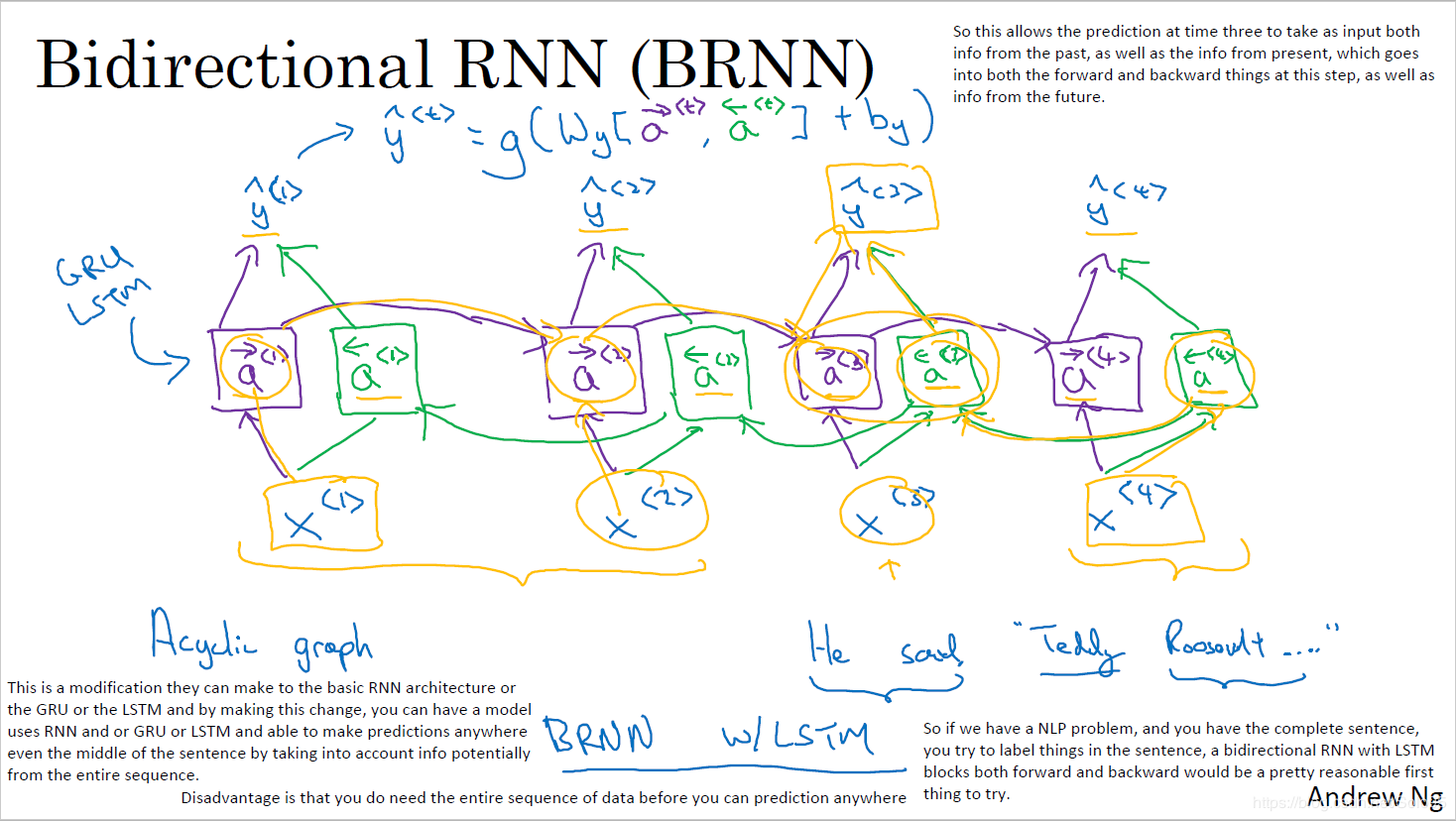
双向RNN
论文:Bidirectional recurrent neural networks
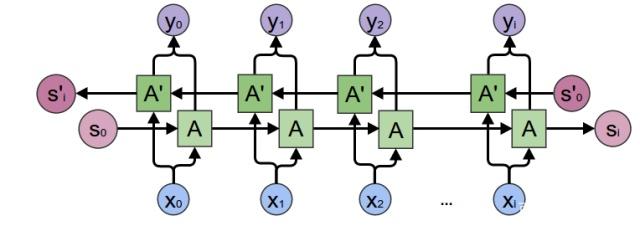
由于模型在理解句子时,常常需要完整的句子信息(既包含输入词前面的内容,也包含输入词后面的内容),因此双向RNN诞生了。
双向RNN有两种类型的连接,一种是向前的,这有助于我们从之前的表示中进行学习,另一种是向后的,这有助于我们从未来的表示中进行学习。
正向传播分三步完成:
- 我们从左向右移动,从初始时间步骤开始计算值,一直持续到到达最终时间步骤为止;
- 接我们从右向左移动,从最后一个时间步骤开始计算值,一直持续到到达最终时间步骤为止;
- 最后我们根据刚才算得的两个方向的,来计算模型的最终输出
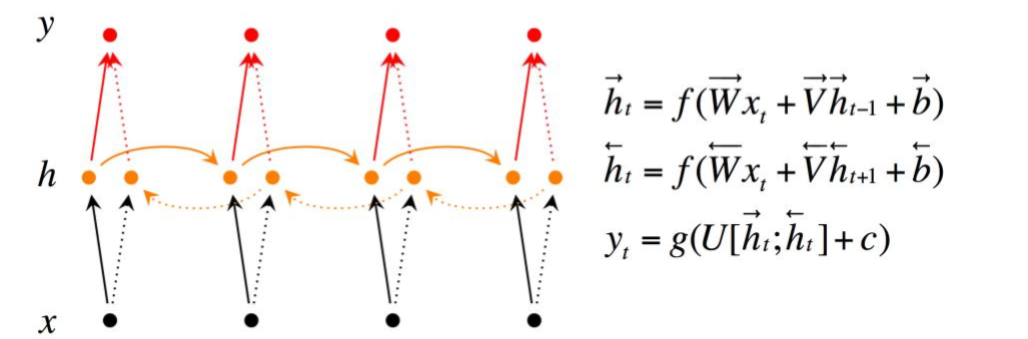
这里的分号代表把两个向量连接在一起
Attention
CS224n 从机器翻译到Attention 这个从45:28开始看
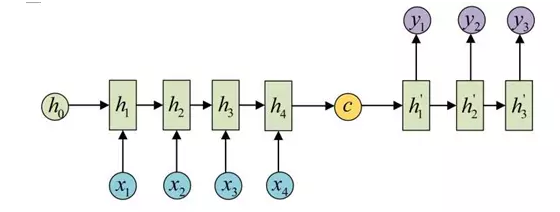
基于RNN的机器翻译模型存在一个问题,就是模型在翻译时依赖于输入序列最后传递的隐藏层参数(如下图中的),如果前面输入的句子是个长句,则模型在翻译时很容易遗忘前面输入的句子。
Attention机制让模型在翻译时可以读到输入序列的所有隐藏层状态()并且自由地选择哪些是它需要关注的东西,因此在一定程度上解决了上述问题。
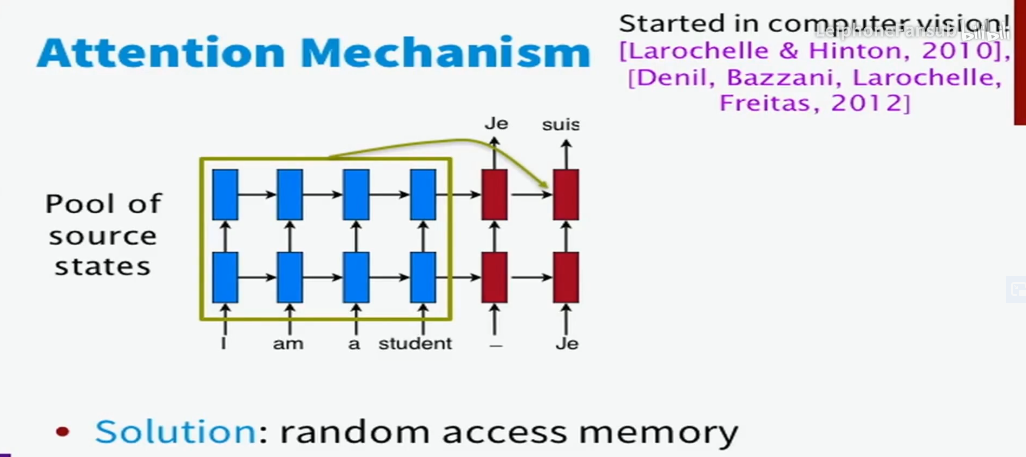
因此,我们可以说,attention机制使得翻译系统可以利用更多的上下文信息(数据也证明了这一点,因为带有attention的模型在长句的翻译上表现得更加出色)

self-attention机制可以理解为一个新的layer,它和RNN一样,输入一个sequence,输出一个sequence:
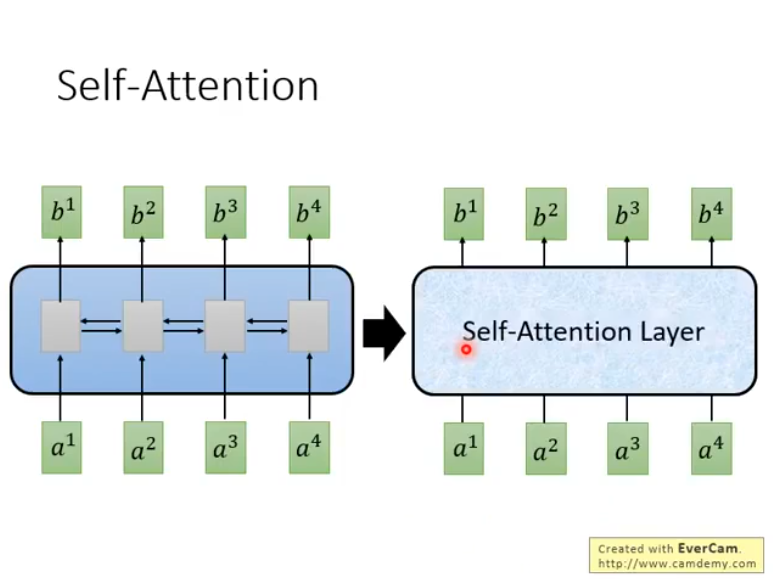
它出自谷歌2017年发布的paper:Attention Is All You Need
那么它具体是怎么工作的呢?
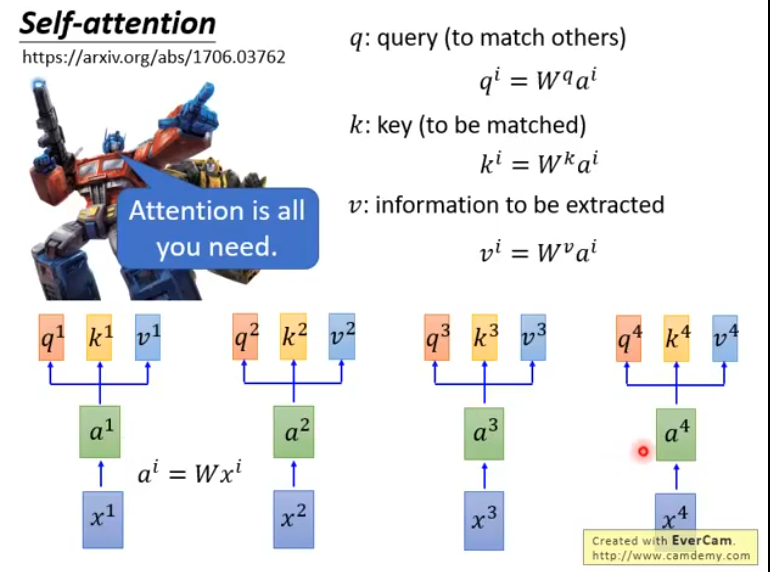
首先,是一串输入序列,对于每一个,我们让它通过一个全链接层得到embedding:,也就是, 接下来,让分别乘以三个不同的矩阵, , 得到, , 三个不同的向量,它们分别代表query, key和information to be extracted
接下来,拿每一个对每一个做attention,以为例:
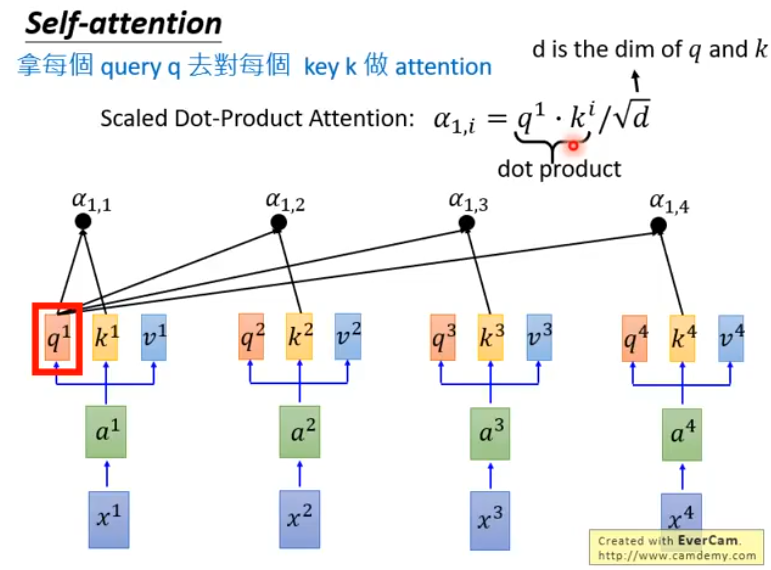
这里展示的只是一种attention的做法(Scaled Dot-Product Attention),除此之外,还有很多种计算Attention的方法,包括:
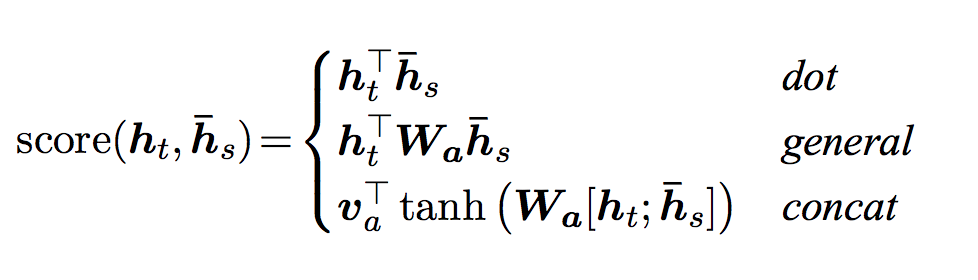
它们有一个共同的特征:都是吃两个向量,然后输出一个值,代表由这两个向量计算出的得分
接下来,让得到的通过一个softmax layer,得到:
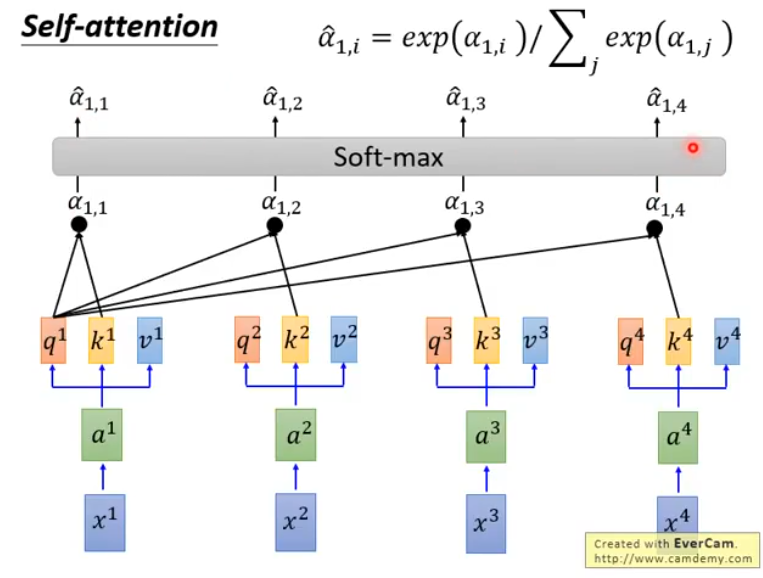
然后,我们把和每一个相乘,并把结果累加起来,得到:
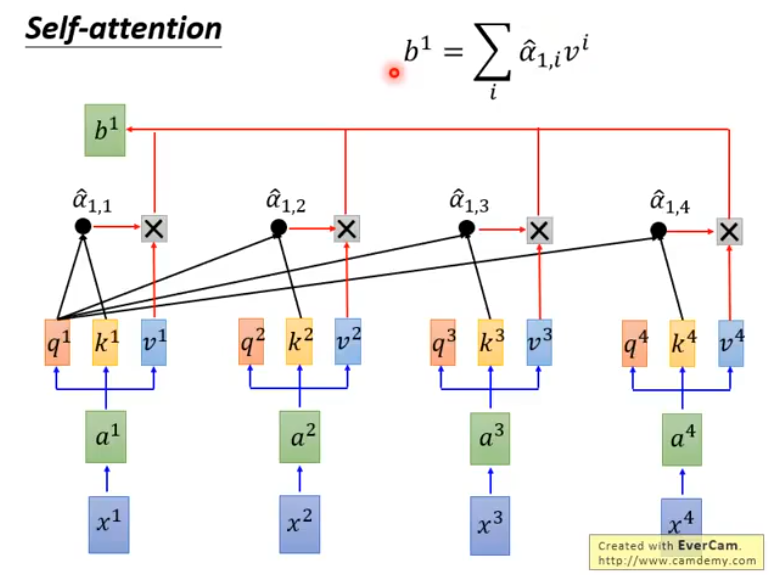
以此类推,得到的就是self-attention的输出序列了。与一般的RNN不同的是,模型输出的每一个都考虑了从输入序列中获取的全部信息。
Transformer
Bert
参考:
