@huangyichun
2018-04-04T11:50:44.000000Z
字数 7803
阅读 1158
面试问题总结
面试
- 计算机网路
- 数据库,Mysql
- Redis数据库
- 分布式设计
- 设计模式
- Java虚拟机
- Java基础知识,容器
- Java多线程
- 框架问题
我的面试问题:
进程和线程的区别
进程是资源分配合调度的基本单位,线程是cup调度和分配的基本单位。一个进程中可以有多个线程,这些线程共享着进程的资源和内存空间,而且每个线程都有自己的栈内存空间。
进程间通信
管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的
IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
Java程序中占cpu过高排查
通过top命令查看当前CPU情况
先获得PID为2023的进程号,查看相应线程获得线程ID
再通过jstack命令获取当前线程栈
mysql中count(*)和count(1),count(列名)区别
采用 Innodb下count(*)和count(1)没有什么区别。
在没有where语句中,count(*)速度还是很快的。
例如:SELECT COUNT(*) FROM student;
给两个有序数组求两个的中位数
/*** 两个有序数组求中位数* 思路:每次删除 k / 2个最大或者最小的数*/public class MedianOfTwoSortedArrays {public static void main(String[] args) {int[] A = new int[]{1};int[] B = new int[] {1};double num = findMedianSortedArrays(A, B);System.out.println(num);}public static double findMedianSortedArrays(int A[], int B[]) {int len = A.length + B.length;if (len % 2 == 1) {return getKthNum(A, 0, B , 0, len / 2 + 1);}else {return (getKthNum(A, 0, B , 0, len / 2 ) + getKthNum(A, 0, B , 0, len / 2 + 1)) / 2.0;}}public static int getKthNum(int[] A, int start_A, int[] B, int start_B, int k) {if (start_A >= A.length) { //当A数组为空return B[start_B + k -1];}if (start_B >= B.length){ //当B数组为空return A[start_A + k -1];}if (k == 1) { //当k为1时return Math.min(A[start_A], B[start_B]);}int A_key = start_A + k / 2 - 1 < A.length ? A[start_A + k / 2 -1] : Integer.MAX_VALUE; //找到A数组 k/2-1的位置int B_key = start_B + k / 2 - 1 < B.length ? B[start_B + k / 2 - 1] : Integer.MAX_VALUE; //找到B数组 k/2 - 1位置if (A_key < B_key) { //删除A小于的部分return getKthNum(A, start_A + k / 2, B, start_B, k - k / 2);}else{ //删除B小于的部分return getKthNum(A, start_A, B, start_B + k / 2, k - k /2);}}}
mysql事务级别
Read Uncommitted(读取未提交内容)在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。Read Committed(读取提交内容)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。Repeatable Read(可重读)这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。Serializable(可串行化)这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
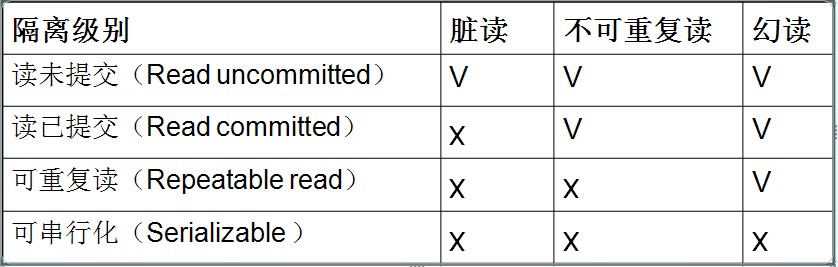
脏读:主要是对于查询语句,当事务A读取事务B修改后未提交数据,由于B提交出错,事务回滚,事务A读到的数据是无效的。不可重复读:主要是针对update更新语句,当事务A两次读取的数据不相同,由于事务B对A读取的数据进行了更新幻读:主要针对insert语句,事务A两次查询表的个数不一致,可能由于在A两次查询之间,事务B对表中插入新的数据。
mysql int(M)代表什么意思
这里的M代表的并不是存储在数据库中的具体的长度,以前总是会误以为int(3)只能存储3个长度的数字,int(11)就会存储11个长度的数字,这是大错特错的。其实当我们在选择使用int的类型的时候,不论是int(3)还是int(11),它在数据库里面存储的都是4个字节的长度,在使用int(3)的时候如果你输入的是10,会默认给你存储位010,也就是说这个3代表的是默认的一个长度,当你不足3位时,会帮你不全,当你超过3位时,就没有任何的影响。要查看出不同效果记得在创建类型的时候加 zerofill这个值,表示用0填充,否则看不出效果的。
已经有synchronized,为什么还要其他锁
Java栈和堆有什么区别
用过的线程安全的容器
准备:
1. CountDownLatch与CyclicBarrier区别
CountDownLatch和CyclicBarrier可以让一组线程等待其他线程,CountDownLatch初始化传入一个int类型的参数,代表你要等待的线程个数,而且初始化后将无法修改这个值。等待线程调用await()方法,被等待线程调用c.countDown(),int传入的值减1,,当值为0时,等待线程运行。
CyclicBarrier可以调用reset()方法重置,所以CyclicBarrier可以运用于更复杂的场景。而且CyclicBarrier构造参数可以传入int类型和一个Runnable对象。当到达等待点时,先运行传入Runnable对象的run方法。
2. ThreadLocal变量
ThreadLocal变量是java一种特殊的变量,在并发编程中,成员变量的使用是不安全的,而采用ThreadLocal变量则可以避免这个问题,使用ThreadLocal可以通过它的set方法将一个值绑定在线程上,然后调用get方法获取。它相当于给每个变量拷贝了一个副本,所以避免了同步问题。单例模式是个特例,我进行测试了,两个对象的hashcode相同。
3. volatile 关键字作用
对于volatile关键字修饰的变量进行写操作,会产生一个Lock前缀的指令,该指令具有两个作用
1. 将当前处理器缓存行的数据写回系统内存
2. 这个写回内存的操作会使其他CPU里缓存该内存地址的数据无效。
然后聊聊java内存模型
4. mylsam与innodb区别
MyISAM缓存在内存的是索引,不是数据。而InnoDB缓存在内存的是数据,相对来说,服务器内存越大,InnoDB发挥的优势越大。
优点:查询数据相对较快,适合大量的select,可以全文索引。
缺点:不支持事务,不支持外键,并发量较小,不适合大量update
InnoDB:
这种类型是事务安全的。.它与BDB类型具有相同的特性,它们还支持外键。InnoDB表格速度很快。具有比BDB还丰富的特性,因此如果需要一个事务安全的存储引擎,建议使用它。在update时表进行行锁,并发量相对较大。如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。
优点:支持事务,支持外键,并发量较大,适合大量update
缺点:查询数据相对较快,不适合大量的select
5. Java内存模型
6. synchronized关键字
Synchronized主要是对方法和代码块加锁,它实现内存的可见性和程序运行的原子性。它的本质是对一个对象的监视器进行获取,而这个获取过程具有排他性,因此同一时刻只能有一个线程获取到由synchronied所保护的对象的监视器。对于未获得监视器的线程在同步队列中等待,线程状态变为阻塞。当线程释放锁后,唤醒阻塞在同步队列中的线程。
7. 悲观锁和乐观锁
悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证,采用的是排它锁实现的。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;另外,在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还有会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数。
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
8. 避免死锁的四个条件
互斥条件:一个资源每次只能被一个进程使用。
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
9. Mysql优化
作者:zhuqz链接:https://www.zhihu.com/question/19719997/answer/81930332来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。很多人第一反应是各种切分;我给的顺序是:第一优化你的sql和索引;第二加缓存,memcached,redis;第三以上都做了后,还是慢,就做主从复制或主主复制,读写分离,可以在应用层做,效率高,也可以用三方工具,第三方工具推荐360的atlas,其它的要么效率不高,要么没人维护;第四如果以上都做了还是慢,不要想着去做切分,mysql自带分区表,先试试这个,对你的应用是透明的,无需更改代码,但是sql语句是需要针对分区表做优化的,sql条件中要带上分区条件的列,从而使查询定位到少量的分区上,否则就会扫描全部分区,另外分区表还有一些坑,在这里就不多说了;第五如果以上都做了,那就先做垂直拆分,其实就是根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;第六才是水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key,为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;mysql数据库一般都是按照这个步骤去演化的,成本也是由低到高;有人也许要说第一步优化sql和索引这还用说吗?的确,大家都知道,但是很多情况下,这一步做的并不到位,甚至有的只做了根据sql去建索引,根本没对sql优化(中枪了没?),除了最简单的增删改查外,想实现一个查询,可以写出很多种查询语句,不同的语句,根据你选择的引擎、表中数据的分布情况、索引情况、数据库优化策略、查询中的锁策略等因素,最终查询的效率相差很大;优化要从整体去考虑,有时你优化一条语句后,其它查询反而效率被降低了,所以要取一个平衡点;即使精通mysql的话,除了纯技术面优化,还要根据业务面去优化sql语句,这样才能达到最优效果;你敢说你的sql和索引已经是最优了吗?再说一下不同引擎的优化,myisam读的效果好,写的效率差,这和它数据存储格式,索引的指针和锁的策略有关的,它的数据是顺序存储的(innodb数据存储方式是聚簇索引),他的索引btree上的节点是一个指向数据物理位置的指针,所以查找起来很快,(innodb索引节点存的则是数据的主键,所以需要根据主键二次查找);myisam锁是表锁,只有读读之间是并发的,写写之间和读写之间(读和插入之间是可以并发的,去设置concurrent_insert参数,定期执行表优化操作,更新操作就没有办法了)是串行的,所以写起来慢,并且默认的写优先级比读优先级高,高到写操作来了后,可以马上插入到读操作前面去,如果批量写,会导致读请求饿死,所以要设置读写优先级或设置多少写操作后执行读操作的策略;myisam不要使用查询时间太长的sql,如果策略使用不当,也会导致写饿死,所以尽量去拆分查询效率低的sql,innodb一般都是行锁,这个一般指的是sql用到索引的时候,行锁是加在索引上的,不是加在数据记录上的,如果sql没有用到索引,仍然会锁定表,mysql的读写之间是可以并发的,普通的select是不需要锁的,当查询的记录遇到锁时,用的是一致性的非锁定快照读,也就是根据数据库隔离级别策略,会去读被锁定行的快照,其它更新或加锁读语句用的是当前读,读取原始行;因为普通读与写不冲突,所以innodb不会出现读写饿死的情况,又因为在使用索引的时候用的是行锁,锁的粒度小,竞争相同锁的情况就少,就增加了并发处理,所以并发读写的效率还是很优秀的,问题在于索引查询后的根据主键的二次查找导致效率低;ps:很奇怪,为什innodb的索引叶子节点存的是主键而不是像mysism一样存数据的物理地址指针吗?如果存的是物理地址指针不就不需要二次查找了吗,这也是我开始的疑惑,根据mysism和innodb数据存储方式的差异去想,你就会明白了,我就不费口舌了!所以innodb为了避免二次查找可以使用索引覆盖技术,无法使用索引覆盖的,再延伸一下就是基于索引覆盖实现延迟关联;不知道什么是索引覆盖的,建议你无论如何都要弄清楚它是怎么回事!尽你所能去优化你的sql吧!说它成本低,却又是一项费时费力的活,需要在技术与业务都熟悉的情况下,用心去优化才能做到最优,优化后的效果也是立竿见影的!
10.行级锁与表级锁
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发性能。在不通过索引条件查询的时候,InnoDB 确实使用的是表锁,而不是行锁。由于 MySQL 的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行 的记录,但是如果是使用相同的索引键,是会出现锁冲突的。应用设计的时候要注意这一点。当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论 是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同 执行计划的代价来决定的,如果 MySQL 认为全表扫 效率更高,比如对一些很小的表,它 就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。因此,在分析锁冲突时, 别忘了检查 SQL 的执行计划,以确认是否真正使用了索引。有多种方法可以避免死锁,这里只介绍常见的三种1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
11.面向对象6大原则
单一原则
开闭原则
依赖倒置
里氏替代
接口隔离原则
迪米特法则
12. AQS原理
AQS是AbstractQueuedSynchronizer的缩写,称为同步器,是用来构建锁或者其他同步组件的基础框架,它使用一个int成员变量表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。该同步器提供的模板方法,
Java基础知识
equals(Object obj)方法和hashcode()
equals(Object obj)方法是Object类的一个方法,作用是判断两个对象是否相同。如果类没有重写equals()方法,则当只有两个对象的地址完全相同时,即两个对象是同一个对象,此时与 == 操作符相等。如果类重写了equals()方法,则判断覆盖equals()方法中两个对象内容是否相同。equals()方法重写需要满足下面的特性:自反性一致性传递性非空性对称性hashCode()方法: 也是Object类中的一个方法,作用是获得对象的哈希码,主要使用在HashCode,HashMap这类的容器中,确定存储地址。equals方法与hashCode方法关系:只有在需要使用散列值时才有必要同时重写两个方法。如果没有重写会造成重复插入。例如有一个Person类,其中有name和age两个方法,重写了equals方法,表示当name和age值相同时表示同一个人。有两个name和age值相同的对象,他们产生的hashcode值不相同,因此会导致重复插入。
