@Vany
2016-03-26T07:48:59.000000Z
字数 3187
阅读 2289
CentOS7上Hadoop集群搭建与使用小记(一)——预备工作
Hadoop CentOS
最近折腾了一圈Hadoop的平台,利用Ambari(简直好用)在实体机上搭建了整个Hadoop集群(在虚拟机上也一样),踩过很多坑,总结了很多经验,在这里一步步记录下来,作为一个总结,也可以给别人作为一个参考。
整个系列将会包括从最开始的裸机的部署,到后面的Ambari, Hadoop软件的安装,以及Hadoop生态圈软件的原理与使用。本教程所采用的操作系统是基于CentOS7,在实体机上搭建的。不过在虚拟机上搭建也不是问题,注意设置好网络就好。操作系统如果不一样的话,可能系统配置以及安装对应的软件包的命令会有所差别。
机器准备
架构介绍
在需要部署的集群的机器以外,我们还需要一台机器,作为配置过程的Server,在预备工作中,所有的操作都是在这台机器上操作。如果是实体机集群的话,可以单独拿出一台来做Server,如果是单机Hadoop平台的话,可以直接建一个Server的虚拟机即可。架构图如下:
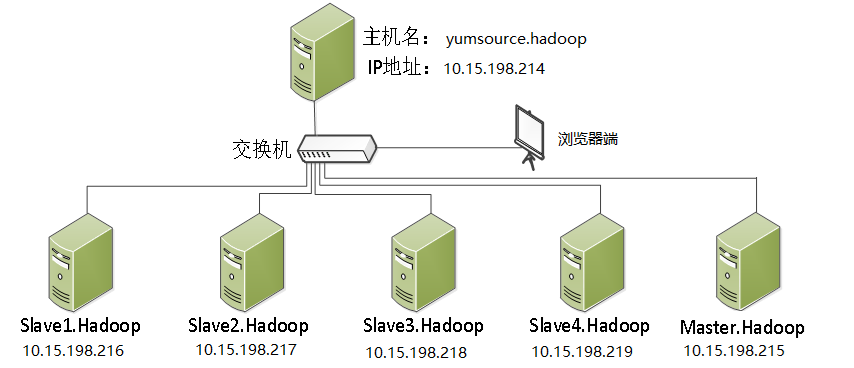
最上面的主机我们后文都称作Server,下面的都称作Client。
机器安装
安装部分其实比较简单,但是有几个坑需要注意一下:
- 安装CentOS7选语言的时候,最好选择英文版,否则后面Ambari注册机器时死活注册不上(不要问我是怎么发现这个原因的,说多了都是泪,猜测要不是时区问题要不就是语言问题,反正选这个就好使了)
【图】
- 需要选择安装模式时,选GNOME Desktop模式就好,对大多数人都方便使用。如果选最小版的话,ifconfig命令等工具包还得自己安装,略麻烦。注意:在右面的附件组件中,最好把Development Tools等附加插件都装上,因为后面安装scipy等等python的packages时需要编译器,否则还要自己安装gcc,g++等C/C++编译器。
【图】
网络部署
安装好后,集群的机器要设置好IP, GATEWAY (网关), DNS,以确保各个机器之间可以互联,集群与Server之间也可以相连,而且最好是可以上网,因为之后需要使用yum命令安装、更新一些软件。
设置网络的地方:/etc/sysconfig/network-scripts/ifcfg-xxx,其中xxx是你的网卡名称,一般可能是enoXXXX或,emXXXXX或,eth0等等,具体我就不细说了。当然也可以在安装的过程中设置,另外注意确保配置文件中(即ifcfg-xxx)的ONBOOT的选项是yes,即网卡自动启动,这样远程重启我们也不怕啦。
【图】
Server的配置
这里的Server指的是上文的架构图中的yumsource.hadoop。
虽然机器名字叫yumsource.hadoop,但是其实我并没有配置CentOS的source(在我的环境下,可以直接采用yum install xxx来安装那些需要的小软件),而是配置了Ambari、HDP(相当于Hadoop)的source。因为如果下载Ambari的话在墙内简直是龟速,有时还会莫名其妙的断线,配置好后 ,看着50MB/s的传输速度,简直爽。
下载离线安装包
首先我们下载Ambari, HDP, JDK等我们需要的软件包:
先到hortonworks上找到最新的文档,比如最新的Ambari的是2.2.1.1,选择Amabri 2.2->Install & Upgrade->Automated Install with Ambari->Using a Local Repository项,里面有个Obtain the Repositories,就可以看到Ambari和HDP Stack的Repository的地址了,两个页面如下:
- Ambari: http://docs.hortonworks.com/HDPDocuments/Ambari-2.2.1.1/bk_Installing_HDP_AMB/content/_ambari_repositories.html
- HDP: http://docs.hortonworks.com/HDPDocuments/Ambari-2.2.1.1/bk_Installing_HDP_AMB/content/_hdp_23_repositories.html
找到对应系统的Tarball版本的地址,将其下载下来。CentOS7对应的Ambari和HDP2.3的版本的Tarball地址如下:
- Ambari: http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.1.1/ambari-2.2.1.1-centos7.tar.gz
- HDP Stack: http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.3.4.7/HDP-2.3.4.7-centos7-rpm.tar.gz
- HDP-UTILS: http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7/HDP-UTILS-1.1.0.20-centos7.tar.gz
配置本地Repo
建立/var/www/html/hdp/文件夹,将我们下载的安装包传到Server上。看看能不能通过http直接访问该机的目录,假设该机的域名是yumsource.hadoop,那么可以在浏览器里输入
http://yumsource.hadoop/hdp/
看看能不能访问到。如果不能的话,可以安装(更新)下httpd试试。如果能访问到,那么就配置成功了。
接下来配置一下repo的文件,也就是说别人想用yum install ambari-server安装时,他要知道从哪里去下。建立ambari.repo,内容如下(这些内容根据你的具体地址和版本号改变而改变):
[Ambari-2.2.0.0]name=Ambari-2.2.0.0baseurl=http://yumsource.hadoop/hdp/ambari-2.2.0.0/centos7/2.2.0.0-1310/gpgcheck=0enabled=1[HDP-2.3.4.0]name=HDP-2.3.4.0baseurl=http://yumsource.hadoop/hdp/HDP/centos7/2.x/updates/2.3.4.0/gpgcheck=0enabled=1[HDP-UTILS-1.1.0.20]name=HDP-UTILS-1.1.0.20baseurl=http://yumsource.hadoop/hdp/HDP-UTILS-1.1.0.20/repos/centos7/gpgcheck=0enabled=1
这个文件要传送到master节点(是指集群的master)的/etc/yum.repos.d/目录下,这里我们先不传送,后面用脚本统一配置。
建立hosts列表
将我们集群的所有机器(不包括这个Server)配置成一个hosts列表,供后面的脚本使用,例如:
10.15.198.204 master.hadoopcluster10.15.198.205 slave1.hadoopcluster10.15.198.206 slave2.hadoopcluster10.15.198.207 slave3.hadoopcluster10.15.198.208 slave4.hadoopcluster
总结
到这里,我们的预备工作基本做完了,目前搭建好了互联的机器集群,和具有Ambari、HDP安装包的Server,以及一个hosts列表。
接下来,我会介绍部署所用的脚本,以及部署的过程。
