@SmashStack
2017-05-17T05:46:17.000000Z
字数 2098
阅读 3853
VUDDY: A Scalable Approach for Vulnerable Code Clone Discovery
Binary
该论文在 SP 17 上发表,文章通过基于源码的匹配方式,实现了对漏洞代码的自动化发掘。
作者
- Seulbae Kim @ Korea University
- Seunghoon Woo @ Korea University
- Heejo Lee @ Korea University
- Hakjoo Oh @ Korea University
Motivation
作者提到,在现在开源软件的大趋势下,通过使用其他开源程序的源代码实现代码重用的情况越来越普遍。但是正是因为这样,安全漏洞的扩散也变得非常容易。事实上,Code Cloning (通过使用其他开源代码的源代码完成编程的方式)已经成为了造成软件漏洞的主要原因之一。另一方面,因为 Code Cloning,漏洞的修补周期将变得更长,导致更多可能的安全问题。
因此,一个专注于漏洞代码发现的 Code Cloning Detection 被作者提出,并命名为 VUDDY (VUlnerable coDe clone DiscoverY)。同时,作者指出,现有工具和技术对于大样本的处理显得有些无力,作者希望能够通过自己提出的这个方法去改善现有的状况。
Code Clone
作者对 Code Clone 进行了四个层次的区分,有:
- Type 1: Exact clones. 直接对源代码执行复用,没有做过任何修改
- Type 2: Renamed clones. 对变量名、类型定义进行了重命名,没有做过语法上的修改。
- Type 3: Restructured clones. 对源代码进行了结构上的修改,但是语义没有变化。
- Type 4: Semantic clones. 语义也进行了变化,但是程序功能没有变化。
VUDDY 对 Type 1 和 Type 2 的 code cloning 提供支持。
VUDDY
VUDDY 的运行逻辑如下图:
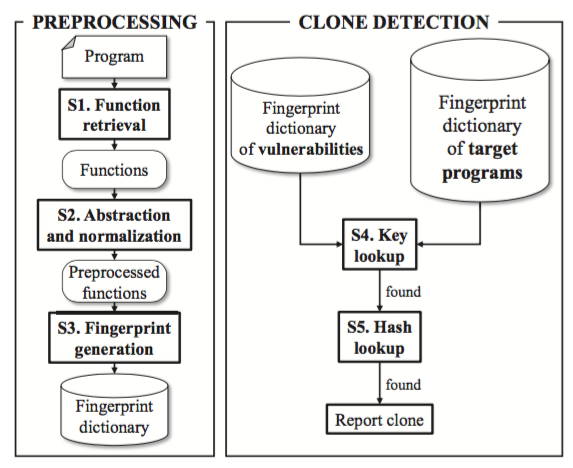
VUDDY 以函数为单位对代码进行处理,其主体分为两个部分:
- PREPROCESSING: 对包涵漏洞的源代码进行预处理,并生成数据库
- CLONE DETECTION: 对目标程序中的函数进行判断,从中发现包涵漏洞的 Code Cloning
在 PREPROCESSING 中,主要分为以下三个步骤:
- S1. Function retrieval
- S2. Abstraction and normalization
- S3. Fingerprint generation
在 CLONE DETECTION 中,主要分为以下两个步骤:
- S4. Key lookup
- S5. Hash lookup
S1. Function retrieval
VUDDY 对输入程序的源程序进行处理,将每一个函数提取出来,同时提取出函数中的参数、本地变量、数据类型、函数调用的信息留到 S2 中处理
S2. Abstraction and normalization
抽象的步骤分为五个层次:
Level 0: No abstraction.
不对函数进行任何的修改。Level 1: Formal parameter abstraction.
将函数传入的参数通过固定字符串 FPARAM 替换。Level 2: Local variable abstraction.
将函数的所有本地变量通过固定字符串 LVAR 替换。Level 3: Data type abstraction.
将函数的变量类型(包括用户自定义类型)通过固定字符串 DTYPE 替换,但是保留 unsigned 等字串。Level 4: Function call abstraction.
将函数内部的函数调用通过固定字符串 FUNCCALL 替换。
下图是抽象过程的举例:

归一化的过程则是:去掉所有的注释和空白字符。
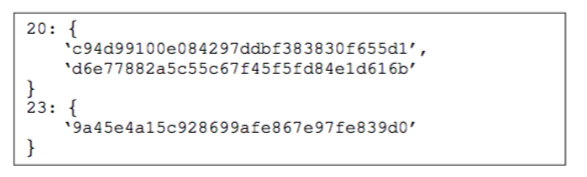
S3. Fingerprint generation
将归一化以后的函数通过 {长度:HASH} 的方式生成。
具体如下图:

并且以键值对的方式存储在数据库中。上图所示的三个函数就可以通过如下的方式存储:
S4. Key lookup
对于目标函数,首先经过抽象和归一化,然后通过归一化以后的函数长度对 key 进行线性查找。
S5. Hash lookup
如果找到了对应的 key,则进入匹配 HASH。
另外需要说明的是,S4 和 S5 的效率都很高,因为实验表明,对于 Linux kernel 4.7.6 生成的数据库,只有 5245 个 key。而对于每一个 key, 最多只有 1019 个 hash 值。
Evaluation
测试环境: Ubuntu 16.04, with a 2.40 GHz Intel Zeon processor, 32 GB RAM, and 6 TB HDD
测试数据集:
- 25,253 个满足如下两个条件的 Github 上的仓库:
- 至少有一个 star
- 在 2016/1/1 到 2016/7/28 之间至少有一次 push
- 一些安卓手机的固件
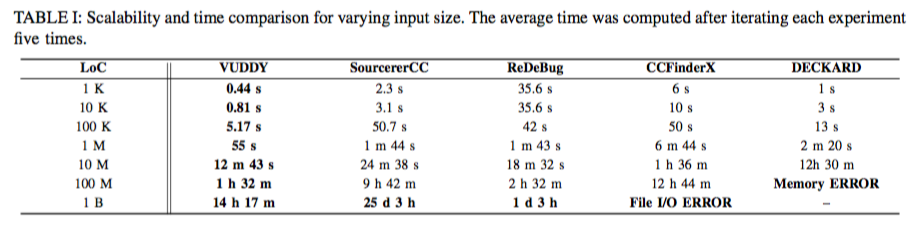
Scalability evaluation
下图是不同的技术处理数据所花费的时间:
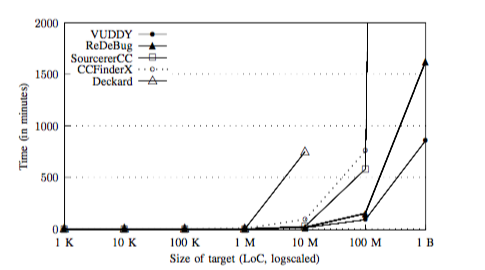
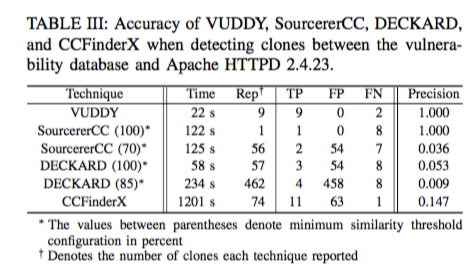
另外,下图为每种技术的运行参数:

Accuracy evaluation
vulnerability database: 从 git 上获取的具有 CVE 的函数
Target function: Functions in Apache HTTPD
通过人工检查的方式确定正确性,结果如图: