@SmashStack
2017-04-18T08:01:33.000000Z
字数 6218
阅读 2690
BinSequence: Fast, Accurate and Scalable Binary Code Reuse Detection
Binary
该论文在 AsiaCCS 2017 中发表,文章通过模糊匹配的方式实现了针对 Binary Code 的函数相似程度的对比,并用以检测代码重用。
作者
- He Huang @ Concordia University
- Amr M. Youssef @ Concordia University
- Mourad Debbabi @ Concordia University
Motivation
作者提出,代码重用的检测在逆向工程中有着举足轻重的作用,好的代码重用的检测工具能大大加快逆向工程的进度,考虑到现有工具的不足,作者以模糊匹配为核心开发了一套新的工具,并命名为 BinSequence 。最后,通过在五个应用场景中将 BinSequence 与包括 BinDiff 在内的现有工具进行对比实验,证明了 BinSequenec 的优越性,其中各个场景包括:
- Function Reuse Detection
- Patch Analysis
- Malware Analysis
- Bug Search
- Function Matching
BinSequence
假设前提:待分析的程序能够通过 IDA 进行反汇编并对每个函数生成控制流图 control flow graph (CFG)
输入:一个待对比的未知目标函数,一系列已经分析并注释过的已知函数
输出:未知函数与各个已知函数的相似程度 (Similarity Score)
处理流程:
1. Filtering:为了提高 BinSequence 的执行效率,首先过滤掉已知函数中不可能与目标函数相似的函数
2. Matching:通过多层次的模糊匹配得出各个已知函数的 Similarity Score
3. Ranking:将结果排序并输出
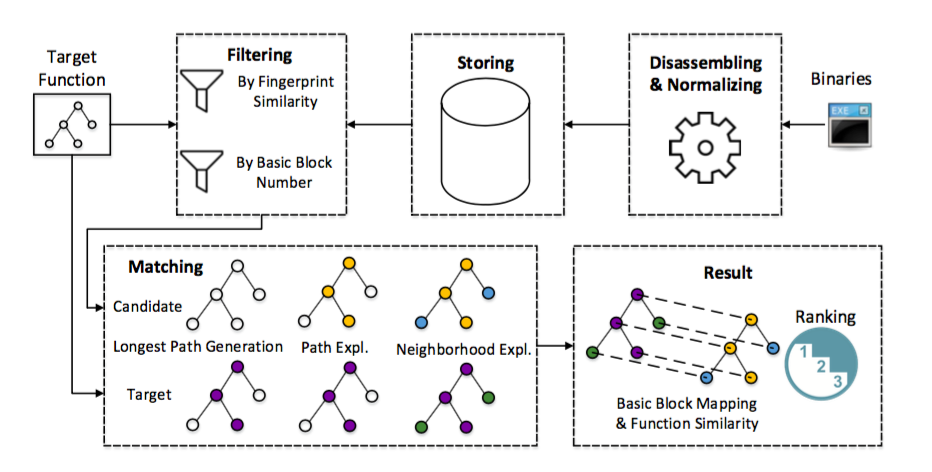
Matching
处理流程:
- Longest Path Generation:以指令集基本块为单位,通过深度优先搜索 (DFS) 获得目标函数中最长的执行路径
- Path Exploration:将目标函数中的最长执行流程与各个已知函数进行比对,获得在已知函数中相似程度最高的执行路径。这个步骤是结构层的模糊匹配, 通过宽度优先搜索(BFS)以及动态规划实现(DP)
- Neighborhood Exploration:通过已匹配的最长执行路径向周围扩展,进而得到整个函数的匹配程度
匹配算法
在 Path Exploration 中我们提到了 结构层的模糊匹配,事实上文章中提出了三种不同程度的匹配算法,包括:
- 汇编指令层的模糊匹配算法
- 基本块层的模糊匹配算法
- 结构层的模糊匹配算法
每一层的匹配算法都依赖于上一层,逐层相扣。
汇编指令层的模糊匹配算法
首先将基本块反汇编,随后对每条汇编指令如下归一化操作:
- 保留指令类型
- 将所有涉及寄存器的操作数统一归一为 REG
- 将作为 Memory Offset 的立即数归一
- 保留作为常量的立即数
依次对比两个指令,并根据对比情况获得 Similarity Score:
Input: Two normalized instructionsOutput: The matching score of two instructionsFunction CompIns(ins1,ins2)score = 0if ins1.Mnemonic == ins2.Mnemonic thenn = num of operands(ins1)score += IDENTICAL_MNEMONIC_SCOREfor i = 0; i < n; ++i doif operand(ins1)[i] == operand(ins2)[i] thenif type(operand(ins1)[i]) == CONSTANTS thenscore += IDENTICAL_CONSTANT_SCOREelsescore += IDENTICAL_OPERAND_SCOREendendendelsescore = 0endreturn scoreend
基本块层的模糊匹配算法
基本块层面的模糊匹配算法基于指令层面的模糊匹配算法。基本块可以看作是指令的序列,对比两个基本块的相似性可以看作是求两个序列的最大匹配程度,这样的问题完全可以转化为经典动态规划问题:最长公共子序列 (LCS)。算法原理方面不在这里深入讨论,该算法时间复杂度和空间复杂度都为:
其中 n 表示序列中元素的个数。
状态转移方程为:
Input: Two basic blocks BB1, BB2Output: The similarity score of two basic blocksAlgorithm CompBBs(BB1, BB2)M = InitTable(|BB1| + 1, |BB2| + 1)for i = 1; i <= |BB1|; ++i dofor j = 1; j <= |BB2|; ++j doM[i,j] = Max(CompIns(BB1[i], BB2[j]) \+ M[i-1,j-1], M[i-1,j], M[i,j-1])endendreturn M[|BB1|,|BB2|]end
结构层的模糊匹配算法(Path Exploration)
结构层的模糊匹配算法是将一个已知执行路径与一整个函数的 CFG,类似于之前提到的思路,作者将基本块视为元素,那么 已知的执行序列 可以看作是元素的序列,而 整个函数的 CFG 则可以看作元素的图,问题转化为一个路径与一整张图的最佳匹配,其实本质上同样是最长公共子序列问题。考虑到图与序列的不同,需要对 LCS 进行算法修正,具体修正方法是引入 BFS 对图进行遍历,遍历出的每一条路径和目标路径进行 LCS 的动归匹配。
Input: P : the longest path from the target function,G : the CFG of the reference functionOutput: A : The memoization table/* B : the array that stores the largest LCSscore for every node in G */Function PathExploration(P,G)A = InitTable(1, |P | + 1)B = InitArray(|G|)Q = InitQueue()Q.pushback(G1) //always start from the head nodewhile Q is not empty docurrNode = Q.front()Q.pop_front()A.AddNewRow() //always add a new row toLCS(currNode,P)//compare currNode with every node in P and update the tableif B(currNode) < A(currNode,|P|) thenB(currNode) = A(currNode,|P|)for each successor s of currNode doQ.pushback(s)endendendreturn BendFunction LCS(u,P)for each node v of P doif SameDegree(u,v) thensim = CompBB(u, v)elsesim = 0endA(u,v) = Max(A(parent(u), parent(v)) + sim,\A(parent(u), v), A(u, parent(v)))endend
注意到这里有一个强剪枝,在对比两个基本块的时候,只有入度或者出度中一个相同的基本块才会有匹配值,这样的做法好处在于可以更快的理清楚 CFG 的框架。如果因为其他原因导致理应对应的基本块入度/出度发生偏差,在后一步 Neighborhood Exploration 将得到修正。
另外,算法中对路径匹配中直接将 Similarity Score 相加的做法最后的实验效果不佳,最终作者们经过归一化处理进行了修正。
其中,Score(P) 返回 P 与自身匹配的 Similarity Score。
Neighborhood Exploration
在 Path Exploration 中,我们获得了与最长执行路径最有匹配的一条路径,现在我们要做的是去扩充这对路径的临近节点。
我们获得了最优匹配路径,换句话说,我们获得了很多对基本块对,这些基本块对有一个关键的特点是:每对基本块对的两个基本块有着相等的入度或者出度。依照 Similarity Score 将这些基本块对排序,从大到小处理。考虑有相同的出度(入度同理可得),我们希望能够得到这些出度节点间的对应关系,获得这些出度节点最大的 Similarity Score 是对应匹配的目标。问题可以转化为标准的 二分图最大匹配问题,可以通过 匈牙利算法 较为高效的实现,其时间复杂度为:
最后,将这些所有的配对基本块求一个总的 Similarity Score,作为函数 f 和 g 的 Similarity Score
同样,Score(f) 是 f 函数与自身匹配的 Similarity Score。
Filtering
考虑到我们可能将一个函数同海量的函数库进行比对,如果不进行预处理,我们的处理效率将大大降低。于是乎作者设计了两层 filter 进行过滤。
根据基本块的数量进行筛选
作者认为,两个相似的函数基本块的数量应该相差不大,于是作者首先定义了一个阀值 x , 当两个函数的基本块数量差在 x 之外的将被排除。
根据指令集特征进行筛选
首先用前文的方法 Normalize 每个函数的汇编指令得到一个集合,然后通过 杰卡德距离 计算出一个相似程度,同样设置一个阀值 y, 当相似度低于 y 的函数将被排出。
另外文中提到了对 pairwise comparison 的处理,可以深入原文阅读。
EVALUATION
测试信息:
CPU: Intel Xeon E31220 Quad-Core
RAM: 16 GB
OS : Microsoft Windows 7 64-bit
Function Reuse Detection
测试对象:zlib 1.2.5 - 1.2.8 (带符号)
引入噪声:1701 个 windows 系统动态链接库函数
测试方法:
将低版本的 zlib 与 后一临近高版本 zlib 对比(如 1.2.5 vs 1.2.6),如果由 BinSequence 输出最高 Similarity Score 的函数对有相同的函数名,则认为配对成功
测试结果:
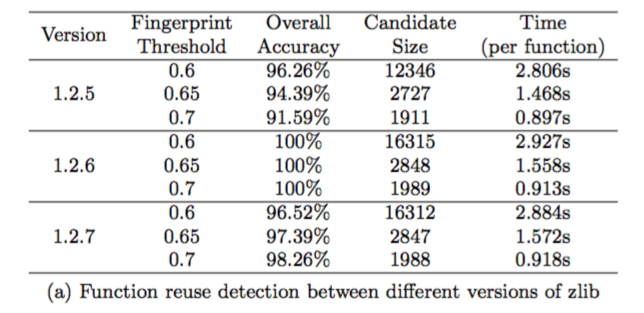
上图中,Fingerprint Threshold 是阀值的选择,Candidate Size 是对每一个目标函数,经过 Filter 以后留下的函数数量的和。
另外,作者还对 libpng 1.6.17 和 zlib 1.2.8 进行了测试(libpng 使用了 zlib 库),得到了如下结果:
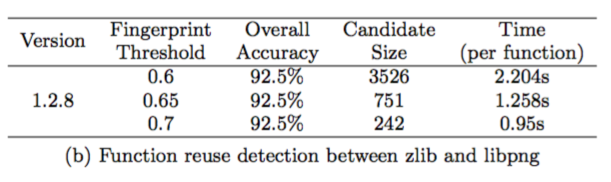
可以看到,Binsequence 精准度和效率都还是很高的
Patch Analysis
通过对 patched 和 unpatched 的 Binary 进行比对,Similarity Score 低于 1 的函数对可以理解为意思 patched 的函数,大大缩小了逆向工程的范围。
测试对象:HTTP.sys with vulneravility MS15-034
测试方法:
将 patched 和 unpatched 的 HTTP.sys 每个函数逐一对比,提取出 Similarity Score 不为 1 的函数
测试结果:
最后发现了 11 个可以的函数,其中 6 个是相同函数,因为 IDA Pro 反汇编出来的指令不同。剩下 5 个中,id 45 的基本块就是 patch 部分。下图 Table 2 就是列举出的剩下的五个不同的函数:

Malware Analysis
测试对象:Citadel and Zeus (Citadel 是从 Zeus 衍生出的恶意软件)
测试方法:
将 Zeus 中的 RC4 函数与一整个 Citadel 进行对比,确定 Citadel 中重用 RC4 的函数部分
测试结果:
BinSequence 给出了相似性前三高的函数,人工确认了 sub_42E92D 确实是改写过的 RC4 函数。
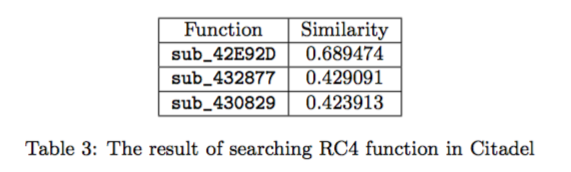
另外,用同样的方法对 BinDiff, Diaphora, PatchDiff2 做了测试
- BinDiff:错误配对为:Decrypt_String_by_Index (Wrong)
- Diaphora:报告 sub_40A8B0 相似度为 0.22 (Wrong)
- PatchDiff2:测试失败,没有结果
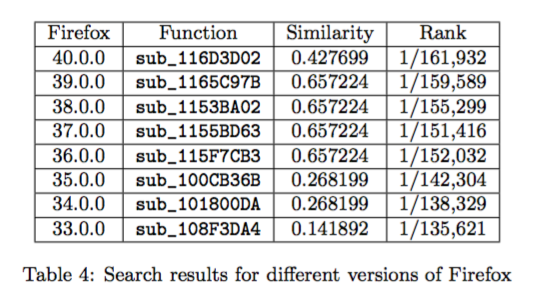
Bug Search
通过一个已知存在漏洞的函数,去检查其他 Binary 是否同样拥有这类有问题的函数。
测试对象:
Bug Function: resize_context_buffers() in FireFox 40.0.0
测试函数集: FireFox 33.0.0 ~ 39.0.0 的所有函数
测试方法:
通过 BinSequence 去定位 resize_context_buffers() 在 FireFox 其他版本中的对应可以函数函数
测试结果:
对于版本 36.0.0,37.0.0,38.0.0,39.0.0,BinSequence 确定定位了带有 bug 的函数
对于版本 33.0.0,34.0.0,35.0.0,BinSequence 给出了 Similarity Score 很低的对应函数,手动查看以后发现这些版本的 FireFox 使用了不同的 libvpx
用同样的方法对 BinDiff, Diaphora, PatchDiff2 做了测试
- BinDiff:
成功定位函数,但是作者们发现 BinDiff 是通过字符串匹配定位的函数,如果手动修改一点这些字符串,BinDiff 就给出了错误的数据。 - Diaphora:失败
- PatchDiff2:失败
Function Matching
测试对象:zlib 1.2.8 分别由 MSVC 2010 和 MSVC 2013
测试方法:
将 MSVC 2010 stripped 编译生成的函数作为目标,MSVC 2013 stripped 编译生成的函数作为函数集,分别使用 BinSequence, FCata-log, Diaphora, PatchDiff2 and BinDiff_ 对所有指令数多于 4 的函数进行配对
__测试结果:
所有工具都在很快的时间内完成了配对:
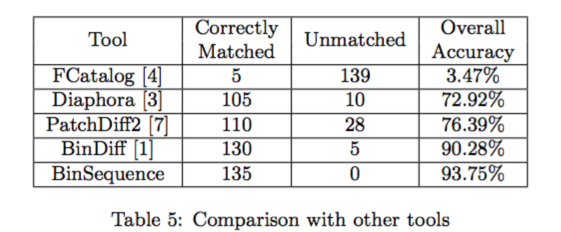
在这张表中,Unmatched 表示没有进行配对的函数数量。
LIMITATIONS
在文章中, 作者同样提出来 BinSequence 的局限性,主要如下:
- False positive: 当函数集中没有和目标函数匹配的函数时,BinSequence 同样会给出一个配对函数
- Function inlining:当目标函数是 inline 进入其他函数时,BinSequence 不能识别出者两个函数
- Equivalent instructions:对于一些等效的汇编指令,BinSequence 不能识别(比如
mov eax, 0和xor eax, eax) - Instruction reordering:编译器有时候可能会乱序指令顺序,导致指令层面模糊匹配的失败
- Basic block reordering:同样的,编译器也会打乱基本块的顺序,导致结构层面模糊匹配的失败
- Obfuscation:当匹配的程序加入混淆以后,会完全混乱基本块的顺序,直接导致 BinSequence 的失败
