@SR1s
2019-03-10T17:21:40.000000Z
字数 3170
阅读 2315
2019-03-10 知识图谱(一)
天命 知识图谱
零
Hello,汇报下本周的进展。
本周主要进行了“知识图谱”相关领域的初步探索。具体来说,就是阅读了两篇文章:《这是一份通俗易懂的知识图谱技术与应用指南》、《美团餐饮娱乐知识图谱——美团大脑揭秘》,大致对知识图谱有了非常初步的认知。
壹:知识图谱的定义
从学术的角度,我们可以对知识图谱给一个这样的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)1。
我的理解:
1. 知识图谱本质上是基于语义的,和机器翻译类似,因此注定依赖NLP相关领域的技术。
2. 语义网络表示语义之间存在联系,如一个个概念组成的网络。
3. 关系是知识图谱研究的核心概念之一,概念1->关系->概念2、主语->谓语->宾语。
4. 以上三者形成的三元组(概念1, 关系, 概念2)、(主语, 谓语, 宾语),是知识图谱中,对知识的表示形式。
5. 多关系图不同于数据结构中传统的图的概念,图中的“节点”和“关系”的类型是多样。
6. 个人理解,知识图谱是一种构建概念之间的联系的技术,并提供了探索这些关系的能力,在探索的过程中,实现业务目标
7. 于我个人而言,探索的过程是吸引我的点;但对于使用知识图谱构建业务的公司/团队,基于业务理解,构建合适的知识图谱,才是核心。
基于知识图谱的AI和基于数据的AI的对比2
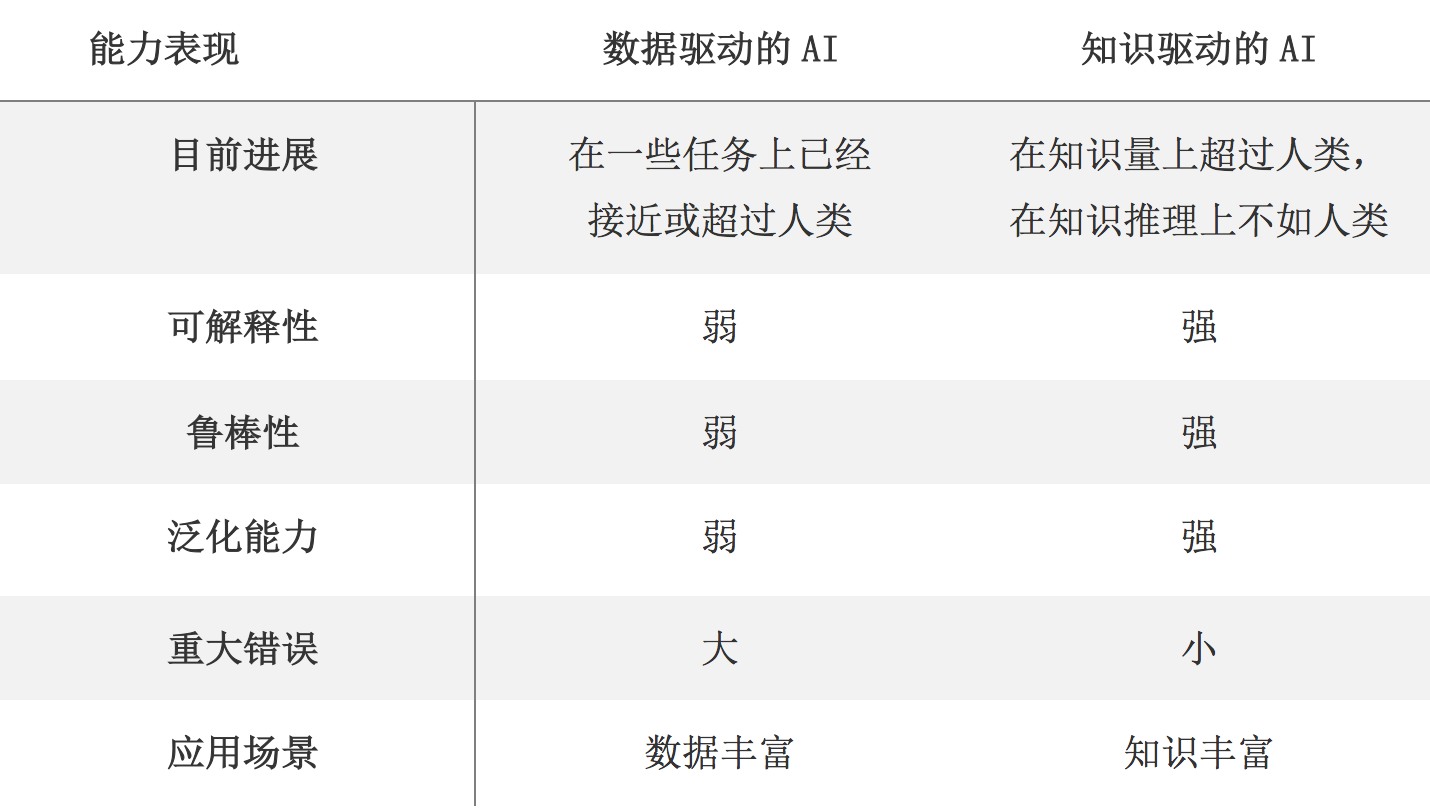
适用场景:知识丰富(低容错需求)
应用领域:美团大脑、金融风控
分析对象从<个体样本>转向<个体+个体之间的关系>
贰:知识图谱使用的数据
结构化数据指的关系型数据库表示和存储的的二维形式数据,这类数据可以直接通过Schema融合、实体对齐等技术将数据提取到知识图谱中。半结构化数据主要指有相关标记用来分隔语义元素,但又不存在数据库形式的强定义数据,如网页中的表格数据、维基百科中的Infobox等等。这类数据通过爬虫、网页解析等技术可以将其转换为结构化数据。现实中结构化、半结构化数据都比较有限,大量的知识往往存在于文本中,这也和人获取知识的方式一致。对应纯文本数据获取知识,主要包括实体识别、实体分类、关系抽取、实体链接等技术2。
简单来说,知识图谱的数据来源,分为两大类:结构化数据和非结构化数据。非结构化信息可进一步划分为半结构化数据和文档型数据。
结构化数据和半结构化数据导入和使用简单,是理想的知识图谱使用的数据,但现实中都比较有限。文档型数据占大多数,而知识则蕴含在其中。为了从文档型数据中获取知识,则需要使用一系列NLP相关的技术进行处理,即引文中提到的“实体识别”、“实体分类”、“关系抽取”、“实体链接技术”。在另一篇文章里1,则将他们称为“实体命名识别”、“关系抽取”、“实体统一”、“指代消解”。说的都是一回事。
另外,由于知识图片基于语义网络,而语义网络又是基于文本的,因此知识图片的数据里,没有多媒体相关的数据,如音频、视频、图片等数据。
知识图谱的数据有开源的数据可供使用:
世界知名的高质量的大规模开放知识库如Wikidata、DBPedia、Yago是构建通用领域多语言知识图谱的首选,国内有OpenKG提供了诸多中文知识库的Dump文件或API。工业界往往基于自有的海量结构化数据,进行图谱的设计与构建,并同时利用实体识别、关系抽取等方式处理非结构化数据,增加更多丰富的信息2。
也就是说,进行知识图谱的相关实践,实际上一开始可以不需要使用到NLP相关的知识,先从开源的数据入手,进行实践,等到需要用到特定领域的数据,再进行非结构化数据处理相关的实践,避免本末倒置(NLP领域博大精深)。
叁:知识图谱相关理论和技术
知识图谱相关理论
在数据还是稀有资源的早期,知识图谱的研究重点偏向语义模型和逻辑推理,知识建模多是自顶向下的设计模式,语义模型非常复杂。伴随着Web带来前所未有的数据之后,知识图谱技术的重心从严谨语义模型转向海量事实实例构建,图谱中知识被组织成<主,谓,宾>三元组的形式,来表征客观世界中的实体和实体之间的关系2。
知识图谱相关技术
知识图谱技术链2:
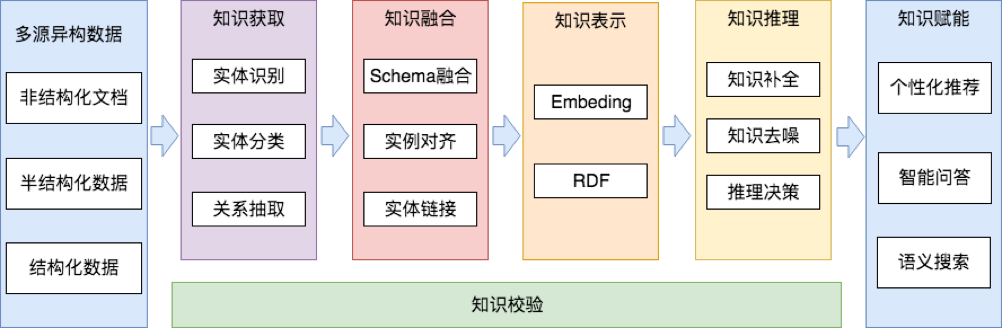
知识获取
知识融合
知识表示
知识理解
知识赋能
存储技术
知识图谱主要有两种存储方式:一种是基于RDF的存储;另一种是基于图数据库的存储。RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景1。
RDF和图数据库对比1:

存储框架选型
Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式。相反,OrientDB和JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃,这也就意味着使用过程当中不可避免地会遇到一些刺手的问题。如果选择使用RDF的存储系统,Jena或许一个比较不错的选择1。
肆:实施流程/构建步骤
一个完整的知识图谱的构建包含以下几个步骤:
1. 定义具体的业务问题
2. 数据的收集 & 预处理
3. 知识图谱的设计
4. 把数据存入知识图谱
5. 上层应用的开发,以及系统的评估1。
在第1点定义具体业务问题的同时,需要分析是否需要使用知识图谱来解决问题,避免为了用而用。
在第2点数据收集过程,需要分析当前可用的数据有哪些,从数据出发,探索可行的实施方式。
最后一点,应用知识图谱的过程,很考验一个人的数据思维,根据1,有:
- 基于规则的方法论
1.1. 不一致性验证
1.2. 基于规则提取特征
1.3. 基于模式的判断
1.3.1. 共享多实体
1.3.2. 强连通图 - 基于概率的方法
2.1. 社区挖掘
2.2. 标签传播
2.3. 聚类
2.4. ... - 基于动态网络的分析
3.1. 基于时间,对结构的变化进行分析
在文章1中有具体例子,很有意思。
伍:其他
知识图谱
- 知识图谱属于知识工程,归属数据科学。
- 应用的前提是完成知识图谱的构建,这和机器学习的应用是一致的。
- 实体/关系的选择是一门艺术,需要基于业务进行理解,这和机器学习里选取特征进行学习一样。
关于知识
知识就是有结构的信息。人从数据中提取有效信息,从信息中提炼有用知识,信息组织成了结构就有了知识。知识工程,作为代表人工智能发展的主要研究领域之一,就是机器仿照人处理信息积累知识运用知识的过程。
即:
数据 -提取-> 有效信息 -提炼结构-> 知识
知识图谱之“知识”的内涵
一开始,我将知识图谱的“知识”理解成了广义的知识,即人脑内的各种概念、推理规则;但《这是一份通俗易懂的知识图谱技术与应用指南》中提到:
需要说明的一点是,有可能不少人认为搭建一个知识图谱系统的重点在于算法和开发。但事实并不是想象中的那样,其实最重要的核心在于对业务的理解以及对知识图谱本身的设计1。
也就是说,在实践知识图谱的过程中,适当的对知识的边界进行约束,能够更高性价比地实现业务目标。虽然说对人类历史上所有的知识进行建模,构造知识图谱是一件很有吸引力的事情(对我而言是如此,Google则是一直在投入资源),但现阶段还是需要务实一点,从业务出发。
美团的知识图谱服务的业务
方法
让机器阅读用户评论数据,理解用户在菜品/价格/服务/环境等方面的喜好;使用深度学习技术,把数据背后的知识挖掘出来
目标
构建人、店、商品、场景之间的知识关联
应用场景
智能搜索推荐、智能金融、智能商户运营等
现状(2018年11月22日)
数十类概念,数十亿实体和数百亿三元组
未来
未来一年内将上涨到数千亿的规模
