@Matrixzhu
2021-10-06T09:01:32.000000Z
字数 3429
阅读 845
Experiment result
Representation
Key-points selection
Totally 19 key points are selected. Left and right eyes are not include, because they are not labeled in Stanfortdextra dataset. For every imge only visible key points are labeled.
| keypoint name | poportion in dataset |
|---|---|
| Left front leg: paw | 0.92 |
| Left front leg: middle | 0.93 |
| Left rear leg: paw | 0.86 |
| Left rear leg: middle joint | 0.69 |
| Left rear leg: top | 0.65 |
| Right front leg: paw | 0.55 |
| Right front leg: middle joint | 0.87 |
| Right front leg: top | 0.88 |
| Right rear leg: paw | 0.84 |
| Right rear leg: middle joint | 0.68 |
| Right rear leg: top | 0.66 |
| Tail start | 0.57 |
| Tail end | 0.58 |
| Base of left ear | 0.86 |
| Base of right ear | 0.85 |
| Nose | 0.99 |
| Left ear tip | 0.44 |
| Right ear tip | 0.45 |
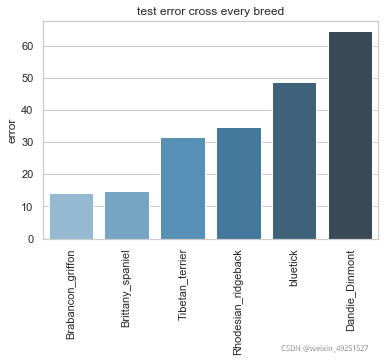
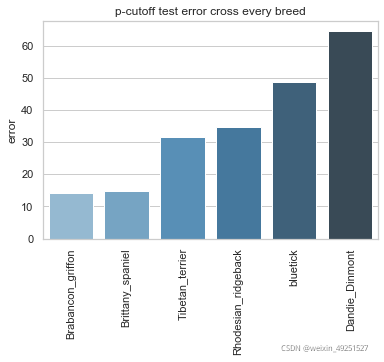
Selected dog breeds
There are 6 types of dog are selected randomly.
- Dandie_Dinmont
- Tibetan_terrier
- bluetick
- Rhodesian_ridgeback
- Brittany_spaniel
- Brabancon_griffon
Example image with ground true for each breed
Training dataset description
The image dataset I use called StanfordExtra. It contains 20580 dog images in 120 breed. There are 12538 images for labeld with ground true keypoints. For this experiment I select 6 breeds of dog ( mensioned before), 60 images for each breed. Since every dog is in different backgrounds and poses, and some images only contain small poportion of my selected keypoints. Thus, my image selection critierion is that only the image contains more than 60 percent visible keypoints out of my label set can be used as training data. There are 353 images are selected. The dataset fraction rare used is 0.9. There are 302 training image and 51 test image.
Model result
The model has been trained for 200,000 iterations which is recommend by the Deeplabcut official document. Mean square error is used as lose function, which is measure by the Euclideam distance between the ground true point's coordinate and prediction point's coordinate. The unite is number of pixel.
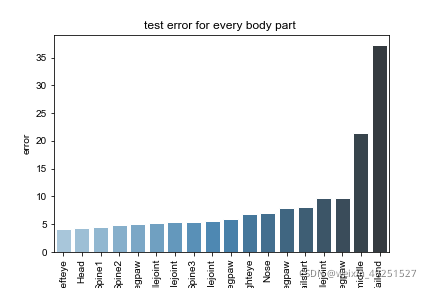
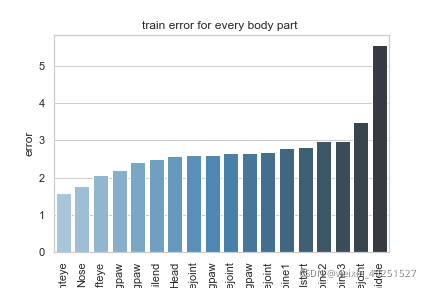
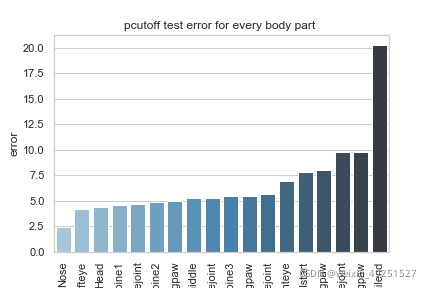
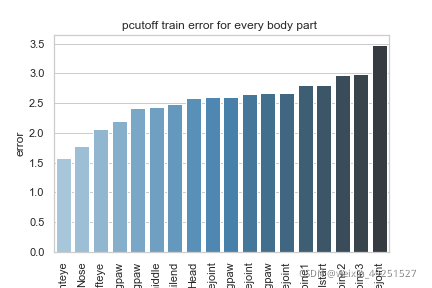
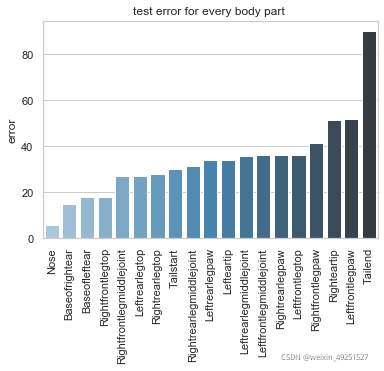
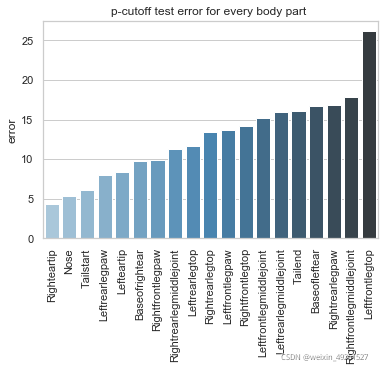
Conbined evaluation result
| Train error | Test error | Train error with p-cutoff | Test error with p-cutoff | p-cutoff used |
|---|---|---|---|---|
| 2.68 | 32.69 | 2.58 | 13.23 | 0.6 |
p-cutoff means only the points with prediction confidence with likelyhood > p-cut would be calculated error. This is helps to exclude occlude points.
Training set result
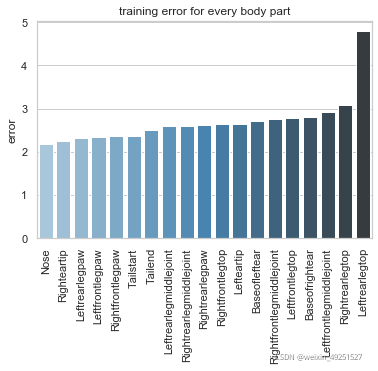
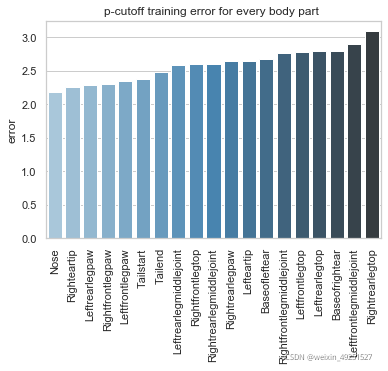
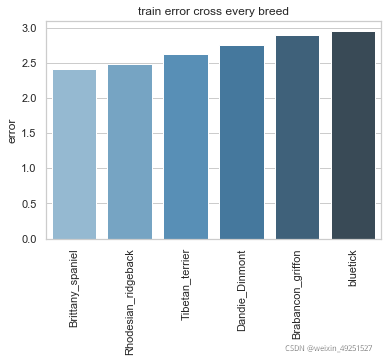
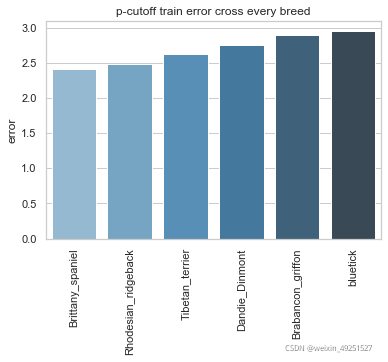
Test set result
Bad prediction images
| top 5 error train images | error | top 5 error test images | error |
|---|---|---|---|
| n02088632_1576.jpg | 23.10 | n02088632_2321.jpg | 156.81 |
| n02112706_1568.jpg | 8.76 | n02096437_2711.jpg | 152.19 |
| n02096437_3241.jpg | 8.12 | n02087394_3314.jpg | 62.80 |
| n02112706_539.jpg | 6.98 | n02088632_4208.jpg | 61.28 |
| n02112706_2074.jpg | 5.92 | n02087394_7025.jpg | 50.37 |
For the training image n02088632_1576.jpg is the most problematic one.
"." is ground true, "+" is right prediction, "x" is wrong prediction.

For test images n02088632_2321.jpg and n02096437_2711.jpg are the most problematic images.

Experiment on Tigdog dataset
Tigdog dataset is a video dataset which consist of the video shots from Youtube channel, however it lack landmark labeling. Thus, I manually labeled 289 image frames out of 9 videos. There are 6 breeds of dog appear in the video.
| keypoint name |
|---|
| Left front leg: paw |
| Left front leg: middle |
| Left rear leg: paw |
| Left rear leg: middle joint |
| Right front leg: paw |
| Right front leg: middle joint |
| Right rear leg: paw |
| Right rear leg: middle joint |
| Tail start |
| Tail middle |
| Tail end |
| left eye |
| Right eye |
| Nose |
| Head |
Conbined evaluation result
The model has been trained for 200,000 iterations which is recommend by the Deeplabcut official document. Mean square error is used as lose function, which is measured by the Euclideam distance between the ground true point's coordinate and prediction point's coordinate. The unite is number of pixels.
| dataset | Train error | Test error | Train error with p-cutoff | Test error with p-cutoff | p-cutoff used |
|---|---|---|---|---|---|
| stanfordog | 2.68 | 32.69 | 2.58 | 13.23 | 0.6 |
| tigdog | 2.73 | 8 | 2.57 | 6.3 | 0.6 |
p-cutoff means only the points with prediction confidence with likelyhood > p-cut would be calculated error. This is helps to exclude occlude points.
Example test result



"+" is ground true, "O" is the prediction with high likelihood, "x" is the prediction with low likelihood.