@BrandonLin
2016-07-30T12:59:53.000000Z
字数 5071
阅读 5350
Hive函数
Hive Hadoop
Hive提供了大多数操作符,例如用于测试相等性的x='a',用于判空的x IS NULL,用于字符串匹配的x LIKE 'a%',数学运算x+1,逻辑判断x OR y,||是或判断而不是连接字符串,字符串的连接通过concat函数来完成。
Hive内置了非常多的函数。大致可以分为:
- 数学和统计函数
- 字符串函数
- 日期函数
- 条件函数
- 聚合函数
- 操作XML和JSON的函数
在Hive shell,中,可以通过show functions来查看:
desc funtion可以获取简单的 函数帮助文档:
当Hive内置的函数无法满足需要时,可以自定义函数。Hive允许我们在查询中轻易地使用自定义的函数。
UDF必须使用Java语言,如果想要其他语言来实现,可以考虑SELECT TRANSFORM查询,它允许Hive与自定义的脚本通过Steam进行交互,类似MapReduce Streaming和Pig Stream。
Hive中有3中类型的自定义函数:通常的UDF、UDAF(user-defined aggregate function)、UDTF(user-difined table-generating function)。这三种函数的区别在于其输入和输出的行数:
- UDF:一行输入,一行输出
- UDGF:多行输入,一行输出
- UDTF:单行输入,多行输出(table)
UDTF
考虑一个只有一列的表,该列的值为字符串数组:
CREATE TABLE arrays(x ARRAY<STRING>)ROW FORMAT DELIMITEDFILEDS TERMINATED BY '\001'COLLECTION ITEMS TERNIMATED BY '\002'<div class="md-section-divider"></div>
表定义中指定了集合中元素的分隔符为CTRL + B。表中的数据样例如下:
hive> SELECT * FROM arrays;["a","b"]["c","b","e"]<div class="md-section-divider"></div>
接下来我们使用explode UDTF来转换这张表,这个函数将字符数组中的每个元素都转化为一行,有点Flat的意思:
hive> SELECT explode(x) AS y FROM arrays;abcde<div class="md-section-divider"></div>
使用UDTF的SELECT查询语句不能再有其他字段的表达式,这是很大的限制。可以使用LATERAL VIEW查询来解决这一问题。比如我们有以下pageAds表数据:
| pageid | adid_list |
|---|---|
| front_page | [1,2,3] |
| contact_page | [3,5,4] |
现在我们想统计每个广告在各个页面上的出现次数。使用lateral view:
SELECT pageid,adidFROM pageAds LATERAL VIEW explode(adid_list) adTable as adid;<div class="md-section-divider"></div>
结果如下:
| pageid(string) | adid(int) |
|---|---|
| front_page | 1 |
| front_page | 2 |
| front_page | 3 |
| contact_page | 3 |
| contact_page | 4 |
| contact_page | 5 |
为了统计每个广告出现的次数:
SELECT adid , count(1)FROM pageAds LATERAL VIEW explode(col1) adTables as adidGROUP by adid<div class="md-section-divider"></div>
| adid(int) | count(1) |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 4 | 1 |
| 5 | 1 |
定义UDF
为了理解UDF,我们写一个简单的trim功能的函数,这个函数在Hive的函数库中已经存在,叫做trim。为了区别,我们叫strip。实现代码如下:
import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;public class Strip extends UDF{private Text result = new Text();public Text evaluate(Text str){if ( str == null){return null;}result.set(StringUtils.strip(str.toString()));return result;}public Text evaluate(Text str,String stripChars){if ( str == null){return null;}result.set(StringUtils.strip(str.toString(),stripChars));return result;}}<div class="md-section-divider"></div>
UDF必须满足以下2个条件:
- 必须是UDF的子类
- 必须实现至少一个evaluate()方法
注意evaluate不是UDF定义的方法(没有@Override),因为这个方法接受的参数类型和个数以及返回值类型都是自己定义的。Hive使用反射机制来调用名为evaluate的方法。
这里没有使用Java的String类型,而是使用Text,主要是为了重用对象。编写完之后,我们将代码打包为hive-examples.jar,然后在Hive中使用CREATE FUNCTION创建函数:
CREATE FUNCTION strip AS 'me.lin.hive.Strip'USING JAR '/path/to/hive-exampls.jar';<div class="md-section-divider"></div>
如果是在集群中运行,则需要将JAR包上传到HDFS,然后使用hdfs的URI。创建函数之后,就可以使用:
hive> SELECT strip(' bee ') FROM dummy;bee<div class="md-section-divider"></div>
与Pig中函数名大小写敏感不同,Hive中的函数名大小写不作区分。上述创建的函数会持久化到metastore中,如果只想在当前会话中使用,可以创建临时函数:
ADD JAR /path/to/hive-exampls.jar;CREATE TEMPORARY FUNCTION strip AS 'me.lin.hive.Strip'<div class="md-section-divider"></div>
ADD JAR命令的一种替代方式是使用Hive的auxiliary path,在启动hive shell时通过--auxpath参数来告诉Hive相应的JAR包位置:
% hive --auxpath /path/to/hive-examples.jar<div class="md-section-divider"></div>
或者设置HIVE_AY_JARS_PATH环境变量,环境变量的值为逗号分隔的JAR文件列表或者包含JAR文件的目录。
定义UDAF函数
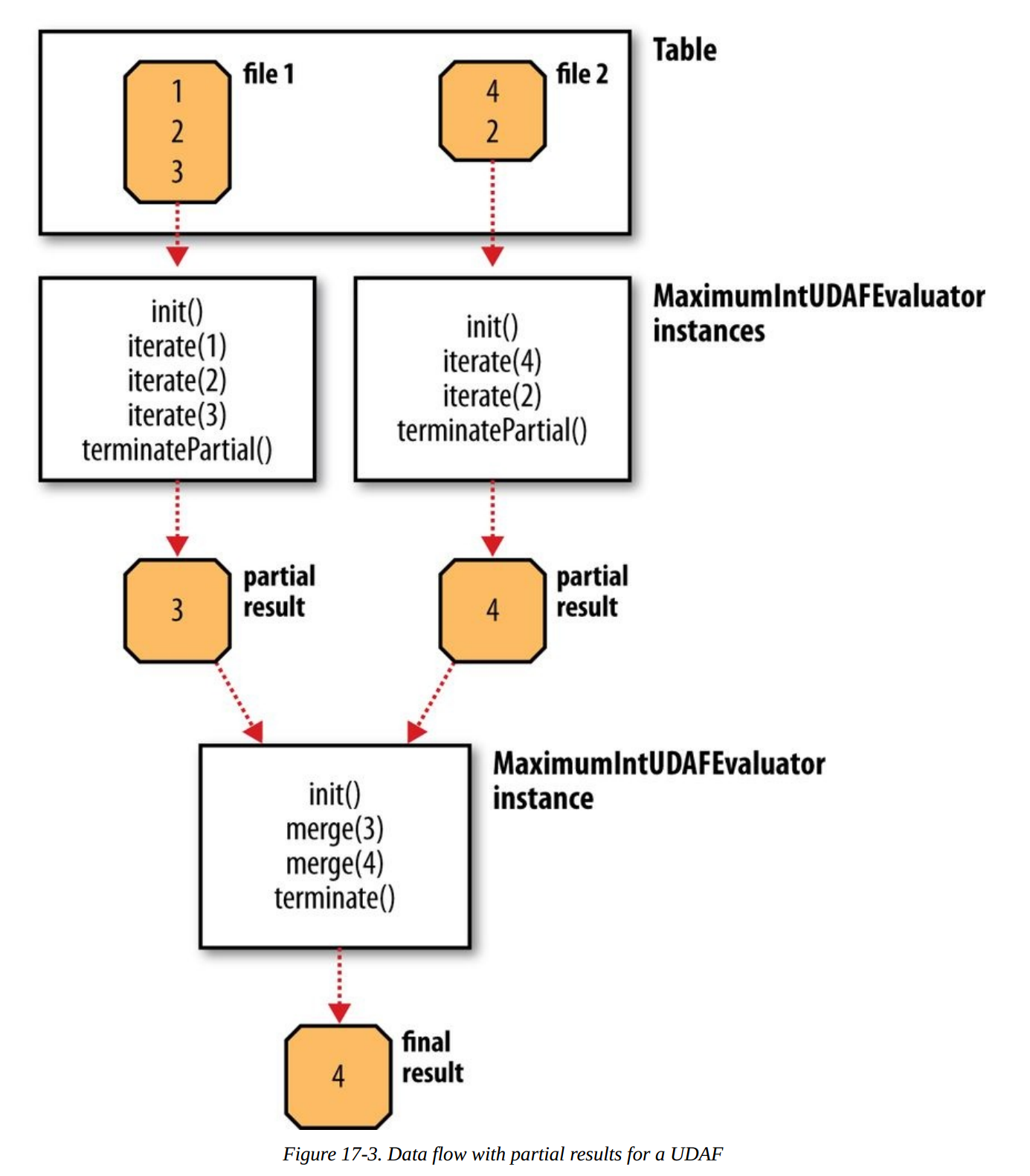
UDTF函数实现起来的UDF复杂一些,聚合操作是在多个任务中完成的,实现中必须定义部分结果的合并操作。用实例来说明更清楚一些,下面这个函数计算集合中的最大值:
import org.apache.hadoop.hive.ql.exec.UDAF;import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;import org.apache.hadoop.io.IntWritable;public class Maximum extends UDAF {public static class MaximumIntUDAFEvaluator implements UDAFEvaluator{private IntWritable result;public void init(){result = null;}public boolean iterate(IntWritable value){if (value == null){return true;}if ( result == null){result = new IntWritable(value.get());}else {result.set(Math.max(result.get(), value.get()));}return true;}public IntWritable terminatePartiaal(){return result;}public boolean merge(IntWritable other){return iterate(other);}public IntWritable terminate(){return result;}}}<div class="md-section-divider"></div>
UDAF的结构比UDF复杂一些,扩展了UDAF,并在内部实现了Evaluator的静态类,我们这里只实现了MaximunIntUDAFEvaluator,还可以实现Long,Float对应类型的版本,以便找出对应类型的最大值。
Evaluator必须实现5个方法:
- init(): 初始化,重置其内部状态等。
- iterate(): 一个新值加入聚合的逻辑
- terminatePartial(): 部分聚合结果
- merge(): 合并多个Partial结果
- terminate(): 获取最终的聚合值
上面的例子中,merge方法直接复用了iterate逻辑,类似于MapReduce中直接将Reducer实现作为Combiner是一样的。整个函数的执行逻辑如下:
如下使用该函数:
hive> CREATE TEMPORARY FUNCTION maximum AS 'me.lin.hive.Maximun';hive> SELECT maximun(temperature) FROM records;111<div class="md-section-divider"></div>
在有些情况下,最后的聚合操作跟部分聚合的操作是不一样的,例如计算平均值,不能直接复用iterate函数。下面是实现取平均值的代码:
import org.apache.hadoop.hive.ql.exec.UDAF;import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;import org.apache.hadoop.io.IntWritable;public class Mean extends UDAF {public static classMeanDoubleUDAFEvaluator implements UDAFEvaluator{public static class PartialResult{double sum;long count;}private PartialResult result;public void init(){result = null;}public boolean iterate(DoubleWritable value){if (value == null){return true;}if ( result == null){result = new PartialResult();}result.sum += value.get();result.count++;return true;}public PartialResult terminatePartiaal(){return result;}public boolean merge(DoubleWritable other){if ( other == null){return true;}if ( result == null){result = new PartialResult();}result.sum += other.sum;result.count += other.count;return true;}public DoubleWritable terminate(){if ( result == null){return null;}return new DoubleWritable( result.sum / result.count);}}}
