@BrandonLin
2016-07-27T13:50:56.000000Z
字数 6021
阅读 5520
理解Spark RDD
Spark
RDD最初是由伯克利大学的几个教授提出的,原始论文Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing可以在这里下载,非常值得认真研究。RDD(Resilient Distributed DataSet)是Spark最核心的抽象。它代表的是元素的集合,Spark的文档中这么描述RDD:
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel.
RDD论文中对RDD的描述:
Resilient Distributed Datasets (RDDs) are a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner.
可以把RDD理解为Scala集合的分布式版本,Scala集合位于单个JVM,而RDD通过分区分布在多个JVM,这些JVM可能跨越不同的物理机器节点
下图是RDD的一个示意图:
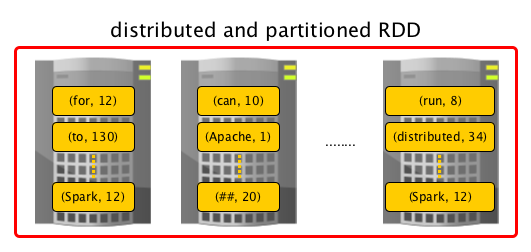
RDD的特点
RDD这种抽象是整个Spark的核心,具有如下特定:
- immutable: 不可变(只读)
- resilient: 弹性(容错)
- distributed:分布式(数据存储在整个集群的各个机器上)
- In-Memory:数据位于内存中(Spark提供了其他的持久化选项)
- Lazy evaluated:有Action触发时才会执行真正的操作
- Cacheable:内存不足以容纳数据时,可以缓存到磁盘
- Typed:每个RDD都有类型,例如RDD[String],RDD[(int,String)]
- patitioned:RDD的数据划分为多个Partition,分布在集群中,每个JVM(Executor)一个Partition。
不可变
RDD支持在其上做很多实用的数据操作,例如map,reduce等。但是这些操作不会修改原来的RDD,而是会产生一个新的RDD或者其他计算结果。一旦创建,RDD就不可修改,称为不可变的。类似于Java中的String,Google提供的基础库Guava中有很多不可变的集合类型,位于com.google.common.collection包下面。状态可变通常会引入复杂性,但是Spark RDD的不可变使得实现容错的方式比较直接。
弹性(容错)
Spark内置的容错和恢复机制使得RDD具备了弹性,当某些节点失败时,Spark可以重新计算得到RDD。在一般的分布式框架中,容错通常采用副本机制来实现,即把同一份数据在多台机器上存储副本,当其中的一些副本损坏时,可以从其他节点中恢复,HDFS中的数据容错就是采用这种机制。RDD则不一样,它通过记录创建RDD的一系列操作来达到容错,也就是记录RDD如果从原始数据演变成当前状态,不可变的特性提供了最基础的保障。当节点故障时,只需要重新计算位于该节点的数据(分区)。一个不太恰当的比喻,RDD记住的是最终答案是如何推倒出来的(记住的是RDD的lineage),而不是像HDFS把最终答案背下来。内部实现中,重新计算RDD通过compute方法进行:
compute(split: Partition , context : TaskContext): Iterator[T]
当请求一个RDD时,如果当前缓存中没有这个RDD,则调用compute计算。如果缓存中已有该RDD,则直接通过CacheManager获取。
分布式与分区
RDD三个词中另一核心词是分布式,一个集合的数据是分布在整个集群中的,更具体地说是执行上下文中,即Executor所在的JVM中。但这一点对用户来说是透明的,对用户而言,操作RDD和操作原生的list,map没有太大的不同。这里的透明不是绝对的,为了优化性能,我们可以控制数据集的分区,例如数据集分为几个partition,每个partition如何分布在集群中,也可以控制RDD分区的持久化机制。
一个RDD被分为若干个分区,分区是并行的基本单元,分区数量可以通过getNumPartitions:Int方法获取。可以在Spark管理界面4040端口查看到RDD的具体分区情况:

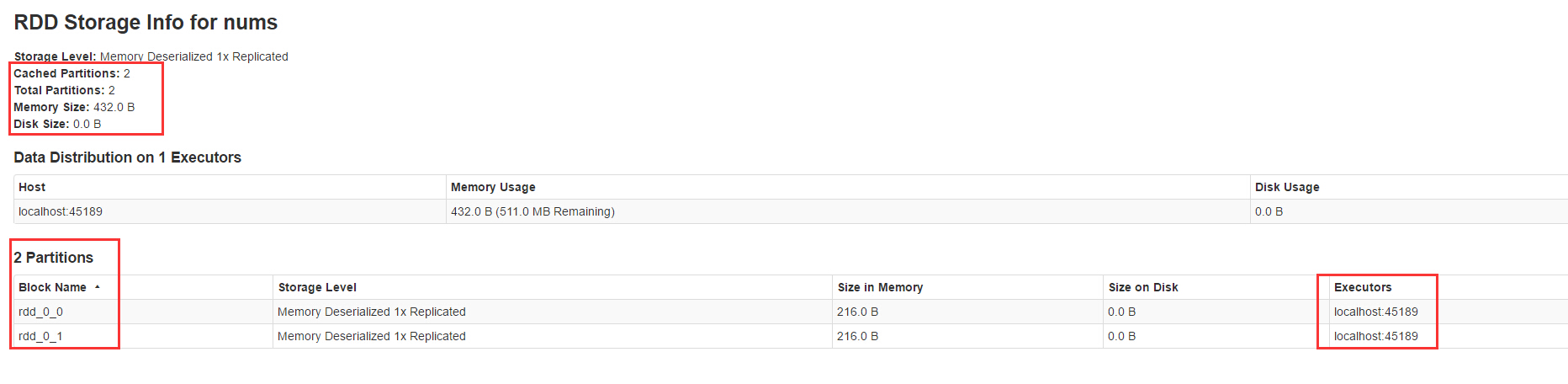
可以通过repartition或者coalesce操作来控制分区数量,在创建RDD时也可以指定分区数量,例如:
val nums = sc.parallelize( 1 to 1000 , 10)
第二个参数指定该RDD的分区数量为10. 在分区内部,数据是串行处理的。保存为外部文件时,也是分区的,类似result-part-000。RDD分布式的特点为并行计算提供了基础。
RDD类型
下面是一些常见的RDD类型:
- ParallelCollectionRDD: Scala集合并行化而来的RDD
- CoGroupedRDD
- HadoopRDD:读取来自HDFS的数据
- MapPartitionsRDD:map,filter,flatMap等操作返回的RDD
- CoalescedRDD:调用repartition或coalesce等操作的结果
- ShuffledRDD: Shuffle后的结果,例如repartition等操作
- PipedRDD:piping元素构成的RDD
- PairRDD:key-value 对,例如groupByKey之后的结果
- DoubleRDD: Double类型
- SequenceFileRDD: HDFS的SequenceFile创建而来的RDD
转换与动作
RDD通常在下面两种类型中使用:
- 迭代式算法:机器学习或者图计算中的算法
- 交互式分析:即席查询(ad-hoc queries)等数据挖掘工具
Spark提供了2种类型的操作:转换和动作。转换操作在已有的RDD上执行数据操作,产生新的RDD,例如filter,map,union等。动作则在RDD上触发计算,计算通常是为了返回结果给调用方或者写入到稳定的存储介质中,例如count,saveAsTextFile。一般可以根据返回类型来判断一个操作是转换还是动作。
理解转换最重要的一点是其惰性操作(lazy operation),转换操作只有在调用Action的时候才会真正发生。当Action被触发时,Spark检查RDD的lineage,并使用这些信息构建一个操作流图(graph of operations),执行这些计算流程得到最终的RDD。lineage的中文翻译是血统、世系,也就是说记住RDD的祖宗十八代,记录其如何从最原始的数据集中演变成当前状态,感受一下这张图:
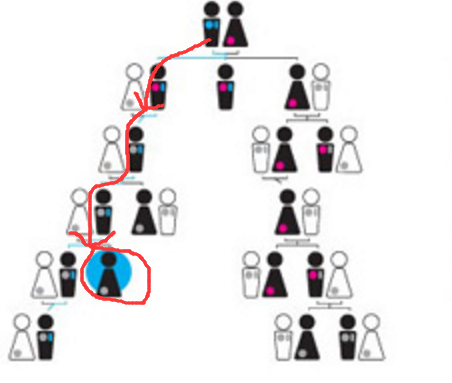
能够根据lineage重新计算RDD,是基于RDD的不可变特性,如果RDD是可变的,不同时间点的值是不一样的,那将无从还原。相比于采用副本实现的容错机制,RDD的容错其实是以不可变为代价的,在HDFS中,即使文件在集群中有多个副本,但是一旦追加新的内容,HDFS会自动帮助我们实现副本同步,也就是说数据是可变的,虽然大多数HDFS操作都是追加类型。计算RDD的整个过程通常使用有向无环图(DAG)来表示。例如,下图和对应的代码展示的是一个过滤日志的操作:
val lines = sc.textFile("hdfs://...")val errors = lines.filter(_.startWith("ERROR"))val hdfsErros = errors.filter(_.contains("HDFS"))val times = hdfsErros.map(_.split("\t")(3)
Transformation是作用在RDD上的懒操作,产生一个或者多个RDD:
transformation: RDD => RDDtransformation: RDD => Seq[RDD]
可以把转换理解为一个函数,接受一个RDD输入,输出一个或者多个RDD。有2中类型的转换操作:
- narrow transformation:
结果RDD中的Partition只能自己父RDD的一个Partition,例如map,filter。 这种narrow transformation可以组织为一个stage,称为pipeling。 - wide transformation:
结果RDD的Partition来自父多个RDD计算的结果,例如groupByKey,reduceByKey等操作。wide transformation有时候也称为shuffle transformation。为了使得key相同的元组都到同一个分区中(被同一个Task处理),Spark必须执行RDD shuffle,shuffle在集群中传输数据,其结果是一个新的Stage和一系列新的分区。
定义RDD的几个方面
一个RDD由5个主要的方面来定义:
1)List of Parent RDDs: RDD依赖的父级RDD
RDD的依赖可以通过dependencies方法获取:
nums.dependencies.map(_.rdd).foreach(println)
依赖又分为shuffle dependency和narrow dependency
2)组成RDD的partition数组
RDD的partitions返回该RDD的分区。
3)作用于分区上计算函数
各种转换及Action,能够在RDD上进行何种操作,很大程度上决定了这种RDD是否好用。
4)定义如何分区的Partitioner
Partitioner决定RDD如何分区:
val partitiner: Option[Partitioner]
常见的有HashPartitioner等。
5)位置偏好:分区更倾向于放在那些节点上
位置偏好(locality pregrence or placement preference)是指RDD分区在HDFS中Block的存储位置,可以通过下面的方法获取:
getPreferredLocations(split: Partition): Seq[String]
RDD位于SparkContext中,一般一个SparkContext对应一个Spark应用。RDD有一个特定的名字和ID。不同SparkContext之间的RDD不能共享,即RDD不能在不同的应用之间共享,只能在同一个应用(SparkContext)内部的作业之间共享。
RDD的id创建时被分配,可以通过id属性来访问,名字可以通过name方法,并且name是可以被修改的:
val nums = sc.parallelize(1 to 200)nums.idnums.namenums.name = "meaningful name"
在Spark Shell中打印出来的是RDD的Debug信息,可以通过toDebugString获取:
nums.toDebugString
Filter操作
filter转换用于过滤RDD元素。filter方法在RDD类定义,其签名如下:
class RDD[T] {// 其他方法def filter( f : (T) => Boolean: RDD[T]}
RDD类定义了一个泛型参数T,类似于Java中的RDD<T>。事实上Spark提供的Java API就是这样的。filter的参数接受的是一个函数,这个函数接受类型T的元素,返回一个布尔值。filter方法最终返回的是另一个同类型的RDD。
Scala中,函数的声明使用的是关键字def,类似于声明不变量的val和声明可变量的var。可以这样来读这个方法:
声明一个叫做filter的函数,接受一个函数类型的参数,返回一个同类型的RDD。
filter返回的RDD类型与原始RDD是一样的,它只是移除了不满足条件(通过传入的函数来判断)的元素,这里的移除是逻辑上的概念,而不是真正移除RDD元素,因为RDD是不可变的。然后使用剩下的元素构建一个新的RDD,原来的RDD保持不变(也不可以变)。
在参数的定义中,我们看到是个函数,名称叫f。参数类型是T,返回Boolean。T表名该参数类型与RDD定义的泛型T是一样的,例如RDD是Int类型(RDD[Int]),则参数类型就为Int,filter返回的RDD元素类型也是Int。例如:
val nums = sc.parallelize( 1 to 10)val numsEven = nums.filter( num => num % 2 ==0)numsEven.foreach(println(_))
SparkContext的parallelize方法把集合并行化,即把集合分布到集群中。在Spark Shell中,我们可以看到nums的类型是ParallelCollectionRDD:
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:21
过滤之后的numsEven是MapPartitionsRDD:
numsEven: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at filter at <console>:23
这是因为filter操作会在整个集群中并发运行,即执行的是Map任务(Spark中有Map Shuffle和Result两类Task)。
foreach这个Action针对每个元素执行println操作:
246810
Predicate Function
filter函数接受的参数是一个predicate函数,predicate是断言的意思:
That which is affirmed or denied
在函数式编程中,断言函数定义为返回true或者false的函数,断言函数基于给定的原书是否满足某些条件来返回结果。
函数在Scala中是一等公民,可以被存储在变量中,可以作为其他函数的输入参数,或者作为函数的返回值。如果一个函数接收一个函数类型的参数,或者返回一个函数,就称为高阶函数(higher order function)。
上述中,我们传给filter的是一个匿名函数,但是我们也可以先定义:
def isEven(num Int) = { num % 2 == 0 }
REPL提示我们:
isEven: (num:Int) Boolean
我们也可以把函数定义存储在一个变量中:
val isEvenInVal = (num:Int) => num % 2 == 0
然后传递给filter:
val numsEven = nums.filter(isEvenInVal)
