@BrandonLin
2016-07-29T16:29:55.000000Z
字数 7243
阅读 5503
Sqoop
Hadoop Sqoop
简介
Sqoop是一个用于在外部结构化数据与Hadoop之间导入导出数据的工具。
Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
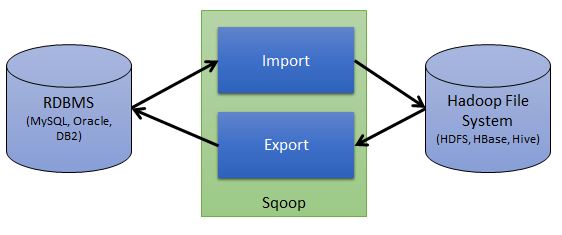
Sqoop:
- 是一个命令行工具?
- 使得结构化数据与Hadoop之间的导入导出变得容易
- 可以导入整个库或者单个表
- 可以与Oozie集成,将 导入导出作为工作流的一部分。
- 内部转化为MapReduce,用于传输数据
下载安装配置
根据Hadoop版本选择对应的Sqoop,我这里是Hadoop,选择Sqoop 1.99.6:
wget http://mirrors.hust.edu.cn/apache/sqoop/1.99.6/sqoop-1.99.6-bin-hadoop200.tar.gztar zxvf sqoop-1.99.6-bin-hadoop200.tar.gzmv sqoop-1.99.6-bin-hadoop200 /home/sqoop-1.99.6
配置PATH:
vim /etc/profileexport SQOOP_HOME=/home/sqoop-1.99.6export PATH=$PATH:$SQOOP_HOME/binsource /etc/profile
配置server/conf/catalina.properties
common.loader=${catalina.base}/lib,${catalina.base}/lib/*.jar,${catalina.home}/lib,${catalina.home}/lib/*.jar,${catalina.home}/../lib/*.jar,/home/hadoop-2.6.0/share/hadoop/common/*.jar,/home/hadoop-2.6.0/share/hadoop/common/lib/*.jar,/home/hadoop-2.6.0/share/hadoop/hdfs/*.jar,/home/hadoop-2.6.0/share/hadoop/hdfs/lib/*.jar,/home/hadoop-2.6.0/share/hadoop/mapreduce/*.jar,/home/hadoop-2.6.0/share/hadoop/mapreduce/lib/*.jar,/home/hadoop-2.6.0/share/hadoop/yarn/*.jar,/home/hadoop-2.6.0/share/hadoop/yarn/lib/*.jar,/home/hadoop-2.6.0/share/hadoop/tools/*.jar,/home/hadoop-2.6.0/share/hadoop/tools/lib/*.jar,/home/hadoop-2.6.0/share/hadoop/httpfs/tomcat/lib/*.jar
配置server/conf/sqoop.properties:
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/home/hadoop-2.6.0/etc/hadoop
验证是否配置正确:
sqoop2-tool veriify

启动sqoop server:
% sqoop2-server start
启动的的tomcat运行在12000端口。
启动客户端shell:
sqoop2-shell

Sqoop实例
启动Hadoop集群:
start-dfs.shstart-yarn.sh
启动sqoop2-shell:
sqoop2-shell
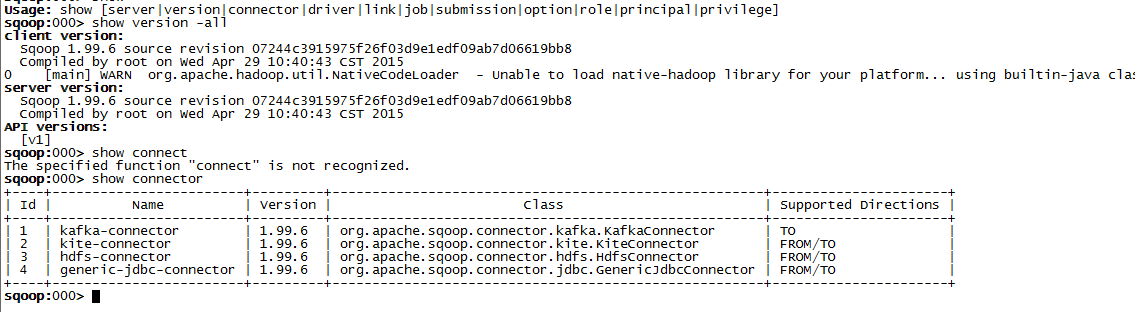
查看版本和connector:
show version -allshow connector
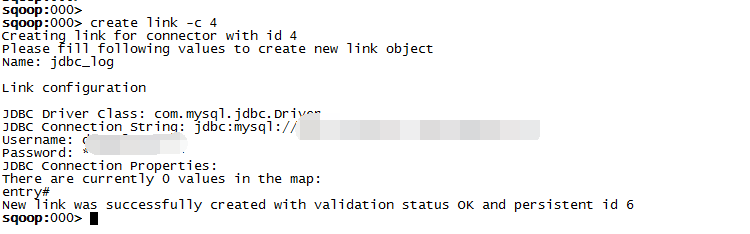
创建JDBC link:
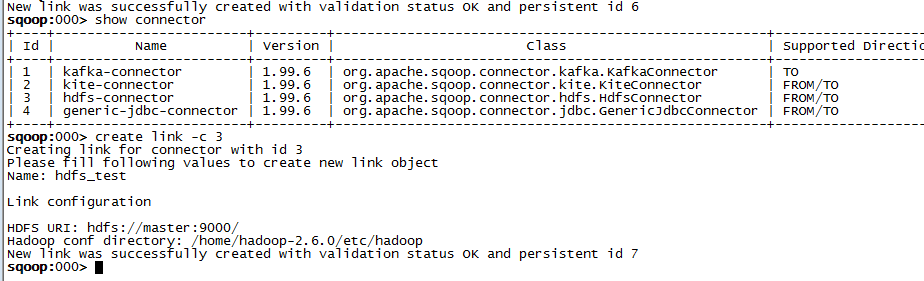
创建HDFS link:
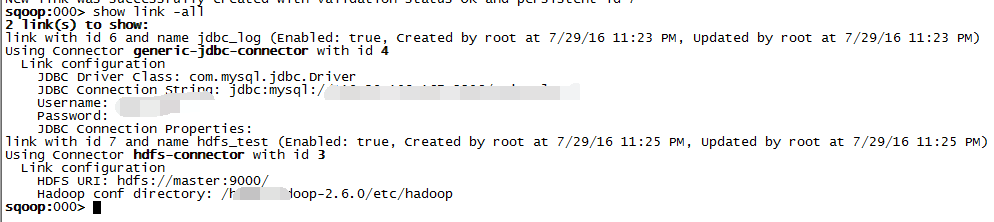
查看可用link
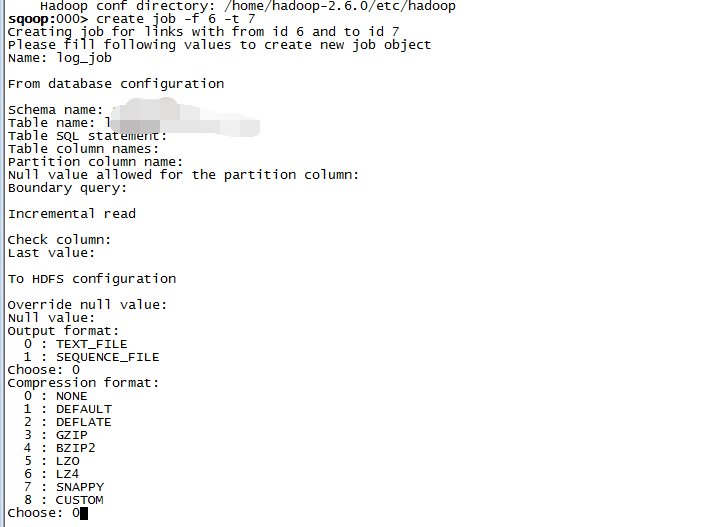
创建从JDBC到HDFS的作业:
create jon -f 6 -t 7
f和t分别指定from和to的link。然后主要是配置数据源中的数据库和表,分区字段,文件格式,压缩格式等:
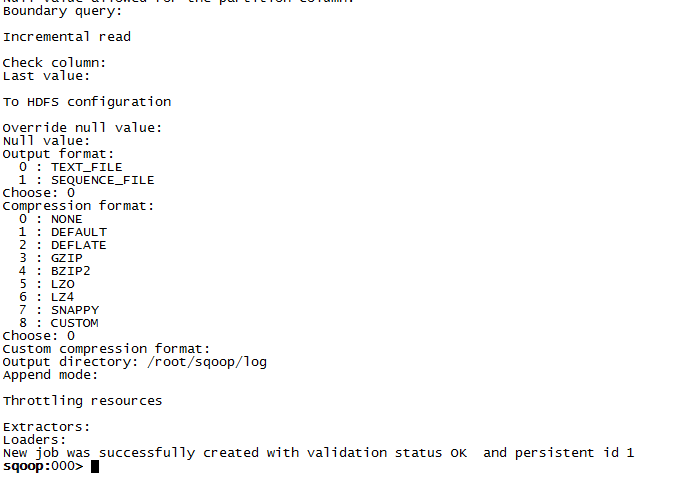
启动刚才创建的作业:
start jon -j 1
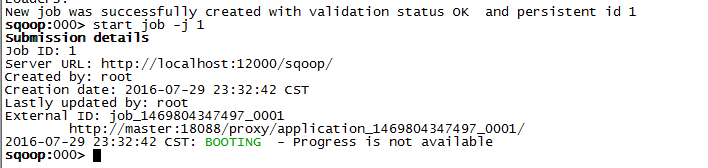
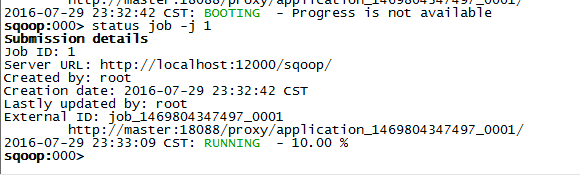
查看进度:
YARN管理界面中的MapReduce作业:

查看HDFS上是否有文件:
hadoop fs -ls /root/...
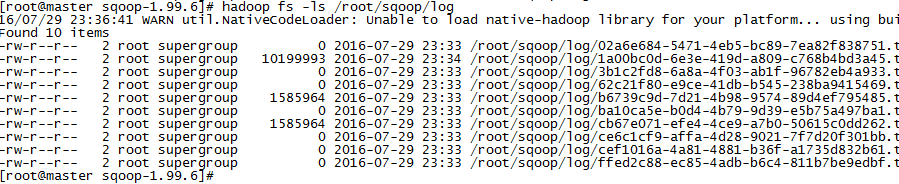

最后运行结果:
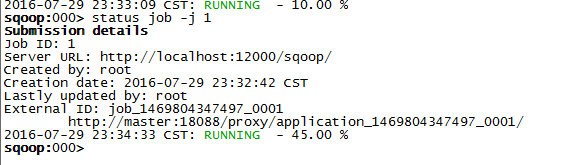
sqoop: status job -j 1
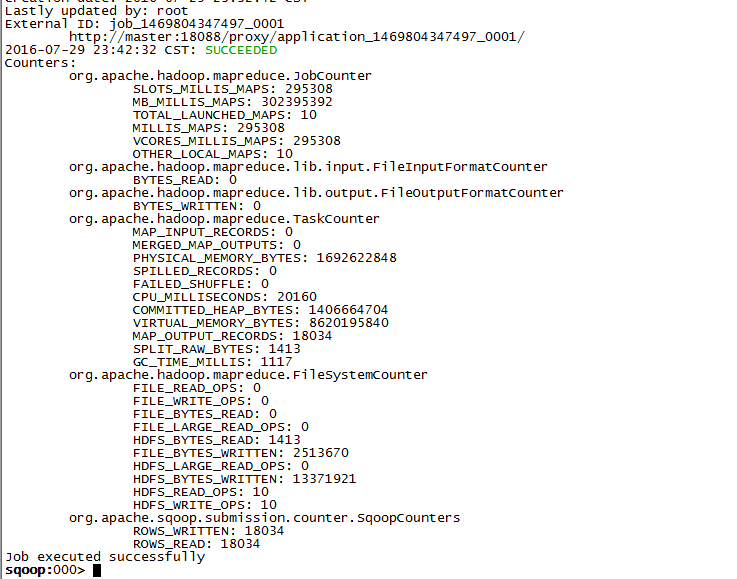
如果发现无法查看作业状态,出现如下异常:

从server的tomcat日志查看到如下异常:
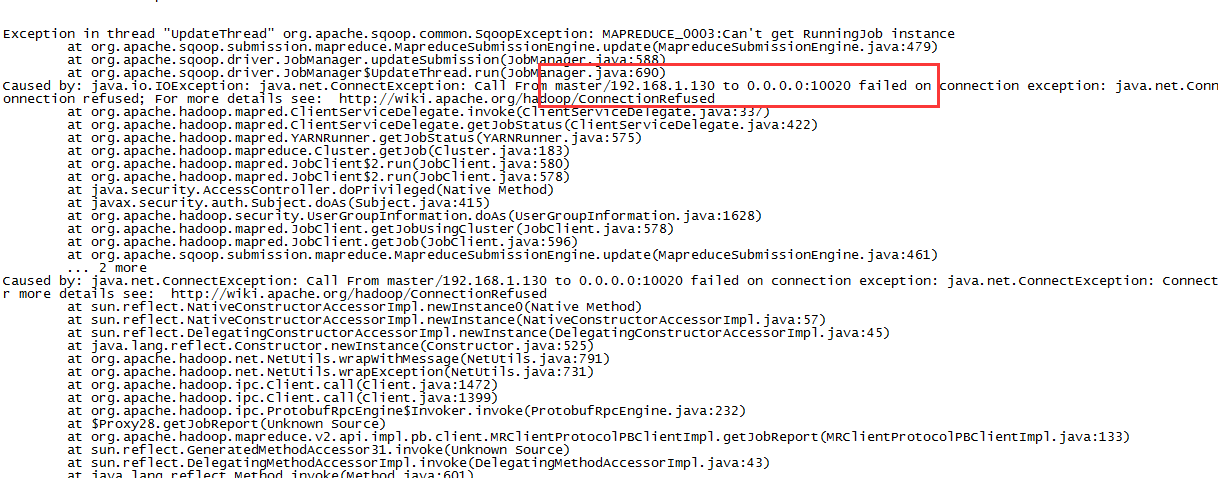
根据经验判断,是没有启动历史作业的服务器,使用如下命令启动:
mr-jobhistory-daemon.sh start historyserver
从YARN管理器上看:
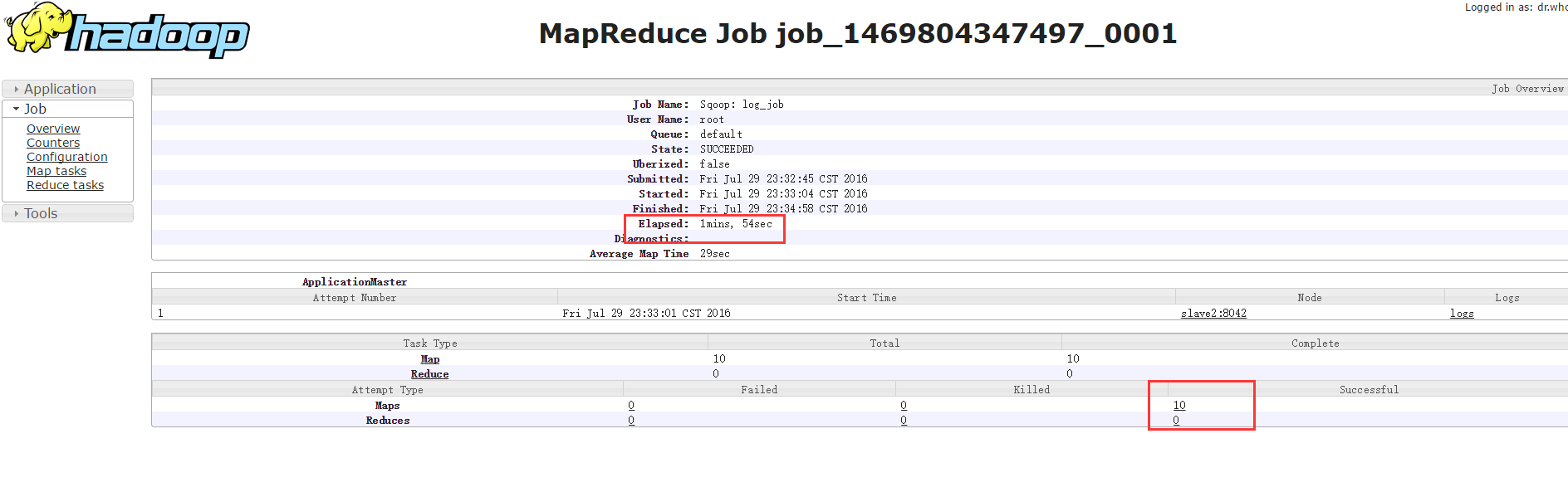
可见Sqoop启动了一个只有map没有reduce的MapReduce作业,使用了10个map。耗时一分钟54秒。
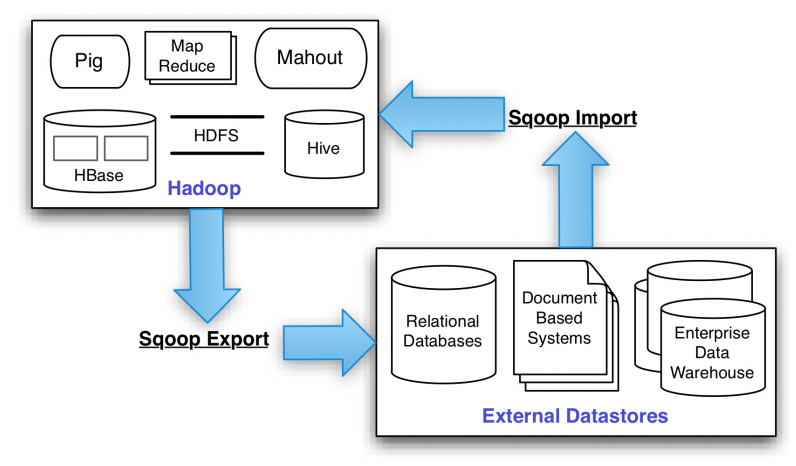
核心概念:Sqoop Connector
Sqoop的整个架构是基于Connector的,外部的结构化数据与Hadoop之间通过Connector连接器完成数据传输。例如针对RDBMS的MySQL连接器,Oracle连接器等,还有一个通用的JDBC连接器。
另外一些Connector针对特定的数据库做了优化,例如使用MySQL的mysqldump可以提高导入效率,这称为Direct-Mode。除了内置的Sqoop Connector外,还有许多第三方的Connector,包括像Couchbase这样的NoSQL数据库。
可以通过sqoop2-shell的命令查看可用的connector:
sqoop: show connector

工作原理
Sqoop内部将数据集划分为不同的分区(Partition),然后使用只有map的MapReduce作业来完成数据传输,每个mapper负责一个分区。Sqoop使用数据库元数据来确保类型安全。
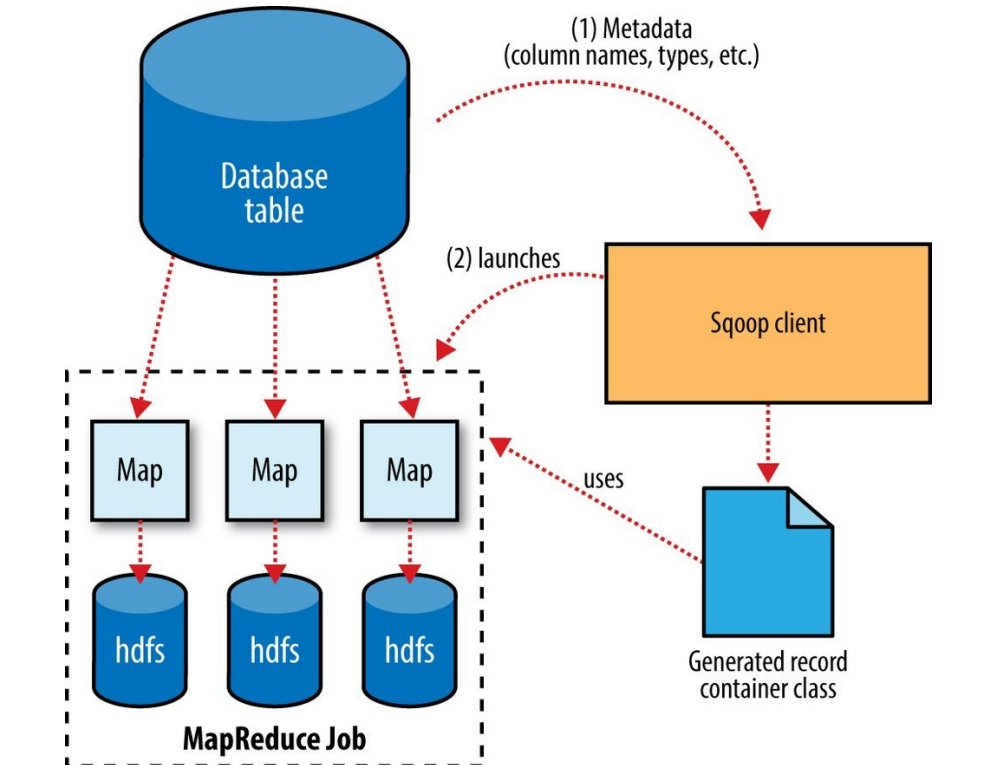
代码生成:
% sqoop codegen --connect jdbc:mysql://localhost/hadoopguide \--table widgets --class-name Widget
可以把生成的代码看做是指定表的数据访问对象(DAO)。生成的代码保存表中提取出来的一条数据,可以在MapReduce中操作数据或者存入到SequenceFile中,每条记录作为value保存在文件中。
基于文本的文件可以不生成代码。
Sqoop启动MapReduce作业用于传输数据。InputFormat可以通过JDBC读取表中的部分数据。Hadoop自带的DataDrivenDBInputFormat用于对表数据进行分区,每个map传输其中的一部分数据。
数据分区一般根据表中特定的列,例如主键。在运行时可以通过指定--split-by参数指定分区使用的列。
可以通过--where参数对导入的数据进行过滤,更复杂的控制可以通过--query参数完成,这在增量任务中很有用。
由于导入进程是并发执行的,进行事务控制很困难。因此通过使用关闭数据写入的方式来保证数据的一致性。
增量导入
通过使用--check-column和--last-value参数,可以增量导入新增的数据,Sqoop只导入指定列中大于last-value的记录。
对于写入后不更新的数据,并且ID是严格递增的,可以使用--incremental参数增量导入。
会更新的数据,可以使用--incremental lastmodified来增量。增量导入结束后,Sqoop会打印出--last-value,用于下次使用,但是更好的方式是使用Sqoop自动保存这个值,下次的时候也自动使用这个值。
Direct-Mode导入
大部分导入都通过DataDrivenDBInputFormat来实现,但是有些数据提供了专门的工具用来快速导入,例如MySQL的mysqldump,这个工具的吞吐量远大于JDBC的能力。使用这些外部工具来完成导入,sqoop中成为Direct-Mode,MapReduce作用启动myqldump,然后读取其输出文件,导入数据。这种模式通过--direct参数来启用,同时会受到一些限制,例如使用mysqldump无法读取CLOB,BLOB这样的数据类型。数据库元数据的获取依然是通过JDBC来完成。
导入后的数据处理
通过Sqoop导入的数据,如果是文本,那么在处理的时候可能需要完成类型的转换,sqoop的生成代码可以帮助完成这个工具,使得我们可以专注于MapReduce的业务逻辑。运行这些作业时,需确保Sqoop的库可以被读取到。驱动程序中可以通过HADOOP_CLASSPATH环境变量来配置:
HADOOP_CLASSPATH=$SQOOP_HOME/sqoop-version.jar
Map作业节点上可以通过libjars参数设置:
hadoop jar className example.jar -libjars $SQOOP_HOME/sqoop-version.jar
如果导入的文件是Avro格式,可以通过Avro MapReduce来处理,通过使用Generic Avro mapping来完成,可以不使用Schema生成的代码。
导入数据与Hive
Sqoop与Hive经常作为工具组合来处理来自关系型数据库中的数据。使用Sqoop提供的工具可以从关系型的元数据中生成Hive表:
sqoop create-hive-table --connect jdbc:mysql://localhost/hadoopguide --table widgets --fields-terminated-by ','
由于Hive的数据类型跟大部分关系型数据库相比较都比较简陋,因此Sqoop在生成Hive表的时候,会尽可能使用接近的数据类型。但是这还是可以导致丢失精度的情况,这时候Sqoop会给出警告信息。例如:
WARN hive.TableDefWriter: Colum design_date had to be cast to a less precise type in Hive
假设widgets表的数据已经通过Sqoop导入到HDFS中的widgets目录,使用下面的命令可以将这些数据导入到创建的Hive表:
LOAD DATA PATH "widgets" INTO TABLE widgets;
导入数据到HDFS、创建Hive表、导入HDFS的数据到Hive表这三个步骤可以被简化成一个步骤:
sqoop import --connect jdbc:mysql://localhost/hadoopguide --table widgets -m 1 --hive-import
使用--hive-import参数导入数据的时候,Sqoop直接把数据从源数据库导入到Hive表,Hive的Schema通过元数据推断而来。
导入到Hive后,就可以结合其他数据,例如LOG日志进行数据分析了。
hive> CREATE TABLE sales(widget_id INT ,qty INT, street STRING,city STRING , state STRING,zip INT , sale_date STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';hive> LOAD DATA LOCAL INPUT "/path/to/logs/sales.log" INTO TABLE slaes;hive> CREATE TABLE zip_profits AS SELECT SUM(w.prices * s.qty) AS sales_vol , s.zip FROM SALES s JOIN widgets w ON (s.widget_id = w.id) GROUP BY s.zip;hive> SELECT * FROM zip_profits ORDER BY sales_vol DESC;...OK403.71 9021028.0 10005
导入大对象
大多数数据库都允许我们将大量的数据存在一个字段,通常有存储文本的CLOB和存储二进制的BLOB。在存储方式上,为了避免扫描时读取大对象字段到内存中,通常不在记录中内联存储大对象,而是独立到外部。
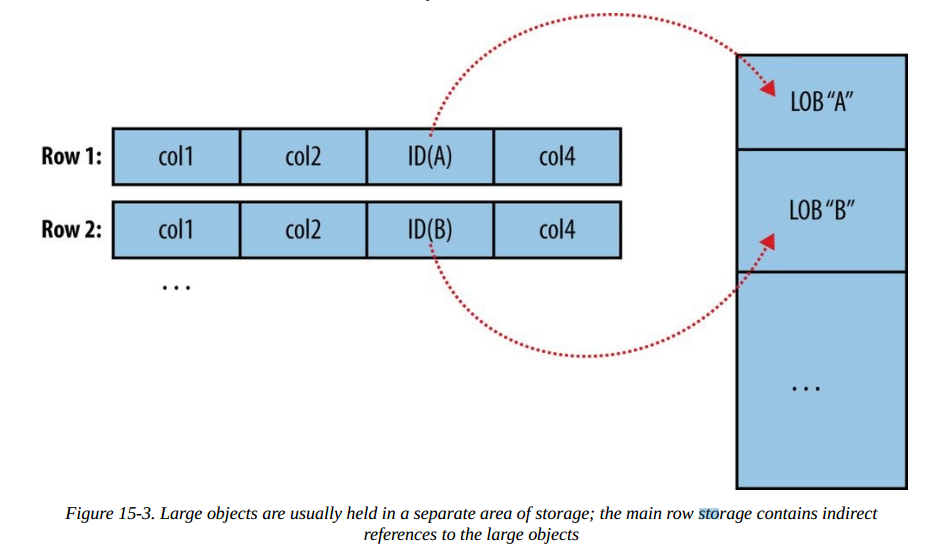
在MapReduce中,数据在送往mapper之前,通常需要物化到内存中,如果把大对象跟其他普通字段存在同一个文件中,将会导致MapReduce性能非常低下。所以Sqoop导入的数据在存储格式上跟数据库非常相似,如果大对象的大小超过16MB(通过sqoop.inline.lob.length.max设置),会被存储在另外的文件中,这种文件的格式为LobFile,LobFile中的每条记录存储一个大对象。这样在客户端(如MapReduce)读入数据的时候,无需读入整个大文件,而只是存储一个引用,当真正需要访问时,则通过该引用进而通过InputStream访问具体的大对象数据。
二进制大对象的引用是一个BlobRef,其格式如下:
externalLob(lf,lobfile0,100,5011714)
分别代表格式为LobFile,存储在lobfile0中,偏移量为100,数据长度为5011714字节。通过BlobRef的getDataStream方法,可以获取到指向大对象的输入流(InputStream)。
CBLOB类似的使用ClobRef引用。
在MapReduce中,访问大对象的次数经常很少,通过这种外部文件加引用的方式,可以大大提高IO效率。
数据导出
Sqoop也可以用于将数据从Hadoop导出到外部数据库。在导出之前,需要先手动创建表(Sqoop可以从SQL类型推断Java类型,但是不能够从Java类型正确推断SQL类型,例如Java的String可以存为CAHR,VARCHAR或者其他类型,因此必须手动创建对应的表。
导出命令如下:
sqoop export --connect jdbc:mysql://localhost -m 1 --table sales_by_zip --export-dir /user/hive/warehouse/zip_profits --input-fields-terminated-by '\0001'
上述命令导出Hive的zip_profites表到mysql的sale_by_zip表,其中指定了Hive文件中默认的字段分隔符CTRL+A(Unicode字符为0x0001)。
在导出数据之前,Sqoop会根据connect string选定一种策略,例如使用mysqlimport或者JDBC。然后基于目标表的元数据生成一个类,这个类能够从文本文件中解析出记录,并将记录插入到对应的表。然后启动一个MapReduce作业,从HDFS中读取文件,用生成的类解析成记录,并用选定的策略执行导出。
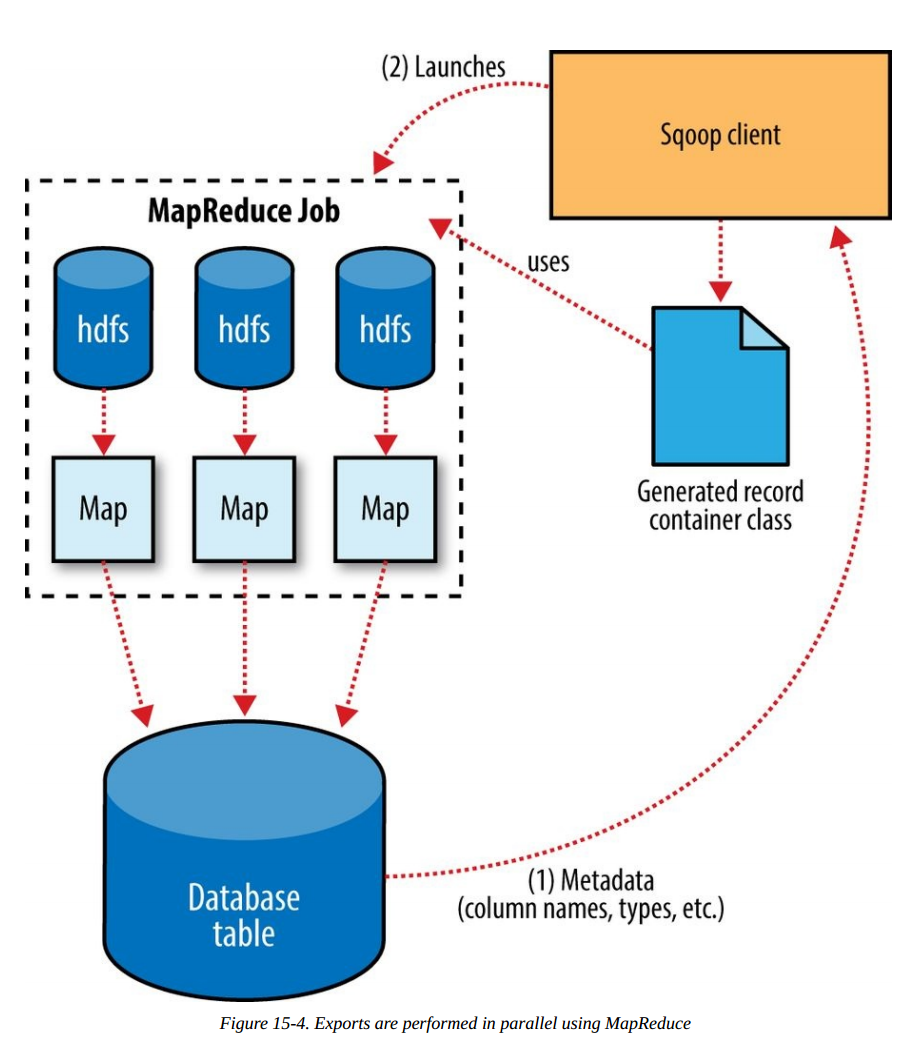
对于mysql的direct-mode,每个map任务启动一个mysqlimport进程,并使用FIFO文件进行通信,导入数据到mysql。map的数量可以通过-m选项指定。基于JDBC的策略会使用批量的模式导出数据。
导出数据是不具备事务性的,并行的导入map可能在不同的时间结束,即使在任务中使用事务,前一个任务的输出也可能在后续的task完成之前可见。另外数据库经常使用固定大小的缓冲来保存事物,这个缓冲很有太小容纳不下一个任务重的所有数据。因此通常在导出完成之前,其他使用数据的应用最好不用访问数据,避免只看到部分结果。
有一种方式可以解决这个问题,Sqoop允许我们先将数据导出到一个临时表,然后在导出结束之后,使用单个事务将中间表导入最终的目标表。临时表通过--staging-table参数指定,这个临时表必须是已经存在的表并且是空的,除非指定了--clear-staging-table参数。使用这种方式会导致性能下降,因为数据需要写两次,并且在最后的数据移动阶段,其实是有2份数据的,占用了更多的空间。
导出SequenceFile
Sqoop可以导出非Hive表的数据,例如SequenceFile类型的文件,但是有较多的限制。
% sqoop import --connect jdbc:mysql://localhost/hadoopguide --table widgets -m 1 --class-name WidgetHolder --as-sequencefile --target-dir widget_sequence_file --bindir .
as-sequencefile指定导入味SequenceFile,bindir指定jar包放在当前目录下,供下一步使用。
%mysql hadoopguidemysql> create table widgets2 (id int ,widget_name varchar(100),price double,desigened date , version int,notes vatchar(200);
% sqoop export --connect jdbc:mysql://localhost/hadoopguide --table widgets -m 1 --class-name WidgetHolder --jar-file WidgetHolder.jar --export-dir widget_sequence_files
jar-file指定上一步中生成的jar包。
参考
官网安装指南:
http://sqoop.apache.org/docs/1.99.6/Installation.html
官网5分钟Demo:
http://sqoop.apache.org/docs/1.99.6/Sqoop5MinutesDemo.html
