@zhutoulwz
2016-04-09T03:19:27.000000Z
字数 918
阅读 2069
mahout相关操作
mahout hadoop
mahout执行自带例子
mahout运行自带的kmeans算法例子:
先下载样本数据
wget http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data
样本数据上传至HDFS,文件名称为
testdatahdfs dfs -put synthetic_control.data testdata
执行命令
$HADOOP_HOME/bin/hadoop jar mahout-examples-0.10.0-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
或者在
mahout安装目录下(注:此方式样本数据不需要上传到HDFS,需放在当前目录下,名称为testdata)bin/mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
结果
第一种方式:执行结果在HDFS,在output文件下会有多个clusters,如下图:
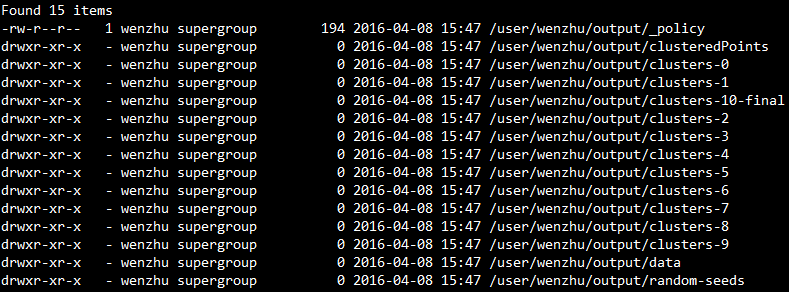
第二种方式:执行结果在当前目录下的output文件夹,内容与第一种方式相同
将HDFS上的mahout运行kmeans算法的结果拉取到本地:
bin/mahout seqdumper -i output/clusters-10-final/part-r-00000 -o /home/wenzhu/out/part-10
其中,
-i参数为HDFS上结果的路径,-o为拉取到本地的保存路径
在hadoop上运行自定义mahout程序
- 使用
Eclipse打包自定义mahout程序,生成jar包 执行命令,命令格式如下:
mahout hadoop jar jar包 Mainclass [args...]
举个例子:
mahout hadoop jar test.jar com.example.TestClass
其中
test.jar是自定义mahout程序jar包,com.example.TestClass为Main class,可以不包含参数
参考文章:
1. 用Maven构建Mahout项目
