@zakexu
2020-01-07T05:15:57.000000Z
字数 6214
阅读 2338
腾讯知文自然语言处理平台上云实践
项目总结
首发时间:2019.8.14
作者:zakexu(个人主页)
目录
前言
笔者自去年年底开始负责腾讯知文自然语言处理平台的公有云研发以及其标准化产品的私有化交付。依托于团队过往在内部业务的NLP沉淀,深度整合公司内部优秀的NLP技术,通过半年时间的产品打磨,目前腾讯知文自然语言处理平台V1.0版本已经正式上云并对外开放。借此机会,笔者将对这半年来上云过程中的研发经验进行简单的总结沉淀,一方面是可以对整个平台从0到1的研发复盘,将部分细节透明化,从而利于平台的持续迭代升级;另一方面也是想将研发过程中遇到的一些问题抛出来,希望可以跟同行大佬们进行深度交流,从而完善方案选型。
一、产品介绍
腾讯知文自然语言处理平台通过服务的方式对外提供一套丰富、高效、精准的底层中文自然语言处理模块。依托于海量中文语料积累,深度整合了腾讯内部(包括腾讯 AI Lab,腾讯信息安全和知文团队自研等)优秀的NLP前沿技术,知文NLP原子化能力可以帮助用户快速搭建内容搜索、内容推荐、舆情识别、文本结构化、问答机器人等智能产品。作为腾讯云对外NLP服务的统一出口,知文NLP将辅助我们的客户在日常工作或者企业运营方面降本、增效、创新,目前已经广泛应用在社交通讯、文化娱乐、金融服务、电商、政务等行业客户的多项业务中。
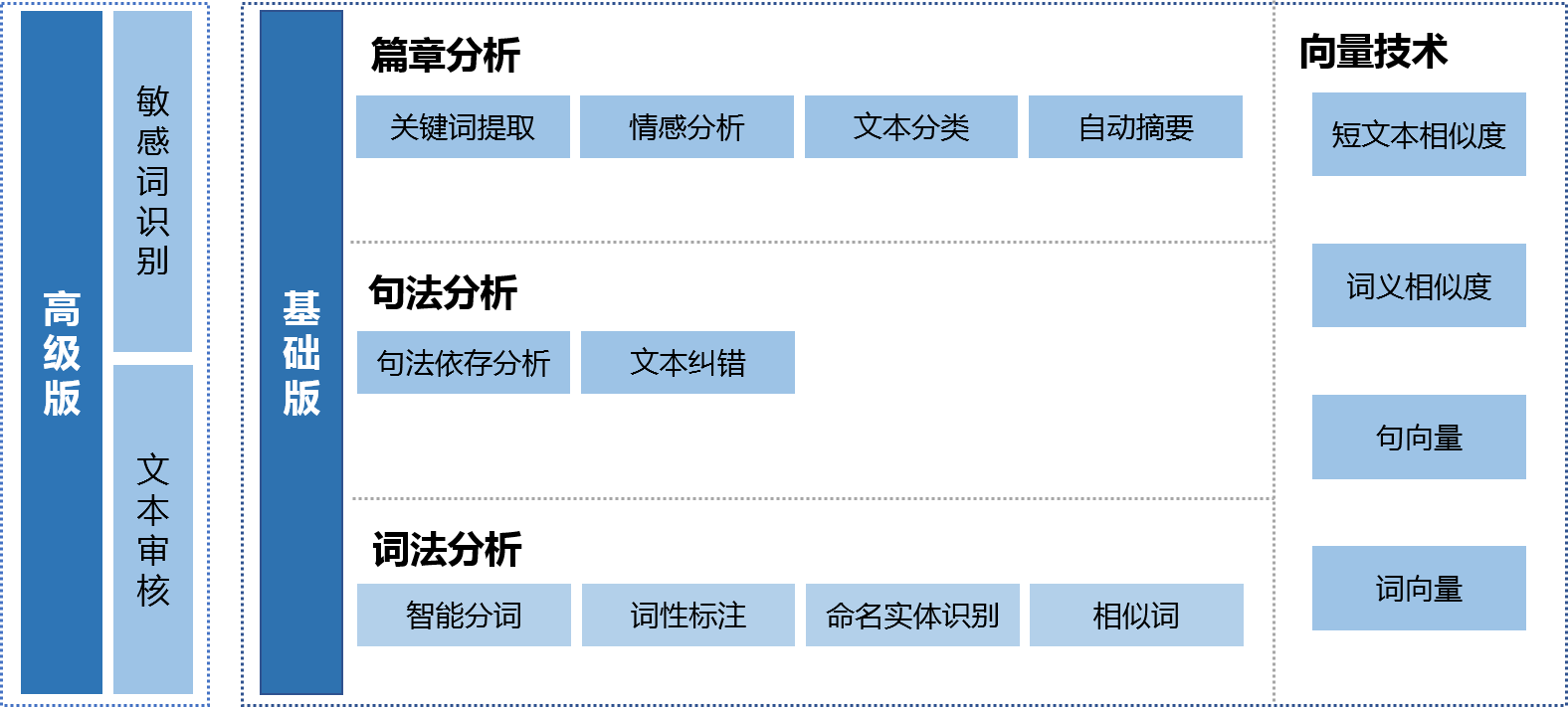
知文NLP全面覆盖了从基础到高级的智能文本处理能力。其中,基础版包括词法分析、句法分析、篇章分析、向量技术、情感分析、文本分类等,高级版包括敏感词识别、文本审核等。具体的服务板块可见图1,更详尽的介绍以及使用方式请移步官网API文档,目前公测阶段,可免费使用。同时也打个小广告,欢迎各行业务寻求合作,也欢迎优秀的NLP能力提供方上云提供服务。
二、系统架构
为了保障线上服务的稳定性以及高效性,整个产品的系统架构采用的是微服务 + DevOps的构建方式,每一个服务都是单独的容器实例,具体的架构参见图2。
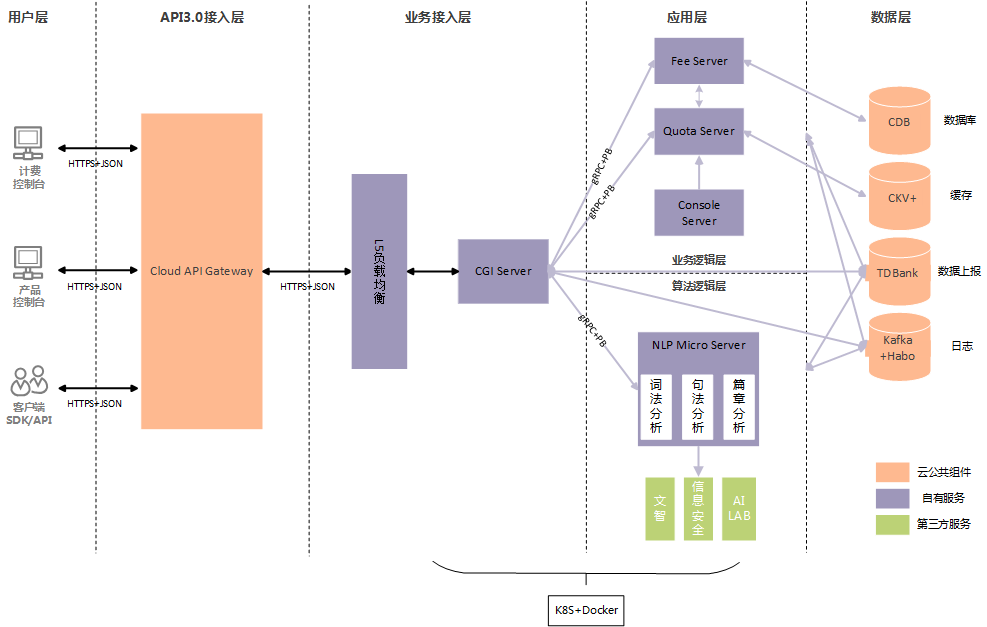
整个产品的系统架构可以分为5层,分别是用户层、API3.0接入层、业务接入层、应用层、数据层。其中用户层主要包括计费、控制台管理以及SDK/API使用。API3.0接入层是所有云上业务对外提供服务必须接入的,目的是为了统一云业务规范,对齐业界标准,从而提升用户对云api的体验;除此之外,云API3.0还接入了公司内部的星云告警系统、哈勃监控系统以及CAM签名服务,能够保障服务的正常运行,同时还减少业务的部分工作量。业务接入层、应用层以及数据层属于业务后端服务。其中业务接入层主要负责服务的接入以及路由。应用层则包括业务逻辑层跟算法逻辑层,业务逻辑层指计费、额度、控制台等服务;算法逻辑层是整个系统架构的核心,也是知文NLP产品的价值体现,需要不断迭代更新,目前总共有10+个算法微服务。最后的数据层则负责数据的存储、上报等,采用的都是目前腾讯云主流的组件。
上述所有的业务后端服务都是基于微服务架构,区别于传统的单体服务,我们将不同的业务逻辑划分成小的服务,服务之间通过相互通信的方式来进行调用。服务与服务之间采用的是轻量级的通信机制进行沟通(目前我们的架构中既支持gRPC也同时支持基于http的Restful API),每个服务都是围绕独立的业务逻辑进行构建,同时能够被独立地部署到生产环境、测试环境等。知文NLP后端服务采用上述的微服务架构,主要是基于以下几点考虑:(1)知文NLP平台涵盖十多个原子化算法服务,采用微服务的架构有利于算法的独立开发以及独立部署,能够更灵活、更快速地响应算法频繁的迭代需求;(2)基于微服务的架构可以实现松耦合且各个服务之间无需统一语言,可以加速合作伙伴上云的节奏;(3)微服务架构结合容器化的DevOps平台,可以简化服务的部署以及运维。
关于整个服务架构的一些关键点选型,这儿可以做一个简单的描述:(1)开发语言:业务逻辑层基于golang开发,主要是golang无法拒绝的优点加上没有历史包袱,果断选择golang;算法逻辑层是基于java开发,主要是在性能以及NLP算法支持粒度两者中间做的权衡选择。(2)通信协议:目前是兼容gRPC跟基于http的Restful API,相比Restful API基于json的数据传输方式,gRPC是基于二进制的pb数据格式,传输性能相对更优,更适合于微服务之间的通信;但考虑到私有化交付的场景,Restful API的重要性也不言而喻;除此之外,我们目前的DevOps平台采用的是公司内部的蓝盾平台,对gRPC协议的连接池支持并不友好,因此目前线上服务暂时采用的是Restful API的协议,关于协议的选型,这点我们也在持续的调研对比中。(3)DevOps平台:K8S + Docker容器的方式作为目前主流方案当仁不让,这一块我们依托蓝盾进行部署。
三、算法微服务
由于知文NLP平台涉及的算法微服务起码10+种,参与的开发同学也比较多,为了提高开发的效率以及规范,如何让开发的同学更多地关注算法逻辑的实现而避免重复的业务逻辑开发成为首要问题。因此,我们设计了如下的工程结构(见图3)。
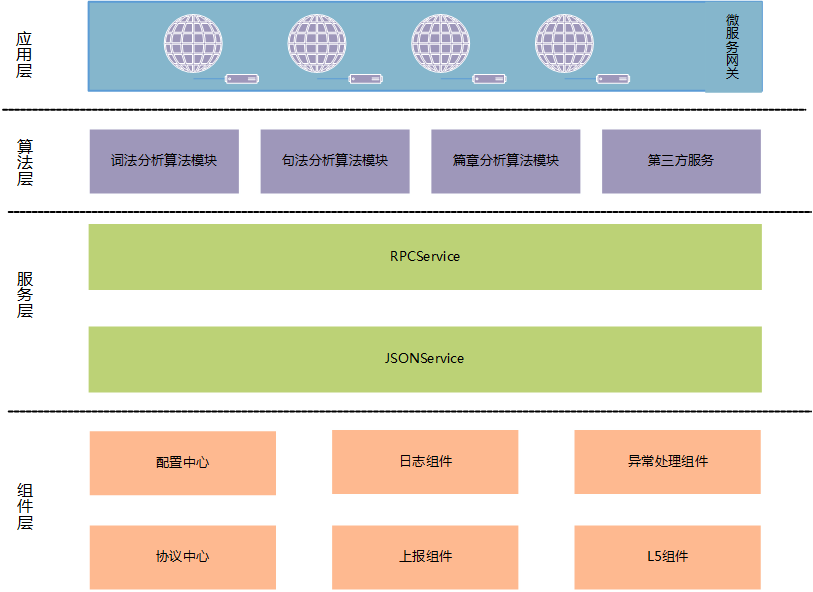
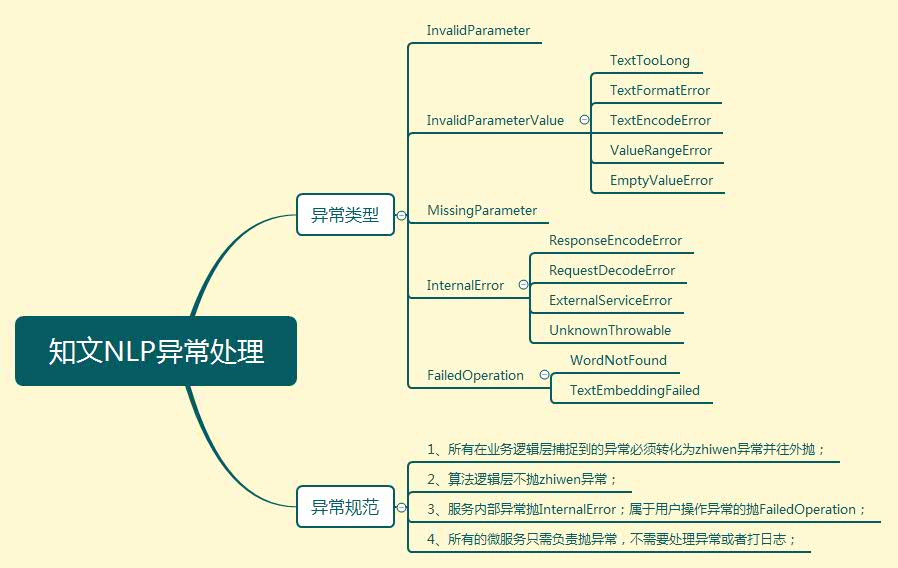
整个算法微服务的工程结构可以分为4层,分别是组件层、服务层、算法层以及应用层。组件层主要是一些常见的逻辑封装;其中配置中心负责算法模型参数设置、微服务的端口管理等;协议中心负责微服务的入参出参配置,需要满足API3.0规范;日志跟上报组件主要采用本地写文件的方式来进行上报,一方面是保证微服务容器是一个无状态服务,另一方面也是为了兼容私有化部署场景;L5组件主要是在第三方服务调用的场景使用,起到负载均衡的作用;异常处理组件主要是对各种异常的封装处理,这儿我们封装了一套满足API3.0的异常类型以及规范,可以见图4。
服务层提供了RPCService跟JSONService两种服务选择,各个算法微服务可以根据自己服务的特性选择合适的协议;除此之外,该service会统一处理异常、日志以及上报的埋点,开发的同学只需要关心算法层的逻辑实现即可。算法层是跟业务逻辑完全解耦的,只需要负责算法的实现即可。最后的应用层主要是一些微服务的网关,在我们的算法微服务中,一个算法API可能会涉及到多个版本模型服务的使用,网关主要是负责流量的分配以及路由。
四、CI持续集成/CD持续部署方案
关于CICD,公司内部的平台有很多,权衡之下,最终选择了蓝盾。原因我个人认为有2个:一个是蓝盾强大的流水线编排能力,另一个就是蓝盾客服的贴心。下面主要是介绍知文NLP是如何结合蓝盾做CICD的。
知文NLP目前总共维护4套环境,zhiwen-release、zhiwen-beta、zhiwen-test、zhiwen-dev,分别对应API3.0的线上环境、预发布环境、测试环境以及开发环境。其中开发环境跟测试环境部署在测试集群,预发布环境跟线上环境部署在正式集群,同个集群不同的环境可以通过蓝盾的命名空间来隔离。4套环境在蓝盾上对应4套不同的流水线以及模版集,从而实现4套环境的隔离。同时基于蓝盾提供的流水线权限管理,目前我们的方案是dev环境的流水线由各个开发负责人去维护管理,而test、beta、release的流水线以及模板集会收拢权限,保证线上环境的稳定。
由于我们线上的算法微服务较多,所以如何灵活地进行服务部署是我们首要考虑的问题,其次就是如何让流水线根据版本号进行滚动升级,最后就是滚动升级的机制应该是怎么样的。下面一一阐述我们是如何解决上面这几个问题的。我们采用总控流水线来做服务部署,如图5所示。
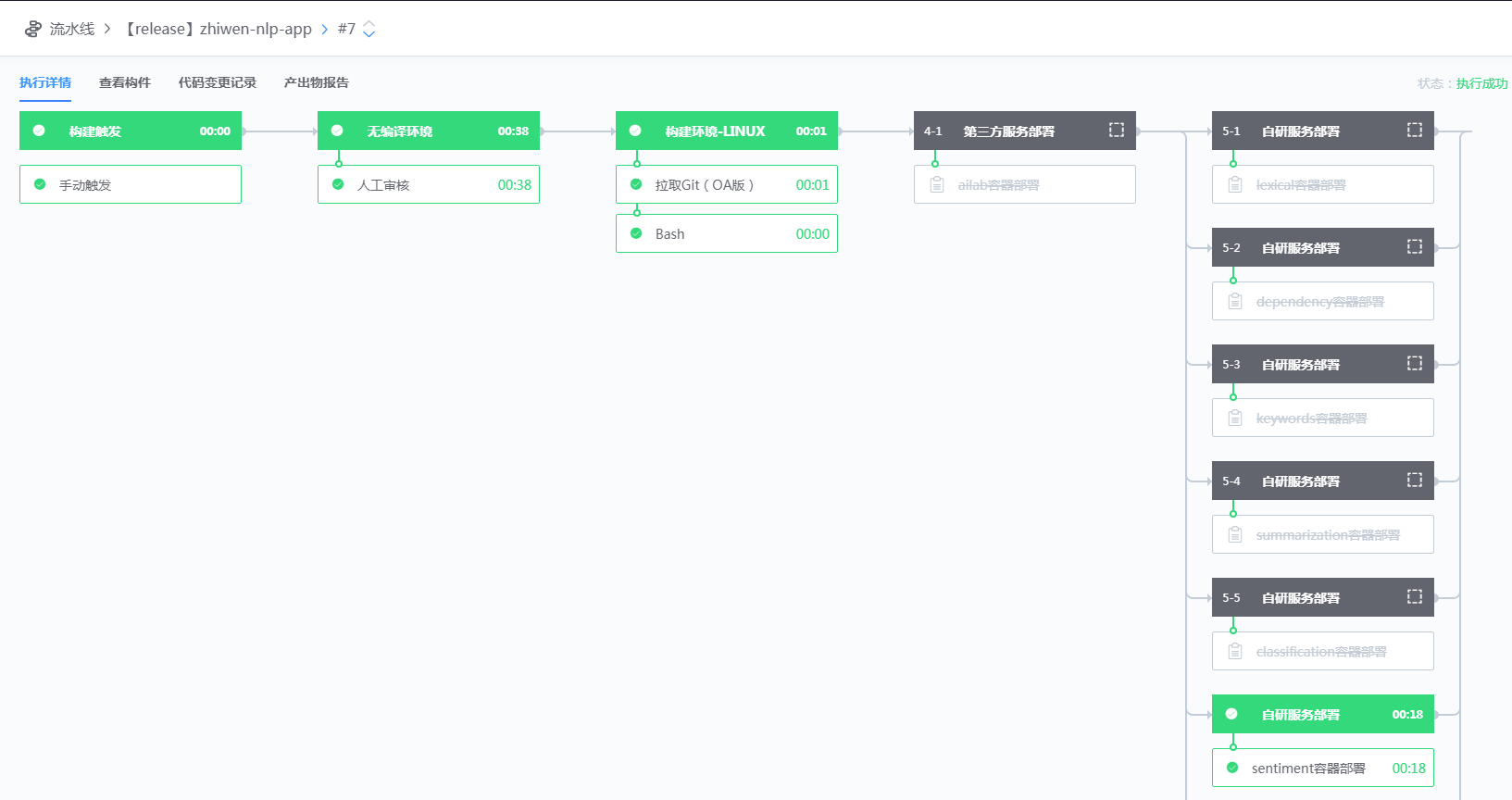
在我们的方案中,每一个微服务都是一条独立的流水线,但是每个微服务的流水线只负责CI部分,CD部分交给总控流水线来做。这样子就可以通过bash脚本来控制需要部署哪些微服务。简直就是一键点run,立马上线。蓝盾的滚动升级可以是模版集的滚动升级,也可以是版本号的滚动升级,我们采用的是后者,版本号采用“主版本号.特性版本号.修正版本号”格式,同样是通过bash脚本来更新镜像版本号以及线上服务的滚动升级,脚本可以参见如下。
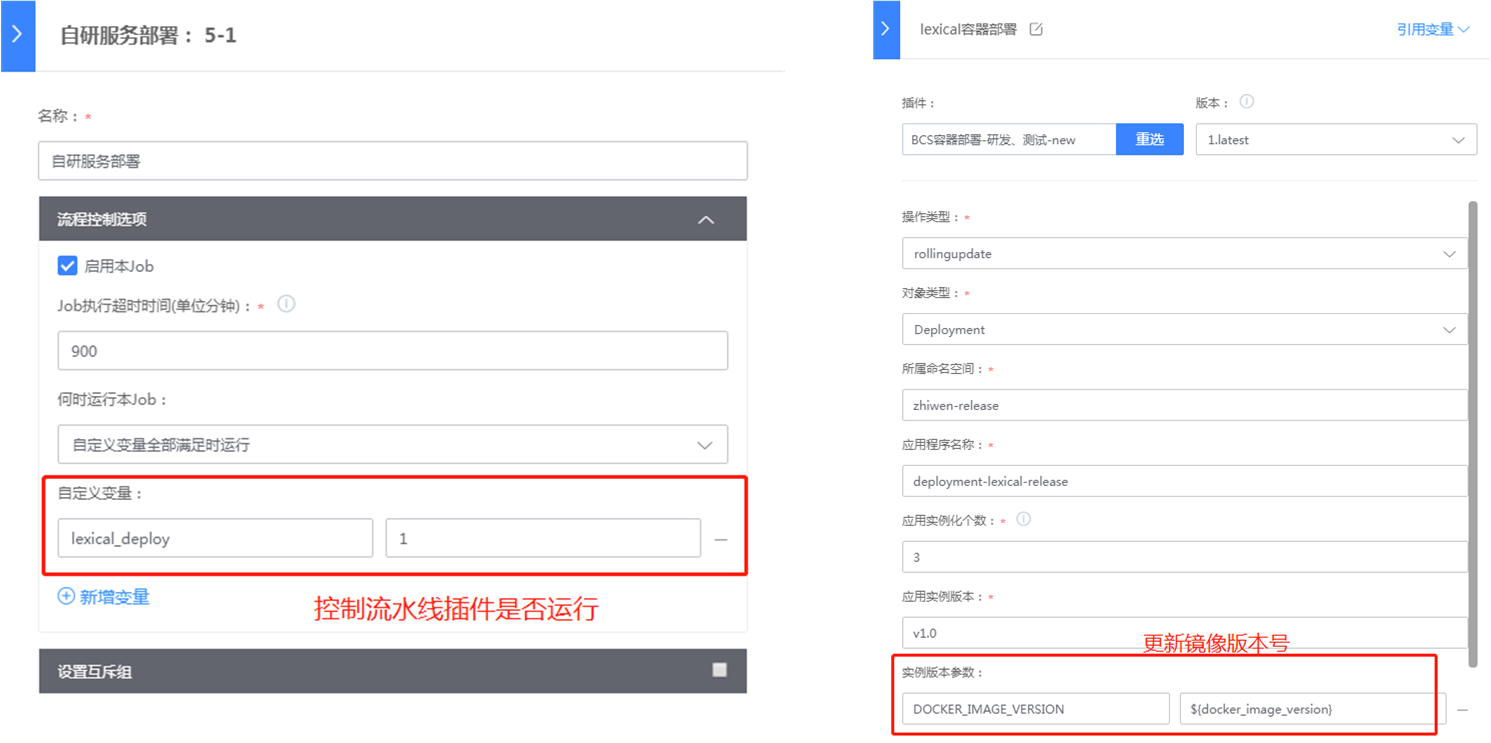
setEnv "docker_image_version" "$(cat zhiwen-nlp-version)"zhiwen_nlp_deploy=$(cat zhiwen-nlp-deploy)[[ $zhiwen_nlp_deploy =~ "lexical" ]] && setEnv "lexical_deploy" "1"[[ $zhiwen_nlp_deploy =~ "dependency" ]] && setEnv "dependency_deploy" "1"[[ $zhiwen_nlp_deploy =~ "keywords" ]] && setEnv "keywords_deploy" "1"[[ $zhiwen_nlp_deploy =~ "summarization" ]] && setEnv "summarization_deploy" "1"[[ $zhiwen_nlp_deploy =~ "classification" ]] && setEnv "classification_deploy" "1"[[ $zhiwen_nlp_deploy =~ "sentiment" ]] && setEnv "sentiment_deploy" "1"[[ $zhiwen_nlp_deploy =~ "vector" ]] && setEnv "vector_deploy" "1"[[ $zhiwen_nlp_deploy =~ "approval" ]] && setEnv "approval_deploy" "1"[[ $zhiwen_nlp_deploy =~ "sensitivewords" ]] && setEnv "sensitivewords_deploy" "1"[[ $zhiwen_nlp_deploy =~ "pinyin" ]] && setEnv "pinyin_deploy" "1"[[ $zhiwen_nlp_deploy =~ "correction" ]] && setEnv "correction_deploy" "1"[[ $zhiwen_nlp_deploy =~ "ailab" ]] && setEnv "ailab_deploy" "1"env | grep "_deploy"
主要是通过zhiwen-nlp-version以及zhiwen-nlp-deploy设置环境变量docker_image_version以及zhiwen_nlp_deploy。其中zhiwen_nlp_deploy是用来决定子流水线是否运行,而docker_image_version是用来更新版本号,从而实现滚动升级。如图6所示。这儿的docker_image_version是可以透传到模版集的,从而实现滚动升级。需要注意的是,对于bash插件,蓝盾默认会以最后一句的执行状态(返回0)作为该bash脚本是否成功执行的标志。
目前蓝盾的滚动升级是通过K8S的rollingupdate来实现的。对于我们的服务而言,滚动升级主要会面临两方面的问题:(1)新旧副本的更新机制;(2)旧副本的生命周期管理。这儿先简单介绍一下K8S的rollingupdate中两个比较重要的参数maxUnavailable、maxSurge,前者表示最大不可用实例个数,后者表示最大生成实例个数,假如某个微服务的实例个数为n,那么在滚动升级的过程中,实例存在个数的范围就是(n-maxUnavailable,n+maxSurge);举个例子,假如服务的实例个数为3个,maxUnavailable=1,maxSurge=0,那么在新旧副本替换时,最少可用实例个数就是2个,最多可用实例个数就是3个,所以其实rollingupdate的过程是会先stop掉一个旧的实例,然后起一个新的实例,等待新的实例可用之后,就stop下一个实例,依次类推,直到3个实例全部更新完成。而我们线上也是采用maxUnavailable=1,maxSurge=0这样的配置,主要的考虑是对于算法微服务而言,有的服务实例占用系统资源较大,maxSurge设置过大会有机器过载的风险,而maxUnavailable=1又能保证线上可用实例的个数,减少线上环境受影响。但maxSurge=0会有一个缺点,就是3个实例是串行更新的,也就意味着服务部署的时间会翻倍。相对服务受资源影响,这个属于可接受范围。对于实例的生命周期管理,主要需要考虑两个点:(1)对于新起实例,部分算法微服务启动时间较长,需要配置服务的就绪检查,以检测端口是否可用为标准;不然K8S会默认容器启动即可用,这样会导致新起的3个实例不可访问但旧的3个实例又被删除了的情况;(2)对于旧的实例副本,在被杀掉之前,需要sleep一段时间,也就是对pod配置prestop操作,让正在处理的请求能够正常返回后再杀掉,不然会出现部分请求失败的情况。
依托蓝盾的CICD,我们的服务可以快速进行迭代部署,然而作为算法微服务,还面临一个比较头疼的问题,也就是算法模型数据的加载,尤其是部分模型数据高达十几G,无法打进docker镜像,目前我们团队这边有两个方案:(1)依托蓝盾的文件分发机制;(2)cos数据管理;这儿主要考虑的问题是,模型数据是否应该跟着docker实例走?如果每个docker实例独享一份数据,就会导致资源消耗,如果共享一份数据,又会面临模型版本管理以及环境隔离的问题。这一块目前团队也还在调研解决中,期待读者们有好的解决方案可以share一下。
综上,通过蓝盾流水线强大的功能,我们的业务可以快速实现CICD、服务的弹性扩缩容、服务的蓝绿部署等,除此之外,通过插件“推送镜像到TKE(腾讯云版)”,我们还可以推送docker镜像到云仓库做私有化交付。
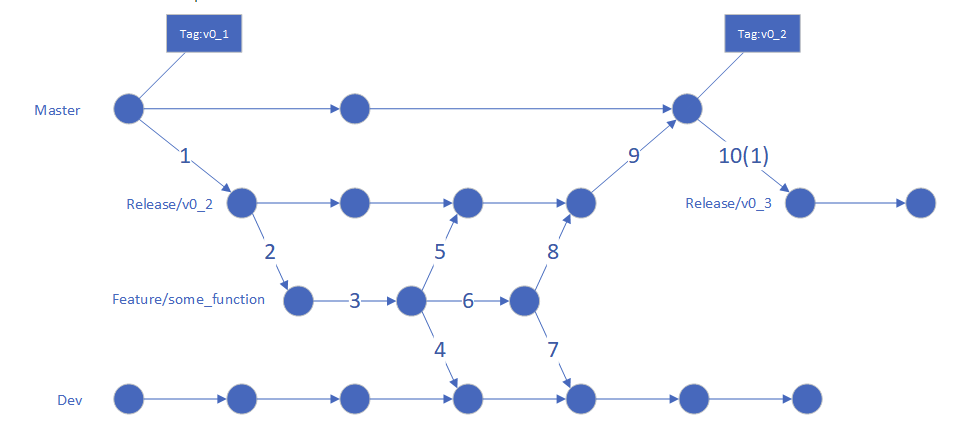
最后,也简单介绍一下开发过程中的代码管理规范,主要包括代码规范以及git管理规范。由于我们的代码迭代主要是java为主,可以通过阿里巴巴的ideal插件实现代码规范管理。至于git管理规范主要参考图7。总共有4个分支,分别是master、release、feature以及dev分支,其中master对应蓝盾的线上环境、预发布环境,release分支对应测试环境,feature跟dev对应开发环境,dev用于联调测试。一般的代码开发流程是:需求评审 —— 起feature分支开发测试 —— dev分支上联调测试 —— 提mr合并到release分支 —— 测试环境提测 —— 提mr合并到master分支 —— 预发布 —— 发布。
总结
本文主要是简单总结一下整个知文NLP平台在研发过程中的一些关键点,至于一些细节的地方,有兴趣的读者欢迎私聊。笔者也是从一个算法研究员逐步接触业务上云的研发流程,从中还有很多方案选择可能略显粗糙,还望各位读者指点。接下来我们也希望有更多的公司内外合作伙伴可以通过知文NLP平台这个出口,对外输出优秀的NLP技术!
