@yy125
2017-04-25T11:44:36.000000Z
字数 12972
阅读 175
60分钟搞定,基于ResNet和Azure GPU加速的肺癌CT图像识别
AI GPU
用深度学习技术分析医学影像和视频是一个新的研究方向。通过已训练好的卷积神经网络,能很快地搭建并训练自己的深度学习系统。 本文介绍了微软的一个比赛队伍参加2017年Kaggle肺癌CT图像检测比赛,成功地借用现成的152层ResNet网络,对接到分布式计算的神经网络上,在60分钟内完成训练。并获得了2017年Kaggle数据科学比赛里很好的名次。
该系统证明了在预先训练好的模型基础上(ImageNet ResNet-152)进行修改,用自己的数据继续更新权重,快速完成适合自己独特场景(肺癌检测)的可能性。同时,有具体实施细节和代码可供大家参考,来搭建自己的由CNTK,LightBGM,ResNet和GPU组成的深度学习系统。本文对卷积神经网络、提升树等技术的基本概念也进行了讲解,希望对刚接触AI的朋友有所帮助。
我们先从DICOM医学影像格式起,讲讲如何使用医疗影像数据,再介绍卷积神经网络(CNN)的基本概念和过程,最后讲讲前面提到的2017年Kaggle比赛里用CT图像检测肺癌的过程,如何用Resnet-152、LightGBM在Azure GPU虚机上,60分钟内完成肺癌检测模型训练和结果提交。
用Python进行图像处理的基础
用于图像处理的库有很多,其中OpenCV(Open computer vision)比较主流,有强大的社区支持,并支持C++,JAVA和python。
安装时,既可以用pip install opencv-python,也可以从opencv.org下载源码。

如果习惯用Jupyter notebook这种开源在线笔记的话,可以先打开Jupyter,导入cv2。要安装numpy和matplotlib,以便在Jupyter里查看绘制的图形。
import numpy as np;
import cv2;
import matplotlib.pyplot as plt
然后在Jupyter里打开图像:
#将彩色图片以灰度加载
img=cv2.imread('/user/img/dsc_0848.jpg')
plt.imshow(img)
plt.show()

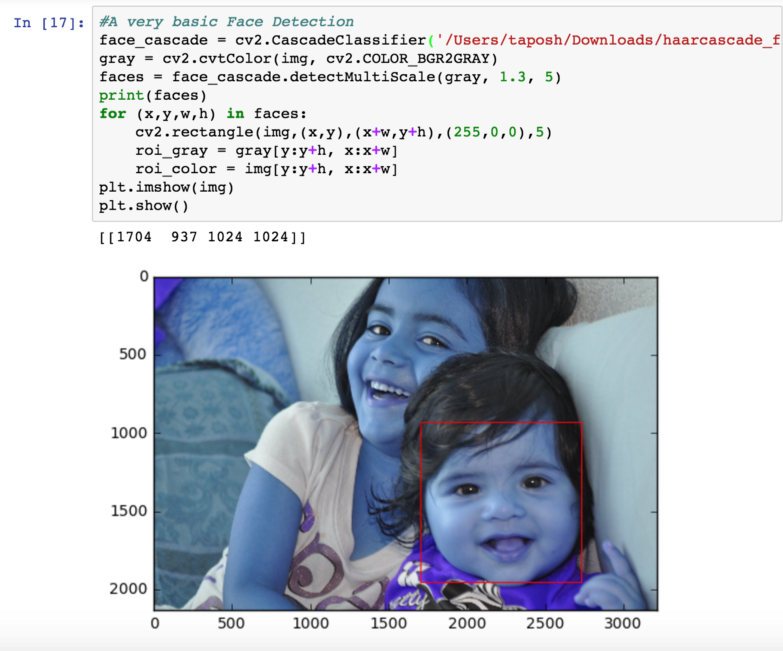
基本脸部识别
用开源的由Rainer Lienhart开发的ada正面脸部检测工具,可以小试一下脸部识别。Haar脸部级联检测的更多信息请见这里,也可以参考用OpenCV进行图像处理的例子。
医学影像数据格式
医学影像常常以DICOM标准进行存储和交换。该标准包括文件格式和通信协议。
- 文件格式:所有患者医疗图像都用DICOM格式保存。该格式包括患者健康隐私信息PHI(protected health information),比如姓名,性别,和其他与图像相关的数据,如采集该图像的设备和相关治疗信息。医学影像设备创建DICOM文件,医生用DICOM查看器——用来展示DICOM图像,并对图像内容进行读取和诊断的应用程序。
- 通信协议:用来搜索图像档案库。医学影像应用程序通过DICOM协议连到医院网络,并交换信息,主要是DICOM图像和小部分患者和治疗信息。更高级的网络命令可以控制和遵循治疗方案,安排治疗时间,汇报状态,和在医生和影像设备之间协调工作。
更多关于DICOM标准的内容,可以参见此博客。
分析DICOM图像
pydicom是个很好的python包,可用来分析DICOM图像。让我们看看如何在Jupyter notebook里渲染DICOM图片。
先安装pydicom:pip install pydicom,在Jupyter notebook里导入dicom之类的包:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import dicom as pdicom
import os
import glob
%matplotlib inline
也可以用pandas, scipy, skimage, mpl_toolkit等进行数据处理和分析。
#其他用来分析的包
import pandas as pd # 数据处理,CSV文件的输入输出
import scipy.ndimage
from skimage import measure, morphology
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
网上有很多免费的DICOM数据集,比较适合自己动手试验:
- Kaggle竞赛数据集: 很好用,比如肺癌检测竞赛和糖尿病视网膜病变。
- DICOM库:用于教学和科研的免费在线视频和图像。
- Osirix数据集:提供各种技术的人类影像数据集。
- Zubal Phantom两个男性的CT和MRI免费数据集。
下载数据,并在Jupyter里打开:
#下载DICOM图像
INPUT_FOLDER='user/img/Downloads/uncompressed/'
patients=os.listdir(INPUT_FOLDER)
#将DICOM图片加载到list里
lstFilesDCM=[]
def load_scan2(path):
for dirName,subdirList,fileList in os.walk(path):
for filename in fileList:
if ".dcm" in filename.lower():
lstFilesDCM.append(os.path.join(dirName,filename))
return lstFilesDCM
first_patient=load_scan2(INPUT_FOLDER)
第一步:在Jupyter里展示DICOM图像:
#加载第一个DICOM文件,获得ref文件。
RefDs=pdicom.read_file(lstFilesDCM[0])
#根据行、列和切片(沿z轴)的数量,对行数、列数和切片数赋值
ConstPixelDims=(int(RefDs.Rows),int(RefDs.Columns),len(lstFilesDCM))
#对沿X,Y,Z轴的间隔赋值(毫米)
ConstPixelSpacing=(float(RefDs.PixelSpacing[0],float(refDs.PixelSpacing[1],float(RefDs.SliceThickness))
再创建一个3D Numpy数组,并读入各个DICOM图像文件中的数据(灰度或RGB值)再用该Numpy数组实现图像分析、学习等步骤,具体步骤可参见下文的肺癌检测例子,或此处。
第二步:DICOM格式的细节
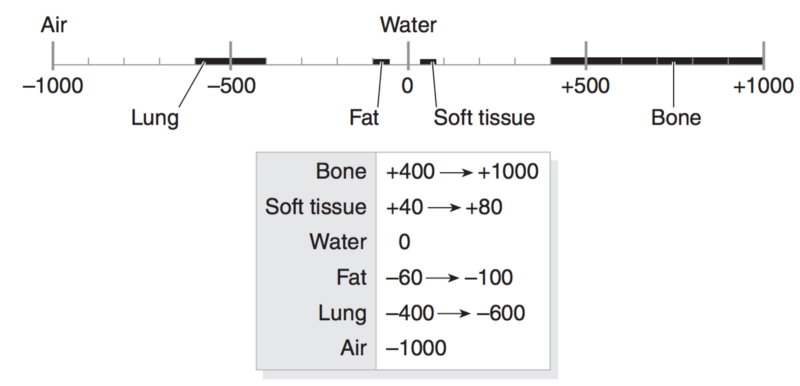
CT扫描的指标 单位是HU,记录放射密度。CT需要经仔细地校准,来准确地记录HU值。更进一步的信息可参考这里。
每个像素都被分配一个数值,即相应体素(Voxel)里所有衰减值的平均值。把它和水的衰减值相比,转化成一个任意单位的值,称之为HU值,因为它是以Sir Godfrey Hounsfield命名的。
水的HU值为0,CT值的范围是2000 HU,而有些现代CT机能达到4000 HU。每个值用一个灰度表示,1000是白色,-1000是黑色。
下面,我们先介绍一下卷积神经网络的基础,再讲讲如何用它来进行图像分析。
卷积神经网络基础
神经网络
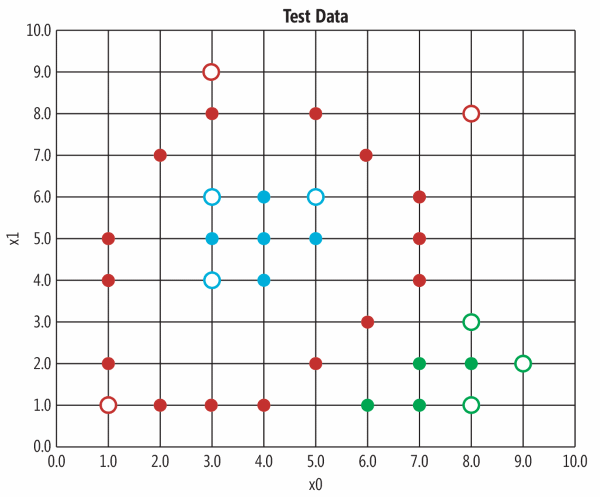
先借用CNTK的一个例子,来看看如何使用神经网络来进行分类。如果想根据一个人的年龄和年收入,对他的政治倾向进行分类(保守派,居中和自由派),怎么做呢?答案是通过已知值,建立并训练一个预测模型。该模型是某种函数,由两个输入产生一个结果,该结果能够解释他属于哪个政治派别。
 |
 |
|---|---|
| 训练和测试数据。输入值X1和X2分别代表年龄和收入,三个颜色的点代表政治倾向类型。实心点代表训练数据,空心点代表预测结果。本图源自MSDN的Machine Learning - Exploring the Microsoft CNTK Machine Learning Tool 一文。 | 基本的神经网络,本图源自MSDN的Machine Learning - Exploring the Microsoft CNTK Machine Learning Tool 一文。 |
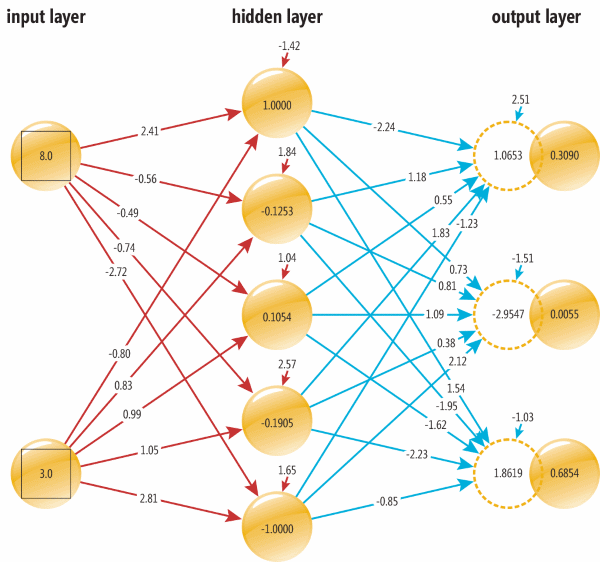
这就可以用一个简单的神经网络来解决:两个输入节点(input nodes,分别代表年龄和收入)和三个输出节点(output nodes分别代表三个政治倾向的概率)。输入(8.0, 3.0)时,输出(0.3090, 0.0055, 0.6854)。该网络还有5个隐藏节点(hidden nodes)。每个节点用从0开始的编号来代表,比如input[0]是最靠左上角的节点,output2是最右下角的。
中间的连线叫做权重(weights),比如,从input[0]到hidden[0]的权重为2.41。
计算隐藏节点的输出值时,先将每个输入的权重乘以所连的节点的值,将所有乘积叠加,并加上偏置量,再输入隐含节点的激活函数,即可得到输出。
常见的隐藏层激活函数包括tanh(双曲正切函数)、Sigmoid和ReLU。
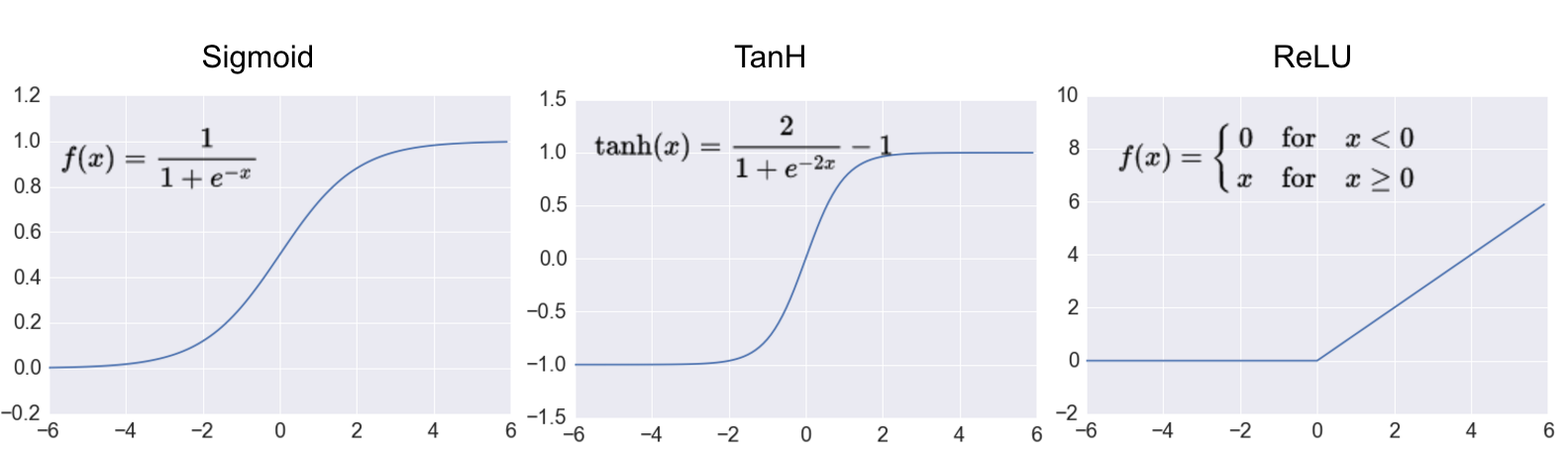 |
|---|
| 常见的激活函数:Sigmoid,双曲正切和ReLU,图片源于A Practical Introduction to Deep Learning with Caffe and Python 一文。 |
比如,图中隐含层第三个节点h[2]:
以此类推,可以算出所有隐藏层的输出。
最终输出和隐藏节点的算法类似,只是去掉了激活函数,比如output[0]:
我们希望得到不同结果的概率,因此将output输入到softmax函数,进行转换。
它会把一个由N个值组成的向量,“压”成另一个N个值的向量。每个结果都在(0,1)之间,且总和为1。同时,该函数能放大最大的值,让大值影响更大,并削弱较小的值的作用。因此,Softmax激活函数常用于神经网络的最后一层,用来得到概率。
以此类推: output[1]=0.0055, output[2]=0.6854。output[2]代表的概率最高,0.6854,因此对(8.0,3.0)的分类是“绿色”,即“自由派”。这些工作是由最后一层:全互联层(Fully Connected Layer)来完成。
用于图像识别的神经网络
图像由像素组成,彩色图像包括RGB(红绿蓝)分量,每个分量的轻重由灰度值表示。 因此,神经网络的输入是N维数组,长宽深,分别由RGB三个颜色分量组成。
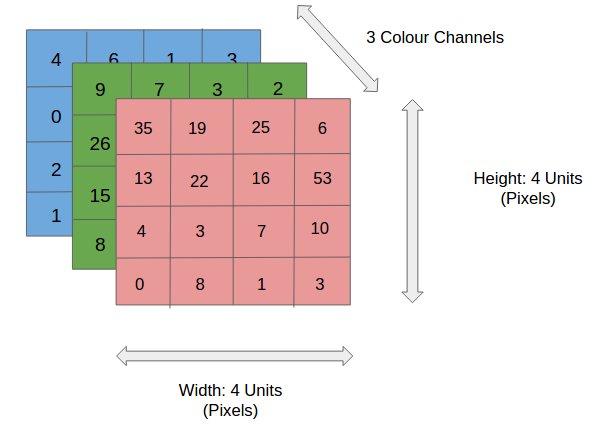 |
|---|
| 图片源于http://xrds.acm.org/blog/2016/06/convolutional-neural-networks-cnns-illustrated-explanation/ |
我们希望通过神经网络后,得到一组数字,来描述每种结果的可能性。对肺癌图像而言,我们希望得到“阴性”和“阳性”这两种情况的各自概率。
图像通过卷积神经网络的卷积层、激活层、池化层、批量归一化层和全互联层(Fully Connected Layer)将产生上述结果。
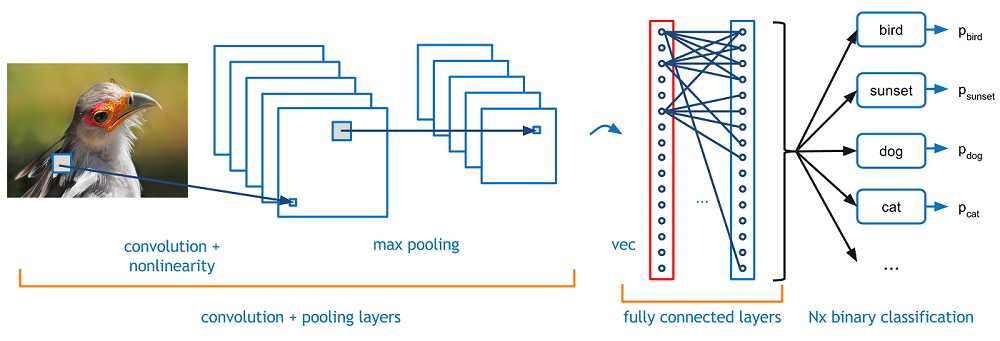 |
|---|
| 感谢*A beginner's guide to understanding convolutional Neural Networks*一文 |
实际上,不需要通过卷积,也可以实现图像识别——只需要用样本图像的二维数组+标签,训练神经网络,也可以产生一样的效果。数据量越大,效果越好。
为什么要在“神经网络”前加“卷积”?
答案很简单。如果要识别一个在图片里位置居中的手写的“8”,用神经网络+一张NVIDIA GTX 1080就可以搞定,无需卷积。然而,同样的“8”,如果位置不居中,在画面的左上角、右下角或缩小50%等等,神经网络都会认为是完全不同的“8”。如果训练数据没有类似的位置和大小,就无法准确识别。
因此,我们在神经网络之前,加了一个重要环节:特征提取。这就是卷积的重要功能之一:它将一个小过滤器(“神经元”或“卷积核”),比如图案“8”,一步步地平移扫描整个图像。无论“8”的位置是在左上角,还是右上角,它都能找出来。卷积的结果就是“特征”,一个数字组成的数组。
然后,再将特征数组,送到神经网络里,让神经网络对这个数组进行判断,而不是对图像本身判断,结果就好得多。
卷积神经网络
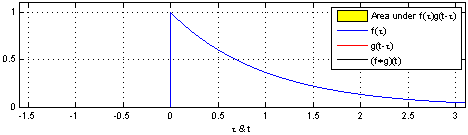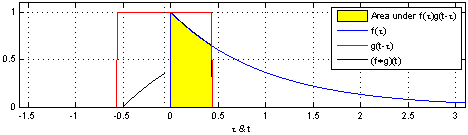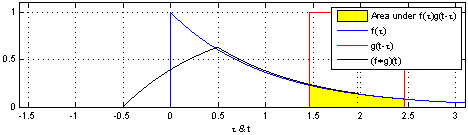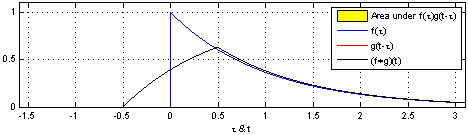
卷积是两个函数和的计算:将翻转平移,和相乘后,做积分。得到。
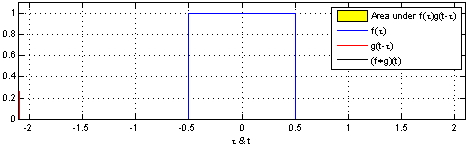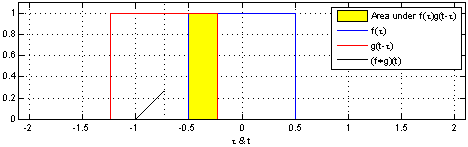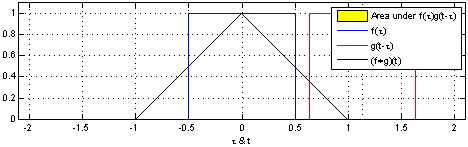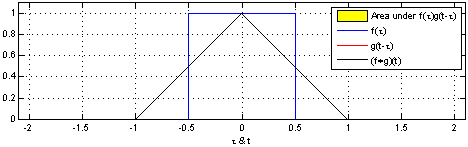 |
 |
|---|---|
| 两个方形脉冲的卷积。先对 反转,接着平移"t",成为。重叠部分的面积(黑色实线),即为"t"处的卷积。横坐标为 及的自变量"t"。 | 方形脉冲和指数衰退脉冲的卷积。重叠部分面积(黑色实线)即为处的卷积。 |
对于离散的矩阵A和B,卷积也是一样的:先将矩阵B翻转,再平移, 每个元素和矩阵A相应的位置的元素相乘后的总和,即得出该位置的卷积。
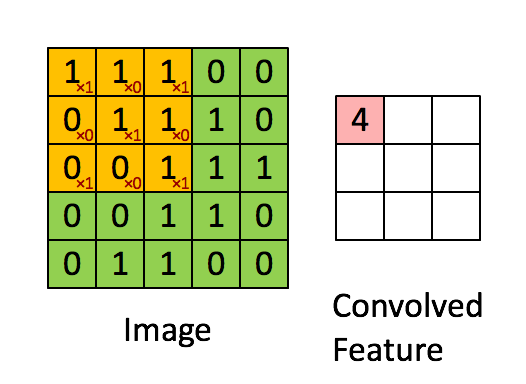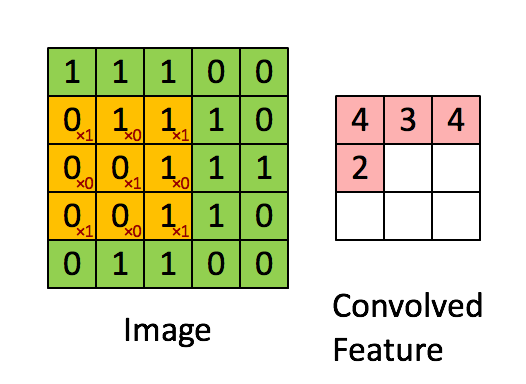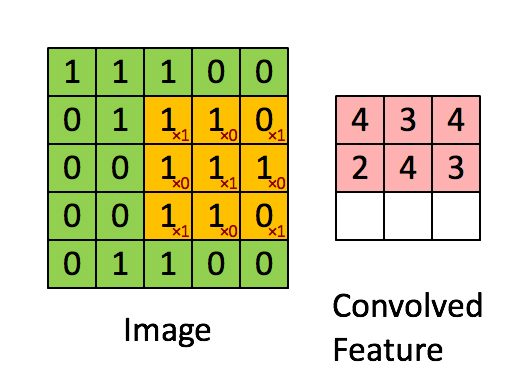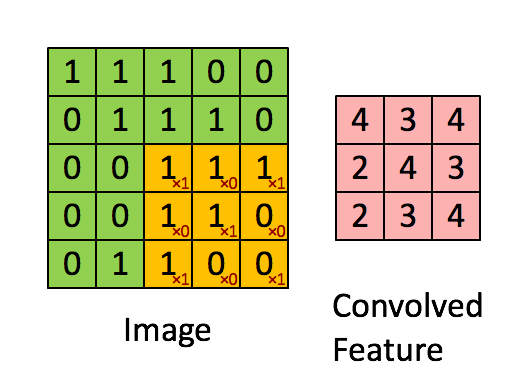 |
|---|
| 5x5的绿色矩阵A和3x3的矩阵B卷积,得出粉红色矩阵C。矩阵B每滑动一步,和矩阵A的[点积][14]就是该位置的卷积值。 |
如前所述,如果矩阵A是输入的图像。矩阵B是过滤器。通过卷积运算,能将各种图案特征分析出来,比如弧线、边缘、色块等等,得到一个较小的矩阵,叫做激活地图(activation map)。 举一个过滤器为例:
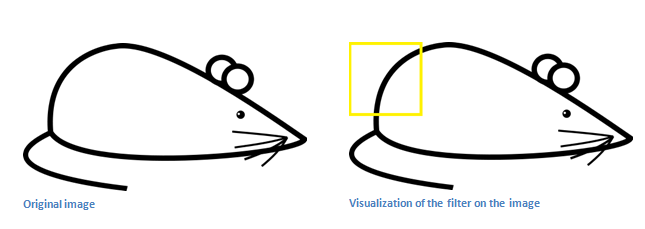 |
|---|
| 比如,要分析出一段长弧线,(本图来自A beginner's guide to understanding convolutional Neural Networks一文) |
| 用第一个矩阵是原图像,第二个矩阵为过滤器(或卷积核),两者卷积结果——激活地图上在弧线位置的值较大:6600,而在其他没有这样大弧线的位置,卷积值较小。(本图来自A beginner's guide to understanding convolutional Neural Networks一文) |
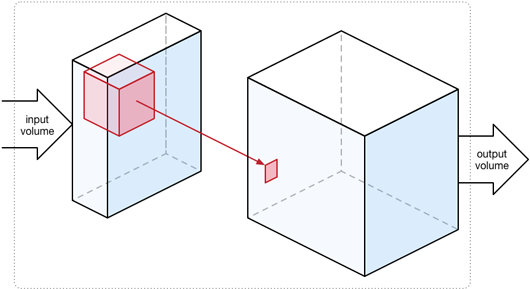
实际用于图像分析的卷积是三维的,请见下图。比如,彩色图像包括RGB三种色彩,因此,输入除了长、宽两个维度之外,还有厚度(“3”)。因此要检测某种图案特征,卷积核或过滤器实际上是三维的,如图中的粉红色方块。
这仅仅是一种图像特征的过滤器,而更多的特征还需要更多的过滤器。最终的激活地图是将多个过滤器的卷积结果沿厚度方向“叠”起来,因此用了多少个过滤器,其结果(激活地图)的“厚度”就是多少。
 |
|---|
| 由RGB三个颜色通道组成的三层图像(第一个浅蓝方块体),与粉红色的3维过滤器(厚度同样为3)卷积后,得到一个面。用96个不同的过滤器卷积,得到96层,即厚度为96。这96个过滤器分别检测不同特征。 |
那么这些过滤器里的值怎么确定,是按经验值或前人的试验来设定的吗? 不是,是机器自己“琢磨”出来的,换句话说,是神经网络训练出来的,过程如下,图片源于Machine Learning is Fun!:
 |
 |
|---|---|
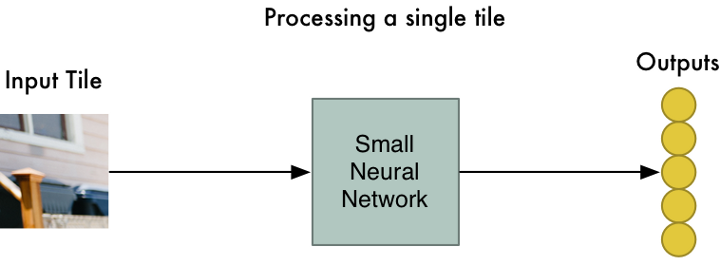
| 第一步:将整个图像分为N小块。每小块分为RGB三层,是个厚度为3的立方体。 | 第二步:每小块都接到同样的神经网络(过滤器,同样是3层)。 |
|
|
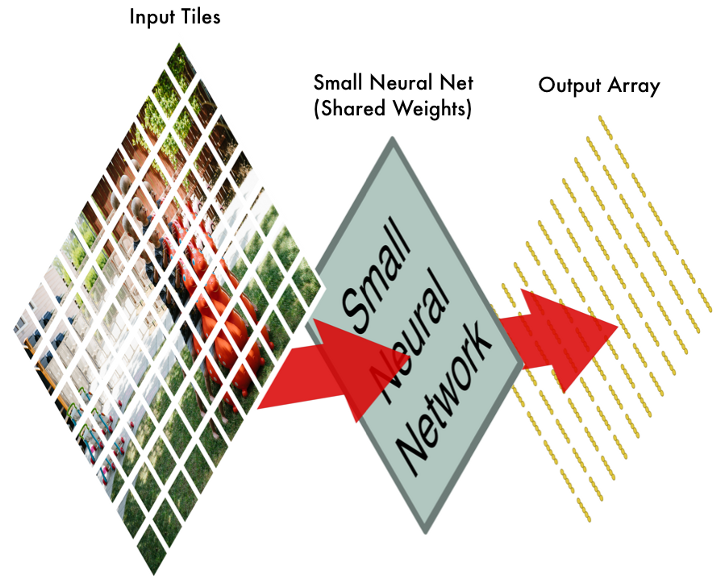
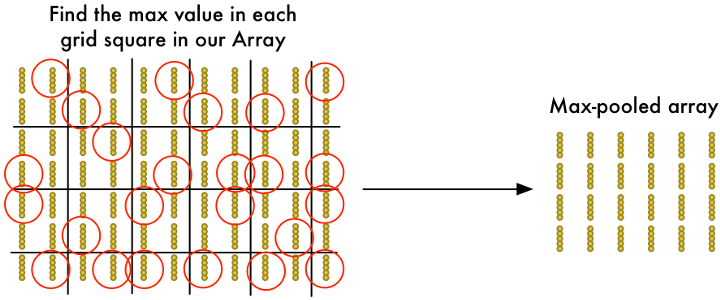
| 第三步:每小块的输出都按输入的位置,依次排列。并通过激活函数,比如用ReLU将负数变为零。对N种过滤器都重复此过程,形成厚度为N的结果集。 | 第四步:池化,将长宽变小,以便减少参数和计算量。比如每四个输出中,仅保留最大值。这些结果即是“特征”,同样,有N种过滤器,会形成厚度为N的结果集。 |
上图中第二步得到激活地图。通过激活层,比如用ReLU作为激活函数,将激活地图上所有负数将变为零,正数将不变。
再通过池化层,将特征地图的空间尺寸逐渐缩小,以便减少网络里的参数和计算量,并控制过拟合。池化层对输入矩阵沿厚度方向的每个切片进行操作,求最大值或平均值来调整其空间大小。
最常见一种池化层是用2x2的Max-Pooling过滤器。
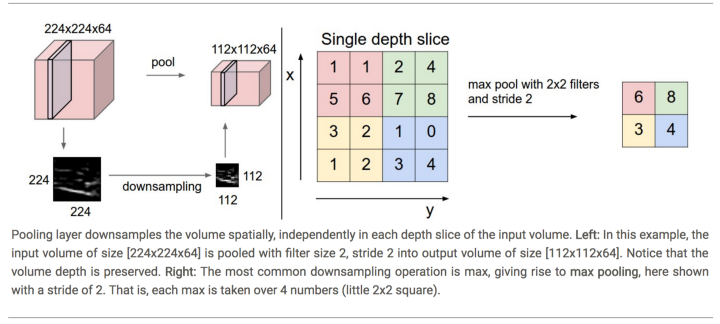 |
|---|
| 池化层在空间上缩减样本,在厚度方向保持不变。 左图:通过尺寸为2、步长为2的过滤器,将尺寸224x224x64缩减为112x112x64,而厚度方向尺寸不变。右图:最常用的缩减运算是“最大值”,即求出2x2格子(同样颜色)里的最大值,然后右移2格(步长为2)。 |
 |
|---|
| 第五步:将第四步输出的“特征”输入另一个神经网络,进行分类。该层叫做“全互联层”。 |

|
| 实际的神经网络会由多个卷积层和池化层组成。每个卷积层实际会用N个不同过滤器,得到N个结果,叠起来形成厚度N。比如第一层卷积会用96个检测不同特征的过滤器,因此厚度为96. 此例将224x224x3(RGB三色)的图像经过两次卷积+池化,再经过3次卷积,一次池化,和两个全互联层(即dense layer),得到最终的1000种分类。 |
一个卷积神经网络里,可以由多个卷积层和池化层组成。每层如何决定权重,完全由训练产生,没有人工干预。不过,有人逐层分析已经训练好的神经网络,发现前面的卷积层寻找的是简单的特征,比如边缘或曲线。而后面的卷积层寻找的是人脸、皱纹等更高级的特征。
最后,将后面得到的高级特征,输入另一个全互联神经网络层和SoftMax函数,即可获得一组输出值:比如每种分类标签的概率。
后面的肺癌CT识别的案例里,正是借用了ImageNet用来进行图像分类的ResNet-157模型,将全互联层的输入,转接到LightGBM。利用已训练好的ResNet-157计算CT图像的特征值,并用这些特征值和标签训练LightGBM的神经网络,并实现对肺癌CT的识别。
训练神经网络
前面提到,所有过滤器的值都是通过训练获得,哪些是肺癌的特征?是机器自己“琢磨”出来的,那么,到底是怎么算出来的呢? 答案是,通过用一组已知的图片和各自对应的标签(Label)来训练神经网络。 训练过程将逐渐调整各个过滤器的每个值(或权重),也称之为反向传播(Back propogation)。反向传播包括四个计算步骤:前向传导(forward pass)、损失函数(loss function)、后向传导(backward pass)和权重更新(weight update)。
先将所有过滤器和权重设为任意数。前向传导是将样本图像输入神经网络,按上面提到的办法计算得到输出。因为在训练阶段知道正确的样本图像分类结果,所以可以算出计算结果和正确结果之间的差距,记为“L”,比如用均方差MSE作为L,这就是一种损失函数。
可以想象,第一次用任意数初始化,得到的L会很大,要逐渐减小L,需要先找到不同权重"W"对L的影响,即求。结果越大,代表影响越大,调整也应该越大;结果为零,则代表该权重对L没影响,无需调整。后向传导就是求。
之后,再将第一轮的权重更新成新的权重:
其中,是学习速度(learning rate),是新的权重,是前一轮的权重。由用户自己选择,值越高,则每次变化越大,有可能更快地得到最优结果,但如果过大,也可能得不到最佳结果。
整个反向传播的过程,包括上述四个部分,称作一个“循环(epoch)"。为了利用并行计算来缩短时间,并能更顺利地收敛,先将每n个训练样本编成一个“小批次”(mini-batch),对每个小批次反复epoch循环中的4个步骤,并更新权重,直到最后的m次循环的得分不再提升时结束。下面肺癌的例子中,对lightGBM回归树训练的“early_stop_ping_round=300”,即m=300。
注意,每次更新权重时,{同一个小批里n个训练样本的的平均值}。有时候用完样本数据后,得分可能还是不收敛,就要将样本数据重新排序(shuffle),取另一套测试数据,继续训练。
防止过拟合
如何避免过拟合是机器学习里非常重要的考虑因素。如果权重和偏置量(Bias)过于“贴近”训练数据,很可能造成模型对新数据不够适应,实际运用时产生很糟糕的效果。更确切地说,如果训练所用的数据少,又追求尽可能拟合绝大多数数据,那么很可能拟合了训练数据里的“噪音”或异常值,弄得模型敏感而复杂,因此,最糟糕的训练是仅用一套数据训练所有节点。后面提到的Early_stop_ping_round,L1和L2,交叉验证,及剔除(Dropout)都是避免过拟合的措施。
剔除(Dropout)
剔除能够在训练阶段快速检验是否过拟合。如果模型没有问题,那么将神经网络里的部分节点去掉,也应该产生正确的结果。
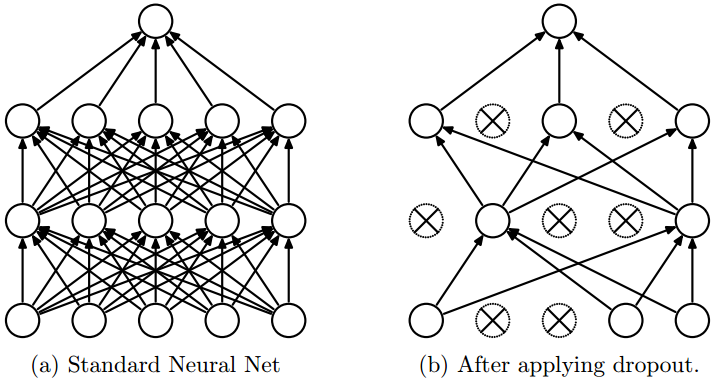 |
|---|
| 神经网络的剔除 左图:带有两个隐藏层的神经网络; 右图:经过剔除的一个子网络。叉代表被剔除的隐藏和输入节点; 图片源于Dropout: A Simple Way to Prevent Neural Network from Overfitting。 |
采用剔除时,每个子网络的每个输入节点和隐藏节点是否出现,由概率p随机决定连接。被剔除的节点权重也剔除掉,如上图的右图(b)所示。一般来说,将保留大部分输入节点和部分隐藏节点(比如50%)。
举一篇关于剔除的经典论文Dropout: A Simple Way to Prevent Neural Network from Overfitting里所采用的的剔除为例:未使用剔除时,训练过程的每个小批次(mini-batch)里的n个图像样本所训练的都是同样的一个网络,如上图(a)。而采用剔除时,每个训练样本都对应一个不同的经随机剔除的子网络,如上图(b)。因此,每个小批次中的n个图像样本,将分别对应n个子网络,而每次epoch循环更新权重w时,用的是n个的平均值。
验证时,不再剔除,而是用完整的网络,每个权重等于训练结果中的权重与相应概率的乘积,即训练权重w),如下图。
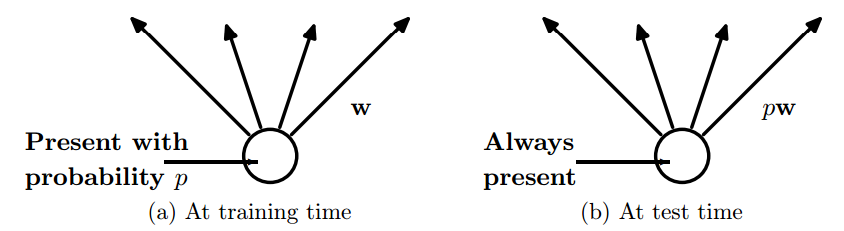 |
|---|
| 从训练到最终的网络 左图:在训练阶段,每个输入和隐藏节点存在的概率为p,和下层网络的连接权重为w; 右图:在验证阶段,每个节点都保留,权重是p和w的乘积,模型的输出是训练阶段所有输出的期望值; 图片源于Dropout: A Simple Way to Prevent Neural Network from Overfitting。 |
交叉验证
如何保证模型在新的数据下,仍有较好表现?一般会将所有样本数据的一部分预留起来,用剩下的训练模型。等训练结束后,再用预留的数据验证,看真实效果如何。这是避免过拟合的重要措施。
但,这样做,使得用于训练模型的数据少了,且选择哪部分数据用于训练,哪部分用于验证,也可能影响效果。交叉验证是个解决方案。比如以K折交叉(K-fold cross validation)验证为例:将样本数据分成K份,先选一份(A)作为验证数据,预留起来。用剩下的K-1份训练网络,再用预留的那份(A)做验证。
然后,再另选一份作为验证数据(B),同样重复上述步骤,用剩下的K-1份训练,并用B做验证。以此类推,K次之后,所有的数据都做过验证数据。最终的验证得分是K次验证得分的平均。
用scikit-learn的train_test_split函数可以很容易地按某个百分比,将数据拆分成训练和验证的两部分。用cross_val_score(clf,x_data,y_label,cv=num_K_fold)可以很容易地用设置好的分类器clf,进行折数为num_K_fold的K折交叉验证。
肺癌CT影像识别
微软的Miguel Fierro, Ye Xing, Tao Wu等人在2017年1月Kaggle上的“数据科学肺癌检测竞赛”里,在60分钟内,利用已训练好的卷积神经网络ResNet-157提取CT图像的特征,并训练提升树(boosted tree),以识别肺癌CT影像是癌症阴性或阳性。他们获得了不错的成绩——1月19日之前排名位前10%,2月7日之前,居前20%。
所用到的工具包括:
1. 特征提取:已训练好的卷积神经网络——一个用CNTK开发的152层ResNet模型,用ImageNet的图像数据集进行的训练;
2. 图像分类:LightGBM灰度提升框架;
3. 带GPU加速的Azure虚机;
具体代码请见Jupyter notebook里的笔记。用CNTK和ResNet-157计算特征用了53分钟(如果用更简单的18层ResNet模型,需29分钟),训练LightGBM用了6分钟。代码请见Kaggle。
训练速度对获奖来说非常重要。CNTK和LightGBM,加上Azure的高性能GPU虚机,为他们按需提供高性能计算环境,效果很好。下面,我们具体看看他们怎么做的。
用ResNet模型、CNTK和LightGBM实施图像识别
深度学习的一种较新的办法是用已训练好的卷积神经网络作为基础,利用已经训练好的模型、权重来加快速度。这也是该团队所采用的方法。他们用ImageNet已训练好的卷积神经网络ResNet-152作为基础,来提取图像特征,然后将特征输入LightGBM灰度提升树框架(包括了GBDT,GBRT,GBM,MART等),来进行训练和分类。
该模型的前面几层会提取基本的特征,比如色块、弧线等。后面的层会识别更高层次的特征,比如结节等,更后面的层再进一步识别更复杂的特征,比如和恶性结节等肺癌特征更加贴近的特征。
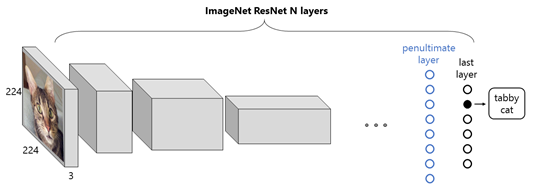
让我们先看看ImageNet如何用卷积神经网络进行图像分类,见上图。输入是224x224的彩色图像,每个图像包括RGB三个色彩分量,记为224x224x3。每个卷积层进行卷积计算,用多个厚度为3的过滤器,提取各种图像特征,因此,每层的输出的厚度随着过滤器的数量增加而变厚。
最后,由池化+SoftMax函数组成的分类器将输出一组由1000种概率组成的向量(最后的一组黑色小圈),对应于ImageNet的1000种不同图像分类。该概率向量中,哪个分类的概率最高,就是识别结果。比如上图中用猫照片输入ResNet,经过每层卷积计算后,图片大小变小,厚度增加,直到最后的判断结果,即图中第二个小黑点的概率值最高,即识别结果:“虎斑猫”。
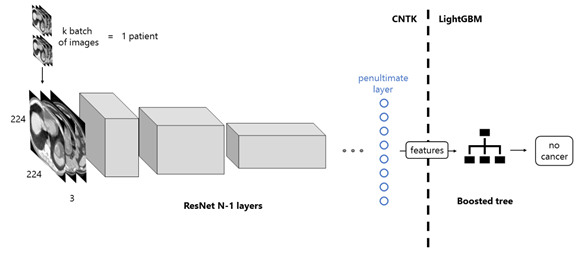 |
|---|
| 用已训练好的ImageNet的ResNet-152模型输出特征,输入到LightGBM中进行分类。 |
为了借用ImageNet的特征提取,来实现肺癌图像分类,先将由池化+SoftMax函数组成的分类器去掉,而将图中的"penultimate layer"的节点的输出作为LightGBM分类器的输入。 同时,每个患者的CT套图是黑白的,所以要先像ImageNet的RBG样本那样,裁切到224x224大小,三张一组。分成K批输入前面提到的已训练的神经网络,计算到“pentimate layer”为止。该过程用CNTK执行。将输出结果输入灰度提升树,用LightGBM分类。
LightGBM是微软DMTK框架的一部分,将灰度提升树用于分布式集群上,以达到更快的速度,而且随着节点数增加,可以成比例地提高计算性能。据好事者测,比XGBoost快10倍,内存使用稍微少些。作为微软AI的两大利器,DMTK(Distributed Machine Learning Toolkit)主要优势是分布式,而非深度学习。CNTK的优势在于深度学习,所以这两种常常一起用。
ResNet
为什么要用ImageNet的ResNet-152模型? ResNet是微软亚洲研究院Kaiming He等人提出的。传统神经网络层数较多时,优化比较困难,因此拟合不够。而且如果仅仅增加层数,得到的训练误差和实验误差可能更高。而ResNet收敛更快,更容易训练,层数也可以更多,误差更低。比如,在2015年ResNet一战成名的ILSVRC比赛中,它囊括ImageNet和COCO的图像分类、物体检测等五项比赛冠军。2014年冠军用的是GoogleNet的22层网络,而2015年的冠军ResNet有152层,将图像分类的误差从6.7%缩减到3.57%,而物体检测mAP指标从2014年16层VGG的66%,提升到101层ResNet的86%。下图是2016年10月25日为止,由Eugenio Culurciello发表的,对AlexNet, VGG和ResNet的比较。
 |
|---|
| 感谢[Eugenio Culurciello][33] |
步骤
具体安装和运行方法,请见Cortana Intelligence的笔记,大概分为以下步骤:
1. 安装以下内容:CUDA 8.0 RC1, cuDNN 5.1, Anaconda 4.2.0, OpenCV, Scikit-learn 0.18, CNTK 2.0beta9 (并打开1-bit SQG, 在多服务器多GPU上更快), LightGBM 已训练的ResNet的CNTK模型;
2. 下载DICOM数据,最大文件67GB,解压后141GB;
3. 用Python加载库,设置路径和参数;
4. 用get_3d_data将某患者的所有CT切片读入一个numpy数组。因为卷积神经网络是用ImageNet的彩色图像进行训练的,所以要把样本按ImageNet的彩色图像进行规范——用get_data_id将该患者所有CT切片的对比度归一化,均衡直方图,再将每三张灰度图编为一组,来替代ImageNet彩图的RGB三分量,将每张灰度图的大小修改为224x224。
5. 加载ImageNet模型,选取分类之前的一层节点(“Penultimate”层,在CNTK中叫做“z.x”)的输出"net"作为特征值(feature),。
6. 计算每个患者的CT切片的特征值,并存成二进制文件.npy。具体来说,用已经训练好的ResNet-152模型,直接进行前向传导(Forward Pass),而无需计算导数或更新ResNet-152模型的权重。因此,将第4步中每个患者的CT切片图像,每三张一组("batch"或前文提到的"mini-batch")计算特征(net.eval(batch)),并将结果存入该患者的.npy文件。
7. 用特征+标签来训练LightGBM,对LightGBM的回归器(Regressor)进行拟合。具体来说,每个患者都对应一个标签,“阳性”或“阴性”。先将该患者的每组(batch)三张切片的特征值的平均,作为该组的特征,再将该患者所有切片组(batch)的特征结果扁平化,形成一维numpy向量X,并对应相应的标签Y(阴性或阳性)。
8. 按交叉验证的办法,将X和Y分为训练组和验证组。再用LGBMRegressor创建分类器,用fit函数进行拟合。优化指标可以有多种选择,本例里,多次尝试下来用L2效果更好。将提前退出次数Early_stop_ping_round设为300次,模型训练到最近300次的L2指标不再改善时,即结束训练。
9. 用训练好的模型对图像样本进行预测。
 |
|---|
| 第8步:训练LightGBM的回归器时,提前退出次数early_stop_ping_round设为300,因此当L2指标在最近的300次迭代后不再改善时,即结束训练。[39] |
这个例子比较典型地展示了用卷积神经网络实现医学图像自动检测的方法。 用Azure的GPU虚机,和CNTK技术,快速地搭建并完成训练,其速度之快让人刮目相看。既反映了微软在人工智能和云计算的技术实力,又显示了ResNet的优势。对于刚开始接触深度学习和卷积神经网络的朋友来说,是个难得的可以自己动手的机会。
