@yy125
2017-04-08T10:37:59.000000Z
字数 5970
阅读 259
哪些GPU更适合深度学习和数据库?
并行开发 AI
前言
GPU和人工智能越来越火,引起了大批投资者和开发者的注意。百度前首席科学家Andrew Ng提到,人工智能的春天已经到来,其重要因素之一是GPU处理能力,能让神经网络的智能可以随数据增加而继续提升,突破了过去的人工智能所能达到的平台,训练饱和极限(智力容量)大大上移。
最近Google在ISCA2017上披露了TPU(Tensor Processing Unit)的细节,继Haswell CPU, Tesla K80GPU之后,又增加了一种专门用于机器学习和神经网络的高性能武器。因此,我想借Tim Dettmers的博客《哪种GPU适合Deep learning:我的经验和建议》来介绍一下GPU的选择。
最开始读到他的文章,是为了找如何用多GPU集群处理大表JOIN偶然遇到的。他分享的内容很适合刚开始涉入GPU开发领域的朋友参考,比如参加Kaggle比赛,用多套数据并行运行于同一个模型,或者用同一套数据并行运行于多个不同模型等。其正文后面的讨论也有很多干货。
数据分析和GPU
GPU不仅能实现数据库的许多功能,而且其强大的计算能力,能实现实时 分析。MapD和Kinetica是这方面比较有名的两家公司。MapD用NVIDIA Tesla K40/K80实现了基于SQL和列式存储的数据库,无需索引,擅长任意多组合的条件查询(Where)、聚合(Groupby)等,实现传统关系型数据库的BI功能,方便用户自由地进行多条件查询。性能优势也很明显(尤其是响应时间)。
比如,MapD将1987-2008年全美国进出港航班的数据扩大10倍后,执行全表扫描的报表任务,如"SELECT ... GROUP BY ...”。一台带有8张Tesla K40显卡的服务器(8核/384G RAM/SSD)比3台服务器(32核/244G RAM/SSD)组成的内存数据库集群快50-100倍(请参见MapD技术白皮书 MapD Technical Whitepaper Summer 2016)。
GPU数据库的另一大特色是可视化渲染和绘制。将OpenGL等的 缓冲区直接映射成GPU CUDA里的显存空间,原地渲染,无需将结果从内存拷到GPU,可以实现高帧频的动画。也可以原地绘制成PNG或视频stream,再发给客户端,大大减少网络传输的数据量。这些优势吸引了很多开发者。
在实时分析上比较有名的一家公司是Kinetica。他们开始时为美国情报机构实时分析250个数据流。现在能用10个节点,基于20万个传感器,为美国邮政服务(USPS)提供15000个并行的实时分析、物流路由计算和调度等。
我国用GPU进行分析和挖掘的用户也越来越多,想深入学习的朋友也不少。最快速的入门办法是重复前人的实验。弗吉尼亚大学的Accelerating SQL Database Operations on a GPU with CUDA里的开发环境和实验,值得借鉴。他们用一张4G显存的NVIDIA Tesla C1060, 在一台低配的服务器上(Xeon X5550(2.66GHz/4核),5G RAM),用5百万行的表做查询和汇总,响应时间30-60毫秒。
我们测过的最低配置是NVidia GTX 780,一千多块,适合用来尝试查询和聚合。先用SQLite将SQL解析成多个OpCode步骤, 然后在CUDA上实现一个虚机,来逐一实现每个步骤,直至将整个表逐行遍历完。其中一些步骤可以并行,因此可用CUDA起几万个线程,每个线程处理一行。
深度学习和GPU
深度需要较高的计算能力,所以对GPU的选择会极大地影响使用者体验。在GPU出现之前,一个实验可能需要等几个月,或者跑了一天才发现某个试验的参数不好。好的GPU可以在深度学习网络上快速迭代,几天跑完几个月的试验,或者几小时代替几天,几分钟代替几小时。
快速的GPU可以帮助刚开始学习的朋友快速地积累实践经验,并用深度学习解决实际问题。如果不能快速得到结果,不能快速地从失误中汲取教训,学起来会比较让人灰心。Tim Dettmers利用GPU,在一系列Kaggle比赛里应用了deep learning,并在Partly Sunny with a chance of Hashtags比赛中获了亚军。他用了两个较大的两层深度神经网络,采用了ReLU激活函数,用Dropout来实现正则化(避免过拟合)。这个网络勉强能加载到6GB的GPU显存里。
是否需要多个GPU?
Tim曾用40G bit/s的InfiniBand搭建了一个小GPU集群,但他发现很难在多个GPU上实现并行的神经网络,而且在密集的神经网络上,速度提升也不明显。小网络可以通过数据并行更有效地并行,但对比赛里所用的这个大网络,几乎没有提速。
后来又开发了一个8-bit压缩方法,按理说,能比32-bit更有效地并行处理密集或全互联的网络层。但是结果也不理想。即使对并行算法进行优化,自己专门写代码在多颗GPU上并行执行,效果和付出的努力相比仍然得不偿失。要非常了解深度学习算法和硬件之间具体如何互动,才能判断是否能从并行里真的得到好处。

图1. 3套GXT Titan GPU卡和一张InfiniBand卡,是好的deep learning配置吗?
对GPU的并行支持越来越常见,但还远未普及,效果也未必很好。仅有CNTK这一种深度学习库通过Microsoft特殊的 1-bit量化并行算法(效率较高)和块动量算法(效率很高),能在多个GPU和多台计算机上高效地执行算法。(参见CNTK Parallel 1-bit SGD,需要安装微软MPI或OpenMPI。)
在96颗GPU的集群上用CNTK,可以获得90-95倍的速度提升。下一个能高效地多机并行的库可能是Pytorch,但还没完全做好。如果想在单机上并行,可以用CNTK,Torch或Pytorch。速度可提升3.6-3.8倍。这些库包含了一些算法,能在4颗GPU的单机上并行执行。 其他支持并行的库,要么慢(比如TensorFlow能加速2-3倍),要么在多GPU上不好用(比如Theano),要么这两个问题都有。
如果并行很重要,那可以用Python或CNTK。
多GPU,非并行
用多个GPU的另一个好处是,即使不并行执行算法,也可以在每个GPU上分别运行多个算法或实验。虽然不能提速,但可以一次性了解多个算法或参数的性能。当科研人员需要尽快地积累深度学习经验,尝试一个算法的不同版本时,这很有用。
这对深度学习的过程也很有好处。任务执行得越快,越能更快地得到反馈,脑子就从这些记忆片段里总结出完整的结论。在不同的GPU上用小数据集训练两个卷积网络,可以更快地摸索到如何能执行得更好。也能更顺地找到交叉验证误差(Cross validation error)的规律,并正确地解读它们。还能发现某种规律,来找到需要增加、移除或调整的参数或层。
总的来说,单GPU几乎对所有的任务都够了,不过用多个GPU来加速深度学习模型变得越来越重要。多颗便宜的GPU也能用来更快地学习深度学习。因此,建议用多个小GPU,而不是一个大的。
选哪种? NVIDIA GPU,AMD GPU还是Intel Xeon Phi?
用NVIDIA的标准库很容易搭建起CUDA的深度学习库,而AMD的OpenCL的标准库没这么强大。而且CUDA的GPU计算或通用GPU社区很大,而OpenCL的社区较小。从CUDA社区找到好的开源办法和可靠的编程建议更方便。
而且,NVIDIA从深度学习的起步时就开始投入,回报颇丰。虽然别的公司现在也对深度学习投入资金和精力,但起步较晚,落后较多。如果在深度学习上采用NVIDIA-CUDA之外的其他软硬件,会走弯路。
据称,Intel的Xeon Phi上支持标准C代码,而且要在Xeon Phi上加速,也很容易修改这些代码。这个功能听起来有意思。但实际上只支持很少一部分C代码,并不实用。即使支持,执行起来也很慢。Tim曾用过500颗Xeon Phi的集群,遇到一个接一个的坑,比如Xeon Phi MKL和Python Numpy不兼容,所以没法做单元测试。因为Intel Xeon Phi编译器无法正确地对模板进行代码精简,比如对switch语句,很大一部分代码需要重构。因为Xeon Phi编译器不支持一些C++11功能,所以要修改程序的C接口。既麻烦,又花时间,让人抓狂。
执行也很慢。当tensor大小连续变化时,不知道是bug,还是线程调度影响了性能。举个例子,如果全连接层(FC)或剔除层(Dropout)的大小不一样,Xeon Phi比CPU慢。
预算内的最快GPU
结论
用于深度学习的GPU的高速取决于什么? 是CUDA核? 时钟速度?还是RAM大小?这些都不是。影响深度学习性能的最重要的因素是显存带宽。
GPU的显存带宽经过优化,而牺牲了访问时间(延迟)。CPU恰恰相反,所用内存较小的计算速度快,比如几个数的乘法(3*6*9);所用内存较大的计算慢,比如矩阵乘法(A*B*C)。 GPU凭借其显存带宽,擅长解决需要大内存的问题。当然,GPU和CPU之间还有更复杂的区别,可以参见Tim在Quora上的回答。
所以,购买快速GPU的时候,先看看带宽。
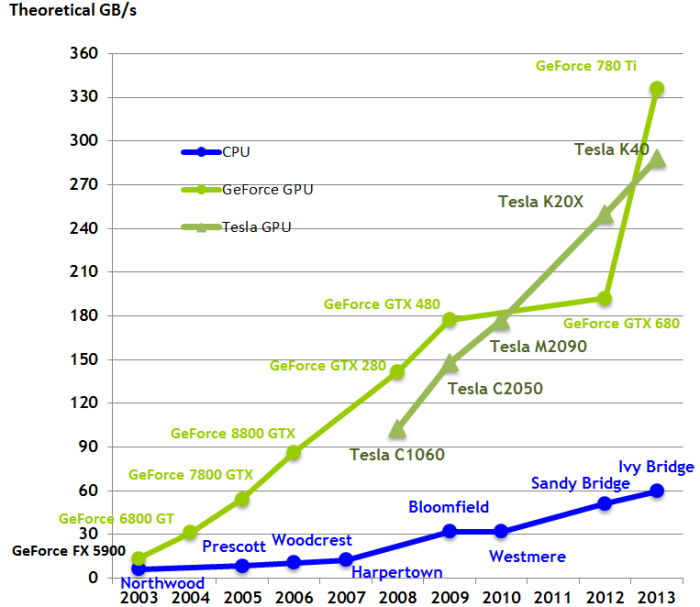
图2. 对比CPU和GPU的带宽发展
芯片架构相同时,带宽可以直接对比。比如,Pascal显卡GTX 1080和1070的性能对比,只需看显存带宽。GTX 1080(320GB/s)比GTX 1070(256GB/s)快25%。不过如果芯片架构不同,不能直接对比。比如Pascal和Maxwell (GTX 1080和Titan X),不同的生产工艺对同样带宽的使用不一样。不过带宽还是可以大概体现GPU有多快。
另外,需要看其架构是否兼容cnDNN。绝大多数深度学习库要用cuDNN来做卷积,因此要用Kepler或更好的GPU,即GTX 600系列或以上。一般来说,Kepler比较慢,所以从性能角度,应考虑900或1000系列。
为了比较不同显卡在深度学习任务上的性能,Tim做了个图。比如GTX 980和0.35个Titan X Pascal一样快,或者说Titan X Pascal比GTX快了差不多3倍。
这些结果并不来自于每张卡的深度学习benchmark测试,而是从显卡参数和计算型benchmark(在计算方面,一些加密货币挖掘任务和深度学习差不多)。所以这只是粗略估计。真实数字会有些不同,不过差距不大,显卡排名应该是对的。 同时,采用没有用足GPU的小网络会让大GPU看上去不够好。比如128个隐藏单元的LSTM(批处理>64)在GTX 1080 Ti上跑的速度不比GTX 1070快多少。要得到性能区别,需要用1024个隐藏单元的LSTM(批处理>64)。
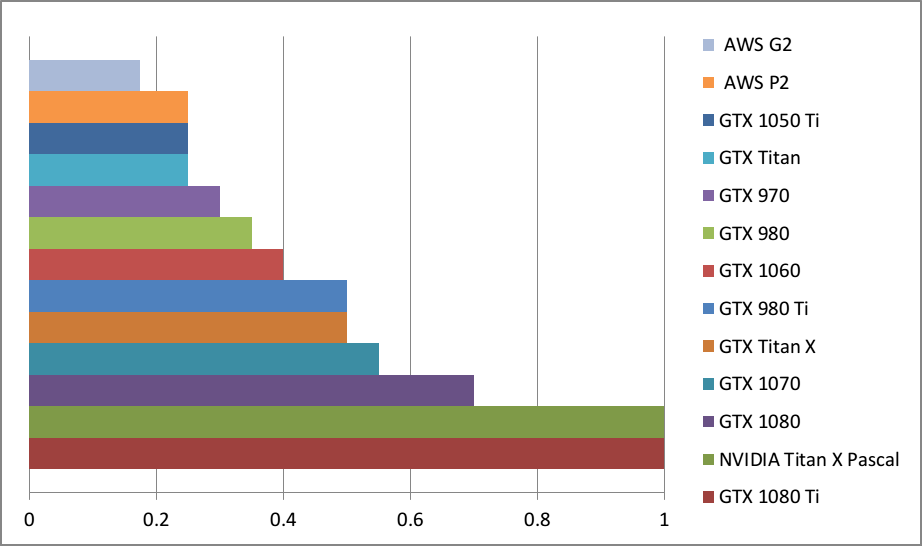
一般来说,Tim建议用GTX 1080 Ti或GTX 1070。这两者都不错。如果预算够的话,可以用GTX 1080 Ti。GTX 1070便宜一点,比普通GTX Titan X(Maxwell)更快。两者都比GTX 980 Ti更适合,因为显存更大——11GB和8GB,而不是6GB。
8GB有点小,但对很多任务都足够了,比如足够应付Kaggle比赛里大多数图像数据集合自然语言理解(NLP)的任务。
刚开始接触深度学习时,GTX 1060是最好的选择,也可以偶尔用于Kaggle比赛。3GB太少,6GB有时不太够,不过能应付很多应用了。GTX 1060比普通Titan X慢,但性能和二手价格都和GTX 980差不多。
从性价比来看,10系列设计很好。GTX 1060, 1070和1080 Ti更好。GTX 1060适合初学者, GTX 1070的用途多,适合初创公司和某些科研和工业应用,GTX 1080 Ti是不折不扣的全能高端产品。
Tim不太建议NVIDIA Titan X (Pascal),因为性价比不太好。它更适合计算机视觉的大数据集,或视频数据的科研。显存大小对这些领域的影响非常大,而Titan X比GTX 1080 Ti大1GB,因此更适合。 不过,从eBay上买GTX Titan X(Maxwell)更划算——慢一点,但12GB的显存够大。
GTX 1080Ti对大多数科研人员够用了。额外多1GB的显存对很多科研和应用的用处不大。
在科研上,Tim个人会选多张GTX 1070. 他宁可多做几次实验,稍微慢一点,而不是跑一次实验,快一点。NLP对显存的要求不像计算机视觉那么紧,因此GTX 1070足够了。他现在处理的任务和方式决定了最合适的选择——GTX 1070。
选择GPU时可以用类似的思路。先想清楚所执行的任务和实验方法,再找满足要求的GPU。现在AWS上的GPU实例比较贵且慢。GTX 970比较慢,而且二手的也比较贵(eBay上卖$150)而且启动时显卡有内存问题。可以多花点钱买GTX 1060,速度更快,显存更大,而且没有显存问题。如果GTX 1060太贵,可以用4G显存的GTX 1050 Ti。4GB有点小,但也深度学习的起步也够了。如果在某些型号上做调整,可以得到较好性能。GTX 1050 Ti适合于大多数Kaggle比赛,不过可能在一些比赛里发挥不出选手优势。
AWS(Amazon Web Services)的GPU实例
现在AWS上的GPU比较慢(GTX 1080速度是AWS GPU的四倍),而且价格最近几个月涨了很多。购买自己的GPU更明智。
结论
采购GPU时,需要平衡所需的显存大小、带宽(GB/s)和价格。目前,预算够的话,可用GTX 1080 Ti或GTX 1070; 如果刚开始或预算有限,可选GTX 1060; 如果钱很少,尽量买GTX 1050 Ti; 如果用于计算机视觉科研,可考虑Titan X Pascal (或者手上现有的GTX Titan X)。
TL;DR 一言以蔽之
数据库GPU
最常用的生产级GPU:Tesla K40/80
起步:GTX 780
深度学习GPU
综合最好的GPU: Titan X Pascal和GTX 1080 Ti
划算,较贵:GTX 1080 Ti, GTX 1070
划算,较便宜: GTX 1060
Tim用于250GB以上的数据集: 普通GTX Titan X或Titan X Pascal
预算很少: GTX 1060
预算少得可怜: GTX 1050 Ti
Tim参加Kaggle竞赛: 普通竞赛用GTX 1060,深度学习类用GTX 1080 Ti
追求性能的计算机视觉科研: Titan X Pascal 或普通GTX Titan X
普通科研人员: GTX 1080 Ti,而某些情况,比如自然语言处理,GTX 1070也够可靠,具体要看所用模型对显存的要求;
GPU集群: 参见此处
刚开始接触深度学习而且比较认真: 从GTX 1060开始,根据日后情况(比如创业、参加Kaggle竞赛、科研或深度学习应用)换成更合适的GPU。
