@yy125
2017-03-27T01:45:59.000000Z
字数 7625
阅读 465
Facebook的开源大规模预测系统Prophet怎么用?
数据分析 预测

图片为作者在印尼Manado拍摄,Sarasvati Anemone Shrimp。
本文将结合Facebook的开源预测系统Prophet,介绍时序分析的基本概念和方法。为从事时序分析,或使用开源预测工具的朋友,提供参考。
基础
时间序列(Time Series Analysis)作为计量经济学的三大数据形态之一,越来越被各行各业所重视,逐渐成为数据分析的重要对象。时序分析应用非常广泛,从业务预测到全球变暖;从生猪、煤炭价格到股票、国债走势。常见的时间序列包括:大宗商品价格、销售额、页面浏览量、广告点击率、消费者物价指数等等,观察间隔从毫秒到年,甚至更大,比如地球物理研究中用到的时间单位。
比较主流的观点认为,时间序列受四种成分影响:
- 趋势:宏观、长期、持续性的作用力,比如我国房地产价格;
- 周期:比如商品价格在较短时间内,围绕某个均值上下波动;
- 季节:变化规律相对固定,并呈现某种周期特征。比如每年国内航班的旅客数、空调销售量、每周晚高峰时间等。“季节”不一定按年计。每周、每天的不同时段的规律,也可称作季节性。
- 随机:随机的不确定性,比如10分钟内A股的股指变化,也是人们常说的随机过程(Stochastic Process)。
这四种成分对时间序列的影响,常归纳为累积和相乘两种。累积意味着四种成分相互叠加,它们之间相对独立,相互影响较小。而相乘意味着它们相互影响更为明显。
时间序列的最主要用途是预测。统计学者常常根据历史数据,找出主要的影响成分和各自的作用,从而得到某种模型。再通过最小二乘法等优化模型,来缩小模型的计算结果和实际观测值之间的差距。最后,用它来预测未来的走势和置信区间。
实践中最常见的分析模型包括三类:自回归、移动平均和整合模型。他们相互结合,又产生了ARIMA(Auto Regression Integreated Moving Average)等模型,不过对数据分析人员来说,更方便的是用现成的软件包和语言。2017年2月23日Facebook开源的Prophet就是其中一种。
Prophet是个基于Python和R语言的预测工具。Facebook用它来进行容量安排和目标设置等工作,以便有效地分配稀有资源,以及评测和考核结果。无论是由机器学习算法还是统计分析师预测,高质量的结果都很难得到。现实中,商用预测一般会出现两种情况。
- 全自动的预测技术可能容易出问题,不能灵活地加入有价值的假设或经验。
- 能提出高质量预测的分析师很少,因为预测需要相当的经验,专业性强。
对高质量预测的需求,远远超过分析师所能提供的速度。因此Facebook做了Prophet:不管使用者是不是专家,都能得到高质量预测结果,并跟得上需求的步伐。
对预测而言,规模化应用不完全受计算和存储的限制。Facebook发现,对大量时序数据进行预测时,计算和基础设施的问题不难解决。所用的程序可以很容易并行化,预测数据可以用MySQL等关系型数据库或Hive等数据仓库轻松存储。
在现实工作中进行规模化预测的复杂之处在于,预测课题的种类不同,而且不易赢得用户对大量预测的信任。Facebook在决策和确定产品特点上,用Prophet已获得了大量可信的预测。
Prophet的亮点
并不是所有问题都可以用同样的程序解决。Prophet所针对的,是Facebook的商业预测任务,这些任务一般具有以下特征:
- 按小时、日、周的观测值,至少是几个月的历史数据(最好是一年);
- 多种和人类活动相关的强周期性:比如每周的某日,一年中的某个时间;
- 按不确定间隔出现,已知的重要节假日,比如超级碗(Super Bowl);
- 合理数量的空白观测值或异常值;
- 时间趋势会转折,比如新产品发布;
- 非线性增长的趋势,比如到达了某种自然局限或饱和。
他们发现Prophet缺省设置产生的预测,常常和有经验的预测者所做的同样准确,而省力很多。如果对预测结果不满意,用Prophet可以避免全自动程序的限制——没接受过时序方法培训的分析师也能用一系列容易理解的参数,来改善或者调整。 通过把自动预测和有分析师参与的预测相结合,来分析特殊案例,可以满足很多的业务场景。下面这幅图展示了可行的规模化预测流程:
建模阶段可用的工具,目前很有限。Rob Hyndman的R语言预测工具包可能是最受欢迎的工具。谷歌和Twitter分别发布的CausalImpact和AnomalyDetection含有更具体的时序功能。据Facebook团队所知,开源的Python预测工具包很少。
他们喜欢用Prophet的原因有二:
1. 用Prophet可以更方便地做出靠谱的预测。其他预测包里有很多不同的预测技术(ARIMA、指数平滑法等等),各自有不同的优缺点和调优参数。一旦选错模型或参数,结果常常较差。即使是有经验的分析师也很难保证从这么多选择里,选出正确的模型和参数。
2. 对于普通用户,Prophet预测可以定制得更直观。 通过周期规律模型的平滑参数,可以调节和历史周期的契合程度,而趋势模型的平滑参数可以调节历史趋势转折所带来的影响有多明显。既可以手动设置增长曲线的“容量”或上限,并加入你所知道的信息来预测增长或下降,也可以设置非周期性的节假日日期,比如超级碗、感恩节和黑色星期五等。
Prophet如何工作?
Prophet程序核心是一个累加回归模型(Additive Regression Model),包括四个主要成分:
- 用分段线性或逻辑增长曲线拟合的趋势成分。Prophet会从数据中找出转折点,来自动检测趋势变化。
- 用傅里叶级数建模的季节成分,以年为单位;
- 用虚拟变量表示的季节成分,以周为单位;
- 用户自己提供的重要节假日清单。
举个例子,用wikipediatrend工具包下载美国著名橄榄球四分卫的维基页面浏览量之后,可以用Prophet进行预测。因为他是美国球员,一年里的周期规律会起很大作用,而一周里的周期规律也很明显。他参加过的季后赛等重要事件也在模型里。
Prophet有两个输入字段: ds(datestamp日期戳)和y (所预测的指标)。ds必须是date或datetime类型,y必须是numeric类型。
用Wikipediatrend的R工具包抓到此维基页面浏览量后,先导入Prophet。
# 导入页面浏览量数据import pandas as pdimport numpy as npfrom fbprophet import Prophet# 用csv建立数据框,转为对数坐标df = pd.read_csv('../examples/example_wp_peyton_manning.csv')df['y'] = np.log(df['y'])df.head()
| DS | y | |
|---|---|---|
| 0 | 2007-12-10 | 9.590761 |
| 1 | 2007-12-11 | 8.519590 |
| 2 | 2007-12-12 | 8.183677 |
| 3 | 2007-12-13 | 8.072467 |
| 4 | 2007-12-14 | 7.893572 |
先用缺省参数,初始化Prophet对象。再调用fit方法,将建好的数据框放到Prophet模型里。大概需要1-5秒。
# 将数据框导入Prophet模型m = Prophet()m.fit(df);
然后用Prophet.make_future_dataframe函数,按你希望预测的天数,将数据框延伸。predict会算出每行相应的预测值yhat,产生一个新的数据框,包括预测值"yhat",预测的上下边界(置信区间)"yhat_upper"、"yhat_lower"。
# 预测,将结果放入forecast数据框future = m.make_future_dataframe(periods=365)forecast = m.predict(future)forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()# 按forecast数据框绘图m.plot(forecast);
| ds | yhat | yhat_lower | yhat_upper | |
|---|---|---|---|---|
| 3265 | 2017-01-15 | 8.205065 | 7.518780 | 8.899184 |
| 3266 | 2017-01-16 | 8.530088 | 7.752344 | 9.246332 |
| 3267 | 2017-01-17 | 8.317468 | 7.641099 | 9.039998 |
| 3268 | 2017-01-18 | 8.150081 | 7.333512 | 8.888837 |
| 3269 | 2017-01-19 | 8.162015 | 7.415570 | 8.850360 |

可以用plot_components方法画出其他分量。缺省情况下,包括趋势、按年和按周的周期变化。如果加入节假日,也可以画出来。

Prophet为R提供了library, 可以在R里调用prophet函数来创建模型,然后同样可以用predict和plot函数。
解读
第一幅趋势图(trend)里,可以看到按页面浏览量的总趋势。他最近退休,所以浏览量逐渐下降。 第二幅按周的周期规律图里能看出,在比赛当天和赛后(周日和周一)访问量明显较高。美国NFL橄榄球比赛主要集中在九月到次年1月初,和二月初的超级碗。这也反映在第三幅图中,按年的周期规律图。
灵活驾驭各种成分
预测工具包的好坏,既和它采用的模型有关,也取决于能否让使用者方便地调整各个成分相应的预测机制。
据Facebook称,Prophet的特色在于,通过灵活地拟合趋势成分,可以更准确地对季节成分建模,预测会更准。采用了曲线拟合比较灵活,也能更好地处理空白观测值和异常值。
趋势
缺省状态下,Prophet用线性模型进行预测,用户可以设置预测能达到的最高点,比如市场容量,人口上限等最大承载力。也可以用逻辑增长的趋势模型进行预测。
成长预测
模型采用了逻辑函数,其中是中值,cap是上限,K是陡峭度。数据框里的每行都对应各自的cap, 比如市场容量在变化。

# 最大承载力,即上限,每行都应设置df['cap'] = 8.5#用逻辑函数拟合时序数据m = Prophet(growth='logistic')m.fit(df)# 预测未来三年,1826天,上限固定在8.5future = m.make_future_dataframe(periods=1826)future['cap'] = 8.5fcst = m.predict(future)m.plot(fcst);

转折点
现实中,趋势会产生转折。因此需要从历史数据中找出转折点,并对趋势进行修正。Prophet会自动检测到转折,用户也可以自己调整。 缺省下,可能的转折点总数是25个,均匀地分布在前80%的时间序列里,如下图竖虚线所示。再用稀疏先验(Sparse Prior, L1范数)选出尽量少的几个点建模。

实际产生影响的转折点并不多,从下图的变动率可以看出,较大的转折点只有9个。

采用L1范数的主要问题是过拟合(Overfitting)。Prophet是通过改变changepoint_prior_scale参数来调整。用户还可以自己指定转折点。
节日效应
对于节假日,需要先建立数据框,包括时间戳ds和观察数据holiday两个字段,每个观测点占一行,要包括以前的和今后会出现的所有节假日时间点。通过lower_window和upper_window来设定每个假期的开始和结束,比如:
#将季后赛、超级碗作为假日,加入数据框playoffs = pd.DataFrame({'holiday': 'playoff','ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16','2010-01-24', '2010-02-07', '2011-01-08','2013-01-12', '2014-01-12', '2014-01-19','2014-02-02', '2015-01-11', '2016-01-17','2016-01-24', '2016-02-07']),'lower_window': 0,'upper_window': 1,})superbowls = pd.DataFrame({'holiday': 'superbowl','ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),'lower_window': 0,'upper_window': 1,})holidays = pd.concat((playoffs, superbowls))#将holiday加入模型,进行预测m = Prophet(holidays=holidays)forecast = m.fit(df).predict(future)
可以看到,各成分的分析图里,Holiday成分在假日后面有明显冲高,但并不影响其他成分的分析。

同样,如果出现过拟合,也可以通过调整holidays_prior_scale加以平滑。
对于L1和L2范数的讨论很多,Prophet采用的L1范数,计算起来比较快,对特征量的选择性较好,更容易解释,不过对过拟合的处理似乎简单了点。
置信区间
统计模型的一个重要的特点在于,包含有随机误差,而且对随机误差有完整的解释体系。预测结果常常是这样的: “下周xx销售额 1000到1100万元之间的概率是90%”。预测结果实际上是出现在某个置信空间(Confidence interval)的概率。预测“准不准”是暂时、局部的——持续几小时还是几个月?适合北上广还是所有城市?不准的时候,会不会偏离得很离谱?
像阴阳共生一样,预测包括了两方面的平衡:准确 vs 可解释性,或者说,可计算 vs 对不确定性的把握。既追求在有限时间内能得到较准确的结论,又要避免“过拟合”。这就要求能在某种程度上解释 模型本身,比如变量之间如何影响,和现实中不同外界条件下的统计分布。
“准确”,意味着即使模型是黑盒子,只要能计算出较准确的结果就行,但如果仅仅追求对模拟数据的拟合度,在真实运营的偏差可能很离谱。更严重的是,难以较准确地估算偏差区间和概率分布,造成风险不可控。统计学家称之为“过拟合”。
比如,在10倍杠杆的情况下进行量化交易,1万元的保证金可以买10万元的股票,同样的涨幅能让你获得10倍收益,坏处是,10%的跌幅将把保证金跌光。如果某个模型能准确地在高点卖出,低点买进,当然能获得更大的收益。但是,你愿意用一个平均收益5%,且回撤(跌幅)达2个标准差的概率仅1%的模型,还是一个收益20%而回撤概率未知的模型?
实际上,预测误差是由三个变量组成:偏差(bias)、方差(variance)和自带误差。如果我们希望用X(时间)来预测Y(浏览量),用ϵ表示预测误差,ϵ符合正态分布),则有:
如果用模型来模拟, 那么预测误差为:
即:
很明显,预测误差包括了偏差(模型和实际结果的偏差)、方差(模型本身的方差)和无法缩减的自带误差。
Scott Fortmann有个很好的图来表示他们之间的关系:
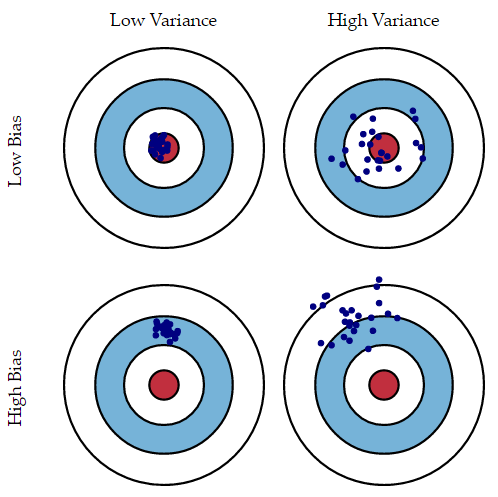
本文来自Scott Fortmann Roe网站
假设我们用不同的数据,重复建模过程。预测结果会有所不同。最佳预测模型能命中靶子中心。每个着弹点表示用每次重复所得到的模型的结果。当训练数据比较好,产生的模型也较准;而训练数据里有很多异常值(Outlier)时,产生的模型就不那么准了。
上文中的模型方差(Variance)越大,弹孔越分散;而偏差(Bias)越大,则弹孔整体偏离靶心越多。这两个差都很重要,并不是平均值越准就越好。统计学里常说Bias-Variance Tradeoff即是如何处理偏差和方差,其本质是减小“过拟合”。模型越复杂,参数越多,则偏差逐渐减小,而方差越大。 关于具体方法的讨论很多,可以参见Scott Fortmann网站,在此不展开了。
对于变量众多且相互影响的场景,比如搜索引擎、电商等,预测模型,如何更好地预测是个比较复杂的课题。我国对机器学习和统计的讨论也很热闹,值得看看。
言归正传,Prophet认为置信区间的不确定性来自于:趋势、季节性(含年月日等周期)和其他观测噪声。
趋势
Prophet假设,趋势和转折会重复。未来转折的平均频率和幅度和历史一样。因此,将以前的趋势和转折向未来推演,并计算相应的分布,就能得到置信区间。
如前文所述,通过changepoint_prior_scale来调整转变点的数量,能提高模型的灵活度。调整interval_width可以调整置信空间的宽度,缺省状况是80%。
季节性
缺省状态下,Prophet只考虑趋势和随机噪声的置信空间。要计算季节性不确定性,需要先进行完整的贝叶斯取样,用马尔科夫链蒙特卡洛(MCMC)取样来代替MAP计算。计算会需要几十倍时间。季节性成分的预测图上会显示出置信区间。

如何使用Prophet
Prophet是用Stan搭建的,其核心函数用Stan概率编程语言编写。Stan计算和优化MAP参数的速度很快(<1秒),方便Facebook用HMC算法(Hamiltonian Monte Carlo) 计算参数的不确定性,而且不用重写其他语言编写的拟合程序。Prophet的Phython和R版本的功能特点完全一样。
最简单的办法是从PyPI(Python)或CRAN (R)下载软件包进行安装。可以阅读快速入门手册或全部文档。时序数据的样本可以从wikipediatrend工具包,来下载维基网页的浏览数据。
欢迎下载Prophet最新版本和补丁,并参与社区贡献。
小结
随着人工智能变得越来越火,预测系统也越来越受关注。它在营销资源调配、供应链管理、金融风控、量化交易等领域的应用越来越广。随着机器学习、神经网络等软件技术的提升,配合大集群、多核、多GPU等分布式计算能力的发展,预测在技术上将变得越来越可行,而不再是少数研究机构和大型高科技企业的特权。
同时,随着预测的应用越来越广,“准确”和“健壮性”缺一不可,否则失败的预测所带来的风险将大大制约其进一步发展。 软件、数据和统计方法这三驾马车缺一不可。“准”到什么程度?如何协调好偏差和方差?样本数据是否具有统计意义?是否涵盖足够现实情况?参数组的优化应该追求些什么?这些问题都非常重要,而不应仅仅靠预测工具来解决。
