@vivounicorn
2017-09-04T09:55:55.000000Z
字数 218636
阅读 74675
机器学习与人工智能技术分享(未完待续)
机器学习 中文版


- 机器学习与人工智能技术分享(未完待续)
- 1. 一些基本概念
- 2. 建模方法回顾
- 3. 机器学习中的统一框架
- 4. 最优化原理
- 5. 深度神经网络
- 5.1 反向传播
- 5.2 卷积网络结构演化史
- 5.3 CNN基本原理
- 5.4 LeNet-5
- 5.5 AlexNet
- 5.6 VGG
- 5.7 MSRANet
- 5.8 Highway Networks
- 5.9 Residual Networks
- 5.10 Maxout Networks
- 5.11 Network in Network
- 5.12 GoogLeNet Inception V1
- 5.13 GoogLeNet Inception V2
- 5.14 GoogLeNet Inception V3
- 5.15 GoogLeNet Inception V4/ResNet V1/V2
- 5.16 模型可视化
- 6. 循环神经网络(待填坑)
- 7. 对抗神经网络(待填坑)
- 8. 目标检测
- 9. 语义分割
- 10. 物体跟踪
- 11. 强化学习
- 12. BOT
- 13. OCR
- 13.1 基于字符分割
- 13.2 基于行分割
- 13.3 CTC
- 14. 机器学习工具
- 15. 自动驾驶
- 16. CUDA编程与高性能计算
- 17. References
1. 一些基本概念
1.1 生成式模型与判别式模型
从概率分布的角度看待模型。
给个例子感觉一下: 如果我想知道一个人A说的是哪个国家的语言,我应该怎么办呢?
- 生成式模型
我把每个国家的语言都学一遍,这样我就能很容易知道A说的是哪国语言,并且C、D说的是哪国的我也可以知道,进一步我还能自己讲不同国家语言。- 判别式模型
我只需要学习语言之间的差别是什么,学到了这个界限自然就能区分不同语言,我能说出不同语言的区别,但我哦可能不会讲。
如果我有输入数据,并且想通过标注去区分不同数据属于哪一类,生成式模型是在学习样本和标注的联合概率分布 而判别式模型是在学习条件概率 。
生成式模型可以通过贝叶斯公式转化为,并用于分类,而联合概率分布也可用于其他目的,比如用来生成样本对。
判别式模型的主要任务是找到一个或一系列超平面,利用它(们)划分给定样本到给定分类,这也能直白的体现出“判别”模型这个名称。
最后给一个很简单的例子说明一下:
假如我有以下独立同分布的若干样本,其中为特征,为标注,,则:
一些理论可看:On Discriminative vs Generative classifiers: A comparison of logistic regression and naive Bayes。
常见生成式模型
- Naive Bayes
- Gaussians
- Mixtures of Gaussians
- Mixtures of Experts
- Mixtures of Multinomials
- HMM
- Markov random fields
- Sigmoidal belief networks
- Bayesian networks
常见判别式模型
- Linear regression
- Logistic regression
- SVM
- Perceptron
- Traditional Neural networks
- Nearest neighbor
- Conditional random fields
1.2 参数学习与非参学习
从参数与样本的关系角度看待模型。
1.2.1 参数学习
参数学习的特点是:
- 选择某种形式的函数并通过机器学习用一系列固定个数的参数尽可能表征这些数据的某种模式;
- 不管数据量有多大,函数参数的个数是固定的,即参数个数不随着样本量的增大而增加,从关系上说它们相互独立;
- 往往对数据有较强的假设,如分布的假设,空间的假设等。
- 常用参数学习的模型有:
- Logistic Regression
- Linear Regression
- Polynomial regression
- Linear Discriminant Analysis
- Perceptron
- Naive Bayes
- Simple Neural Networks
- 使用线性核的SVM
- Mixture models
- K-means
- Hidden Markov models
- Factor analysis / pPCA / PMF
1.2.2 非参学习
注意不要被名字误导,非参不等于无参。
- 数据决定了函数形式,函数参数个数不固定;
- 随着数据量的增加,参数个数一般也会随之增长;
- 对数据本身做较少的先验假设。
- 一些常用的非参学习模型:
- k-Nearest Neighbors
- Decision Trees like CART and C4.5
- 使用非线性核的SVM
- Gradient Boosted Decision Trees
- Gaussian processes for regression
- Dirichlet process mixtures
- infinite HMMs
- infinite latent factor models
进一步知识可以看:Parametric vs Nonparametric Models。
1.3 监督学习、非监督学习与强化学习
1.3.1 监督学习
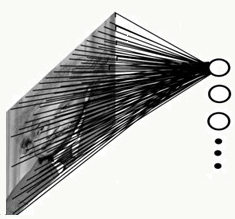
对于每一个样本都会提供一个明确的学习目标(标注),有自变量也有因变量,学习机接收样本进行学习并通过对该样本预测后的结果和事先给定的目标比较后修正学习过程,这里的每一个样本都是标注好的,所以好处是歧义较低,坏处是万一有一定量样本标错了或者没标会对最终应用效果影响较大。通常监督学习过程如下:

picture from here
1.3.2 非监督学习
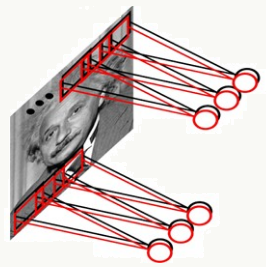
对于每个样本不提供明确的学习目标(标注),有自变量但无因变量,学习机接收样本后会按事先指定的必要参数,依据某种相似度衡量方式自动学习样本内部的分布模式,好处是没有过多先验假设,能够体现数据内在模式并应用,坏处是有“盲目”性,并会混在噪声数据。比如:常用LDA做主题聚类,但如果使用场景不是降维而是想得到可输出的主题词,基本上没有人肉的干预无法直接使用(虽然整体上看感觉可能不错)。

picture from here
1.3.3 强化学习
我认为强化学习是最接近人类学习过程的,很多情况下我们无法直接表达什么是正确的什么是错误的(比如:我正在爬山,迈了一大步,又迈了一小步,那么没法儿说我迈了大步正确还是错误),但是可以通过惩罚不好的结果或者奖励好的结果来强化学习的效果(我迈了个大步,导致没有站稳,那么对迈大步做惩罚,然后接下来我会迈小一点)。所以强化学习是一个序列的决策过程,学习机的学习目标是通过在给定状态下选择某种动作,寻找合适动作的策略序列使得它可以获得某种最优结果的过程。
强化学习的几个要素,体现其序列、交互性:
- 环境(environment):强化学习所处的上下文;
- 学习器(agent):与环境的交互并学习的对象,具有主动性;
- 动作(action):处于环境下的可行动作集合;
- 反馈(feedback):对动作的回报或惩罚;
- 策略(policy):学习到的策略链。

picture from here
经典的训练狗的实验就是一种强化学习的过程:

picture from here
强化学习的有趣应用例如:
- AlphaGo
Mastering the Game of Go with Deep Neural Networks and Tree Search - Atari 2600 games
Human-level control through deep reinforcement learning
Massively Parallel Methods for Deep Reinforcement Learning
2. 建模方法回顾
以通用的监督学习为例,基本包含4个部分:
2.0 偏差与方差
- 在机器学习算法中,偏差是由先验假设的不合理带来的模型误差,高偏差会导致欠拟合: 所谓欠拟合是指对特征和标注之间的因果关系学习不到位,导致模型本身没有较好的学到历史经验的现象;
- 方差表征的是模型误差对样本发生一定变化时的敏感度,高方差会导致过拟合:模型对训练样本中的随机噪声也做了拟合学习,导致在未知样本上应用时出现效果较差的现象;
- 机器学习模型的核心之一在于其推广能力,即在未知样本上的表现。
对方差和偏差的一种直观解释:

一个例子,假如我们有预测模型:
我们希望用 估计 ,如果使用基于square loss 的线性回归,则误差分析如下:

所以大家可以清楚的看到模型学习过程其实就是对偏差和方差的折中过程。
2.1 线性回归-Linear Regression

2.1.1 模型原理
标准线性回归通过对自变量的线性组合来预测因变量,组合自变量的权重通过最小化训练集中所有样本的预测平方误差和来得到,原理如下。
- 预测函数
- 参数学习-采用最小二乘法
所有机器学习模型的成立都会有一定的先验假设,线性回归也不例外,它对数据做了以下强假设:
- 自变量相互独立,无多重共线性
- 因变量是自变量的线性加权组合:
- 所有样本独立同分布(iid),且误差项服从以下分布:
最小二乘法与以上假设的关系推导如下:
使用MLE(极大似然法)估计参数如下:
线性回归有两个重要变体:
- Lasso Regression:采用L1正则并使用MAP做参数估计
- Ridge Regression:采用L2正则并使用MAP做参数估计
关于正则化及最优化后续会做介绍。
2.1.2 损失函数
损失函数1 —— Least Square Loss
进一步阅读可参考:Least Squares
Q: 模型和损失的关系是什么?
2.2 支持向量机-Support Vector Machine
支持向量机通过寻找一个分类超平面使得(相对于其它超平面)它与训练集中任何一类样本中最接近于超平面的样本的距离最大。虽然从实用角度讲(尤其是针对大规模数据和使用核函数)并非最优选择,但它是大家理解机器学习的最好模型之一,涵盖了类似偏差和方差关系的泛化理论、最优化原理、核方法原理、正则化等方面知识。
2.2.1 模型原理
SVM原理可以从最简单的解析几何问题中得到:

超平面的定义如下:
从几何关系上来看,超平面与数据点的关系如下(以正样本点为例):
定义几何距离和函数距离分别如下:
由于超平面的大小对于SVM求解并不重要,重要的是其方向,所以根据SVM的定义,得到约束最优化问题:
现实当中我们无法保证数据是线性可分的,强制要求所有样本能正确分类是不太可能的,即使做了核变换也只是增加了这种可能性,因此我们又需要做折中,允许误分的情况出现,对误分的样本根据其严重性做惩罚,所以引入松弛变量,将上述问题变成软间隔优化问题。

新的优化问题:
如果选择:
那么优化问题变成:
2.2.2 损失函数
损失函数2 —— Hinge Loss
使用hinge loss将SVM套入机器学习框架,让它更容易理解。此时原始约束最优化问题变成损失函数是hinge loss且正则项是L2正则的无约束最优化问题:
下面我证明以上问题(1)和问题(2)是等价的(反之亦然):
到此为止,SVM和普通的判别模型没什么两样,也没有support vector的概念,它之所以叫SVM就得说它的对偶形式了,通过拉格朗日乘数法对原始问题做对偶变换:
从互补松弛条件可以得到以下信息:
当时,松弛变量不为零,此时其几何间隔小于,对应样本点就是误分点;当时,松弛变量为零,此时其几何间隔大于,对应样本点就是内部点,即分类正确而又远离最大间隔分类超平面的那些样本点;而时,松弛变量为零,此时其几何间隔等于,对应样本点就是支持向量。的取值一定是,这意味着向量被限制在了一个边长为的盒子里。详细说明可参考SVM学习——软间隔优化。

当以上问题求得最优解后,几何间隔变成如下形式:
它只与有限个样本有关系,这些样本被称作支持向量,从这儿也能看出此时模型参数个数与样本个数有关系,这是典型的非参学习过程。
2.2.3 核方法
上面对将内积用一个核函数做了代替,实际上这种替换不限于SVM,所有出现样本间内积的地方都可以考虑这种核变换,本质上它就是通过某种隐式的空间变换在新空间(有限维或无限维兼可)做样本相似度衡量,采用核方法后的模型都可以看做是无固定参数的基于样本的学习器,属于非参学习,核方法与SVM这类模型的发展是互相独立的。

这里不对原理做展开,可参考:
1、Kernel Methods for Pattern Analysis
2、the kernel trick for distances
一些可以应用核方法的模型:
- SVM
- Perceptron
- PCA
- Gaussian processes
- Canonical correlation analysis
- Ridge regression
- Spectral clustering
在我看来核方法的意义在于:
1、对样本进行空间映射,以较低成本隐式的表达样本之间的相似度,改善样本线性可分的状况,但不能保证线性可分;
2、将线性模型变成非线性模型从而提升其表达能力,但这种升维的方式往往会造成计算复杂度的上升。
一些关于SVM的参考资料
SVM学习——线性学习器
SVM学习——求解二次规划问题
SVM学习——核函数
SVM学习——统计学习理论
SVM学习——软间隔优化
SVM学习——Coordinate Desent Method
SVM学习——Sequential Minimal Optimization
SVM学习——Improvements to Platt’s SMO Algorithm
2.3 逻辑回归-Logistic Regression
逻辑回归恐怕是互联网领域用的最多的模型之一了,很多公司做算法的同学都会拿它做为算法系统进入模型阶段的baseline。
2.3.1 模型原理
逻辑回归是一种判别模型,与线性回归类似,它有比较强的先验假设 :
- 假设因变量服从贝努利分布
- 假设训练样本服从钟形分布,例如高斯分布:
- 是样本标注,布尔类型,取值为0或1;
- 是样本的特征向量。
逻辑回归是判别模型,所以我们直接学习,以高斯分布为例:

整个原理部分的推导过程如下:
采用 MLE 或者 MAP 做参数求解:
2.3.2 损失函数
损失函数3 —— Cross Entropy Loss
简单理解,从概率角度:Cross Entropy损失函数衡量的是两个概率分布与之间的相似性,对真实分布估计的越准损失越小;从信息论角度:用编码方式对由编码方式产生的信息做编码,如果两种编码方式越接近,产生的信息损失越小。与Cross Entropy相关的一个概念是Kullback–Leibler divergence,后者是衡量两个概率分布接近程度的标量值,定义如下:
当两个分布完全一致时其值为0,显然Cross Entropy与Kullback–Leibler divergence的关系是:
关于交叉熵及其周边原理,有一篇文章写得特别好:Visual Information Theory。
2.4 Bagging and Boosting框架
Bagging和Boosting是两类最常用以及好用的模型融合框架,殊途而同归。
2.4.1 Bagging框架
Bagging(Breiman, 1996) 方法是通过对训练样本和特征做有放回的抽样,并拟合若干个基础模型进而通过投票方式做最终分类决策的框架。每个基础分类器(可以是树形结构、神经网络等等任何分类模型)的特点是低偏差、高方差,框架通过(加权)投票方式降低方差,使得整体趋于低偏差、低方差。

分析如下:
假设任务是学习一个模型 ,我们通过抽样生成生成 个数据集,并训练得到个基础分类器。
从结论可以发现多分类器投票机制的引入可以降低模型方差从而降低分类错误率,大家可以多理解理解这一系列推导。
2.4.2 Boosting框架
Boosting(Freund & Shapire, 1996) 通过迭代方式训练若干基础分类器,每个分类器依据上一轮分类器产生的残差做权重调整,每轮的分类器需要够“简单”,具有高偏差、低方差的特点,框架再辅以(加权)投票方式降低偏差,使得整体趋于低偏差、低方差。

一个简单的总结:
AnyBoost Algorithm
Boost算法是个框架,很多模型都能往进来套。
Q: boosting 和 margin的关系是什么(机器学习中margin的定义为)?
Q: 类似bagging,为什么boosting能够通过reweight及投票方式降低整体偏差?
2.5 Additive Tree 模型
Additive tree models (ATMs)是指基础模型是树形结构的一类融合模型,可做分类、回归,很多经典的模型可以被看做ATM模型,比如Random forest 、Adaboost with trees、GBDT等。
ATM 对N棵决策树做加权融合,其判别函数为:
2.5.1 Random Forests
Random Forest 属于bagging类模型,每棵树会使用各自随机抽样样本和特征被独立的训练。

2.5.2 AdaBoost with trees
AdaBoost with trees通过训练多个弱分类器来组合得到一个强分类器,每次迭代会生成一棵高偏差、低方差的树形弱分类器,每一轮的训练会更关注上一轮被分类器分错的样本,为其加大权重,训练过程如下:

2.5.3 Gradient Boosting Decision Tree
Gradient boosted 是一类boosting的技术,不同于Adaboost加大误分样本权重的策略,它每次迭代加的是上一轮梯度更新值:
其训练过程如下:
GBDT是基础分类器为决策树的可做分类和回归的模型。

目前我认为最好的GBDT的实现是XGBoost:
其回归过程的示例图如下,通过对样本落到每棵树的叶子节点的权重值做累加来实现回归(或分类):

其原理推导如下:
对GBDT来说依然避免不了过拟合,所以与传统机器学习一样,通过正则化策略可以降低这种风险:
- 提前终止(Early Stopping)
通过观察模型在验证集上的错误率,如果它变化不大则可以提前结束训练,控制迭代轮数(即树的个数);- 收缩(Shrinkage)
从迭代的角度可以看成是学习率(learning rate),从融合(ensemble)的角度可以看成每棵树的权重,的大小经验上可以取0.1,它是对模型泛化性和训练时长的折中;- 抽样(Subsampling)
借鉴Bagging的思想,GBDT可以在每一轮树的构建中使用训练集中无放回抽样的样本,也可以对特征做抽样,模拟真实场景下的样本分布波动;- 目标函数中显式的正则化项
通过对树的叶子节点个数、叶子节点权重做显式的正则化达到缓解过拟合的效果;- 参数放弃(Dropout)
模拟深度学习里随机放弃更新权重的方法,可以在每新增一棵树的时候拟合随机抽取的一些树的残差,相关方法可以参考:DART: Dropouts meet Multiple Additive Regression Trees,文中对该方法和Shrinkage的方法做了比较:

XGBoost源码在: https://github.com/dmlc中,其包含非常棒的设计思想和实现,建议大家都去学习一下,一起添砖加瓦。原理部分我就不再多写了,看懂一篇论文即可,但特别需要注意的是文中提到的weighted quantile sketch算法,它用来解决当样本集权重分布不一致时如何选择分裂节点的问题:XGBoost: A Scalable Tree Boosting System。
2.5.4 简单的例子
下面是关于几个常用机器学习模型的对比,从中能直观地体会到不同模型的运作区别,数据集采用libsvm作者整理好的fourclass_scale数据集,机器学习工具采用sklearn,代码中模型未做任何调参,仅使用默认参数设置。
import urllibimport matplotlibimport osmatplotlib.use('Agg')from matplotlib import pyplot as pltfrom mpl_toolkits.mplot3d import proj3dimport numpy as npfrom mpl_toolkits.mplot3d import Axes3Dfrom sklearn.externals.joblib import Memoryfrom sklearn.datasets import load_svmlight_filefrom sklearn import metricsfrom sklearn.metrics import roc_auc_scorefrom sklearn import svmfrom sklearn.linear_model import LogisticRegressionfrom sklearn.linear_model import Ridgefrom sklearn.ensemble import GradientBoostingClassifierfrom mpl_toolkits.mplot3d import Axes3Dfrom matplotlib import cmfrom matplotlib.ticker import LinearLocator, FormatStrFormatterfrom sklearn.tree import DecisionTreeClassifierimport kerasfrom keras.models import Sequentialfrom keras.layers.core import Dense,Dropout,Activationdef download(outpath):filename=outpath+"/fourclass_scale"if os.path.exists(filename) == False:urllib.urlretrieve("https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/fourclass_scale",filename)def data_building():dtrain = load_svmlight_file('fourclass_scale')train_d=dtrain[0].toarray()train_l=dtrain[1]x1 = train_d[:,0]x2 = train_d[:,1]y = train_lpx1 = []px2 = []pl = []nx1 = []nx2 = []nl = []idx = 0for i in y:if i == 1:px1.append(x1[idx]-0.5)px2.append(x2[idx]+0.5)pl.append(i)else:nx1.append(x1[idx]+0.8)nx2.append(x2[idx]-0.8)nl.append(i)idx = idx + 1x_axis, y_axis = np.meshgrid(np.linspace(x1.min(), x1.max(), 100), np.linspace(x2.min(), x2.max(), 100))return x_axis, y_axis, px1, px2, nx1, nx2, train_d, train_ldef paint(name, x_axis, y_axis, px1, px2, nx1, nx2, z):fig = plt.figure()ax = Axes3D(fig)ax=plt.subplot(projection='3d')ax.scatter(px1,px2,c='r')ax.scatter(nx1,nx2,c='g')ax.plot_surface(x_axis, y_axis,z.reshape(x_axis.shape), rstride=8, cstride=8, alpha=0.3)ax.contourf(x_axis, y_axis, z.reshape(x_axis.shape), zdir='z', offset=-100, cmap=cm.coolwarm)ax.contourf(x_axis, y_axis, z.reshape(x_axis.shape), levels=[0,max(z)], cmap=cm.hot)ax.set_xlabel('X')ax.set_ylabel('Y')ax.set_zlabel('Z')fig.savefig(name+".png", format='png')def svc(x_axis, y_axis, x,y):clf = svm.SVC()clf.fit(x, y)y = clf.predict(np.c_[x_axis.ravel(), y_axis.ravel()])return ydef lr(x_axis, y_axis, x,y):clf = LogisticRegression()clf.fit(x, y)y = clf.predict(np.c_[x_axis.ravel(), y_axis.ravel()])return ydef ridge(x_axis, y_axis, x,y):clf = Ridge()clf.fit(x, y)y = clf.predict(np.c_[x_axis.ravel(), y_axis.ravel()])return ydef dt(x_axis, y_axis, x,y):clf = GradientBoostingClassifier()clf.fit(x, y)y = clf.predict(np.c_[x_axis.ravel(), y_axis.ravel()])return ydef nn(x_axis, y_axis, x,y):model = Sequential()model.add(Dense(20, input_dim=2))model.add(Activation('relu'))model.add(Dense(20))model.add(Activation('relu'))model.add(Dense(1, activation='tanh'))model.compile(loss='mse',optimizer='adam',metrics=['accuracy'])model.fit(x,y,batch_size=20, nb_epoch=50, validation_split=0.2)y = model.predict(np.c_[x_axis.ravel(), y_axis.ravel()],batch_size=20)return yif __name__ == '__main__':download("/root")x_axis, y_axis, px1, px2, nx1, nx2, train_d, train_l = data_building()z = svc(x_axis, y_axis, train_d, train_l)paint("svc", x_axis, y_axis, px1, px2, nx1, nx2, z)z = lr(x_axis, y_axis, train_d, train_l)paint("lr", x_axis, y_axis, px1, px2, nx1, nx2, z)z = ridge(x_axis, y_axis, train_d, train_l)paint("ridge", x_axis, y_axis, px1, px2, nx1, nx2, z)z = dt(x_axis, y_axis, train_d, train_l)paint("gbdt", x_axis, y_axis, px1, px2, nx1, nx2, z)z = nn(x_axis, y_axis, train_d, train_l)paint("nn", x_axis, y_axis, px1, px2, nx1, nx2, z)


2.6 人工神经网络-Neural Network
神经网络在维基百科上的定义是:NN is a network inspired by biological neural networks (the central nervous systems of animals, in particular the brain) which are used to estimate or approximate functions that can depend on a large number of inputs that are generally unknown.(from wikipedia)

2.6.1 神经元
神经元是神经网络和SVM这类模型的基础模型和来源,它是一个具有如下结构的线性模型:

其输出模式为:
示意图如下:

2.6.2 神经网络的常用结构
神经网络由一系列神经元组成,典型的神经网络结构如下:

其中最左边是输入层,包含若干输入神经元,最右边是输出层,包含若干输出神经元,介于输入层和输出层的所有层都叫隐藏层,由于神经元的作用,任何权重的微小变化都会导致输出的微小变化,即这种变化是平滑的。
神经元的各种组合方式得到性质不一的神经网络结构 :






2.6.3 一个简单的神经网络例子
假设随机变量 , 使用3层神经网络拟合该分布:
import numpy as npimport matplotlibmatplotlib.use('Agg')import matplotlib.pyplot as pltimport randomimport mathimport kerasfrom keras.models import Sequentialfrom keras.layers.core import Dense,Dropout,Activationdef gd(x,m,s):left=1/(math.sqrt(2*math.pi)*s)right=math.exp(-math.pow(x-m,2)/(2*math.pow(s,2)))return left*rightdef pt(x, y1, y2):if len(x) != len(y1) or len(x) != len(y2):print 'input error.'returnplt.figure(num=1, figsize=(20, 6))plt.title('NN fitting Gaussian distribution', size=14)plt.xlabel('x', size=14)plt.ylabel('y', size=14)plt.plot(x, y1, color='b', linestyle='--', label='Gaussian distribution')plt.plot(x, y2, color='r', linestyle='-', label='NN fitting')plt.legend(loc='upper left')plt.savefig('ann.png', format='png')def ann(train_d, train_l, prd_d):if len(train_d) == 0 or len(train_d) != len(train_l):print 'training data error.'returnmodel = Sequential()model.add(Dense(30, input_dim=1))model.add(Activation('relu'))model.add(Dense(30))model.add(Activation('relu'))model.add(Dense(1, activation='sigmoid'))model.compile(loss='mse',optimizer='rmsprop',metrics=['accuracy'])model.fit(train_d,train_l,batch_size=250, nb_epoch=50, validation_split=0.2)p = model.predict(prd_d,batch_size=250)return pif __name__ == '__main__':x = np.linspace(-5, 5, 10000)idx = random.sample(x, 900)train_d = []train_l = []for i in idx:train_d.append(x[i])train_l.append(gd(x[i],0,1))y1 = []y2 = []for i in x:y1.append(gd(i,0,1))y2 = ann(np.array(train_d).reshape(len(train_d), 1), np.array(train_l), np.array(x).reshape(len(x), 1))pt(x, y1, y2.tolist())

3. 机器学习中的统一框架
很多机器学习问题都可以放在一个统一框架下讨论,这样大家在理解各种模型时就是相互联系的。
3.1 目标函数
回忆一下目标函数的定义:
很多模型可以用这种形式框起来,比如linear regression、logistic regression、SVM、additive models、k-means,neural networks 等等。其中损失函数部分用来控制模型的拟合能力,期望降低偏差,正则项部分用来提升模型泛化能力,期望降低方差,最优模型是对偏差和方差的最优折中。
3.1.1 损失函数
损失函数反应了模型对历史数据的学习程度,我们期望模型能尽可能学到历史经验,得到一个低偏差模型。

Q:大家想想横坐标是什么?
实践当中很少直接使用0-1损失做优化(当然也有这么用的如:Direct 0-1 Loss Minimization and Margin Maximization with Boosting 和 Algorithms for Direct 0–1 Loss Optimization in Binary Classification,但总的来说应用有限),原因如下:
- 0-1损失的优化是组合优化问题且为NP-hard,无法在多项式时间内求得;
- 损失函数非凸非光滑,很多优化方法无法使用;
- 对权重的更新可能会导致损失函数大的变化,即变化不光滑;
- 只能使用正则,其他正则形式都不起作用;
- 即使使用正则,依然是非凸非光滑,优化求解困难。
由于0-1损失的问题,所以以上损失函数都是对它的近似。原理细节可以参考:Understanding Machine Learning: From Theory to Algorithms
不同损失函数在相同数据集下的直观表现如下:

3.1.2 正则化项
正则化项影响的是模型在未知样本上的表现,我们希望通过它能降低模型方差提高泛化性。
如果有数据集:
在给定假设下,通常采用极大似然估计(MLE)求解参数:
假设模型参数也服从某种概率分布: , 可以采用极大后验概率估计(MAP)求解参数。
3.1.3 L2 正则
假设

3.1.4 L1 正则
假设

3.1.5 正则化的几何解释

给定向量, 定义 正则,其中 :
不同q的取值下正则项的几何表现如下:

3.1.6 Dropout正则化与数据扩充
这两类方法在神经网络中比较常用,后面会专门介绍。
3.2 神经网络框架
很多模型可以看做是神经网络,例如:感知机、线性回归、支持向量机、逻辑回归等
3.2.1 Linear Regression
线性回归可以看做是激活函数为的单层神经网络:

3.2.2 Logistic Regression
逻辑回归可以看做是激活函数为的单层神经网络:

3.2.3 Support Vector Machine
采用核方法后的支持向量机可以看做是含有一个隐层的3层神经网络:

3.2.4 Bootstrap Neural Networks
采用bagging方式的组合神经网络:

3.2.5 Boosting Neural Network
采用boosting方式的组合神经网络:

4. 最优化原理
4.1 泰勒定理
满足一定条件的函数可以通过泰勒展开式对其做近似:
4.1.1 泰勒展开式
泰勒展开式原理如下,主要采用分部积分推导:
4.1.2 泰勒中值定理
需要注意泰勒中值定理是一个严格的等式:
4.2 梯度下降法
4.2.1 基本原理
梯度下降是一种简单、好用、经典的使用一阶信息的最优化方法(意味着相对低廉的计算成本),其基本原理可以想象为一个下山问题,当下降方向与梯度方向一致时,目标函数的方向导数最大,即此时目标函数在当前起点位置的下降速度最快。

基于梯度的优化算法通常有两个核心元素:搜索方向和搜索步长,并且一般都会和泰勒定理有某种联系,从泰勒中值定理可以得到下面的等式:
4.2.2 迭代框架
4.2.3 批量梯度下降
按照上面等式,每次迭代,为计算梯度值都需要把所有样本扫描一遍,收敛曲线类似下图:

它的优点如下:
- 模型学习与收敛过程通常是平滑的和稳定的;
- 关于收敛条件有成熟完备的理论;
- 针对它有不少利用二阶信息加速收敛的技术,例如conjugate gradient;
- 对样本噪声点相对不敏感。
它的缺点如下:
- 收敛速度慢;
- 对初始点敏感;
- 数据集的变化无法被学习到; captured.
- 不太适用于大规模数据。
4.2.4 随机梯度下降
完全随机梯度下降(Stochastic Gradient Descent,可以想想这里为什么用Stochastic而不用Random?)每次选择一个样本更新权重,这样会带来一些噪声,但可能得到更好的解,试想很多问题都有大量局部最优解,传统批量梯度下降由于每次收集所有样后更新梯度值,当初始点确定后基本会落入到离它最近的洼地,而随机梯度下降由于噪声的引入会使它有高概率跳出当前洼地,选择变多从而可能找到更好的洼地。
收敛曲线类似下图:

完全随机梯度下降和批量梯度下降的优缺点几乎可以互换:
- SGD的收敛速度更快;
- SGD相对来说对初始点不敏感,容易找到更优方案;
- SGD相对适合于大规模训练数据;
- SGD能够捕捉到样本数据的变化;
- 噪声样本可能导致权重波动从而造成无法收敛到局部最优解,步长的设计对其非常重要。
实践当中,很多样本都有类似的模式,所以SGD可以使用较少的抽样样本学习得到局部最优解,当然完全的批量学习和完全的随机学习都太极端,所以往往采用对两者的折中。
4.2.5 小批量梯度下降
小批量梯度下降(Mini-batch Gradient Descent)是对SGD和BGD的折中,采用相对小的样本集学习,样本集大小随着学习过程保持或逐步加大,这样既能有随机带来的好处,又能使用二阶优化信息加速收敛,目前主流机器学习工具几乎都支持小批量学习。
小批量学习收敛过程如下:

梯度下降的另外一个任务是寻找合适的学习率,关于它有很多方法,介绍如下:
4.2.6 牛顿法
从泰勒展开式可以得到带最优步长的迭代式:
但最优的学习率需要计算hessian矩阵,计算复杂度为,所以这种方法不怎么用。
为方便起见,使用 代替 .
4.2.7 Momentum
SGD的一大缺点是 只和当前样本有关系,如果样本存在噪声则会导致权重波动,一种自然的想法就是即考虑历史梯度又考虑新样本的梯度:
对动量的运行过程说明如下:
- 在初始阶段,历史梯度信息会极大加速学习过程(比如n=2时);
- 当准备穿越函数波谷时,差的学习率会导致权重向相反方向更新,于是学习过程会发生回退,这时有动量项的帮助则有可能越过这个波谷;
- 最后在梯度几乎为0的时候,动量项的存在又可能会使它跳出当前局部最小值,于是可能找到更好的最优值点。
Nesterov accelerated gradient 是对动量法的一种改进,具体做法是:首先在之前的方向上迈一大步(棕色向量),之后计算在该点的梯度(红色向量),然后计算两个向量的和,得到的向量(绿色向量)作为最终优化方向。

4.2.8 AdaGrad
Adagrad同样是基于梯度的方法,对每个参数给一个学习率,因此对于常出现的权重可以给个小的更新,而不常出现的则给予大的更新,于是对于稀疏数据集就很有效,这个方法常用于大规模神经网络,Google的FTRL-Proximal也使用了类似方法,可参见:Google Ad Click Prediction a View from the Trenches和Follow-the-Regularized-Leader and Mirror Descent:
Equivalence Theorems and L1 Regularization。
这个方法有点像L2正则,其运作原理如下:
- 在学习前期,梯度比较小regularizer比较大,所以梯度会被放大;
- 在学习后期,梯度比较大regularizer比较小,所以梯度会被缩小。
但它的缺点是,当初始权重过大或经过几轮训练后会导致正则化太小,所以训练将被提前终止。
4.2.9 AdaDelta
Adadelta是对Adagrad的改进,解决了以下短板:
- 经过几轮的训练会导致正则化太小;
- 需要设置一个全局学习率;
- 当我们更新,等式左边和右边的单位不一致。
对于第一个短板,设置一个窗口,仅使用最近几轮的梯度值去更新正则项但计算 太复杂,所以使用类似动量法的策略:
对其他短板,AdaDelta通过以下方法解决。
对SGD与Momentum(里面的注释是理解这个变换的关键):
对牛顿法:
所以二阶方法有正确的单位且快于一阶方法。
来源于Becker 和 LeCuns' 的hessian估计法:
完整的算法描述如下:

对以上算法的比较如下:
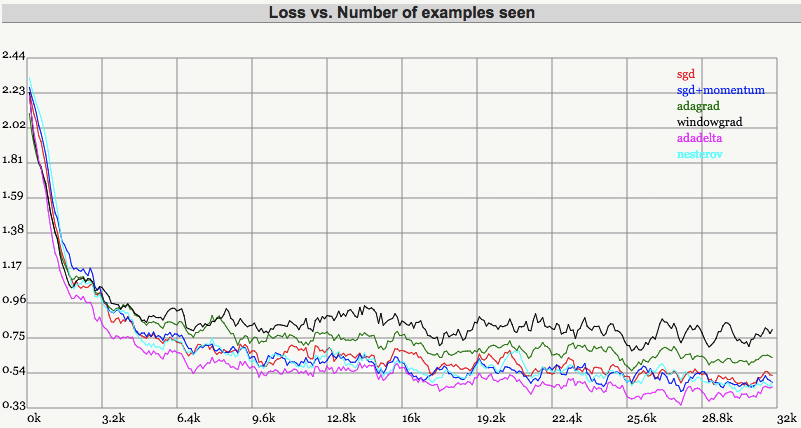

From SGD optimization on loss surface contours
4.2.10 Adam
Adam是对Adadelta的改进,原理如下:
算法伪代码如下:

4.3 并行SGD
SGD相对简单并且被证明有较好的收敛性质和精度,所以自然而然就想到将其扩展到大规模数据集上,就像Hadoop/Spark的基本框架是MapReduce,并行机器学习的常见框架有两种: AllReduce 和 Parameter Server(PS)。
4.3.1 AllReduce
AllReduce的思想来源于MPI,它可以被看做Reduce操作+Broadcast操作,例如:
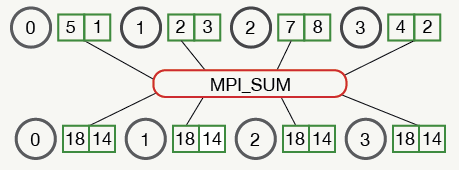
其他AllReduce的拓扑结构如下:

非常好的开源实现有John Langford的vowpal wabbit和陈天奇的Rabit(轻量级、可容错)。并行计算的关键之一是如何在大规模数据集下计算目标函数的梯度值,AllReduce框架很适合这种任务,比如:vw通过构建一个二叉树来管理机器节点,其中一个节点会被当做master,其他节点作为slave,master管理着slave并定期接受它们的心跳,每个子节点的计算结果会被其父节点收集,到达根节点后累加并广播到其所有子节点,一个简单的例子如下:
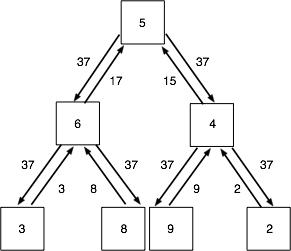
使用mini-batch的并行SGD算法伪代码如下:
4.3.2 参数服务器(Parameter Server)
参数服务器强调模型训练时参数的并行异步更新,最早是由Google的Jeffrey Dean团队提出,为了解决深度学习的参数学习问题,其基本思想是:将数据集划分为若干子数据集,每个子数据集所在的节点都运行着一个模型的副本,通过独立 部署的参数服务器组织模型的所有权重,其基本操作有:Fatching:每隔n次迭代,从参数服务器获取参数权重,Pushing:每隔m次迭代,向参数服务器推送本地梯度更新值,之后参数服务器会更新相关参数权重,其基本架构如下:
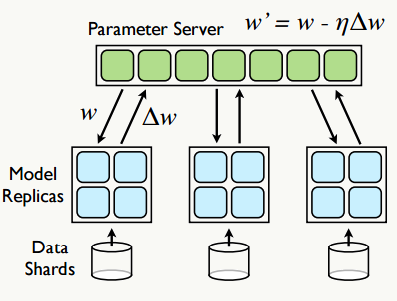
每个模型的副本都是,为减少通信开销,每个模型副本在迭代次后向参数服务器请求参数跟新,反过来本地模型每迭代次后向参数服务器推送一次梯度更新值,当然,为了折中速度和效果,梯度的更新可以选择异步也可以是同。
参数服务器是一个非常好的机器学习框架,尤其在深度学习的应用场景中,有篇不错的文章: 参数服务器——分布式机器学习的新杀器。开源的实现中比较好的是bosen项目和李沐的ps-lite(现已集成到DMLC项目中)。
下面是一个Go语言实现的多线程版本的参数服务器(用于Ftrl算法的优化),源码位置:Goline:
// data structure of ftrl solver.type FtrlSolver struct {Alpha float64 `json:"Alpha"`Beta float64 `json:"Beta"`L1 float64 `json:"L1"`L2 float64 `json:"L2"`Featnum int `json:"Featnum"`Dropout float64 `json:"Dropout"`N []float64 `json:"N"`Z []float64 `json:"Z"`Weights util.Pvector `json:"Weights"`Init bool `json:"Init"`}// data structure of parameter server.type FtrlParamServer struct {FtrlSolverParamGroupNum intLockSlots []sync.Mutexlog log4go.Logger}// fetch parameter group for update n and z value.func (fps *FtrlParamServer) FetchParamGroup(n []float64, z []float64, group int) error {if !fps.FtrlSolver.Init {fps.log.Error("[FtrlParamServer-FetchParamGroup] Initialize fast ftrl solver error.")return errors.New("[FtrlParamServer-FetchParamGroup] Initialize fast ftrl solver error.")}var start int = group * ParamGroupSizevar end int = util.MinInt((group+1)*ParamGroupSize, fps.FtrlSolver.Featnum)fps.LockSlots[group].Lock()for i := start; i < end; i++ {n[i] = fps.FtrlSolver.N[i]z[i] = fps.FtrlSolver.Z[i]}fps.LockSlots[group].Unlock()return nil}// fetch parameter from server.func (fps *FtrlParamServer) FetchParam(n []float64, z []float64) error {if !fps.FtrlSolver.Init {fps.log.Error("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.")return errors.New("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.")}for i := 0; i < fps.ParamGroupNum; i++ {err := fps.FetchParamGroup(n, z, i)if err != nil {fps.log.Error(fmt.Sprintf("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.", err.Error()))return errors.New(fmt.Sprintf("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.", err.Error()))}}return nil}// push parameter group for upload n and z value.func (fps *FtrlParamServer) PushParamGroup(n []float64, z []float64, group int) error {if !fps.FtrlSolver.Init {fps.log.Error("[FtrlParamServer-PushParamGroup] Initialize fast ftrl solver error.")return errors.New("[FtrlParamServer-PushParamGroup] Initialize fast ftrl solver error.")}var start int = group * ParamGroupSizevar end int = util.MinInt((group+1)*ParamGroupSize, fps.FtrlSolver.Featnum)fps.LockSlots[group].Lock()for i := start; i < end; i++ {fps.FtrlSolver.N[i] += n[i]fps.FtrlSolver.Z[i] += z[i]n[i] = 0z[i] = 0}fps.LockSlots[group].Unlock()return nil}// push weight update to parameter server.func (fw *FtrlWorker) PushParam(param_server *FtrlParamServer) error {if !fw.FtrlSolver.Init {fw.log.Error("[FtrlWorker-PushParam] Initialize fast ftrl solver error.")return errors.New("[FtrlWorker-PushParam] Initialize fast ftrl solver error.")}for i := 0; i < fw.ParamGroupNum; i++ {err := param_server.PushParamGroup(fw.NUpdate, fw.ZUpdate, i)if err != nil {fw.log.Error(fmt.Sprintf("[FtrlWorker-PushParam] Initialize fast ftrl solver error.", err.Error()))return errors.New(fmt.Sprintf("[FtrlWorker-PushParam] Initialize fast ftrl solver error.", err.Error()))}}return nil}// to do update for all weights.func (fw *FtrlWorker) Update(x util.Pvector,y float64,param_server *FtrlParamServer) float64 {if !fw.FtrlSolver.Init {return 0.}var weights util.Pvector = make(util.Pvector, fw.FtrlSolver.Featnum)var gradients []float64 = make([]float64, fw.FtrlSolver.Featnum)var wTx float64 = 0.for i := 0; i < len(x); i++ {item := x[i]if util.UtilGreater(fw.FtrlSolver.Dropout, 0.0) {rand_prob := util.UniformDistribution()if rand_prob < fw.FtrlSolver.Dropout {continue}}var idx int = item.Indexif idx >= fw.FtrlSolver.Featnum {continue}var val float64 = fw.FtrlSolver.GetWeight(idx)weights = append(weights, util.Pair{idx, val})gradients = append(gradients, item.Value)wTx += val * item.Value}var pred float64 = util.Sigmoid(wTx)var grad float64 = pred - yutil.VectorMultiplies(gradients, grad)for k := 0; k < len(weights); k++ {var i int = weights[k].Indexvar g int = i / ParamGroupSizeif fw.ParamGroupStep[g]%fw.FetchStep == 0 {param_server.FetchParamGroup(fw.FtrlSolver.N,fw.FtrlSolver.Z,g)}var w_i float64 = weights[k].Valuevar grad_i float64 = gradients[k]var sigma float64 = (math.Sqrt(fw.FtrlSolver.N[i]+grad_i*grad_i) - math.Sqrt(fw.FtrlSolver.N[i])) / fw.FtrlSolver.Alphafw.FtrlSolver.Z[i] += grad_i - sigma*w_ifw.FtrlSolver.N[i] += grad_i * grad_ifw.ZUpdate[i] += grad_i - sigma*w_ifw.NUpdate[i] += grad_i * grad_iif fw.ParamGroupStep[g]%fw.PushStep == 0 {param_server.PushParamGroup(fw.NUpdate, fw.ZUpdate, g)}fw.ParamGroupStep[g] += 1}return pred}
4.4 二阶优化方法
4.4.1 概览
大部分的优化算法都是基于梯度的迭代方法,其迭代式来源为泰勒展开式,迭代的一般式为:
其中 被称作步长,向量 被称作搜索方向,它一般要求是一个能使目标函数值(最小化问题)下降的方向,即满足:
进一步说, 的通项式有以下形式:
是一个对称非奇异矩阵(大家请问为什么?)。
- 在 Steepest Descent 法中 是一个单位矩阵;
- 在 Newton 法中, 是一个精确的Hessian 矩阵 ;
- 在 Quasi-Newton 法中, 是对Hessian矩阵的估计。
这类优化方法大体分两种,要么是先确定优化方向后确定步长(line search),要么是先确定步长后确定优化方向(trust region)。

以常用的line search为例,如何找到较好的步长 呢?好的步长它需要满足以下条件:
- Armijo 条件
充分下降条件,即要使步长在非精确一维搜索中能保证目标函数 下降,则它需要满足以下不等式:
一般选取一个较小的值,例如:。
Armijo 条件的几何解释如下:

常用求解方法如下:
- Curvature 条件
不只要求步长能使目标函数下降,还要求其程度,这个要求有点严格,一般只要做到Armijo条件就好了,不等式如下:

- Wolfe 条件
步长同时满足Armijo 条件和Curvature 条件则被称为其满足Wolfe 条件。
4.4.2 牛顿法(Newton Method)
- 以点开始寻找的解,在该点做切线,得到新的起点:
- 迭代,直到满足精度条件得到的最优解.
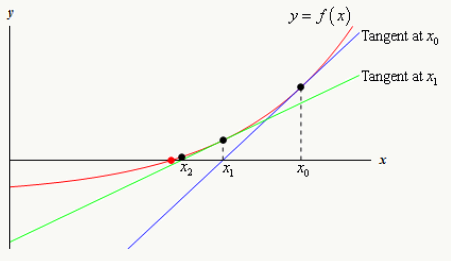
从泰勒展开式得到牛顿法的基本迭代式:
对牛顿法的改进之一是使用自适应步长 :

但总的来说牛顿法由于需要求解Hessian 矩阵,所以计算代价过大,对问题规模较大的优化问题力不从心。
4.4.3 拟牛顿法(Quasi-Newton Method)
为解决Hessian 矩阵计算代价的问题,想到通过一阶信息去估计它的办法,于是涌现出一类方法,其中最有代表性的是DFP和BFGS(L-BFGS),其原理如下:
一些有用的资料:
- 最优化相关书籍首推:《Numerical Optimization 2nd ed (Jorge Nocedal, Stephen J.Wright)》
- vw源码:vowpal_wabbit
- John Langford的博客
思考一个问题:为什么通常二阶优化方法收敛速度快于一阶方法?

5. 深度神经网络
深度学习是基于多层神经网络的一种对数据进行自动表征学习的框架,能使人逐步摆脱传统的人工特征提取过程,它的基础之一是distributed representation,读论文时注意以下概念区分:
- Distributional representation
Distributional representation是基于某种分布假设和上下文共现的一类表示方法,比如,对于词的表示来说:有相似意义的词具有相似的分布。
从技术上讲这类方法的缺点是:通常对存储敏感,在representation上也不高效,但是优点是:算法相对简单,甚至像LSA那样简单的线性分解就行。
几类常见的Distributional representation模型:
- Distributed representation
Distributed representation是对实体(比如:词、车系编号、微博用户id等等)稠密、低维、实数的向量表示,也就是常说的embedding,它不需要做分布假设,向量的每个维度代表实体在某个空间下的隐含特征。
从技术上讲它的缺点是:计算代价较高,算法往往不简单直接,通常通过神经网络/深度神经网络实现,优点是:对原始信息的有效稠密压缩表示,不仅仅是考虑“共现”,还会考虑其他信息,比如:“时序”等。
几类常见的Distributed representation模型:
- Collobert and Weston embeddings
- HLBL embeddings
关于Distributional representation和Distributed representation以及几个相关概念,看论文Word representations:
A simple and general method for semi-supervised learning即可明了。
5.1 反向传播
反向传播是神经网络参数学习的必备工具,以经典的多层前向神经网络为例:
整个网络可以认为是以下结构的重复,其中n代表处于第几层:

假设:
1、当为输出层时,整个网络的误差表示为:,其中为期望输出;
2、任意层的激活函数表示为;
3、第层输入为上一层输出,该层权重为,则:
该层中间输出为:
该层输出为:。
那么误差反向传播原理为:
其中,定义为误差反向传播时第层某个节点的“误差敏感度”。
参数学习过程为:,其中的讨论前文已经做过不在赘述,应用导数的链式传导原理,所有层的权重都将得到更新。
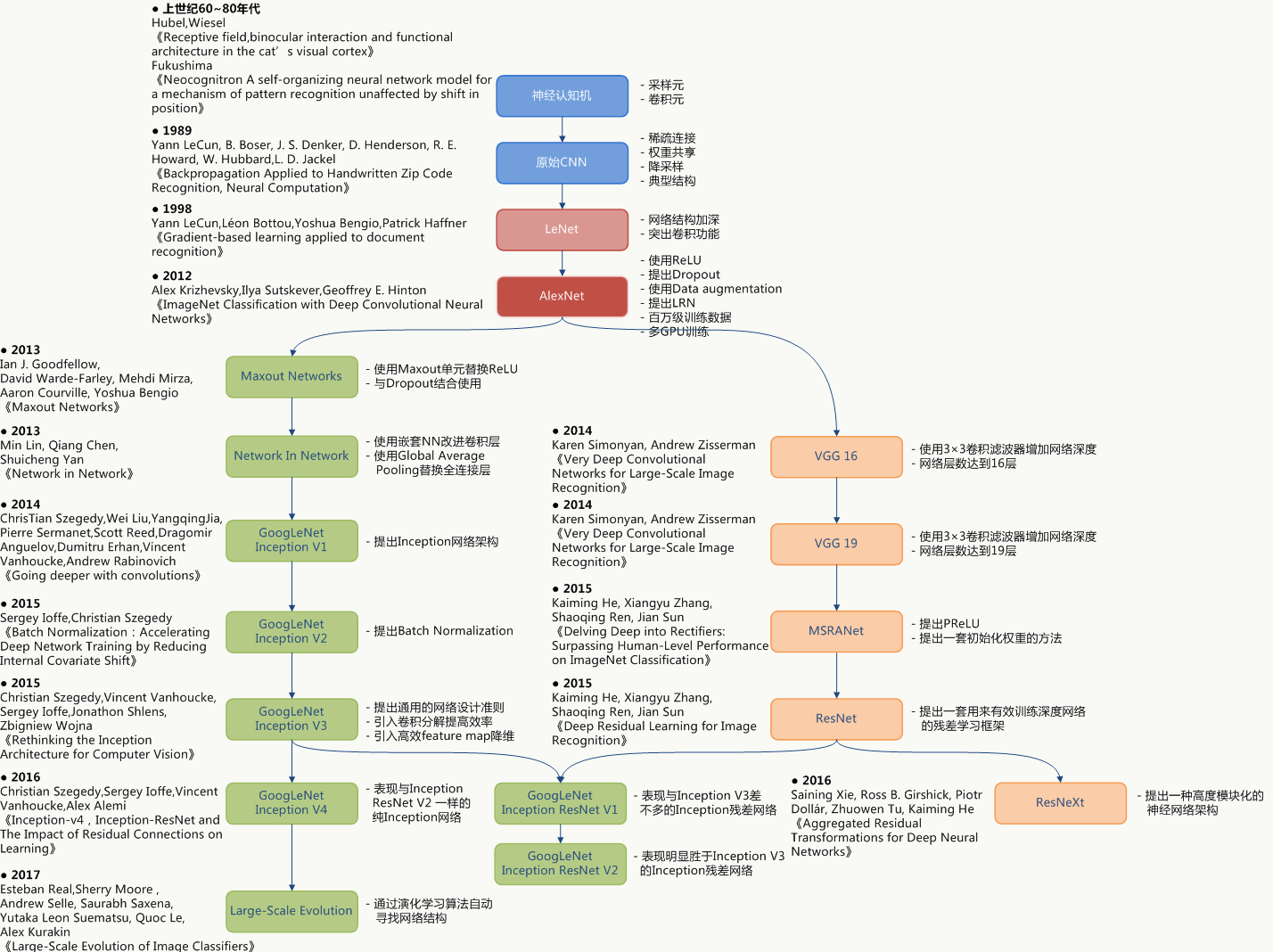
5.2 卷积网络结构演化史
网络结构的发展历程更像是一个实验科学的过程,人们通过不断地尝试和实验来得到与验证各种网络结构。
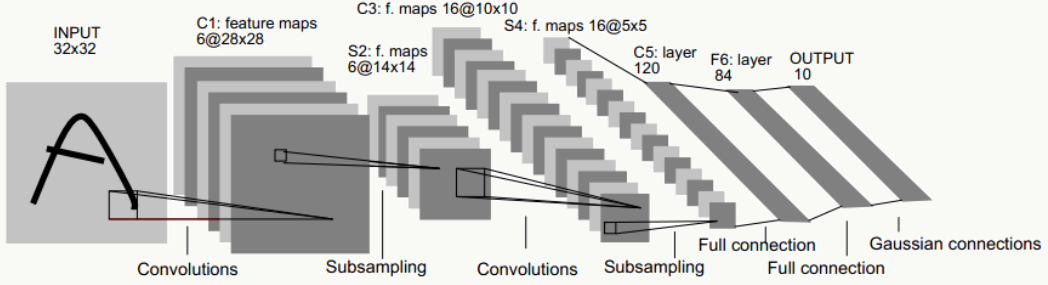
5.3 CNN基本原理
卷积神经网络是我认为非常好用的一类神经网络结构,当数据具有局部相关性时是一种比较好选择,在图像、自然语言处理、棋类竞技、新药配方研制等方面有广泛应用。比如,经典的LeNet-5网络结构:
5.3.1 Sigmoid激活函数
激活函数是神经网络必备工具,而Sigmoid激活函数是早期神经网络最普遍的选择。Sigmoid函数是类神奇的函数,广义上所有形为“S”的函数都可叫做Sigmoid函数,从早期的感知机模型中Sigmoid函数就被用来模拟生物细胞的激活反应,所以又被叫做激活函数,从数学角度看,Sigmoid函数对中间信号增益较大而对两侧信号增益小,所以在信号的特征空间映射上效果好。
从生物角度看,中间部分类似神经元的兴奋状态而两侧类似神经元的抑制状态,所以神经网络在学习时,区分度大的重要特征被推向中间而次要特征被推向两侧。

Logistic函数最早是Pierre François Verhulst在研究人口增长问题时提出的,由于其强悍的普适性(从概率角度的理解见前面对Logistic Regression的讲解)而被广泛应用(在传统机器学习中派生出Logistic Regression),但是实践中,它作为激活函数有两个重要缺点:
- 梯度消失问题(Vanishing Gradient Problem)
从前面BP的推导过程可以看出:误差从输出层反向传播时,在各层都要乘以当前层的误差敏感度,而误差敏感度又与有关系,由于 且,可见误差会从输出层开始呈指数衰减,这样即使是一个4层神经网络可能在靠近输入层的部分都已经无法学习了,更别说“更深”的网络结构了,Hinton提出的逐层贪心预训练方法在一定程度缓解了这个问题但没有真正解决。- 激活输出非0均值问题
假设一个样本一个样本的学习,当前层输出非0均值信号给下一层神经元时:如果输入值大于0,则后续通过权重计算出的梯度也大于0,反之亦然,这会导致整个网络训练速度变慢,虽然采用batch的方式训练会缓解这个问题,但毕竟在训练中是拖后腿的,所以Yann LeCun在《Efficient BackPro》一文中也提到了解决的trick。
Tanh函数是另外一种Sigmoid函数,它的输出是0均值的,Yann LeCun给出的一种经验激活函数形式为:
CNN的典型特点是:局部相关性(稀疏连接)、权重与偏置共享及采样,一套典型的结构由输入层、卷积层、采样层、全连接层、输出层组成。
5.3.2 输入层
CNN的输入层一般为一个n维矩阵,可以是图像、向量化后的文本等等。比如一幅彩色图像:

5.3.3 卷积层
卷积操作在数学上的定义如下:

但对于我们正在讲的CNN中的卷积并不是严格意义的卷积(Convolution)操作,而是变体Cross-Correlation:
其中为的Complex Conjugate。
卷积层的作用:当数据及其周边有局部关联性时可以起到滤波、去噪、找特征的作用;每一个卷积核做特征提取得到结果称为feature map,利用不同卷积核做卷积会得到一系列feature map,这些feature map大小为长宽深度(卷积核的个数)并作为下一层的输入。
以图像处理为例,卷积可以有至少3种理解:
- 平滑
当设置一个平滑窗口后(如3*3),除了边缘外,图像中每个像素点都是以某个点为中心的窗口中各个像素点的加权平均值,这样由于每个点都考虑了周围若干点的特征,所以本质上它是对像素点的平滑。- 滤波
将信号中特定波段频率过滤的操作,是防干扰的一类方法,如果滤波模板(卷积核)是均匀分布,那么滤波就是等权滑动平均,如果模板是高斯分布,那么滤波就是权重分布为钟形的加权滑动平均,不同的模板能得到图像的不同滤波后特征。- 投影
卷积是个内积操作,如果把模板(卷积核)拉直后看做一个基向量,那么滑动窗口每滑动一次就会产生一个向量,把这个向量往基向量上做投影就得到feature map,如果模板有多个,则组成一组基,投影后得到一组feature map。
卷积和权重共享可以在保证效果的基础上大大降低模型复杂度,说明如下:
输入层为5*5矩阵,卷积核为3*3矩阵,隐藏层为:3*3矩阵:
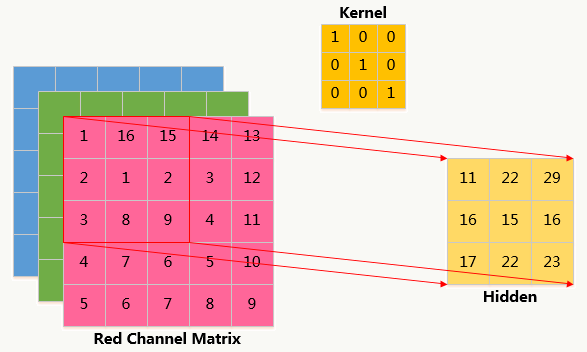
- 采用全连接神经网络
参数个数为:5*5*9=225
- 采用局部连接神经网络
隐藏层只与3*3大小的局部像素相连,参数个数为:3*3*9=81

- 采用局部连接权重共享神经网络
所有隐藏层共享权值,且权值为卷积核,参数个数为:3*3*1=9,共享权重的本质含义是对图片某种统计模式的描述,这种模式与图像位置无关。
5.3.4 Zero-Padding
Zero-Padding是一种影响输出层构建的方法,思路比较简单:把输入层边界外围用0填充,当我们希望输出空间维度和输入空间维度大小一样时可以用此方法,例如下图:当输入为4*4,卷积核为3*3时,利用Zero-Padding可以让输出矩阵也是4*4。
Zero-Padding一方面让你的网络结构设计更灵活,一方面还可以保留边界信息,不至于随着卷积的过程信息衰减的太快。
大家如果使用Tenserflow会知道它的padding参数有两个值:SAME,代表做类似上图的Zero padding,使得输入的feature map和输出的feature map有相同的大小;VALID,代表不做padding操作。
5.3.5 采样层(pooling)
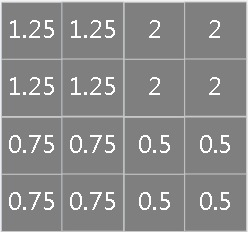
通过卷积后。模型的参数规模大幅下降,但对于复杂网络参数个数依然很多,且容易造成过拟合,所以一种自然的方式就是做下采样,采样依然采用滑动窗口方式,常用采样有Max-Pooling(将Pooling窗口中的最大值作为采样值)和Mean-Pooling(将Pooling窗口中的所有值相加取平均,用平均值作为采样值),一个例子如下:

实际上也有人尝试抛弃Pooling层而采用Stride大于1的卷积层,例如,以下例子中Stride=2,效果类似:

另外,如果卷积层的下一层是pooling层,那么每个feature map都会做pooling,与人类行为相比,pooling可以看做是观察图像某个特征区域是否有某种特性,对这个区域而言不关心这个特性具体表现在哪个位置(比如:看一个人脸上某个局部区域是否有个痘痘)。
5.3.6 全连接样层
全连接层一般是CNN的最后一层,它是输出层和前面若干层的过渡层,用来组织生成特定节点数的输出层。
5.3.7 参数求解
对于多分类任务,假设损失函数采用平方误差:
下面以一个样本为例推导CNN的原理:
全连接层
为方便,假设偏置项都被放入权重项中,则对全连接层来说第层与第层的关系为:
反向传播定义为:
卷积层
由于卷积操作、共享权重的存在,这一中间层的输出会被定义为:
其中:为当前卷积层,为卷积层某个特征,为卷积核,为偏置。
1、当前层为卷积层且下一层为下采样层(pooling)时,反向传播的原理为:。
下面解释和操作:
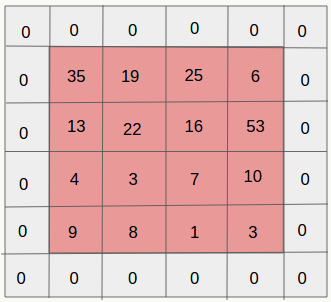
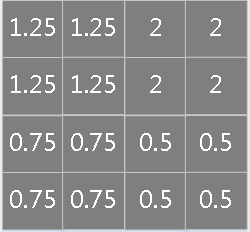
卷积层在卷积窗口内的像素与下采样层的像素是多对一的关系,即下采样层的一个神经元节点对应的误差灵敏度对应于上一层卷积层的采样窗口大小的一块像素,下采样层每个节点的误差敏感值由上一层卷积层中采样窗口中节点的误差敏感值联合生成,因此,为了使下采样层的误差敏感度窗口大小和卷积层窗口(卷积核)大小一致,就需要对下采样层的误差敏感度做上采样操作,相当于是某种逆映射操作,对于max-pooling、mean-polling或者各自的加权版本来说处理方法类似:

第层为卷积层和第层为下采样层,由于二者维度上的不一致,需要做以下操作来分配误差敏感项,以mean-pooling为例,假设卷积层的核为4×4,pooling的窗口大小为2×2,为简单起见,pooling过程采用每次移动一个窗口大小的方式,显然pooling后的矩形大小为2×2,如果此时pooling后的矩形误差敏感值如下:

操作,按照顺序对每个误差敏感项在水平和垂直方向各复制出口大小次:

做误差敏感项归一化,即上面公式里的取值,需要注意,如果采用的是加权平均的话,则窗口内误差敏感项权重是不一样的(不像现在这样是等权的)。
2、当前层为卷积层,与其相连的上一层相关核权重及偏置计算如下:
假设通过来标识卷积层任意位置,则:
假设第层输入矩阵大小为5×5:

第层误差敏感项矩阵大小为4×4:
则核的偏导为:

偏置的偏导为误差敏感项矩阵元素之和:
3、当前层为下采样(pooling)层且下一层为卷积层时反向传播的原理如下:
其中运算符号为卷积操作。一个简单的例子如下:
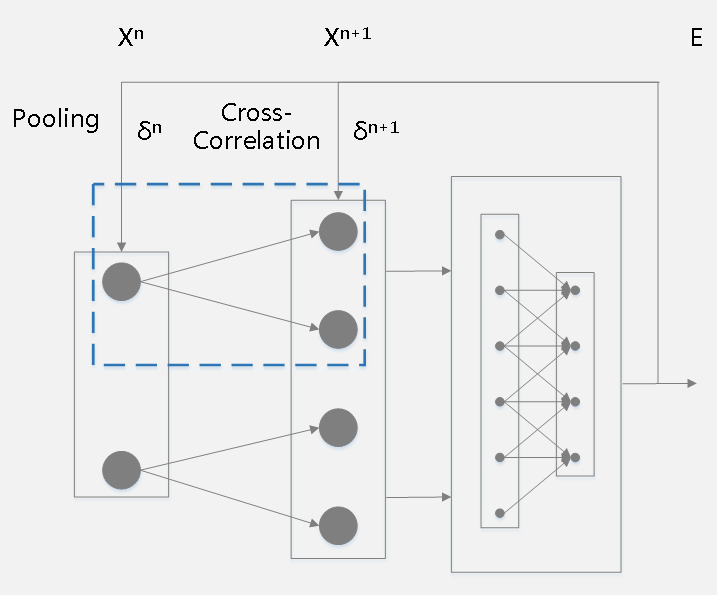
假设下采样(pooling)层处于第层且feature map大小为3×3,其下一层为卷积层处于第层且通过两个2×2卷积核得到了两个feature map(蓝色虚框框住的网络结构)。
2个卷积核为:

假设第层对两个卷积核的误差敏感项已经计算好:

则对第层的误差敏感项做zero-padding并利用卷积操作(注意:会对卷积核做180度旋转)可以得到第层的误差敏感项,过程如下:

假设,则第层的误差敏感项为:

5.3.8 CNN在NLP领域应用实例
在NLP领域,文本分类是一类常用应用,传统方法是人工提取类似n-gram的各种特征以及各种交叉组合。文本类似图像天然有一种局部相关性,想到利用CNN做一种End to End的分类器,把提特征的工作交给模型。
对于一个句子,它是一维的,无法像图像一样直接处理,因此需要通过distributed representation learning得到词向量,或者在模型第一层增加一个embedding层起到类似作用,这样一个句子就变成二维的了:
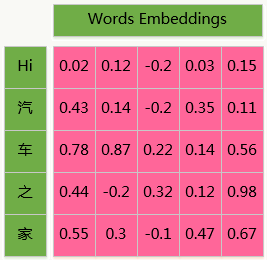
我们用Tensorflow为后端的Keras搭建这个模型:
前面说到可以使用两种方法得到词向量:
1、预先训练好的结果,例如使用已经训练好的word2vec模型,相关资料:Using pre-trained word embeddings in a Keras model;
2、模型第一层增加embedding层,我们使用这种方式。
网络结构如下:
def build_embedding_cnn(max_caption_len, vocab_size):# 二分类问题nb_classes = 2# 词向量维度word_dim = 256# 卷积核个数nb_filters = 64# 使用max pooling的窗口大小nb_pool = 2# 卷积核大小kernel_size = 5# 模型结构定义model = Sequential()# 第一层是embedding层model.add(Embedding(output_dim=word_dim, input_dim=vocab_size, input_length=max_caption_len, name='main_input'))model.add(Dropout(0.5))# 第二层是激活函数为Relu的卷积层model.add(Convolution1D(nb_filters, kernel_size))model.add(Activation('relu'))# 第三层是max pooling层model.add(MaxPooling1D(nb_pool))model.add(Dropout(0.5))model.add(Flatten())# 第四层是全连接层model.add(Dense(256))model.add(Activation('relu'))model.add(Dropout(0.3))# 第五层是输出层model.add(Dense(nb_classes))model.add(Activation('softmax'))# 损失函数采用交叉熵,优化算法采用adadeltamodel.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])return model
max_caption_len=100时的网络结构如下:

详细代码可以参见GitHub:Cnn-tc-Keras。
5.4 LeNet-5
最初的网络结构来源于论文:《Gradient-based learning applied to document recognition》(论文里使用原始未做规范化的数据时,INPUT是32×32的),我用以下结构做说明:

LeNet-5一共有8层:1个输入层+3个卷积层(C1、C3、C5)+2个下采样层(S2、S4)+1个全连接层(F6)+1个输出层,每层有多个feature map(自动提取的多组特征)。
5.4.1 输入层
采用keras自带的MNIST数据集,输入像素矩阵为28×28的单通道图像数据。
5.4.2 C1卷积层
由6个feature map组成,每个feature map由5×5卷积核生成(feature map中每个神经元与输入层的5×5区域像素相连),考虑每个卷积核的bias,该层需要学习的参数个数为:(5×5+1)×6=156个,神经元连接数为:156×24×24=89856个。
5.4.3 S2下采样层
该层每个feature map一一对应上一层的feature map,由于每个单元的2×2感受野采用不重叠方式移动,所以会产生6个大小为12×12的下采样feature map,如果采用Max Pooling/Mean Pooling,则该层需要学习的参数个数为0个(如果采用非等权下采样——即采样核有权重,则该层需要学习的参数个数为:(2×2+1)×6=30个),神经元连接数为:30×12×12=4320个。
5.4.4 C3卷积层
这层略微复杂,S2神经元与C3是多对多的关系,比如最简单方式:用S2的所有feature map与C3的所有feature map做全连接(也可以对S2抽样几个feature map出来与C3某个feature map连接),这种全连接方式下:6个S2的feature map使用6个独立的5×5卷积核得到C3中1个feature map(生成每个feature map时对应一个bias),C3中共有16个feature map,所以该层需要学习的参数个数为:(5×5×6+1)×16=2416个,神经元连接数为:2416×8×8=154624个。
5.4.5 S4下采样层
同S2,如果采用Max Pooling/Mean Pooling,则该层需要学习的参数个数为0个,神经元连接数为:(2×2+1)×16×4×4=1280个。
5.4.6 C5卷积层
类似C3,用S4的所有feature map与C5的所有feature map做全连接,这种全连接方式下:16个S4的feature map使用16个独立的1×1卷积核得到C5中1个feature map(生成每个feature map时对应一个bias),C5中共有120个feature map,所以该层需要学习的参数个数为:(1×1×16+1)×120=2040个,神经元连接数为:2040个。
5.4.7 F6全连接层
将C5层展开得到4×4×120=1920个节点,并接一个全连接层,考虑bias,该层需要学习的参数和连接个数为:(1920+1)*84=161364个。
5.4.8 输出层
该问题是个10分类问题,所以有10个输出单元,通过softmax做概率归一化,每个分类的输出单元对应84个输入。
Minist(Modified NIST)数据集下使用LeNet-5的训练可视化:

可以看到其实全连接层之前的各层做的就是特征提取的事儿,且比较通用,对于标准化实物(人、车、花等等)可以复用,后面会单独介绍模型的fine-tuning。
5.4.9 LeNet-5代码实践
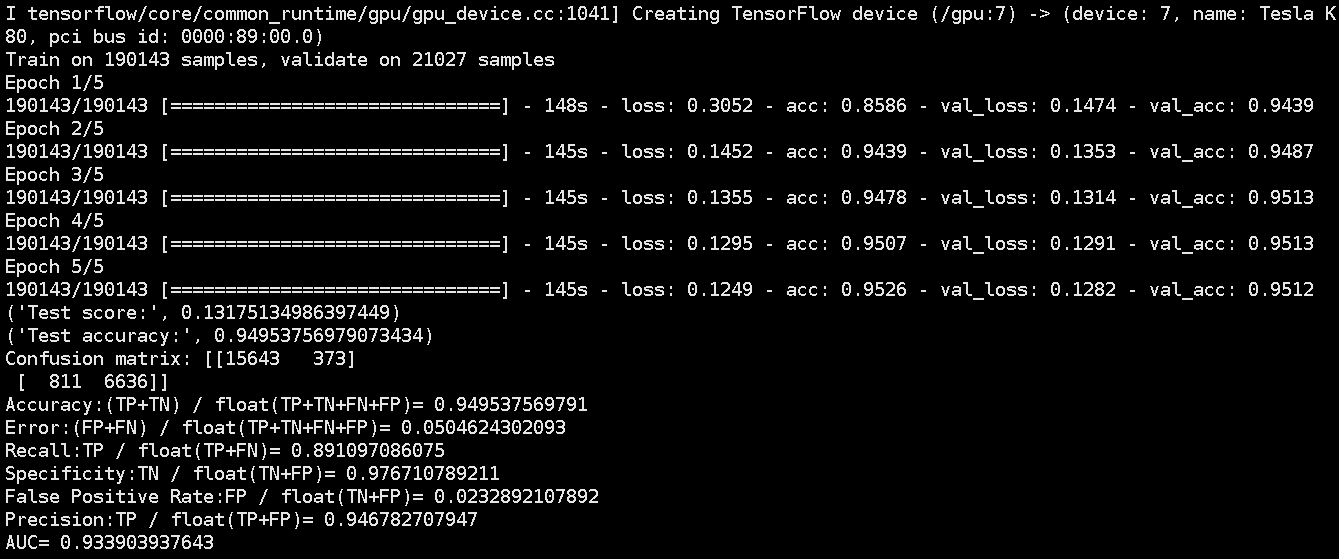
import copyimport numpy as npimport pandas as pdimport matplotlibmatplotlib.use("Agg")import matplotlib.pyplot as pltfrom matplotlib.pyplot import plot,savefigfrom keras.datasets import mnist, cifar10from keras.models import Sequential, Graphfrom keras.layers.core import Dense, Dropout, Activation, Flatten, Reshapefrom keras.optimizers import SGD, RMSpropfrom keras.utils import np_utilsfrom keras.regularizers import l2from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D, AveragePooling2Dfrom keras.callbacks import EarlyStoppingfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.layers.normalization import BatchNormalizationimport tensorflow as tftf.python.control_flow_ops = tffrom PIL import Imagedef build_LeNet5():model = Sequential()model.add(Convolution2D(6, 5, 5, border_mode='valid', input_shape = (28, 28, 1), dim_ordering='tf'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Activation("relu"))model.add(Convolution2D(16, 5, 5, border_mode='valid'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Activation("relu"))model.add(Convolution2D(120, 1, 1, border_mode='valid'))model.add(Flatten())model.add(Dense(84))model.add(Activation("sigmoid"))model.add(Dense(10))model.add(Activation('softmax'))return modelif __name__=="__main__":from keras.utils.visualize_util import plotmodel = build_LeNet5()model.summary()plot(model, to_file="LeNet-5.png", show_shapes=True)(X_train, y_train), (X_test, y_test) = mnist.load_data()X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255Y_train = np_utils.to_categorical(y_train, 10)Y_test = np_utils.to_categorical(y_test, 10)# trainingmodel.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])batch_size = 128nb_epoch = 1model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,verbose=1, validation_data=(X_test, Y_test))score = model.evaluate(X_test, Y_test, verbose=0)print('Test score:', score[0])print('Test accuracy:', score[1])y_hat = model.predict_classes(X_test)test_wrong = [im for im in zip(X_test,y_hat,y_test) if im[1] != im[2]]plt.figure(figsize=(10, 10))for ind, val in enumerate(test_wrong[:100]):plt.subplots_adjust(left=0, right=1, bottom=0, top=1)plt.subplot(10, 10, ind + 1)im = 1 - val[0].reshape((28,28))plt.axis("off")plt.text(0, 0, val[2], fontsize=14, color='blue')plt.text(8, 0, val[1], fontsize=14, color='red')plt.imshow(im, cmap='gray')savefig('error.jpg')
网络结构
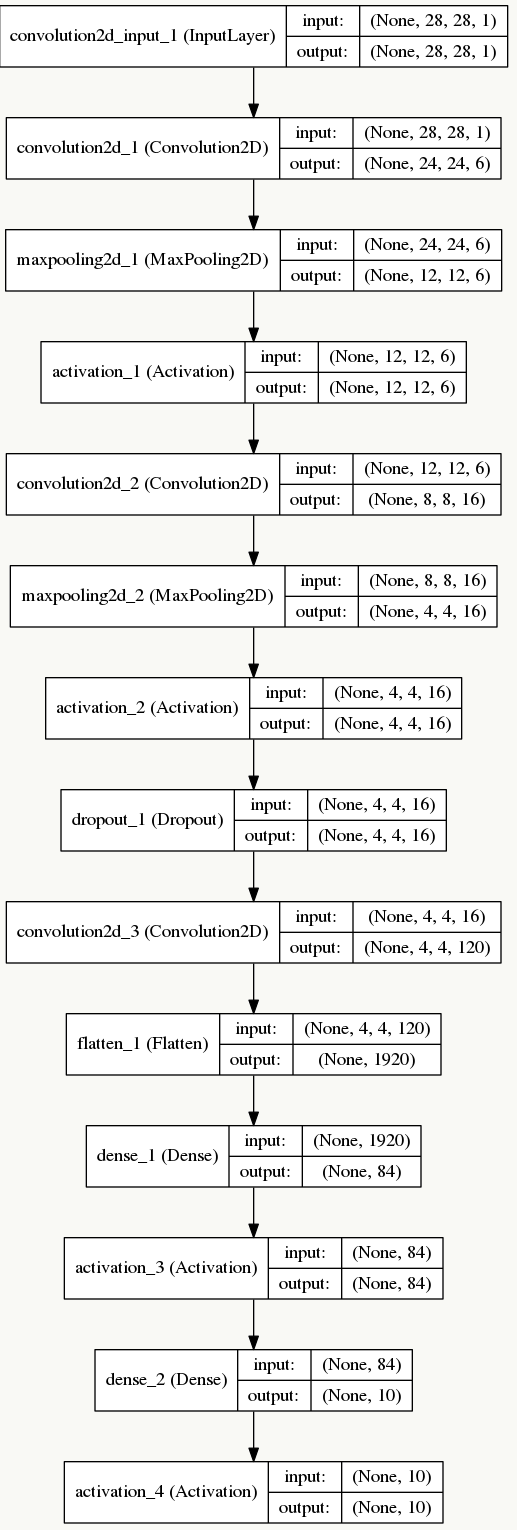
错误分类可视化

5.5 AlexNet
AlexNet在ILSVRC-2012的比赛中获得top5错误率15.3%的突破(第二名为26.2%),其原理来源于2012年Alex的论文《ImageNet Classification with Deep Convolutional Neural Networks》,这篇论文是深度学习火爆发展的一个里程碑和分水岭,加上硬件技术的发展,深度学习还会继续火下去。
5.5.1 网络结构分析
由于受限于当时的硬件设备,AlexNet在GPU粒度都做了设计,当时的GTX 580只有3G显存,为了能让模型在大量数据上跑起来,作者使用了两个GPU并行,并对网络结构做了切分,如下:

输入层
输入为224×224×3的三通道RGB图像,为方便后续计算,实际操作中通过padding做预处理,把图像变成227×227×3。
C1卷积层
该层由:卷积操作 + Max Pooling + LRN(后面详细介绍它)组成。
(1)、卷积层:由96个feature map组成,每个feature map由11×11卷积核在stride=4下生成,输出feature map为55×55×48×2,其中55=(227-11)/4+1,48为分在每个GPU上的feature map数,2为GPU个数;
(2)、激活函数:采用ReLU;
(3)、Max Pooling:采用stride=2且核大小为3×3(文中实验表明采用2×2的非重叠模式的Max Pooling相对更容易过拟合,在top 1和top 5下的错误率分别高0.4%和0.3%),输出feature map为27×27×48×2,其中27=(55-3)/2+1,48为分在每个GPU上的feature map数,2为GPU个数;
(4)、LRN:邻居数设置为5做归一化。
最终输出数据为归一化后的:27×27×48×2。C2卷积层
该层由:卷积操作 + Max Pooling + LRN组成
(1)、卷积层:由256个feature map组成,每个feature map由5×5卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为2的padding,输出feature map为27×27×128×2,其中27=(27-5+2×2)/1+1,128为分在每个GPU上的feature map数,2为GPU个数;
(2)、激活函数:采用ReLU;
(3)、Max Pooling:采用stride=2且核大小为3×3,输出feature map为13×13×128×2,其中13=(27-3)/2+1,128为分在每个GPU上的feature map数,2为GPU个数;
(4)、LRN:邻居数设置为5做归一化。
最终输出数据为归一化后的:13×13×128×2。C3卷积层
该层由:卷积操作 + LRN组成(注意,没有Pooling层)
(0)、输入为13×13×256,因为这一层两个GPU会做通信(途中虚线交叉部分)
(1)、卷积层:之后由384个feature map组成,每个feature map由3×3卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为1的padding,输出feature map为13×13×192×2,其中13=(13-3+2×1)/1+1,192为分在每个GPU上的feature map数,2为GPU个数;
(2)、激活函数:采用ReLU;
最终输出数据为归一化后的:13×13×192×2。C4卷积层
该层由:卷积操作 + LRN组成(注意,没有Pooling层)
(1)、卷积层:由384个feature map组成,每个feature map由3×3卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为1的padding,输出feature map为13×13×192×2,其中13=(13-3+2×1)/1+1,192为分在每个GPU上的feature map数,2为GPU个数;
(2)、激活函数:采用ReLU;
最终输出数据为归一化后的:13×13×192×2。C5卷积层
该层由:卷积操作 + Max Pooling组成
(1)、卷积层:由256个feature map组成,每个feature map由3×3卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为1的padding,输出feature map为13×13×128×2,其中13=(13-3+2×1)/1+1,128为分在每个GPU上的feature map数,2为GPU个数;
(2)、激活函数:采用ReLU;
(3)、Max Pooling:采用stride=2且核大小为3×3,输出feature map为6×6×128×2,其中6=(13-3)/2+1,128为分在每个GPU上的feature map数,2为GPU个数.
最终输出数据为归一化后的:6×6×128×2。F6全连接层
该层为全连接层 + Dropout
(1)、使用4096个节点;
(2)、激活函数:采用ReLU;
(3)、采用参数为0.5的Dropout操作
最终输出数据为4096个神经元节点。F7全连接层
该层为全连接层 + Dropout
(1)、使用4096个节点;
(2)、激活函数:采用ReLU;
(3)、采用参数为0.5的Dropout操作
最终输出为4096个神经元节点。F8输出层
该层为全连接层 + Softmax
(1)、使用1000个输出的Softmax
最终输出为1000个分类。
AlexNet的亮点如下:
5.5.2 ReLu激活函数
AlexNet引入了ReLU激活函数,这个函数是神经科学家Dayan、Abott在《Theoretical Neuroscience》一书中提出的更精确的激活模型:

其中:
详情请阅读书中2.2 Estimating Firing Rates这一节。新激活模型的特点是:
- 激活稀疏性(小于1时为0)
- 单边抑制(不像Sigmoid是双边的)
- 宽兴奋边界,非饱和性(ReLU导数始终为1),很大程度缓解了梯度消失问题
1、 原始ReLu
在这些前人研究的基础上(可参见 Hinton论文:《Rectified Linear Units Improve Restricted Boltzmann Machines》),类似Eq.2.9的新激活函数被引入:
这个激活函数把负激活全部清零(模拟上面提到的稀疏性),这种做法在实践中即保留了神经网络的非线性能力,又加快了训练速度。
但是这个函数也有缺点:
- 在原点不可微
反向传播的梯度计算中会带来麻烦,所以Charles Dugas等人又提出Softplus来模拟上述ReLu函数(可视作其平滑版):
实际上它的导数就是一个logistic-sigmoid函数:
- 过稀疏性
当学习率设置不合理时,即使是一个很大的梯度,在经过ReLu单元并更新参数后该神经元可能永不被激活。
2、 Leaky ReLu
为了解决上述过稀疏性导致的大量神经元不被激活的问题,Leaky ReLu被提了出来:
其中是人工指定的较小值(如:0.1),它一定程度保留了负激活信息。
3、Parametric ReLu
上述值是可以不通过人为指定而学习出的,于是Parametric ReLu被提了出来:
利用误差反向传播原理:
当采用动量法更新权重:
详情请阅读Kaiming He等人的《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》论文。
4、Randomized ReLu
Randomized ReLu 可以看做是leaky ReLu的随机版本,原理是:假设
其中:
5.5.3 Local Response Normalization
LRN利用相邻feature map做特征显著化,文中实验表明可以降低错误率,公式如下:
公式的直观解释如下:
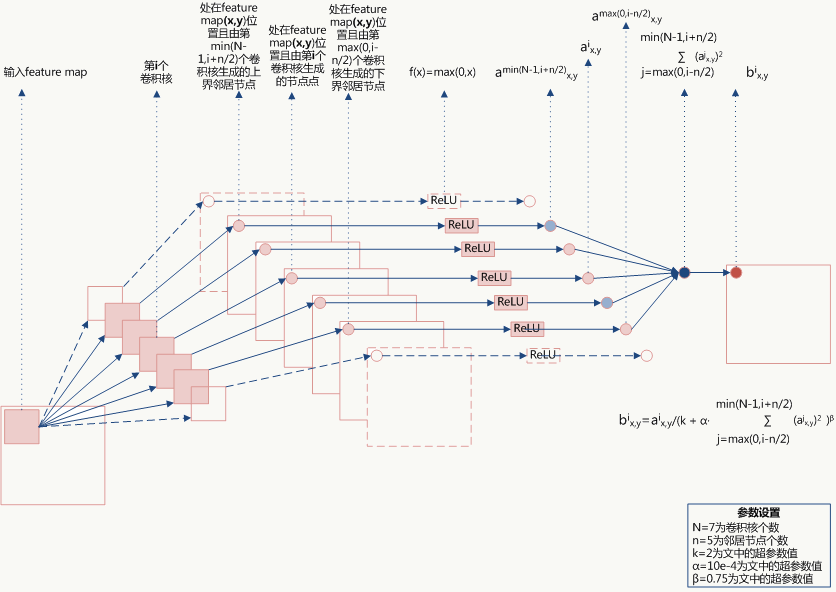
由于都是经过了ReLU的输出,所以一定是大于0的,函数:取文中参数的图形如下(横坐标为):

当值较小时,即当前节点和其邻居节点输出值差距不明显且大家的输出值都不太大,可以认为此时特征间竞争激烈,该函数可以使原本差距不大的输出产生显著性差异且此时函数输出不饱和;当值较大时,说明特征本身有显著性差别但输出值太大容易过拟合,该函数可以令最终输出接近0从而缓解过拟合提高了模型泛化性。
5.5.4 Overlapping Pooling
如其名,实验表明有重叠的抽样可以提高泛化性。
5.5.5 Dropout
Dropout是文章亮点之一,属于提高模型泛化性的方法,操作比较简单,以一定概率随机让某些神经元输出设置为0,既不参与前向传播也不参与反向传播,也可以从正则化角度去看待它。
- 从模型集成的角度看
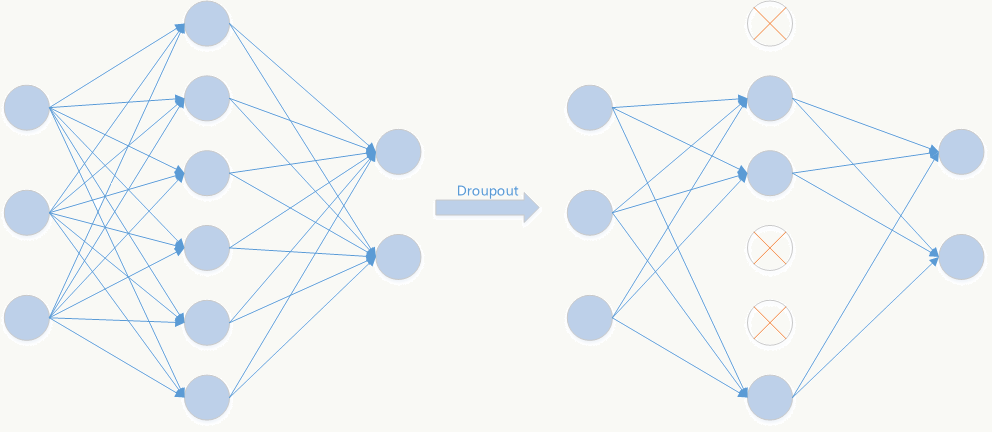
无Dropout网络:
有Dropout网络:
其中为Dropout的概率,为所在层。
它是极端情况下的Bagging,由于在每步训练中,神经元会以某种概率随机被置为无效,相当于是参数共享的新网络结构,每个模型为了使损失降低会尽可能学最“本质”的特征,“本质”可以理解为由更加独立的、和其他神经元相关性弱的、泛化能力强的神经元提取出来的特征;而如果采用类似SGD的方式训练,每步迭代都会选取不同的数据集,这样整个网络相当于是用不同数据集学习的多个模型的集成组合。
- 从数据扩充(Data Augmentation)的角度看
机器学习学的就是原始数据的数据分布,而泛化能力强的模型自然不能只针对训练集上的数据正确映射输出,但要想学到好的映射又需要数据越多越好,很多论文已经证明,带领域知识的数据扩充能够提高训练数据对原始真实分布的覆盖度,从而能够提高模型泛化效果。
《Dropout as Data Augmentation》将Dropout看做数据扩充的方法,文中证明了:总能找到一个样本,使得原始神经网络的输出与Dropout神经网络的输出一致(projecting noise back into the input space)。
用论文中符号说明如下:
其中:为维空间的输入,为从维空间到维空间的仿射映射,为激活函数,为Dropout版激活函数,,为rectifier函数(比如:ReLU):
对任何一个隐层,假设都存在一个输入,满足:
注:式子左边为原始神经网络某层,右边为Dropout神经网络某层。
采用SGD优化下面目标函数,总能找到一个输入:
对于一个层的神经网络:
原始神经网络表示为:
Dropout神经网络表示为:
采用SGD优化下面目标函数,总能找到一系列输入:
文中附录部分证明不可能找到唯一序列使得:
所以每次Dropout都是在生成新的样本。
5.5.6 数据扩充
- 基本方法
正如前面所说,数据扩充本质是减少过拟合的方法,AlexNet使用的方法计算量较小,所以也不用存储在磁盘,代码实现时,当GPU在训练前一轮图像时,后一轮的图像扩充在CPU上完成,扩充使用了两种方法:
1、图像平移和图像反射(关于某坐标轴对称);
2、通过ImageNet训练集做PCA,用PCA产生的特征值和特征向量及期望为0标准差为0.1的高斯分布改变原图RGB三个通道的强度,该方法使得top-1错误率降低1%。
5.5.7 多GPU训练
作者使用GTX 580来加速训练,但受限于当时硬件设备的发展,作者需要对网络结构做精细化设计,甚至需要考虑两块GPU之间如何及何时通信,现在的我们比较幸福,基本不用考虑这些。
5.5.8 AlexNet代码实践
使用CIFAR-10标准数据集,由6w张32×32像素图片组成,一共10个分类。像这样:

代码实现:
# -*- coding: utf-8 -*-import copyimport numpy as npimport pandas as pdimport matplotlibmatplotlib.use("Agg")import matplotlib.pyplot as pltimport osfrom matplotlib.pyplot import plot,savefigfrom scipy.misc import toimagefrom keras.datasets import cifar10,mnistfrom keras.models import Sequential, Graphfrom keras.layers.core import Dense, Dropout, Activation, Flatten, Reshapefrom keras.optimizers import SGD, RMSpropfrom keras.utils import np_utilsfrom keras.regularizers import l2from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D, AveragePooling2Dfrom keras.callbacks import EarlyStoppingfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.layers.normalization import BatchNormalizationfrom keras.callbacks import ModelCheckpointfrom keras import backend as Kimport tensorflow as tftf.python.control_flow_ops = tffrom PIL import Imagedef data_visualize(x, y, num):plt.figure()for i in range(0, num*num):axes=plt.subplot(num,num,i + 1)axes.set_title("label=" + str(y[i]))axes.set_xticks([0,10,20,30])axes.set_yticks([0,10,20,30])plt.imshow(toimage(x[i]))plt.tight_layout()plt.savefig('sample.jpg')#以下结构统一忽略LRN层def build_AlexNet(s):model = Sequential()#第一层,卷积层 + max poolingmodel.add(Convolution2D(96, 11, 11, border_mode='same', input_shape = s))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2, 2)))#第二层,卷积层 + max poolingmodel.add(Convolution2D(256, 5, 5, border_mode='same', activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))#第三层,卷积层model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, 3, 3, border_mode='same', activation='relu'))#第四层,卷积层model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(1024, 3, 3, border_mode='same', activation='relu'))#第五层,卷积层model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(1024, 3, 3, border_mode='same', activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Flatten())#第六层,全连接层model.add(Dense(3072, activation='relu'))model.add(Dropout(0.5))#第七层,全连接层model.add(Dense(4096, activation='relu'))model.add(Dropout(0.5))#第八层, 输出层model.add(Dense(10))model.add(Activation('softmax'))return modelif __name__=="__main__":from keras.utils.visualize_util import plot//使用第三个GPU卡with tf.device('/gpu:3'):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)//只有卡3可见防止tensorflow占用所有卡os.environ["CUDA_VISIBLE_DEVICES"]="3"tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))(X_train, y_train), (X_test, y_test) = cifar10.load_data()data_visualize(X_train, y_train, 4)s = X_train.shape[1:]model = build_AlexNet(s)model.summary()plot(model, to_file="AlexNet.jpg", show_shapes=True)#定义输入数据并做归一化dim = 32channel = 3class_num = 10X_train = X_train.reshape(X_train.shape[0], dim, dim, channel).astype('float32') / 255X_test = X_test.reshape(X_test.shape[0], dim, dim, channel).astype('float32') / 255Y_train = np_utils.to_categorical(y_train, class_num)Y_test = np_utils.to_categorical(y_test, class_num)#预处理与数据扩充datagen = ImageDataGenerator(featurewise_center=False,samplewise_center=False,featurewise_std_normalization=False,samplewise_std_normalization=False,zca_whitening=False,rotation_range=25,width_shift_range=0.1,height_shift_range=0.1,horizontal_flip=False,vertical_flip=False)datagen.fit(X_train)model.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])batch_size = 32nb_epoch = 10#import pdb#pdb.set_trace()ModelCheckpoint("weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5", monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=False, mode='auto')model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,verbose=1, validation_data=(X_test, Y_test))score = model.evaluate(X_test, Y_test, verbose=0)print('Test score:', score[0])print('Test accuracy:', score[1])y_hat = model.predict_classes(X_test)test_wrong = [im for im in zip(X_test,y_hat,y_test) if im[1] != im[2]]plt.figure(figsize=(10, 10))for ind, val in enumerate(test_wrong[:100]):plt.subplots_adjust(left=0, right=1, bottom=0, top=1)plt.subplot(10, 10, ind + 1)plt.axis("off")plt.text(0, 0, val[2][0], fontsize=14, color='blue')plt.text(8, 0, val[1], fontsize=14, color='red')plt.imshow(toimage(val[0]))savefig('Wrong.jpg')
- 训练数据可视化

- 网络结构

可以看到实践中,AlexNet的参数规模巨大(将近2亿个参数),所以即使在GPU上训练也很慢。
- 错误分类可视化
蓝色为实际分类,红色为预测分类。

5.6 VGG
在论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》中提出,通过缩小卷积核大小来构建更深的网络。
5.6.1 网络结构

图中D和E分别为VGG-16和VGG-19,是文中两个效果最好的网络结构,VGG网络结构可以看做是AlexNet的加深版,VGG在图像检测中效果很好(如:Faster-RCNN),这种传统结构相对较好的保存了图片的局部位置信息(不像GoogLeNet中引入Inception可能导致位置信息的错乱)。
与AlexNet相比:
相同点
- 整体结构分五层;
- 除softmax层外,最后几层为全连接层;
- 五层之间通过max pooling连接。
不同点
- 使用3×3的小卷积核代替7×7大卷积核,网络构建的比较深;
- 由于LRN太耗费计算资源,性价比不高,所以被去掉;
- 采用了更多的feature map,能够提取更多的特征,从而能够做更多特征的组合。
5.6.2 VGG代码实践
- VGG-16/VGG-19
使用CIFAR-100数据集,ps复杂网络在这种数据集上表现不好。
# -*- coding: utf-8 -*-import copyimport numpy as npimport pandas as pdimport matplotlibmatplotlib.use("Agg")import matplotlib.pyplot as pltimport osfrom matplotlib.pyplot import plot,savefigfrom scipy.misc import toimagefrom keras.datasets import cifar100,mnistfrom keras.models import Sequential, Graphfrom keras.layers.core import Dense, Dropout, Activation, Flatten, Reshapefrom keras.optimizers import SGD, RMSpropfrom keras.utils import np_utilsfrom keras.regularizers import l2from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D, AveragePooling2Dfrom keras.callbacks import EarlyStoppingfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.layers.normalization import BatchNormalizationfrom keras.callbacks import ModelCheckpointfrom keras import backend as Kimport tensorflow as tftf.python.control_flow_ops = tffrom PIL import Imagedef data_visualize(x, y, num):plt.figure()for i in range(0, num*num):axes=plt.subplot(num,num,i + 1)axes.set_title("label=" + str(y[i]))axes.set_xticks([0,10,20,30])axes.set_yticks([0,10,20,30])plt.imshow(toimage(x[i]))plt.tight_layout()plt.savefig('sample.jpg')def build_VGG_16(s):model = Sequential()fm = 3model.add(ZeroPadding2D((1,1),input_shape=s))model.add(Convolution2D(64, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(64, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(128, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(128, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(Flatten())model.add(Dense(4096, activation='relu'))model.add(Dropout(0.5))model.add(Dense(4096, activation='relu'))model.add(Dropout(0.5))model.add(Dense(100, activation='softmax'))return modeldef build_VGG_19(s):model = Sequential()fm = 3model.add(ZeroPadding2D((1,1),input_shape=s))model.add(Convolution2D(64, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(64, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(128, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(128, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, fm, fm, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(Flatten())model.add(Dense(4096, activation='relu'))model.add(Dropout(0.5))model.add(Dense(4096, activation='relu'))model.add(Dropout(0.5))model.add(Dense(100, activation='softmax'))return modelif __name__=="__main__":from keras.utils.visualize_util import plotwith tf.device('/gpu:2'):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)os.environ["CUDA_VISIBLE_DEVICES"]="2"tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))(X_train, y_train), (X_test, y_test) = cifar100.load_data()data_visualize(X_train, y_train, 4)s = X_train.shape[1:]print (s)model = build_VGG_16(s) #build_VGG_19(s)model.summary()plot(model, to_file="VGG.jpg", show_shapes=True)#定义输入数据并做归一化dim = 32channel = 3class_num = 100X_train = X_train.reshape(X_train.shape[0], dim, dim, channel).astype('float32') / 255X_test = X_test.reshape(X_test.shape[0], dim, dim, channel).astype('float32') / 255Y_train = np_utils.to_categorical(y_train, class_num)Y_test = np_utils.to_categorical(y_test, class_num)# this will do preprocessing and realtime data augmentationdatagen = ImageDataGenerator(featurewise_center=False, # set input mean to 0 over the datasetsamplewise_center=False, # set each sample mean to 0featurewise_std_normalization=False, # divide inputs by std of the datasetsamplewise_std_normalization=False, # divide each input by its stdzca_whitening=False, # apply ZCA whiteningrotation_range=25, # randomly rotate images in the range (degrees, 0 to 180)width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)height_shift_range=0.1, # randomly shift images vertically (fraction of total height)horizontal_flip=False, # randomly flip imagesvertical_flip=False) # randomly flip imagesdatagen.fit(X_train)# trainingmodel.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])batch_size = 32nb_epoch = 10#import pdb#pdb.set_trace()ModelCheckpoint("weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5", monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto')model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,verbose=1, validation_data=(X_test, Y_test))score = model.evaluate(X_test, Y_test, verbose=0)print('Test score:', score[0])print('Test accuracy:', score[1])
5.7 MSRANet
该网络的亮点有两个:提出PReLU和一种鲁棒性强的参数初始化方法
5.7.1 PReLU
前面已经介绍过传统ReLU的一些缺点,PReLU是其中一种解决方案:

如何合理保留负向信息,一种方式是上图中值是可以不通过人为指定而自动学出来:
定义Parametric Rectifiers如下:
利用误差反向传播原理:
当采用动量法更新权重:
详情请阅读Kaiming He等人的《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》论文。
5.8 Highway Networks
Highway Networks在我看来是一种承上启下的结构,来源于论文《Highway Networks》借鉴了类似LSTM(后面会介绍)中门(gate)的思想,结构很通用(太通用的结构不一定是件好事儿),给出了一种建立更深网络的思路:
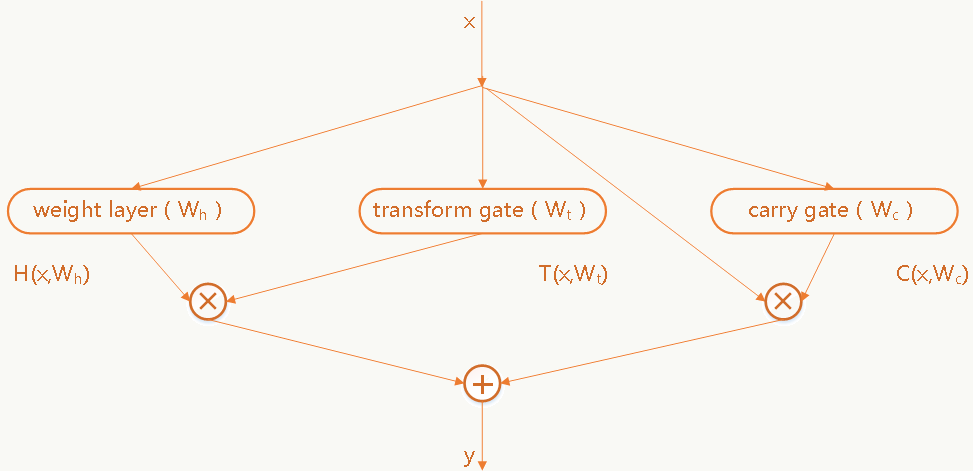
任何一层或几层都可以通过上述方式构建Block,公式中叫做transform gate,叫做carry gate,一般简单起见可以让,显然公式中,,,需要有相同的维度(比如,可以通过zero-padding或者做映射),通过这种结构可以把网络做到很深(比如100层以上),并且优化没有那么困难,看着似乎提供了解决“深”网络学习问题的方案(下一节会解释“似乎”这个词)。
5.9 Residual Networks
残差网络在《Deep Residual Learning for Image Recognition》中被第一次提出,作者利用它在ILSVRC 2015的ImageNet 分类、检测、定位任务以及COCO 2015的检测、图像分割任务上均拿到第一名,也证明ResNet是比较通用的框架。
5.9.1 ResNet产生的动机
我一直说深度学习的研究很大程度是实验科学,ResNet的研究上也比较能体现这点。一个问题:是否能够通过简单的增加网络层数就能学到更好的模型呢?通过实验发现答案是否定的,并且随着层数的增加预测精度会趋于饱和,然后迅速下降,这个现象叫degradation。

图中可以看到在CIFAR-10数据集上,20层网络在训练集和测试集上的表现都明显好于56层网络,这显然不是过拟合导致的,这个现象也不符合我们的直观映像:按理说多增加一层的模型效果应该好于未增加时的模型,最起码不应该变差(比如直接做恒等映射),于是作者提出原始的残差学习框架(也可以看成是Highway Networks在T=0.5时的特例):

其中为恒等映射,为激活函数,输入和输出的维度是一样的(即使不一样也可以通过zero-padding或再做一次映射变成一样),图中恒等映射是在两层神经网络后,也可以在任意层后。
这个框架的假设是:多层非线性激活的神经网络学习恒等映射的能力比较弱,直接将恒等映射加入可以跳过这个问题。
与Highway Networks相比:
- HN的transform gate和carry
5.9.2 恒等映射
恒等映射在深度残差网络中究竟扮演什么角色呢?在《Identity Mappings in Deep Residual Networks》中作者做了分析,并提出新的残差block结构,将和都改为恒等映射,通过这个变化使得信号在前向和反向传播中都有“干净”的路径(图中灰色部分),a为原始block结构,b为新的结构。。

原始结构:
新结构:
其中为Batch Normalization。
在CIFAR-10上用1001层残差网络做测试,效果如下:

新的proposed结构比原始结构效果明显:
双恒等映射下,任何一个残差block如下:
对上述结构做递归展开,任何一个深层block和其所有浅层block的关系为:
这个形式会有很好的计算性质,回想GBDT,是否觉得有点像?在反向传播时同样也有良好的性质:
前半部分传播时完全不用考虑权重层,可以很直接的把误差的梯度信息反向传播给任何一个浅层block,而在mini-batch时又不太可能总为-1,所以即使权重很小也很难出现梯度消失的问题。假如不采用恒等映射,例如:,则:
如果网络比较深,对于参数,当时它会很大;当时,它会很小甚至消失,此时反向信号会被强制流到block的各个权重层,显然恒等映射的优点完全没有了。
5.9.3 模型集成角度看残差网络
《Residual Networks Behave Like Ensembles of Relatively Shallow Networks》中把残差网络做展开,其实会发现以下关系:

如果有个残差block,展开后会得到个路径,于是残差网络就可以看成这么多模型的集成。那么这些路径之间是否有互相依赖关系呢:

可以看到删除VGG任何一层,不管在CIFAR-10还是ImageNet数据集上,准确率立马变得惨不忍睹,而删除残差网络的任何一个block几乎不会影响效果,但删除采样层会对效果影响较大(采样层不存在展开多路径特点),上面实验表明对残差网络,虽然多路径是联合训练的,但路径间相互没有强依赖性,直观的解释如图:
即使删掉这个节点,还有其它路径存在,而非残差结构的路径则会断掉。
残差网络看做集成模型可以通过下面实验结果得到印证:

模型在运行时的效果与有效路径的个数成正比且关系平滑,左图说明残差网络的效果类似集成模型,右图说明实践中残差网络可以在运行时做网络结构修改。
5.9.4 残差网络中的短路径
通过残差block的结构可知展开后的个路径的长度服从二项分布,(每次选择是否跳过权重层的概率是0.5),所以其期望为:,下面三幅图是在有54个残差block下的实验,第一幅图为路径分布图,可以看到95%的路径长度都在19~35之间:

由于路径长短不同,在反向传播时携带的梯度信息量也不同,路径长度与携带梯度信息量成反比,实验结果如下图:

残差网络中真正有效的路径几乎都是浅层路径,实验中有效路径长度在5~17之间,所以实践中做模型压缩可以先从长路径入手。

虽然残差网络没有解决梯度消失问题,只是把它给绕过了,并没有解决深层神经网络的本质问题,但我们应用时更多的看实践效果。
5.9.5 代码实践
下面我们实现在《Deep Residual Learning for Image Recognition》中提到的ResNet-34,并演示在CIFAR-10下的训练效果。

- resnet.py
# -*- coding: utf-8 -*-from keras import backend as Kfrom keras.layers.merge import addfrom keras.layers import Input, Activation, Dense, Flattenfrom keras.layers.convolutional import Conv2D, MaxPooling2D, AveragePooling2Dfrom keras.layers.normalization import BatchNormalizationfrom keras.regularizers import l1_l2from keras.models import Modelclass ResNet(object):'''残差网络基本模块定义'''name = 'resnet'def __init__(self, n):self.name = ndef bn_relu(self, input):'''构建propoesd残差block中BN与ReLU子结构,针对tensorflow'''normalize = BatchNormalization(axis=3)(input)return Activation("relu")(normalize)def bn_relu_weight(self, filters, kernel_size, strides):'''构建propoesd残差block中BN->ReLu->Weight的子结构'''def inner_func(input):act = self.bn_relu(input)conv = Conv2D(filters=filters,kernel_size=kernel_size,strides=strides,padding='same',kernel_initializer='he_normal',kernel_regularizer=l1_l2(0.0001))(act)return convreturn inner_funcdef weight_bn_relu(self, filters, kernel_size, strides):'''构建propoesd残差block中BN->ReLu->Weight的子结构'''def inner_func(input):return self.bn_relu(Conv2D(filters=filters,kernel_size=kernel_size,strides=strides,padding='same',kernel_initializer='he_normal',kernel_regularizer=l1_l2(0.0001))(input))return inner_funcdef shortcut(self, left, right):'''构建propoesd残差block中恒等映射的子结构,分两种情况,输入、输出维度一致&维度不一致'''left_shape = K.int_shape(left)right_shape = K.int_shape(right)stride_width = int(round(left_shape[1] / right_shape[1]))stride_height = int(round(left_shape[2] / right_shape[2]))equal_channels = left_shape[3] == right_shape[3]x_l = left# 如果输入输出维度不一致需要通过映射变一致,否则一致则返回单位矩阵,这个映射发生在两个不同维度block之间(论文中虚线部分)if left_shape != right_shape:x_l = Conv2D(filters=right_shape[3],kernel_size=(1, 1),strides=(int(round(left_shape[1] / right_shape[1])),int(round(left_shape[2] / right_shape[2]))),padding="valid",kernel_initializer="he_normal",kernel_regularizer=l1_l2(0.01, 0.0001))(left)x_l_1 = add([x_l, right])return x_l_1def basic_block(self, filters, strides=(1, 1), is_first_block=False):"""34层以内的残差网络使用的block,2层一跨"""def inner_func(input):# 恒等映射if not is_first_block:conv1 = self.bn_relu_weight(filters=filters,kernel_size=(3, 3),strides=strides)(input)else:conv1 = Conv2D(filters=filters, kernel_size=(3, 3),strides=strides,padding="same",kernel_initializer="he_normal",kernel_regularizer=l1_l2(0.01, 0.0001))(input)# 残差网络residual = self.bn_relu_weight(filters=filters,kernel_size=(3, 3), strides=(1, 1))(conv1)# 构建一个两层的残差blockreturn self.shortcut(input, residual)return inner_funcdef residual_block(self, block_func, filters, repeat_times, is_first_block):'''构建多层残差block'''def inner_func(input):for i in range(repeat_times):# 第一个block的第一层,其输入为pooling层if is_first_block:strides = (1, 1)else:if i == 0: # 每个残差block的第一层strides = (2, 2)else: # 每个残差block的非第一层strides = (1, 1)flag = i == 0 and is_first_blockinput = block_func(filters=filters,strides=strides,is_first_block=flag)(input)return inputreturn inner_funcdef residual_builder(self, input_shape, softmax_num, func_type, repeat_times):'''指定输入、输出、残差block的类型、网络深度并构建残差网络'''input = Input(shape=input_shape)# 第一层为卷积层conv1 = self.weight_bn_relu(filters=64, kernel_size=(7, 7), strides=(2, 2))(input)# 第二层为max pooling层pool1 = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding="same")(conv1)residual_block = pool1filters = 64# 接着16个残差blockfor i, r in enumerate(repeat_times):if i == 0:residual_block = self.residual_block(func_type,filters=filters,repeat_times=r,is_first_block=True)(residual_block)else:residual_block = self.residual_block(func_type,filters=filters,repeat_times=r,is_first_block=False)(residual_block)filters *= 2residual_block = self.bn_relu(residual_block)shape = K.int_shape(residual_block)# average pooling层pool2 = AveragePooling2D(pool_size=(shape[1], shape[2]),strides=(1, 1))(residual_block)flatten1 = Flatten()(pool2)# 全连接层dense1 = Dense(units=softmax_num,kernel_initializer="he_normal",activation="softmax")(flatten1)return Model(inputs=input, outputs=dense1)
- resnet-cifar-10.py
# -*- coding: utf-8 -*-import numpy as npimport matplotlibimport resnetmatplotlib.use("Agg")import matplotlib.pyplot as pltimport osfrom scipy.misc import toimagefrom keras.datasets import cifar10from keras.utils import np_utilsfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.callbacks import ModelCheckpointfrom keras import backend as Kimport tensorflow as tftf.python.control_flow_ops = tffrom keras.callbacks import ReduceLROnPlateau, CSVLogger, EarlyStoppinglr_reducer = ReduceLROnPlateau(monitor='val_loss', factor=np.sqrt(0.5), cooldown=0, patience=3, min_lr=1e-6)early_stopper = EarlyStopping(monitor='val_acc', min_delta=0.0005, patience=15)csv_logger = CSVLogger('resnet34_cifar10.csv')def data_visualize(x, y, num):plt.figure()for i in range(0, num * num):axes = plt.subplot(num, num, i + 1)axes.set_title("label=" + str(y[i]))axes.set_xticks([0, 10, 20, 30])axes.set_yticks([0, 10, 20, 30])plt.imshow(toimage(x[i]))plt.tight_layout()plt.savefig('sample.jpg')if __name__ == "__main__":from keras.utils.vis_utils import plot_modelwith tf.device('/gpu:3'):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)os.environ["CUDA_VISIBLE_DEVICES"] = "3"tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))(X_train, y_train), (X_test, y_test) = cifar10.load_data()data_visualize(X_train, y_train, 4)# 定义输入数据并做归一化dim = 32channel = 3class_num = 10X_train = X_train.reshape(X_train.shape[0], dim, dim, channel).astype('float32') / 255X_test = X_test.reshape(X_test.shape[0], dim, dim, channel).astype('float32') / 255Y_train = np_utils.to_categorical(y_train, class_num)Y_test = np_utils.to_categorical(y_test, class_num)# this will do preprocessing and realtime data augmentationdatagen = ImageDataGenerator(featurewise_center=False, # set input mean to 0 over the datasetsamplewise_center=False, # set each sample mean to 0featurewise_std_normalization=False, # divide inputs by std of the datasetsamplewise_std_normalization=False, # divide each input by its stdzca_whitening=False, # apply ZCA whiteningrotation_range=25, # randomly rotate images in the range (degrees, 0 to 180)width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)height_shift_range=0.1, # randomly shift images vertically (fraction of total height)horizontal_flip=True, # randomly flip imagesvertical_flip=False) # randomly flip imagesdatagen.fit(X_train)s = X_train.shape[1:]print(s)builder = resnet.ResNet("ResNet-test")resnet_34 = builder.residual_builder(s, class_num, builder.basic_block, [3, 4, 6, 3])model = resnet_34model.summary()#import pdb#pdb.set_trace()plot_model(model, to_file="ResNet.jpg", show_shapes=True)model.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])batch_size = 32nb_epoch = 100# import pdb# pdb.set_trace()ModelCheckpoint("weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5", monitor='val_loss', verbose=0,save_best_only=False, save_weights_only=False, mode='auto')model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size),steps_per_epoch=X_train.shape[0],validation_data=(X_test, Y_test),epochs=nb_epoch,verbose=1,max_q_size=100,callbacks=[lr_reducer, early_stopper, csv_logger])score = model.evaluate(X_test, Y_test, verbose=0)print('Test score:', score[0])print('Test accuracy:', score[1])
ps:注意使用keras的plot_model函数需要安装graphviz与pydot_ng,且安装顺序为先graphviz后pydot_ng。
graphviz安装
yum list available 'graphviz*'
yum install 'graphviz*'pydot_ng安装
pip install pydot_ng网络结构

可以看到网络结构很复杂但需要训练的参数个数只有21296522个,远小于AlexNet参数个数。
- CIFAR-10训练情况

迭代100次后,训练集上Acc为:0.8367,测试集上Acc为0.8346。
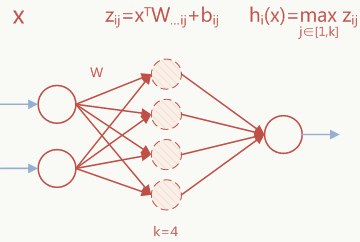
5.10 Maxout Networks
Goodfellow等人在《Maxout Networks》一文中提出,这篇论文值得一看。
5.10.1 Maxout激活函数
对于神经网络任意一层可以添加Maxout结构,公式如下:
上面的和是要学习的参数,这些参数可以通过反向传播计算,是事先指定的参数,是输入节点,假定有以下3层网络结构:

Maxout激活可以认为是在输入节点和输出节点中间加了个隐含节点,以上图节点为例,上图红色部分在Maxout结构中被扩展为以下结构:
实际上图所示的单个Maxout 单元本质是一个分段线性函数,而任意凸函数都可以通过分段线性函数来拟合,这个可以很直观的理解,以抛物线为例:每个节点都是一个线性函数,上图~节点输出对应下图~线段:

从全局上看,ReLU可以看做Maxout的一种特例,Maxout通过网络自动学习激活函数(从这个角度看Maxout也可以看做某种Network-In-Network结构),不对做限制,只要两个Maxout 单元就能拟合任意连续函数,关于这部分论文中有更详细的证明,这里不再赘述,实际上它与Dropout配合效果更好,这里可以回想下核方法(Kernel Method),核方法采用非线性核(如高斯核)也会有类似通过局部线性拟合来模拟非线性行为,但传统核方法会事先指定核函数(如高斯函数),而不是数据驱动的方式算出来,当然也有kernel组合方面的研究,但在我看来最终和神经网络殊途同归,其实都可以在神经网络的大框架下去思考(回想前面的SVM与神经网络的关系)。
凡事都有两面性,Maxout的缺点也是明显的:多了一倍参数、需要人为指定值、先验假设被学习的激活函数是凸的。
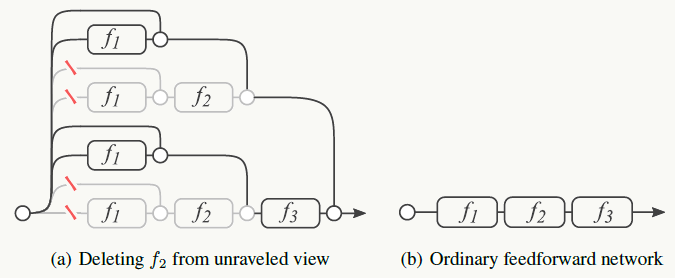
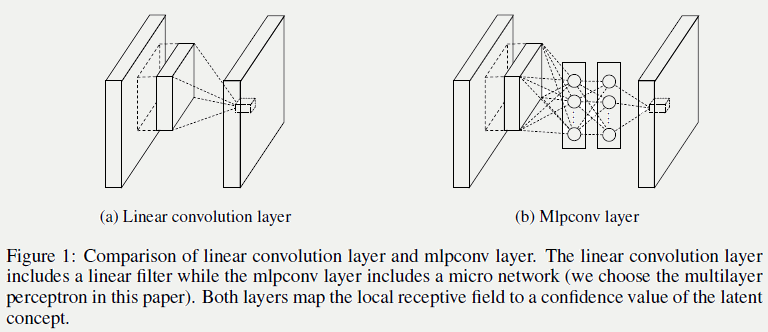
5.11 Network in Network
NIN的思想来源于《Network In Network》,其亮点有2个方面:将传统卷积层替换为非线性卷积层以提升特征抽象能力;使用新的pooling层代替传统全连接层,后续出现的各个版本GoogLeNet也很大程度借鉴了这个思想。
5.11.1 NIN卷积层(MLP Convolution)
传统卷积操作,例如:,本质是广义线性模型,意味着当数据接近线性可分时模型效果会比较好,反之亦然。Maxout网络在一定程度上解决了这个问题,但它有凸函数的假设,实际当中可能很多情况是非凸的,所以论文提出使用多层感知机(MLP)来拟合,不做任何先验假设。
选择MLP的原因是:
- MLP能拟合任意函数,不需要做先验假设(如:线性可分、凸集);
- MLP与卷积神经网络结构天然兼容,可以通过BP方便的做训练;
- MLP本身也能做的较深,且特征能够得到复用;
- 通过MLP做卷积可以起到feature map级联交叉加权组合的作用,能提升特征抽象能力:
显然这个结构也等价于传统卷积层接着一个1×1卷积层,简单起见,下面示意图中激活函数使用线性激活(使用ReLU无非是让某些输出可能为0,不影响问题说明):

的前半部分是传统卷积层,后半部分可以看做1×1卷积层。
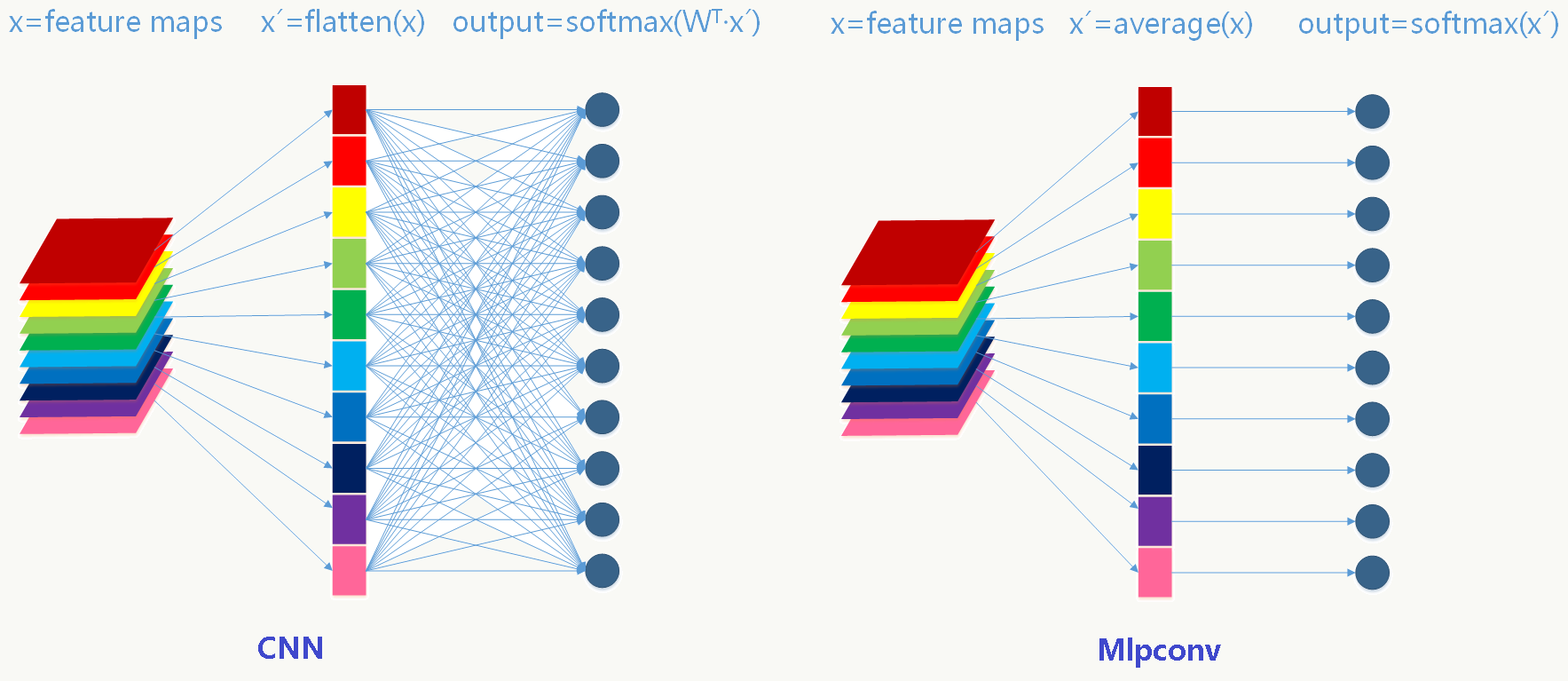
5.11.2 NIN抽样层(Global Average Pooling)
把传统卷积网络分两部分看待:除全连接层外的各个卷积层看做特征提取器,全连接层看成特征组合器。由于全连接的存在破坏了数据的可解释性并大大增加了可训练参数的个数,NIN通过GAP来避免这两个问题,具体做法是:
- 最后一层卷积feature map的个数与分类类别数一致,这种一致性可以产生相对较少的feature map,比如有10个分类和10个n×n的feature map;
- 每个feature map对应一个分类,并对整个feature map求平均值,这种方法能提高空间变换的稳定性,但损失了位置信息(例如在目标检测中位置信息很重要),比如10个n×n的feature map会得到10个实数值组成的一维向量;
- 用softmax做归一化,注意这里要区分传统CNN下的softmax激活和softmax归一,这一层没有需要优化的参数。
传统CNN与Mlpconv的区别如下图:
最后整个NIN的网络结构如下图:
5.12 GoogLeNet Inception V1
GoogLeNet是由google的Christian Szegedy等人在2014年的论文《Going Deeper with Convolutions》提出,其最大的亮点是提出一种叫Inception的结构,以此为基础构建GoogLeNet,并在当年的ImageNet分类和检测任务中获得第一,ps:GoogLeNet的取名是为了向YannLeCun的LeNet系列致敬。
5.12.1 一些思考
为了提高深度神经网络的性能,最简单粗暴有效的方法是增加网络深度与宽度,但这个方法有两个明显的缺点:
- 更深更宽的网络意味着更多的参数,从而大大增加过拟合的风险,尤其在训练数据不是那么多或者某个label训练数据不足的情况下更容易发生;
- 增加计算资源的消耗,实际情况下,不管是因为数据稀疏还是扩充的网络结构利用不充分(比如很多权重接近0),都会导致大量计算的浪费。
解决以上两个问题的基本方法是将全连接或卷积连接改为稀疏连接。不管从生物的角度还是机器学习的角度,稀疏性都有良好的表现,回想Dropout网络以及ReLU激活函数,其本质就是利用稀疏性提高模型泛化性(但需要计算的参数没变少)。
简单解释下稀疏性,当整个特征空间是非线性甚至不连续时:
- 学好局部空间的特征集更能提升性能,类似于Maxout网络中使用多个局部线性函数的组合来拟合非线性函数的思想;
- 假设整个特征空间由N个不连续局部特征空间集合组成,任意一个样本会被映射到这N个空间中并激活/不激活相应特征维度,如果用C1表示某类样本被激活的特征维度集合,用C2表示另一类样本的特征维度集合,当数据量不够大时,要想增加特征区分度并很好的区分两类样本,就要降低C1和C2的重合度(比如可用Jaccard距离衡量),即缩小C1和C2的大小,意味着相应的特征维度集会变稀疏。
尴尬的是,现在的计算机体系结构更善于稠密数据的计算,而在非均匀分布的稀疏数据上的计算效率极差,比如稀疏性会导致的缓存miss率极高,于是需要一种方法既能发挥稀疏网络的优势又能保证计算效率。好在前人做了大量实验(如《On Two-Dimensional Sparse Matrix Partitioning: Models, Methods, and a Recipe》),发现对稀疏矩阵做聚类得到相对稠密的子矩阵可以大幅提高稀疏矩阵乘法性能,借鉴这个思想,作者提出Inception的结构。
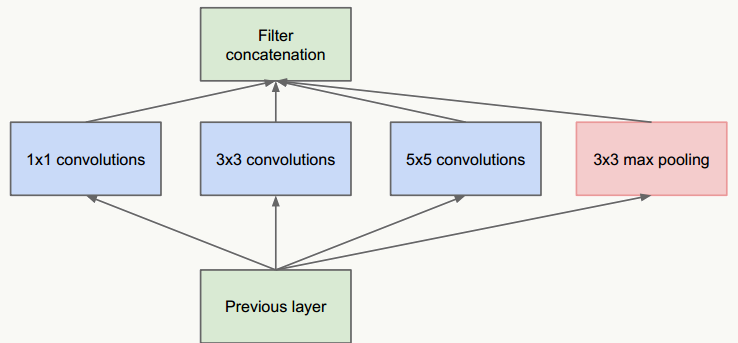
- 把不同大小卷积核抽象得到的特征空间看做子特征空间,每个子特征空间都是稀疏的,把这些不同尺度特征做融合,相当于得到一个相对稠密的空间;
- 采用1×1、3×3、5×5卷积核(不是必须的,也可以是其他大小),stride取1,利用padding可以方便的做输出特征维度对齐;
- 大量事实表明pooling层能有效提高卷积网络的效果,所以加了一条max pooling路径;
- 这个结构符合直观理解,视觉信息通过不同尺度的变换被聚合起来作为下一阶段的特征,比如:人的高矮、胖瘦、青老信息被聚合后做下一步判断。
这个网络的最大问题是5×5卷积带来了巨大计算负担,例如,假设上层输入为:28×28×192:
- 直接经过96个5×5卷积层(stride=1,padding=2)后,输出为:28×28×96,卷积层参数量为:192×5×5×96=460800;
- 借鉴NIN网络,在5×5卷积前使用32个1×1卷积核做维度缩减,变成28×28×32,之后经过96个5×5卷积层(stride=1,padding=2)后,输出为:28×28×96,但所有卷积层的参数量为:192×1×1×32+32×5×5×96=82944,可见整个参数量是原来的1/5.5,且效果上没有多少损失。
新网络结构为:

5.12.2 GoogLeNet结构
利用上述Inception模块构建GoogLeNet,实验表明Inception模块出现在高层特征抽象时会更加有效(我理解由于其结构特点,更适合提取高阶特征,让它提取低阶特征会导致特征信息丢失),所以在低层依然使用传统卷积层。整个网路结构如下:


网络说明:
- 所有卷积层均使用ReLU激活函数,包括做了1×1卷积降维后的激活;
- 移除全连接层,像NIN一样使用Global Average Pooling,使得Top 1准确率提高0.6%,但由于GAP与类别数目有关系,为了方便大家做模型fine-tuning,最后加了一个全连接层;
- 与前面的ResNet类似,实验观察到,相对浅层的神经网络层对模型效果有较大的贡献,训练阶段通过对Inception(4a、4d)增加两个额外的分类器来增强反向传播时的梯度信号,但最重要的还是正则化作用,这一点在GoogLeNet v3中得到实验证实,并间接证实了GoogLeNet V2中BN的正则化作用,这两个分类器的loss会以0.3的权重加在整体loss上,在模型inference阶段,这两个分类器会被去掉;
- 用于降维的1×1卷积核个数为128个;
- 全连接层使用1024个神经元;
- 使用丢弃概率为0.7的Dropout层;
网络结构说明:
输入数据为224×224×3的RGB图像,图中"S"代表做same-padding,"V"代表不做。
- C1卷积层:64个7×7卷积核(stride=2,padding=3),输出为:112×112×64;
- P1抽样层:64个3×3卷积核(stride=2),输出为56×56×64,其中:56=(112-3+1)/2+1
- C2卷积层:192个3×3卷积核(stride=1,padding=1),输出为:56×56×192;
- P2抽样层:192个3×3卷积核(stride=2),输出为28×28×192,其中:28=(56-3+1)/2+1,接着数据被分出4个分支,进入Inception (3a)
- Inception (3a):由4部分组成
- 64个1×1的卷积核,输出为28×28×64;
- 96个1×1的卷积核做降维,输出为28×28×96,之后128个3×3卷积核(stride=1,padding=1),输出为:28×28×128
- 16个1×1的卷积核做降维,输出为28×28×16,之后32个5×5卷积核(stride=1,padding=2),输出为:28×28×32
- 192个3×3卷积核(stride=1,padding=1),输出为28×28×192,进行32个1×1卷积核,输出为:28×28×32
最后对4个分支的输出做“深度”方向组合,得到输出28×28×256,接着数据被分出4个分支,进入Inception (3b);
- Inception (3b):由4部分组成
- 128个1×1的卷积核,输出为28×28×128;
- 128个1×1的卷积核做降维,输出为28×28×128,进行192个3×3卷积核(stride=1,padding=1),输出为:28×28×192
- 32个1×1的卷积核做降维,输出为28×28×32,进行96个5×5卷积核(stride=1,padding=2),输出为:28×28×96
- 256个3×3卷积核(stride=1,padding=1),输出为28×28×256,进行64个1×1卷积核,输出为:28×28×64
最后对4个分支的输出做“深度”方向组合,得到输出28×28×480;
后面结构以此类推。
5.12.3 代码实践
- googlenet_inception_v1.py
# -*- coding: utf-8 -*-from keras.layers import Input, Conv2D, Dense, MaxPooling2D, AveragePooling2Dfrom keras.layers import Dropout, Flatten, merge, ZeroPadding2D, Reshape, Activationfrom keras.models import Modelfrom keras.regularizers import l1_l2import tensorflow as tfimport googlenet_custom_layersdef inception_module(name,input_layer,num_c_1x1,num_c_1x1_3x3_reduce,num_c_3x3,num_c_1x1_5x5_reduce,num_p_5x5,num_c_1x1_reduce):inception_1x1 = Conv2D(name=name+"/inception_1x1",filters=num_c_1x1,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input_layer)inception_3x3_reduce = Conv2D(name=name+"/inception_3x3_reduce",filters=num_c_1x1_3x3_reduce,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input_layer)inception_3x3 = Conv2D(name=name+"/inception_3x3",filters=num_c_3x3,kernel_size=(3, 3),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(inception_3x3_reduce)inception_5x5_reduce = Conv2D(name=name+"/inception_5x5_reduce",filters=num_c_1x1_5x5_reduce,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input_layer)inception_5x5 = Conv2D(name=name+"/inception_5x5",filters=num_p_5x5,kernel_size=(5, 5),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(inception_5x5_reduce)inception_max_pool = MaxPooling2D(name=name+"/inception_max_pool",pool_size=(3, 3),strides=(1, 1),padding="same")(input_layer)inception_max_pool_proj = Conv2D(name=name+"/inception_max_pool_project",filters=num_c_1x1_reduce,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(inception_max_pool)print (inception_1x1.get_shape(), inception_3x3.get_shape(), inception_5x5.get_shape(), inception_max_pool_proj.get_shape())# inception_output = tf.concat(3, [inception_1x1, inception_3x3, inception_5x5, inception_max_pool_proj])from keras.layers.merge import concatenate#注意,由于变态的tensorflow更改了concat函数的参数顺序,需要注意自己的tf和keras版本#适时的将/usr/lib/python×××/site-packages/keras/backend/tensorflow_backend.py的1554行的代码由#return tf.concat([to_dense(x) for x in tensors], axis) 改为:#return tf.concat(axis, [to_dense(x) for x in tensors])inception_output = concatenate([inception_1x1, inception_3x3, inception_5x5, inception_max_pool_proj])return inception_outputdef googLeNet_inception_v1_building(input_shape, output_num, fine_tune=None):input_layer = Input(shape=input_shape)# 第一层,卷积层conv1_7x7 = Conv2D(name="conv1_7x7/2",filters=64,kernel_size=(7, 7),strides=(2, 2),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input_layer)conv1_zero_pad = ZeroPadding2D(padding=(1, 1))(conv1_7x7)# 第二层,max pooling层pool1_3x3 = MaxPooling2D(name="max_pool1_3x3/2",pool_size=(3, 3),strides=(2, 2),padding='valid')(conv1_zero_pad)# 第二层,LRN规范化#pool1_norm1 = tf.nn.lrn(pool1_3x3, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='ax_pool1_3x3/norm1')pool1_norm1 = googlenet_custom_layers.LRN2D(name='max_pool1_3x3/norm1')(pool1_3x3)# 第四层,卷积层降维conv2_3x3_reduce = Conv2D(name="conv2_3x3_reduce/1",filters=64,kernel_size=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(pool1_norm1)# 第五层,卷积层conv2_3x3 = Conv2D(name="conv2_3x3/1",filters=192,kernel_size=(3, 3),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(conv2_3x3_reduce)# 第六层,LRN规范化#conv2_norm2 = tf.nn.lrn(conv2_3x3, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='conv2_3x3/norm2')conv2_norm2 = googlenet_custom_layers.LRN2D(name='conv2_3x3/norm2')(conv2_3x3)conv2_zero_pad = ZeroPadding2D(padding=(1, 1))(conv2_norm2)# 第七层,max pooling层pool2_3x3 = MaxPooling2D(name="max_pool2_3x3",pool_size=(3, 3),strides=(2, 2),padding='valid')(conv2_zero_pad)# 第八层,inception 3ainception_3a = inception_module("inception_3a",pool2_3x3, 64, 96, 128, 16, 32, 32)# 第九层,inception 3binception_3b = inception_module("inception_3b",inception_3a, 128, 128, 192, 32, 96, 64)inception_3b_zero_pad = ZeroPadding2D(padding=(1, 1))(inception_3b)# 第十层,max pooling层pool3_3x3 = MaxPooling2D(name="max_pool3_3x3/2",pool_size=(3, 3),strides=(2, 2),padding='valid')(inception_3b_zero_pad)# 第十一层,inception 4ainception_4a = inception_module("inception_4a",pool3_3x3, 192, 96, 208, 16, 48, 64)# 第十二层,分支loss1loss1_ave_pool = AveragePooling2D(name="loss1/ave_pool",pool_size=(5, 5),strides=(3, 3))(inception_4a)loss1_conv = Conv2D(name="loss1/conv",filters=128,kernel_size=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(loss1_ave_pool)loss1_flat = Flatten()(loss1_conv)loss1_fc = Dense(1024,activation='relu',name="loss1/fc",kernel_regularizer=l1_l2(0.0001))(loss1_flat)loss1_drop_fc = Dropout(0.7)(loss1_fc)loss1_classifier = Dense(output_num,name="loss1/classifier",kernel_regularizer=l1_l2(0.0001))(loss1_drop_fc)loss1_classifier_act = Activation('softmax')(loss1_classifier)# 第十二层,inception_4binception_4b = inception_module("inception_4b",inception_4a, 160, 112, 224, 24, 64, 64)# 第十三层,inception_4cinception_4c = inception_module("inception_4c",inception_4b, 128, 128, 256, 24, 64, 64)# 第十四层,inception_4cinception_4d = inception_module("inception_4d",inception_4c, 112, 144, 288, 32, 64, 64)# 第十五层,分支loss2loss2_ave_pool = AveragePooling2D(pool_size=(5, 5),strides=(3, 3),name='loss2/ave_pool')(inception_4d)loss2_conv = Conv2D(name="loss2/conv",filters=128,kernel_size=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(loss2_ave_pool)loss2_flat = Flatten()(loss2_conv)loss2_fc = Dense(1024,activation='relu',name="loss2/fc",kernel_regularizer=l1_l2(0.0001))(loss2_flat)loss2_drop_fc = Dropout(0.7)(loss2_fc)loss2_classifier = Dense(output_num,name="loss2/classifier",kernel_regularizer=l1_l2(0.0001))(loss2_drop_fc)loss2_classifier_act = Activation('softmax')(loss2_classifier)# 第十五层,inception_4einception_4e = inception_module("inception_4e",inception_4d, 256, 160, 320, 32, 128, 128)inception_4e_zero_pad = ZeroPadding2D(padding=(1, 1))(inception_4e)# 第十六层,max pooling层pool4_3x3 = MaxPooling2D(name="max_pool4_3x3",pool_size=(3, 3),strides=(2, 2),padding='valid')(inception_4e_zero_pad)# 第十七层,inception_5ainception_5a = inception_module("inception_5a",pool4_3x3, 256, 160, 320, 32, 128, 128)# 第十八层,inception_5binception_5b = inception_module("inception_5b",inception_5a, 384, 192, 384, 48, 128, 128)# 第十九层,average pooling层pool5_7x7 = AveragePooling2D(name="ave_pool5_7x7",pool_size=(7, 7),strides=(1, 1))(inception_5b)loss3_flat = Flatten()(pool5_7x7)pool5_drop_7x7 = Dropout(0.4)(loss3_flat)# 第二十层,全连接层loss3_classifier = Dense(output_num,name="loss3/classifier",kernel_regularizer=l1_l2(0.0001))(pool5_drop_7x7)loss3_classifier_act = Activation('softmax')(loss3_classifier)googlenet_inception_v1 = Model(name="googlenet_inception_v1",input=input_layer,output=[loss1_classifier_act, loss2_classifier_act, loss3_classifier_act])if fine_tune:googlenet_inception_v1.load_weights(fine_tune)return googlenet_inception_v1
- googlenet_custom_layers.py
from keras.layers.core import Layerimport keras.backend as Kclass LRN2D(Layer):"""This code is adapted from pylearn2.License at: https://github.com/lisa-lab/pylearn2/blob/master/LICENSE.txt"""def __init__(self, alpha=1e-4, k=2, beta=0.75, n=5, **kwargs):if n % 2 == 0:raise NotImplementedError("LRN2D only works with odd n. n provided: " + str(n))super(LRN2D, self).__init__(**kwargs)self.alpha = alphaself.k = kself.beta = betaself.n = ndef get_output(self, train):X = self.get_input(train)b, ch, r, c = K.shape(X)half_n = self.n // 2input_sqr = K.square(X)extra_channels = K.zeros((b, ch + 2 * half_n, r, c))input_sqr = K.concatenate([extra_channels[:, :half_n, :, :],input_sqr,extra_channels[:, half_n + ch:, :, :]],axis=1)scale = self.kfor i in range(self.n):scale += self.alpha * input_sqr[:, i:i + ch, :, :]scale = scale ** self.betareturn X / scaledef get_config(self):config = {"name": self.__class__.__name__,"alpha": self.alpha,"k": self.k,"beta": self.beta,"n": self.n}base_config = super(LRN2D, self).get_config()return dict(list(base_config.items()) + list(config.items()))class PoolHelper(Layer):def __init__(self, **kwargs):super(PoolHelper, self).__init__(**kwargs)def call(self, x, mask=None):return x[:, :, 1:, 1:]def get_config(self):config = {}base_config = super(PoolHelper, self).get_config()return dict(list(base_config.items()) + list(config.items()))
- googlenet_inception_v1-cifar10.py
# -*- coding: utf-8 -*-import numpy as npimport matplotlibmatplotlib.use("Agg")import matplotlib.pyplot as pltimport osfrom scipy.misc import toimagefrom keras.datasets import cifar10from keras.utils import np_utilsfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.callbacks import ModelCheckpointfrom keras import backend as Kimport tensorflow as tftf.python.control_flow_ops = tffrom keras.callbacks import ReduceLROnPlateau, CSVLogger, EarlyStoppinglr_reducer = ReduceLROnPlateau(monitor='val_loss', factor=np.sqrt(0.5), cooldown=0, patience=3, min_lr=1e-6)early_stopper = EarlyStopping(monitor='val_acc', min_delta=0.0005, patience=15)csv_logger = CSVLogger('resnet34_cifar10.csv')import osimport googlenet_inception_v1if __name__ == "__main__":from keras.utils.vis_utils import plot_modelwith tf.device('/gpu:4'):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)os.environ["CUDA_VISIBLE_DEVICES"] = "4"tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))(X_train, y_train), (X_test, y_test) = cifar10.load_data()# 定义输入数据并做归一化dim = 32channel = 3class_num = 10X_train = X_train.reshape(X_train.shape[0], dim, dim, channel).astype('float32') / 255X_test = X_test.reshape(X_test.shape[0], dim, dim, channel).astype('float32') / 255Y_train = np_utils.to_categorical(y_train, class_num)Y_test = np_utils.to_categorical(y_test, class_num)# this will do preprocessing and realtime data augmentationdatagen = ImageDataGenerator(featurewise_center=False, # set input mean to 0 over the datasetsamplewise_center=False, # set each sample mean to 0featurewise_std_normalization=False, # divide inputs by std of the datasetsamplewise_std_normalization=False, # divide each input by its stdzca_whitening=False, # apply ZCA whiteningrotation_range=25, # randomly rotate images in the range (degrees, 0 to 180)width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)height_shift_range=0.1, # randomly shift images vertically (fraction of total height)horizontal_flip=True, # randomly flip imagesvertical_flip=False) # randomly flip imagesdatagen.fit(X_train)s = X_train.shape[1:]print(s)model = googlenet_inception_v1.googLeNet_inception_v1_building(s,class_num)model.summary()#import pdb#pdb.set_trace()plot_model(model, to_file="GoogLeNet-Inception-V1.jpg", show_shapes=True)model.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])batch_size = 32nb_epoch = 100# import pdb# pdb.set_trace()ModelCheckpoint("weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5", monitor='val_loss', verbose=0,save_best_only=False, save_weights_only=False, mode='auto')for e in range(nb_epoch):batches = 0for X_batch, Y_batch in datagen.flow(X_train, Y_train, batch_size=64):loss = model.train_on_batch(X_batch, [Y_batch,Y_batch,Y_batch]) # note the three outputsprint loss#print '\r\n'#loss_and_metrics = model.evaluate(X_test, [Y_test,Y_test,Y_test], batch_size=128)#model.fit(X_test, [Y_test,Y_test,Y_test], batch_size=64)batches += 1if batches >= len(X_train) / 64:# we need to break the loop by hand because# the generator loops indefinitelybreakscore = model.evaluate(X_test, Y_test, verbose=0)print('Test score:', score[0])print('Test accuracy:', score[1])
整个网络结构如下:

需要训练的总参数量为10,334,030个。
5.13 GoogLeNet Inception V2
GoogLeNet Inception V2在《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》出现,最大亮点是提出了Batch Normalization方法,它起到以下作用:
- 使用较大的学习率而不用特别关心诸如梯度爆炸或消失等优化问题;
- 降低了模型效果对初始权重的依赖;
- 可以加速收敛,一定程度上可以不使用Dropout这种降低收敛速度的方法,但却起到了正则化作用提高了模型泛化性;
- 即使不使用ReLU也能缓解激活函数饱和问题;
- 能够学习到从当前层到下一层的分布缩放( scaling (方差),shift (期望))系数。
5.13.1 一些思考
在机器学习中,我们通常会做一种假设:训练样本独立同分布(iid)且训练样本与测试样本分布一致,如果真实数据符合这个假设则模型效果可能会不错,反之亦然,这个在学术上叫Covariate Shift,所以从样本(外部)的角度说,对于神经网络也是一样的道理。从结构(内部)的角度说,由于神经网络由多层组成,样本在层与层之间边提特征边往前传播,如果每层的输入分布不一致,那么势必造成要么模型效果不好,要么学习速度较慢,学术上这个叫Internal Covariate Shift。
假设:为样本标注,为样本通过神经网络若干层后每层的输入;
理论上:的联合概率分布应该与集合中任意一层输入的联合概率分布一致,如:;
但是:,其中条件概率是一致的,即,但由于神经网络每一层对输入分布的改变,导致边缘概率是不一致的,即,甚至随着网络深度的加深,前面层微小的变化会导致后面层巨大的变化。
5.13.2 BN原理
BN整个算法过程如下:

- 以batch的方式做训练,对m个样本求期望和方差后对训练数据做白化,通过白化操作可以去除特征相关性并把数据缩放在一个球体上,这么做的好处既可以加快优化算法的优化速度也可能提高优化精度,一个直观的解释:
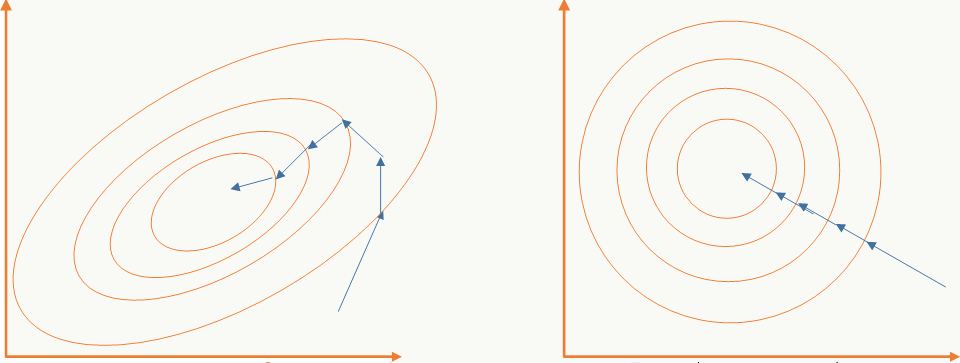
左边是未做白化的原始可行域,右边是做了白化的可行域; - 当原始输入对模型学习更有利时能够恢复原始输入(和残差网络有点神似):
这里的参数和是需要学习的。
参数学习依然是利用反向传播原理:

对卷积神经网络而言,BN被加在激活函数的非线性变换前,即:
由于BN参数的存在,这里的偏置可以被去掉,即:
所以在看相关代码实现时大家会发现没有偏置这个参数。
另外当采用较大的学习率时,传统方法会由于激活函数饱和区的存在导致反向传播时梯度出现爆炸或消失,但采用BN后,参数的尺度变化不影响梯度的反向传播,可以证明:
在模型Inference阶段,BN层需要的期望和方差是固定值,由于所有训练集batch的期望和方差已知,可以用这些值对整体训练集的期望和方差做无偏估计修正,修正方法为:
Inference时的公式变为:
5.13.2 卷积神经网络中的BN
卷积网络中采用权重共享策略,每个feature map只有一对,需要学习。
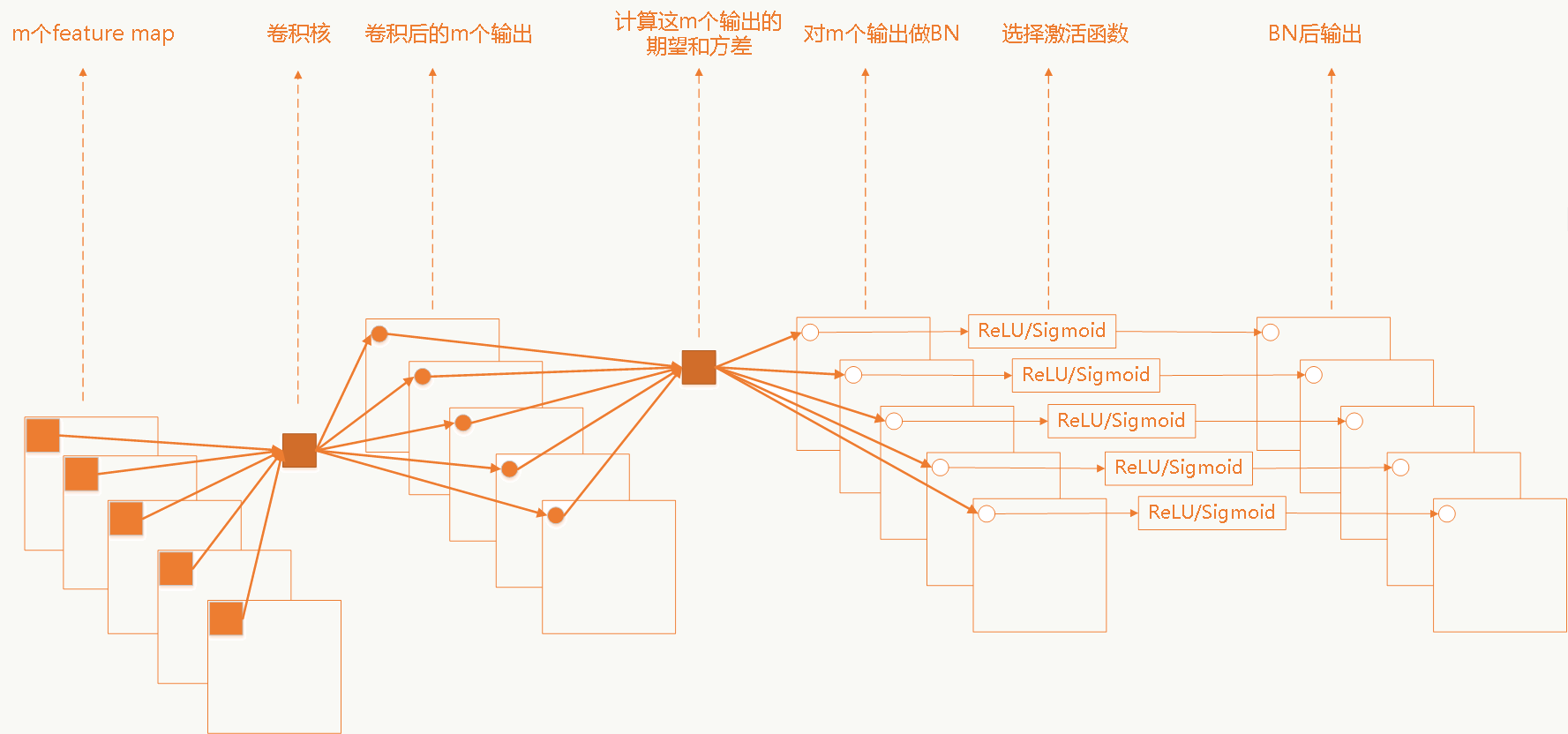
5.13.3 代码实践
import copyimport numpy as npimport pandas as pdimport matplotlibmatplotlib.use("Agg")import matplotlib.pyplot as pltfrom matplotlib.pyplot import plot,savefigfrom keras.datasets import mnist, cifar10from keras.models import Sequentialfrom keras.layers.core import Dense, Dropout, Activation, Flatten, Reshapefrom keras.optimizers import SGD, RMSpropfrom keras.utils import np_utilsfrom keras.regularizers import l2from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D, AveragePooling2Dfrom keras.callbacks import EarlyStoppingfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.layers.normalization import BatchNormalizationimport tensorflow as tftf.python.control_flow_ops = tffrom PIL import Imagedef build_LeNet5():model = Sequential()model.add(Convolution2D(96, 11, 11, border_mode='same', input_shape = (32, 32, 3), dim_ordering='tf'))#注释1 model.add(BatchNormalization())model.add(MaxPooling2D(pool_size=(2, 2)))#注释2 model.add(BatchNormalization())model.add(Activation("tanh"))model.add(Convolution2D(120, 1, 1, border_mode='valid'))#注释3 model.add(BatchNormalization())model.add(Flatten())model.add(Dense(10))model.add(BatchNormalization())model.add(Activation("relu"))#注释4 model.add(Dense(10))model.add(Activation('softmax'))return modelif __name__=="__main__":from keras.utils.vis_utils import plot_modelmodel = build_LeNet5()model.summary()plot_model(model, to_file="LeNet-5.png", show_shapes=True)(X_train, y_train), (X_test, y_test) = cifar10.load_data()#mnist.load_data()X_train = X_train.reshape(X_train.shape[0], 32, 32, 3).astype('float32') / 255X_test = X_test.reshape(X_test.shape[0], 32, 32, 3).astype('float32') / 255Y_train = np_utils.to_categorical(y_train, 10)Y_test = np_utils.to_categorical(y_test, 10)# this will do preprocessing and realtime data augmentationdatagen = ImageDataGenerator(featurewise_center=False, # set input mean to 0 over the datasetsamplewise_center=False, # set each sample mean to 0featurewise_std_normalization=False, # divide inputs by std of the datasetsamplewise_std_normalization=False, # divide each input by its stdzca_whitening=False, # apply ZCA whiteningrotation_range=25, # randomly rotate images in the range (degrees, 0 to 180)width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)height_shift_range=0.1, # randomly shift images vertically (fraction of total height)horizontal_flip=False, # randomly flip imagesvertical_flip=False) # randomly flip imagesdatagen.fit(X_train)# trainingmodel.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])batch_size = 32nb_epoch = 8model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,verbose=1, validation_data=(X_test, Y_test))score = model.evaluate(X_test, Y_test, verbose=0)print('Test score:', score[0])print('Test accuracy:', score[1])
三组实验对比:
- 第一组:放开所有注释
- 第二组:放开注释4
- 第三组:注释掉所有BN

5.14 GoogLeNet Inception V3
GoogLeNet Inception V3在《Rethinking the Inception Architecture for Computer Vision》中提出(注意,在这篇论文中作者把该网络结构叫做v2版,我们以最终的v4版论文的划分为标准),该论文的亮点在于:
- 提出通用的网络结构设计准则
- 引入卷积分解提高效率
- 引入高效的feature map降维
5.14.1 网络结构设计的准则
前面也说过,深度学习网络的探索更多是个实验科学,在实验中人们总结出一些结构设计准则,但说实话我觉得不一定都有实操性:
避免特征表示上的瓶颈,尤其在神经网络的前若干层
神经网络包含一个自动提取特征的过程,例如多层卷积,直观并符合常识的理解:如果在网络初期特征提取的太粗,细节已经丢了,后续即使结构再精细也没法做有效表示了;举个极端的例子:在宇宙中辨别一个星球,正常来说是通过由近及远,从房屋、树木到海洋、大陆板块再到整个星球之后进入整个宇宙,如果我们一开始就直接拉远到宇宙,你会发现所有星球都是球体,没法区分哪个是地球哪个是水星。所以feature map的大小应该是随着层数的加深逐步变小,但为了保证特征能得到有效表示和组合其通道数量会逐渐增加。
下图违反了这个原则,刚开就始直接从35×35×320被抽样降维到了17×17×320,特征细节被大量丢失,即使后面有Inception去做各种特征提取和组合也没用。

对于神经网络的某一层,通过更多的激活输出分支可以产生互相解耦的特征表示,从而产生高阶稀疏特征,从而加速收敛,注意下图的1×3和3×1激活输出:

合理使用维度缩减不会破坏网络特征表示能力反而能加快收敛速度,典型的例如通过两个3×3代替一个5×5的降维策略,不考虑padding,用两个3×3代替一个5×5能节省1-(3×3+3×3)/(5×5)=28%的计算消耗。
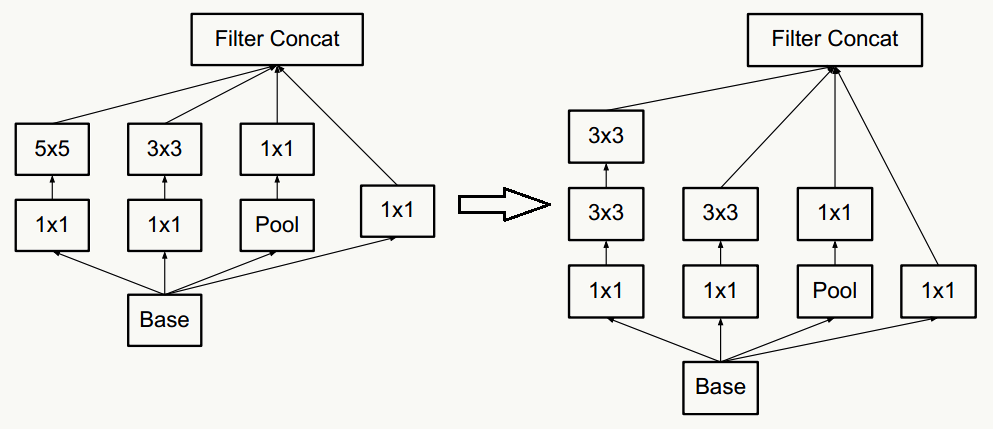
以及一个n×n卷积核通过顺序相连的两个1×n和n×1做降维(有点像矩阵分解),如果n=3,计算性能可以提升1-(3+3)/9=33%,但如果考虑高性能计算性能,这种分解可能会造成L1 cache miss率上升。

- 通过合理平衡网络的宽度和深度优化网络计算消耗(这句话尤其不具有实操性)。
- 抽样降维,传统抽样方法为pooling+卷积操作,为了防止出现特征表示的瓶颈,往往需要更多的卷积核,例如输入为n个d×d的feature map,共有k个卷积核,pooling时stride=2,为不出现特征表示瓶颈,往往k的取值为2n,通过引入inception module结构,即降低计算复杂度,又不会出现特征表示瓶颈,实现上有如下两种方式:
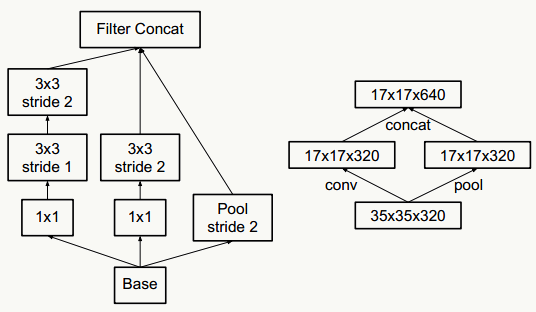
5.14.2 平滑样本标注
对于多分类的样本标注一般是one-hot的,例如[0,0,0,1],使用类似交叉熵的损失函数会使得模型学习中对ground truth标签分配过于置信的概率,并且由于ground truth标签的logit值与其他标签差距过大导致,出现过拟合,导致降低泛化性。一种解决方法是加正则项,即对样本标签给个概率分布做调节,使得样本标注变成“soft”的,例如[0.1,0.2,0.1,0.6],这种方式在实验中降低了top-1和top-5的错误率0.2%。
5.14.3 网络结构


5.14.4 代码实践
为了能在单机跑起来,对feature map做了缩减,为适应cifar10的输入大小,对输入的stride做了调整,代码如下。
# -*- coding: utf-8 -*-import numpy as npfrom keras.layers import Input, merge, Dropout, Dense, Lambda, Flatten, Activation, mergefrom keras.layers.convolutional import MaxPooling2D, Conv2D, AveragePooling2Dfrom keras.layers.normalization import BatchNormalizationfrom keras.layers.merge import concatenate, addfrom keras.regularizers import l1_l2from keras.models import Modelfrom keras.callbacks import CSVLogger, ReduceLROnPlateau, ModelCheckpoint, EarlyStoppinglr_reducer = ReduceLROnPlateau(monitor='val_loss', factor=np.sqrt(0.5), cooldown=0, patience=3, min_lr=1e-6)early_stopper = EarlyStopping(monitor='val_acc', min_delta=0.0005, patience=15)csv_logger = CSVLogger('resnet34_cifar10.csv')from keras.utils.vis_utils import plot_modelimport osfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.utils import np_utilsfrom keras.datasets import cifar10from keras import backend as Kimport tensorflow as tftf.python.control_flow_ops = tfimport warningswarnings.filterwarnings('ignore')filter_control = 8def bn_relu(input):"""Helper to build a BN -> relu block"""norm = BatchNormalization()(input)return Activation("relu")(norm)def before_inception(input_shape, small_mode=False):input_layer = input_shapeif small_mode:strides = (1, 1)else:strides = (2, 2)before_conv1_3x3 = Conv2D(name="before_conv1_3x3/2",filters=32 // filter_control,kernel_size=(3, 3),strides=strides,kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.00001))(input_layer)before_conv2_3x3 = Conv2D(name="before_conv2_3x3/1",filters=32 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.00001))(before_conv1_3x3)before_conv3_3x3 = Conv2D(name="before_conv3_3x3/1",filters=64 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(before_conv2_3x3)before_pool1_3x3 = MaxPooling2D(name="before_pool1_3x3/2",pool_size=(3, 3),strides=strides,padding='valid')(before_conv3_3x3)before_conv4_3x3 = Conv2D(name="before_conv4_3x3/1",filters=80 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='valid',kernel_regularizer=l1_l2(0.00001))(before_pool1_3x3)before_conv5_3x3 = Conv2D(name="before_conv3_3x3/2",filters=192 // filter_control,kernel_size=(3, 3),strides=strides,kernel_initializer='he_normal',activation='relu',padding='valid',kernel_regularizer=l1_l2(0.00001))(before_conv4_3x3)before_conv6_3x3 = Conv2D(name="before_conv6_3x3/1",filters=288 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='valid',kernel_regularizer=l1_l2(0.00001))(before_conv5_3x3)return before_conv6_3x3def inception_A(i, input_shape):input_layer = input_shape# (20,20,288)inception_A_conv1_1x1 = Conv2D(name="inception_A_conv1_1x1/1" + i,filters=64 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_A_conv2_3x3 = Conv2D(name="inception_A_conv2_3x3/1" + i,filters=96 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_A_conv1_1x1)inception_A_conv3_3x3 = Conv2D(name="inception_A_conv3_3x3/1" + i,filters=96 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_A_conv2_3x3)inception_A_conv4_1x1 = Conv2D(name="inception_A_conv4_1x1/1" + i,filters=48 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_A_conv5_3x3 = Conv2D(name="inception_A_conv5_3x3/1" + i,filters=64 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_A_conv4_1x1)inception_A_pool1_3x3 = AveragePooling2D(name="inception_A_pool1_3x3/1" + i,pool_size=(3, 3),strides=(1, 1),padding='same')(input_layer)inception_A_conv6_1x1 = Conv2D(name="inception_A_conv6_1x1/1" + i,filters=64 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_A_pool1_3x3)inception_A_conv7_1x1 = Conv2D(name="inception_A_conv7_1x1/1" + i,filters=64 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_A_merge1 = concatenate([inception_A_conv3_3x3, inception_A_conv5_3x3, inception_A_conv6_1x1, inception_A_conv7_1x1])return bn_relu(inception_A_merge1)def inception_B(i, input_shape):input_layer = input_shapeinception_B_conv1_1x1 = Conv2D(name="inception_B_conv1_1x1/1" + i,filters=128 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_B_conv2_1x7 = Conv2D(name="inception_A_conv2_3x3/1" + i,filters=128 // filter_control,kernel_size=(1, 7),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_B_conv1_1x1)inception_B_conv3_7x1 = Conv2D(name="inception_B_conv3_7x1/1" + i,filters=128 // filter_control,kernel_size=(7, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_B_conv2_1x7)inception_B_conv4_1x7 = Conv2D(name="inception_B_conv4_1x7/1" + i,filters=128 // filter_control,kernel_size=(1, 7),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_B_conv3_7x1)inception_B_conv5_7x1 = Conv2D(name="inception_B_conv5_7x1/1" + i,filters=192 // filter_control,kernel_size=(7, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_B_conv4_1x7)inception_B_conv6_1x1 = Conv2D(name="inception_B_conv6_1x1/1" + i,filters=128 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_B_conv7_1x7 = Conv2D(name="inception_B_conv7_1x7/1" + i,filters=128 // filter_control,kernel_size=(1, 7),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_B_conv6_1x1)inception_B_conv8_7x1 = Conv2D(name="inception_B_conv8_7x1/1" + i,filters=192 // filter_control,kernel_size=(7, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_B_conv7_1x7)inception_B_pool1_3x3 = AveragePooling2D(name="inception_B_pool1_3x3/1" + i,pool_size=(3, 3),strides=(1, 1),padding='same')(input_layer)inception_B_conv9_1x1 = Conv2D(name="inception_B_conv9_1x1/1" + i,filters=192 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_B_pool1_3x3)inception_B_conv10_1x1 = Conv2D(name="inception_B_conv10_1x1/1" + i,filters=192 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_B_merge1 = concatenate([inception_B_conv5_7x1, inception_B_conv8_7x1, inception_B_conv9_1x1, inception_B_conv10_1x1])return bn_relu(inception_B_merge1)def inception_C(i, input_shape):input_layer = input_shapeinception_C_conv1_1x1 = Conv2D(name="inception_C_conv1_1x1/1" + i,filters=448 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_C_conv2_3x3 = Conv2D(name="inception_C_conv2_3x3/1" + i,filters=384 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_C_conv1_1x1)inception_C_conv3_1x3 = Conv2D(name="inception_C_conv3_1x3/1" + i,filters=384 // filter_control,kernel_size=(1, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_C_conv2_3x3)inception_C_conv4_3x1 = Conv2D(name="inception_C_conv4_3x1/1" + i,filters=384 // filter_control,kernel_size=(3, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_C_conv2_3x3)inception_C_merge1 = concatenate([inception_C_conv3_1x3, inception_C_conv4_3x1])inception_C_conv5_1x1 = Conv2D(name="inception_C_conv5_1x1/1" + i,filters=384 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_C_conv6_1x3 = Conv2D(name="inception_C_conv6_1x3/1" + i,filters=384 // filter_control,kernel_size=(1, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_C_conv5_1x1)inception_C_conv7_3x1 = Conv2D(name="inception_C_conv7_3x1/1" + i,filters=384 // filter_control,kernel_size=(3, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_C_conv5_1x1)inception_C_merge2 = concatenate([inception_C_conv6_1x3, inception_C_conv7_3x1])inception_C_pool1_3x3 = AveragePooling2D(name="inception_C_pool1_3x3/1" + i,pool_size=(3, 3),strides=(1, 1),padding='same')(input_layer)inception_C_conv8_1x1 = Conv2D(name="inception_C_conv8_1x1/1" + i,filters=192 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(inception_C_pool1_3x3)inception_C_conv9_1x1 = Conv2D(name="inception_C_conv9_1x1/1" + i,filters=320 // filter_control,kernel_size=(1, 1),strides=(1, 1),kernel_initializer='he_normal',activation='relu',padding='same',kernel_regularizer=l1_l2(0.00001))(input_layer)inception_C_merge3 = concatenate([inception_C_merge1, inception_C_merge2, inception_C_conv8_1x1, inception_C_conv9_1x1])return bn_relu(inception_C_merge3)def create_inception_v3(input_shape, nb_classes=10, small_mode=False):input_layer = Input(input_shape)x = before_inception(input_layer, small_mode)# 3 x Inception Afor i in range(3):x = inception_A(str(i), x)# 5 x Inception Bfor i in range(5):x = inception_B(str(i), x)# 2 x Inception Cfor i in range(2):x = inception_C(str(i), x)x = AveragePooling2D((8, 8), strides=(1, 1))(x)# Dropoutx = Dropout(0.8)(x)x = Flatten()(x)# Outputout = Dense(output_dim=nb_classes, activation='softmax')(x)model = Model(input_layer, output=out, name='Inception-v3')return modelif __name__ == "__main__":with tf.device('/gpu:3'):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)os.environ["CUDA_VISIBLE_DEVICES"] = "3"tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))(x_train, y_train), (x_test, y_test) = cifar10.load_data()# reorder dimensions for tensorflowx_train = np.transpose(x_train.astype('float32') / 255., (0, 1, 2, 3))x_test = np.transpose(x_test.astype('float32') / 255., (0, 1, 2, 3))print('x_train shape:', x_train.shape)print(x_train.shape[0], 'train samples')print(x_test.shape[0], 'test samples')# convert class vectors to binary class matricesy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)s = x_train.shape[1:]batch_size = 128nb_epoch = 10nb_classes = 10model = create_inception_v3(s, nb_classes)model.summary()plot_model(model, to_file="GoogLeNet-Inception-V3.jpg", show_shapes=True)model.compile(optimizer='adadelta',loss='categorical_crossentropy',metrics=['accuracy'])model.fit(x_train, y_train,batch_size=batch_size, nb_epoch=nb_epoch, verbose=1,validation_data=(x_test, y_test), shuffle=True,callbacks=[])# Model saving callbackcheckpointer = ModelCheckpoint("weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5", monitor='val_loss',verbose=0,save_best_only=False, save_weights_only=False, mode='auto')print('Using real-time data augmentation.')datagen_train = ImageDataGenerator(featurewise_center=False,samplewise_center=False,featurewise_std_normalization=False,samplewise_std_normalization=False,zca_whitening=False,rotation_range=0,width_shift_range=0.125,height_shift_range=0.125,horizontal_flip=True,vertical_flip=False)datagen_train.fit(x_train)history = model.fit_generator(datagen_train.flow(x_train, y_train, batch_size=batch_size, shuffle=True),samples_per_epoch=x_train.shape[0],nb_epoch=nb_epoch, verbose=1,validation_data=(x_test, y_test),callbacks=[lr_reducer, early_stopper, csv_logger, checkpointer])
5.15 GoogLeNet Inception V4/ResNet V1/V2
这三种结构在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》一文中提出,论文的亮点是:提出了效果更好的GoogLeNet Inception v4网络结构;与残差网络融合,提出效果不逊于v4但训练速度更快的结构。
5.15.1 GoogLeNet Inception V4网络结构
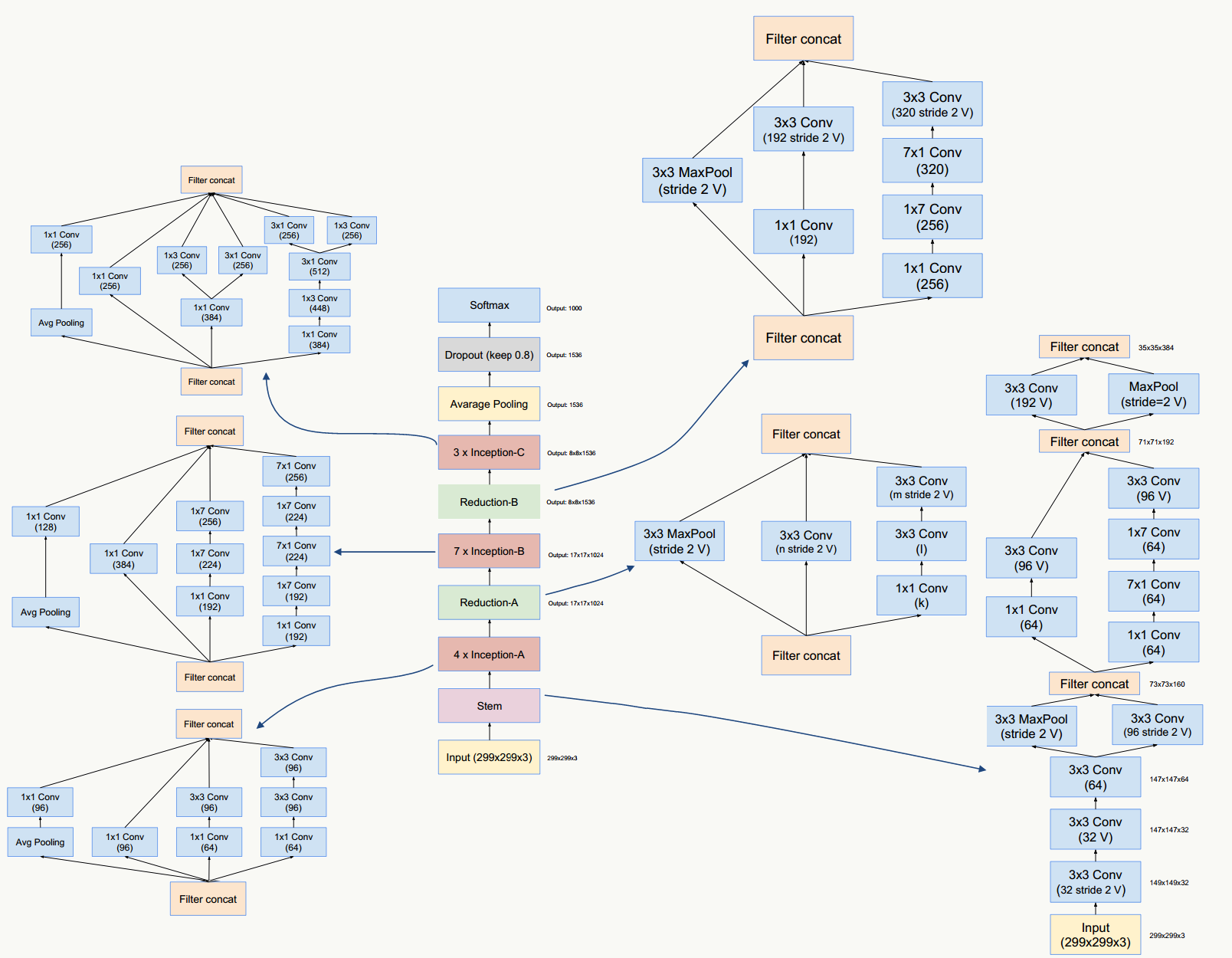
5.15.2 GoogLeNet Inception ResNet网络结构

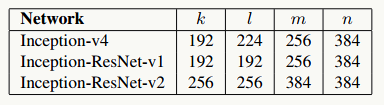
5.15.3 代码实践
GoogLeNet Inception ResNet V2
# -*- coding: utf-8 -*-import numpy as npfrom keras.layers import Input, merge, Dropout, Dense, Lambda, Flatten, Activationfrom keras.layers.convolutional import MaxPooling2D, Conv2D, AveragePooling2Dfrom keras.layers.normalization import BatchNormalizationfrom keras.layers.merge import concatenate, addfrom keras.regularizers import l1_l2from keras.models import Modelfrom keras.callbacks import CSVLogger, ReduceLROnPlateau, ModelCheckpoint, EarlyStoppinglr_reducer = ReduceLROnPlateau(monitor='val_loss', factor=np.sqrt(0.5), cooldown=0, patience=3, min_lr=1e-6)early_stopper = EarlyStopping(monitor='val_acc', min_delta=0.0005, patience=15)csv_logger = CSVLogger('resnet34_cifar10.csv')from keras.utils.vis_utils import plot_modelimport osfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.utils import np_utilsfrom keras.datasets import cifar10from keras import backend as Kimport tensorflow as tftf.python.control_flow_ops = tfimport warningswarnings.filterwarnings('ignore')filter_control = 8def bn_relu(input):"""Helper to build a BN -> relu block"""norm = BatchNormalization()(input)return Activation("relu")(norm)def inception_resnet_stem(input_shape, small_mode=False):input_layer = input_shapeif small_mode:strides = (1, 1)else:strides = (2, 2)stem_conv1_3x3 = Conv2D(name="stem_conv1_3x3/2",filters=32 // filter_control,kernel_size=(3, 3),strides=strides,kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input_layer)stem_conv2_3x3 = Conv2D(name="stem_conv2_3x3/1",filters=32 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_conv1_3x3)stem_conv3_3x3 = Conv2D(name="stem_conv3_3x3/1",filters=64 // filter_control,kernel_size=(3, 3),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_conv2_3x3)stem_pool1_3x3 = MaxPooling2D(name="stem_pool1_3x3/2",pool_size=(3, 3),strides=strides,padding='valid')(stem_conv3_3x3)stem_conv4_3x3 = Conv2D(name="stem_conv4_3x3/2",filters=96 // filter_control,kernel_size=(3, 3),strides=strides,padding='valid',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_conv3_3x3)stem_merge1 = concatenate([stem_pool1_3x3, stem_conv4_3x3])stem_conv5_1x1 = Conv2D(name="stem_conv5_1x1/1",filters=64 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_merge1)stem_conv6_3x3 = Conv2D(name="stem_conv6_3x3/1",filters=96 // filter_control,kernel_size=(3, 3),strides=(1, 1),kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_conv5_1x1)stem_conv7_1x1 = Conv2D(name="stem_conv7_1x1/1",filters=64 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_merge1)stem_conv8_7x1 = Conv2D(name="stem_conv8_7x1/1",filters=64 // filter_control,kernel_size=(7, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_conv7_1x1)stem_conv9_1x7 = Conv2D(name="stem_conv8_1x7/1",filters=64 // filter_control,kernel_size=(1, 7),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_conv8_7x1)stem_conv10_3x3 = Conv2D(name="stem_conv10_3x3/1",filters=96 // filter_control,kernel_size=(3, 3),strides=(1, 1),padding='valid',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_conv9_1x7)stem_merge2 = concatenate([stem_conv6_3x3, stem_conv10_3x3])stem_pool2_3x3 = MaxPooling2D(name="stem_pool2_3x3/2",pool_size=(3, 3),strides=strides,padding='valid')(stem_merge2)stem_conv11_3x3 = Conv2D(name="stem_conv11_3x3/2",filters=192 // filter_control,kernel_size=(3, 3),strides=strides,padding='valid',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(stem_merge2)stem_merge3 = concatenate([stem_pool2_3x3, stem_conv11_3x3])return bn_relu(stem_merge3)def inception_resnet_v2_A(i, input):# 输入是一个ReLU激活init = inputinception_A_conv1_1x1 = Conv2D(name="inception_A_conv1_1x1/1" + i,filters=32 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input)inception_A_conv2_1x1 = Conv2D(name="inception_A_conv2_1x1/1" + i,filters=32 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input)inception_A_conv3_3x3 = Conv2D(name="inception_A_conv3_3x3/1" + i,filters=32 // filter_control,kernel_size=(3, 3),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(inception_A_conv2_1x1)inception_A_conv4_1x1 = Conv2D(name="inception_A_conv4_1x1/1" + i,filters=32 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(input)inception_A_conv5_3x3 = Conv2D(name="inception_A_conv5_3x3/1" + i,filters=48 // filter_control,kernel_size=(3, 3),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(inception_A_conv4_1x1)inception_A_conv6_3x3 = Conv2D(name="inception_A_conv6_3x3/1" + i,filters=64 // filter_control,kernel_size=(3, 3),strides=(1, 1),padding='same',kernel_initializer='he_normal',activation='relu',kernel_regularizer=l1_l2(0.0001))(inception_A_conv5_3x3)inception_merge1 = concatenate([inception_A_conv1_1x1, inception_A_conv3_3x3, inception_A_conv6_3x3])inception_A_conv7_1x1 = Conv2D(name="inception_A_conv7_1x1/1" + i,filters=384 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='linear')(inception_merge1)out = add([input, inception_A_conv7_1x1])return bn_relu(out)def inception_resnet_v2_B(i, input):# 输入是一个ReLU激活init = inputinception_B_conv1_1x1 = Conv2D(name="inception_B_conv1_1x1/1" + i,filters=192 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)inception_B_conv2_1x1 = Conv2D(name="inception_B_conv2_1x1/1" + i,filters=128 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)inception_B_conv3_1x7 = Conv2D(name="inception_B_conv3_1x7/1" + i,filters=160 // filter_control,kernel_size=(1, 7),strides=(1, 1),padding='same',activation='relu')(inception_B_conv2_1x1)inception_B_conv4_7x1 = Conv2D(name="inception_B_conv4_7x1/1" + i,filters=192 // filter_control,kernel_size=(7, 1),strides=(1, 1),padding='same',activation='relu')(inception_B_conv3_1x7)inception_B_merge = concatenate([inception_B_conv1_1x1, inception_B_conv4_7x1])inception_B_conv7_1x1 = Conv2D(name="inception_B_conv7_1x1/1" + i,filters=1154 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='linear')(inception_B_merge)out = add([input, inception_B_conv7_1x1])return bn_relu(out)def inception_resnet_v2_C(i, input):# 输入是一个ReLU激活inception_C_conv1_1x1 = Conv2D(name="inception_C_conv1_1x1/1" + i,filters=192 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)inception_C_conv2_1x1 = Conv2D(name="inception_C_conv2_1x1/1" + i,filters=192 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)inception_C_conv3_1x3 = Conv2D(name="inception_C_conv3_1x3/1" + i,filters=224 // filter_control,kernel_size=(1, 3),strides=(1, 1),padding='same',activation='relu')(inception_C_conv2_1x1)inception_C_conv3_3x1 = Conv2D(name="inception_C_conv3_3x1/1" + i,filters=256 // filter_control,kernel_size=(3, 1),strides=(1, 1),padding='same',activation='relu')(inception_C_conv3_1x3)ir_merge = concatenate([inception_C_conv1_1x1, inception_C_conv3_3x1])inception_C_conv4_1x1 = Conv2D(name="inception_C_conv4_1x1/1" + i,filters=2048 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='linear')(ir_merge)out = add([input, inception_C_conv4_1x1])return bn_relu(out)def reduction_A(input, k=192, l=224, m=256, n=384):pool_size = (3, 3)strides = (2, 2)reduction_A_pool1 = MaxPooling2D(name="reduction_A_pool1/2",pool_size=pool_size,strides=strides,padding='valid')(input)reduction_A_conv1_3x3 = Conv2D(name="reduction_A_conv1_3x3/1",filters=n // filter_control,kernel_size=pool_size,strides=strides,activation='relu')(input)reduction_A_conv2_1x1 = Conv2D(name="reduction_A_conv2_1x1/1",filters=k // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)reduction_A_conv2_3x3 = Conv2D(name="reduction_A_conv2_3x3/1",filters=l // filter_control,kernel_size=(3, 3),strides=(1, 1),padding='same',activation='relu')(reduction_A_conv2_1x1)reduction_A_conv3_3x3 = Conv2D(name="reduction_A_conv3_3x3/1",filters=m // filter_control,kernel_size=pool_size,strides=strides,activation='relu')(reduction_A_conv2_3x3)reduction_A_merge = concatenate([reduction_A_pool1, reduction_A_conv1_3x3, reduction_A_conv3_3x3])return reduction_A_mergedef reduction_B(input):pool_size = (3, 3)strides = (2, 2)reduction_B_pool1 = MaxPooling2D(name="reduction_B_pool1/2",pool_size=pool_size,strides=strides,padding='valid')(input)reduction_B_conv1_1x1 = Conv2D(name="reduction_B_conv3_3x3/1",filters=256 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)reduction_B_conv2_3x3 = Conv2D(name="reduction_B_conv2_3x3/1",filters=288 // filter_control,kernel_size=pool_size,strides=strides,activation='relu')(reduction_B_conv1_1x1)reduction_B_conv3_1x1 = Conv2D(name="reduction_B_conv3_1x1/1",filters=256 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)reduction_B_conv4_3x3 = Conv2D(name="reduction_B_conv4_3x3/1",filters=288 // filter_control,kernel_size=pool_size,strides=strides,activation='relu')(reduction_B_conv3_1x1)reduction_B_conv5_1x1 = Conv2D(name="reduction_B_conv5_1x1/1",filters=256 // filter_control,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(input)reduction_B_conv5_3x3 = Conv2D(name="reduction_B_conv5_3x3/1",filters=288 // filter_control,kernel_size=(3, 3),strides=(1, 1),padding='same',activation='relu')(reduction_B_conv5_1x1)reduction_B_conv6_3x3 = Conv2D(name="reduction_B_conv6_3x3/1",filters=320 // filter_control,kernel_size=pool_size,strides=strides,activation='relu')(reduction_B_conv5_3x3)reduction_B_merge = concatenate([reduction_B_pool1, reduction_B_conv2_3x3, reduction_B_conv4_3x3, reduction_B_conv6_3x3])return reduction_B_mergedef create_inception_resnet_v2(input_shape, nb_classes=10, small_mode=False):input_layer = Input(input_shape)x = inception_resnet_stem(input_layer, small_mode)# 10 x Inception Resnet Afor i in range(10):x = inception_resnet_v2_A(str(i), x)# Reduction Ax = reduction_A(x, k=256, l=256, m=384, n=384)# 20 x Inception Resnet Bfor i in range(20):x = inception_resnet_v2_B(str(i), x)# 对32*32*3的数据可以更改pooling层aout = AveragePooling2D((5, 5), strides=(3, 3))(x)aout = Conv2D(name="conv1_1x1/1",filters=128,kernel_size=(1, 1),strides=(1, 1),padding='same',activation='relu')(aout)aout = Conv2D(name="conv1_5x5/1",filters=768,kernel_size=(5, 5),strides=(1, 1),padding='same',activation='relu')(aout)aout = Flatten()(aout)aout = Dense(nb_classes, activation='softmax')(aout)# Reduction Resnet Bx = reduction_B(x)# 10 x Inception Resnet Cfor i in range(10):x = inception_resnet_v2_C(str(i), x)# 需要视情况更改x = AveragePooling2D((4, 4), strides=(1, 1))(x)# Dropoutx = Dropout(0.8)(x)x = Flatten()(x)# Outputout = Dense(output_dim=nb_classes, activation='softmax')(x)# 简单起见去掉附加目标函数# model = Model(input_layer, output=[out, aout], name='Inception-Resnet-v2')model = Model(input_layer, output=out, name='Inception-Resnet-v2')return modelif __name__ == "__main__":with tf.device('/gpu:3'):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)os.environ["CUDA_VISIBLE_DEVICES"] = "3"tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))(x_train, y_train), (x_test, y_test) = cifar10.load_data()# reorder dimensions for tensorflowx_train = np.transpose(x_train.astype('float32') / 255., (0, 1, 2, 3))x_test = np.transpose(x_test.astype('float32') / 255., (0, 1, 2, 3))print('x_train shape:', x_train.shape)print(x_train.shape[0], 'train samples')print(x_test.shape[0], 'test samples')# convert class vectors to binary class matricesy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)s = x_train.shape[1:]batch_size = 128nb_epoch = 10nb_classes = 10model = create_inception_resnet_v2(s, nb_classes, False, True)model.summary()plot_model(model, to_file="GoogLeNet-Inception-Resnet-V2.jpg", show_shapes=True)model.compile(optimizer='adadelta',loss='categorical_crossentropy',metrics=['accuracy'])# Model saving callbackcheckpointer = ModelCheckpoint("weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5", monitor='val_loss',verbose=0,save_best_only=False, save_weights_only=False, mode='auto')print('Using real-time data augmentation.')datagen_train = ImageDataGenerator(featurewise_center=False,samplewise_center=False,featurewise_std_normalization=False,samplewise_std_normalization=False,zca_whitening=False,rotation_range=0,width_shift_range=0.125,height_shift_range=0.125,horizontal_flip=True,vertical_flip=False)datagen_train.fit(x_train)history = model.fit_generator(datagen_train.flow(x_train, y_train, batch_size=batch_size, shuffle=True),samples_per_epoch=x_train.shape[0],nb_epoch=nb_epoch, verbose=1,validation_data=(x_test, y_test),callbacks=[lr_reducer, early_stopper, csv_logger, checkpointer])
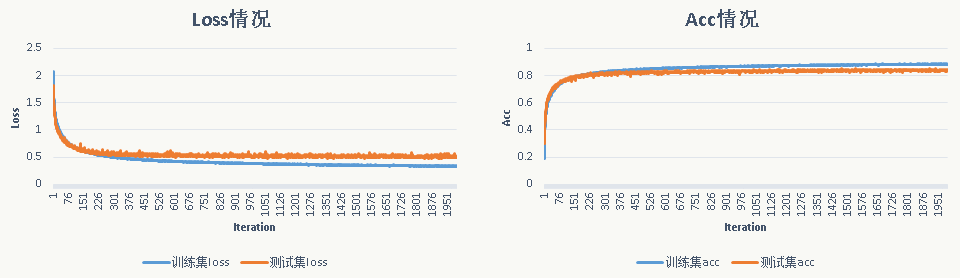
5.16 模型可视化
5.16.1 一些说明
神经网络本身包含了一系列特征提取器,理想的feature map应该是稀疏的以及包含典型的局部信息,通过模型可视化能有一些直观的认识并帮助我们调试模型,比如:feature map与原图很接近,说明它没有学到什么特征;或者它几乎是一个纯色的图,说明它太过稀疏,可能是我们feature map数太多了。可视化有很多种,比如:feature map可视化、权重可视化等等,我以feature map可视化为例。
利用keras,采用在imagenet 1000分类的数据集上预训练好的googLeNet inception v3做实验,以下面两张图作为输入。
输入图片
奥迪A7及其分类结果:原图

北汽绅宝D50及其分类结果:原图

feature map可视化
取网络的前15层,每层取前3个feature map。
奥迪A7 feature map:

北汽绅宝D50 feature map:

从左往右看,可以看到整个特征提取的过程,有的分离背景、有的提取轮廓,有的提取色差,但也能发现10、11层中间两个feature map是纯色的,可能这一层feature map数有点多了,另外北汽绅宝D50的光晕对feature map中光晕的影响也能比较明显看到。
- Hypercolumns
通常我们把神经网络最后一个fc全连接层作为整个图片的特征表示,但是这一表示可能过于粗糙(从上面的feature map可视化也能看出来),没法精确描述局部空间上的特征,而网络的第一层空间特征又太过精确,缺乏语义信息(比如后面的色差、轮廓等),于是论文《Hypercolumns for Object Segmentation and Fine-grained Localization》提出一种新的特征表示方法:Hypercolumns——将一个像素的 hypercolumn 定义为所有 cnn 单元对应该像素位置的激活输出值组成的向量),比较好的tradeoff了前面两个问题,直观地看如图:

把奥迪A7 第1、4、7层的feature map以及第1, 4, 7, 10, 11, 14, 17层的feature map分别做平均,可视化如下:

把北汽绅宝D50 第1、4、7层的feature map以及第1, 4, 7, 10, 11, 14, 17层的feature map分别做平均,可视化如下:
5.16.2 代码实践
需要安装opencv,注意它与python的版本兼容性,test_opencv函数可以测试是否安装成功。
# -*- coding: utf-8 -*-from keras.applications import InceptionV3from keras.applications.inception_v3 import preprocess_inputfrom keras.preprocessing import imagefrom keras.models import Modelfrom keras.applications.imagenet_utils import decode_predictionsimport numpy as npimport cv2from cv2 import *import matplotlib.pyplot as pltimport scipy as spfrom scipy.misc import toimagedef test_opencv():# 加载摄像头cam = VideoCapture(0) # 0 -> 摄像头序号,如果有两个三个四个摄像头,要调用哪一个数字往上加嘛# 抓拍 5 张小图片for x in range(0, 5):s, img = cam.read()if s:imwrite("o-" + str(x) + ".jpg", img)def load_original(img_path):# 把原始图片压缩为 299*299大小im_original = cv2.resize(cv2.imread(img_path), (299, 299))im_converted = cv2.cvtColor(im_original, cv2.COLOR_BGR2RGB)plt.figure(0)plt.subplot(211)plt.imshow(im_converted)return im_originaldef load_fine_tune_googlenet_v3(img):# 加载fine-tuning googlenet v3模型,并做预测model = InceptionV3(include_top=True, weights='imagenet')model.summary()x = image.img_to_array(img)x = np.expand_dims(x, axis=0)x = preprocess_input(x)preds = model.predict(x)print('Predicted:', decode_predictions(preds))plt.subplot(212)plt.plot(preds.ravel())plt.show()return model, xdef extract_features(ins, layer_id, filters, layer_num):'''提取指定模型指定层指定数目的feature map并输出到一幅图上.:param ins: 模型实例:param layer_id: 提取指定层特征:param filters: 每层提取的feature map数:param layer_num: 一共提取多少层feature map:return: None'''if len(ins) != 2:print('parameter error:(model, instance)')return Nonemodel = ins[0]x = ins[1]if type(layer_id) == type(1):model_extractfeatures = Model(input=model.input, output=model.get_layer(index=layer_id).output)else:model_extractfeatures = Model(input=model.input, output=model.get_layer(name=layer_id).output)fc2_features = model_extractfeatures.predict(x)if filters > len(fc2_features[0][0][0]):print('layer number error.', len(fc2_features[0][0][0]),',',filters)return Nonefor i in range(filters):plt.subplots_adjust(left=0, right=1, bottom=0, top=1)plt.subplot(filters, layer_num, layer_id + 1 + i * layer_num)plt.axis("off")if i < len(fc2_features[0][0][0]):plt.imshow(fc2_features[0, :, :, i])# 层数、模型、卷积核数def extract_features_batch(layer_num, model, filters):'''批量提取特征:param layer_num: 层数:param model: 模型:param filters: feature map数:return: None'''plt.figure(figsize=(filters, layer_num))plt.subplot(filters, layer_num, 1)for i in range(layer_num):extract_features(model, i, filters, layer_num)plt.savefig('sample.jpg')plt.show()def extract_features_with_layers(layers_extract):'''提取hypercolumn并可视化.:param layers_extract: 指定层列表:return: None'''hc = extract_hypercolumn(x[0], layers_extract, x[1])ave = np.average(hc.transpose(1, 2, 0), axis=2)plt.imshow(ave)plt.show()def extract_hypercolumn(model, layer_indexes, instance):'''提取指定模型指定层的hypercolumn向量:param model: 模型:param layer_indexes: 层id:param instance: 模型:return:'''feature_maps = []for i in layer_indexes:feature_maps.append(Model(input=model.input, output=model.get_layer(index=i).output).predict(instance))hypercolumns = []for convmap in feature_maps:for i in convmap[0][0][0]:upscaled = sp.misc.imresize(convmap[0, :, :, i], size=(299, 299), mode="F", interp='bilinear')hypercolumns.append(upscaled)return np.asarray(hypercolumns)if __name__ == '__main__':img_path = 'd:\car3.jpg'img = load_original(img_path)x = load_fine_tune_googlenet_v3(img)extract_features_batch(15, x, 3)extract_features_with_layers([1, 4, 7])extract_features_with_layers([1, 4, 7, 10, 11, 14, 17])
6. 循环神经网络(待填坑)
6.1 RNN
6.1.1 解决的问题
6.1.2 基本结构
6.1.3 BPTT
6.1.4 模型缺点
6.1.5 代码实践
6.2 LSTM
6.2.1 解决的问题
6.2.2 基本结构
6.2.3 模型缺点
6.2.4 代码实践
6.3 Sequence to Sequence应用
7. 对抗神经网络(待填坑)
7.1 GANs
7.2 Wasserstein GAN
7.3 代码实践
8. 目标检测
目标检测的发展历程大致如下:

8.1 Selective Search
对于目标识别任务,比如判断一张图片中有没有车、是什么车,一般需要解决两个问题:目标检测、目标识别。而目标检测任务中通常需要先通过某种方法做图像分割,事先得到候选框;直观的做法是:给定窗口,对整张图片滑动扫描,结束后改变窗口大小重复上面步骤,缺点很明显:重复劳动耗费资源、精度和质量不高等等。
针对上面的问题,一种解决方案是借鉴启发式搜索的方法,充分利用人类的先验知识。J.R.R. Uijlings在《Selective Search for Object Recoginition》提出一种方法:基于数据驱动,与具体类别无关的多种策略融合的启发式生成方法。图片包含各种丰富信息,例如:大小、形状、颜色、纹理、物体重叠关系等,如果只使用一种信息往往不能解决大部分问题,例如:

左边的两只猫可以通过颜色区别而不是通过纹理,右面的变色龙却只能通过纹理区别而不是颜色。
8.1.1 启发式生成设计准则
所以概括来说:
- 能够捕捉到各种尺度物体,大的、小的、边界清楚的、边界模糊的等等;
多尺度的例子:

- 策略多样性,采用多样的策略集合共同作用;
- 计算快速,由于生成候选框只是检测第一步,所以计算上它决不能成为瓶颈。
8.1.2 Selective Search
基于以上准则设计Selective Search算法:
- 采用层次分组算法解决尺度问题。
引入图像分割中的自下而上分组思想,由于整个过程是层次的,在将整个图合并成一个大的区域的过程中会输出不同尺度的多个子区域。整个过程如下:
1、利用《Efficient Graph-Based Image Segmentation》(基本思想:将图像中每个像素表示为图上的一个节点,用于连接不同节点的无向边都有一个权重,这个权重表示两个节点之间的不相似度,通过贪心算法利用最小生成树做图像分割)生成初始候选区域;
2、采用贪心算法合并区域,计算任意两个领域的相似度,把达到阈值的合并,再计算新区域和其所有领域的相似度,循环迭代,直到整个图变成了一个区域,算法如下:

- 多样化策略
三个方面:使用多种颜色空间、使用多种相似度计算方法、搜索起始区域不固定。
1、颜色空间有很多种:RGB、HSV、Lab等等,不是论文重点;
2、相似度衡量算法,结合了4重策略:
◆ 颜色相似度
以RGB为例,使用L1-norm归一化每个图像通道的色彩直方图(bins=25),每个区域被表示为25×3维向量:;
颜色相似度定义为:
区域合并后对新的区域计算其色彩直方图:
新区域的大小为:
◆ 纹理相似度
使用快速生成的类SIFT特征,对每个颜色通道在8个方向上应用方差为1的高斯滤波器,对每个颜色通道的每个方向提取bins=10的直方图,所以整个纹理向量维度为:3×8×10=240,表示为:;
纹理相似度定义为:
◆ 大小相似度
该策略希望小的区域能尽早合并,让合并操作比较平滑,防止出现某个大区域逐步吞并其他小区域的情况。相似度定义为:
其中为图像包含像素点数目。
◆ 区域规则度相似度
能够框住合并后的两个区域的矩形大小越小说明两个区域的合并越规则,如:
区域规则度相似度定义为:
最终相似度为所有策略加权和,文中采用等权方式:
8.1.3 使用Selective Search做目标识别
训练过程包含:提取候选框、提取特征、生成正负样本、训练模型,图示如下:

早期图像特征提取往往是各种HOG特征或BoW特征,现在CNN特征几乎一统天下。
检测定位效果评价采用Average Best Overlap(ABO)和Mean Average Best Overlap(MABO):
其中:为类别标注、为类别下的ground truth,为通过Selective Search生成的候选框。
8.1.4 代码实践
参见AlpacaDB。
- selectivesearch.py
# -*- coding: utf-8 -*-import skimage.ioimport skimage.featureimport skimage.colorimport skimage.transformimport skimage.utilimport skimage.segmentationimport numpy# "Selective Search for Object Recognition" by J.R.R. Uijlings et al.## - Modified version with LBP extractor for texture vectorizationdef _generate_segments(im_orig, scale, sigma, min_size):"""segment smallest regions by the algorithm of Felzenswalb andHuttenlocher"""# open the Imageim_mask = skimage.segmentation.felzenszwalb(skimage.util.img_as_float(im_orig), scale=scale, sigma=sigma,min_size=min_size)# merge mask channel to the image as a 4th channelim_orig = numpy.append(im_orig, numpy.zeros(im_orig.shape[:2])[:, :, numpy.newaxis], axis=2)im_orig[:, :, 3] = im_maskreturn im_origdef _sim_colour(r1, r2):"""calculate the sum of histogram intersection of colour"""return sum([min(a, b) for a, b in zip(r1["hist_c"], r2["hist_c"])])def _sim_texture(r1, r2):"""calculate the sum of histogram intersection of texture"""return sum([min(a, b) for a, b in zip(r1["hist_t"], r2["hist_t"])])def _sim_size(r1, r2, imsize):"""calculate the size similarity over the image"""return 1.0 - (r1["size"] + r2["size"]) / imsizedef _sim_fill(r1, r2, imsize):"""calculate the fill similarity over the image"""bbsize = ((max(r1["max_x"], r2["max_x"]) - min(r1["min_x"], r2["min_x"]))* (max(r1["max_y"], r2["max_y"]) - min(r1["min_y"], r2["min_y"])))return 1.0 - (bbsize - r1["size"] - r2["size"]) / imsizedef _calc_sim(r1, r2, imsize):return (_sim_colour(r1, r2) + _sim_texture(r1, r2)+ _sim_size(r1, r2, imsize) + _sim_fill(r1, r2, imsize))def _calc_colour_hist(img):"""calculate colour histogram for each regionthe size of output histogram will be BINS * COLOUR_CHANNELS(3)number of bins is 25 as same as [uijlings_ijcv2013_draft.pdf]extract HSV"""BINS = 25hist = numpy.array([])for colour_channel in (0, 1, 2):# extracting one colour channelc = img[:, colour_channel]# calculate histogram for each colour and join to the resulthist = numpy.concatenate([hist] + [numpy.histogram(c, BINS, (0.0, 255.0))[0]])# L1 normalizehist = hist / len(img)return histdef _calc_texture_gradient(img):"""calculate texture gradient for entire imageThe original SelectiveSearch algorithm proposed Gaussian derivativefor 8 orientations, but we use LBP instead.output will be [height(*)][width(*)]"""ret = numpy.zeros((img.shape[0], img.shape[1], img.shape[2]))for colour_channel in (0, 1, 2):ret[:, :, colour_channel] = skimage.feature.local_binary_pattern(img[:, :, colour_channel], 8, 1.0)return retdef _calc_texture_hist(img):"""calculate texture histogram for each regioncalculate the histogram of gradient for each coloursthe size of output histogram will beBINS * ORIENTATIONS * COLOUR_CHANNELS(3)"""BINS = 10hist = numpy.array([])for colour_channel in (0, 1, 2):# mask by the colour channelfd = img[:, colour_channel]# calculate histogram for each orientation and concatenate them all# and join to the resulthist = numpy.concatenate([hist] + [numpy.histogram(fd, BINS, (0.0, 1.0))[0]])# L1 Normalizehist = hist / len(img)return histdef _extract_regions(img):R = {}# get hsv imagehsv = skimage.color.rgb2hsv(img[:, :, :3])# pass 1: count pixel positionsfor y, i in enumerate(img):for x, (r, g, b, l) in enumerate(i):# initialize a new regionif l not in R:R[l] = {"min_x": 0xffff, "min_y": 0xffff,"max_x": 0, "max_y": 0, "labels": [l]}# bounding boxif R[l]["min_x"] > x:R[l]["min_x"] = xif R[l]["min_y"] > y:R[l]["min_y"] = yif R[l]["max_x"] < x:R[l]["max_x"] = xif R[l]["max_y"] < y:R[l]["max_y"] = y# pass 2: calculate texture gradienttex_grad = _calc_texture_gradient(img)# pass 3: calculate colour histogram of each regionfor k, v in R.items():# colour histogrammasked_pixels = hsv[:, :, :][img[:, :, 3] == k]R[k]["size"] = len(masked_pixels / 4)R[k]["hist_c"] = _calc_colour_hist(masked_pixels)# texture histogramR[k]["hist_t"] = _calc_texture_hist(tex_grad[:, :][img[:, :, 3] == k])return Rdef _extract_neighbours(regions):def intersect(a, b):if (a["min_x"] < b["min_x"] < a["max_x"]and a["min_y"] < b["min_y"] < a["max_y"]) or (a["min_x"] < b["max_x"] < a["max_x"]and a["min_y"] < b["max_y"] < a["max_y"]) or (a["min_x"] < b["min_x"] < a["max_x"]and a["min_y"] < b["max_y"] < a["max_y"]) or (a["min_x"] < b["max_x"] < a["max_x"]and a["min_y"] < b["min_y"] < a["max_y"]):return Truereturn FalseR = regions.items()neighbours = []for cur, a in enumerate(R[:-1]):for b in R[cur + 1:]:if intersect(a[1], b[1]):neighbours.append((a, b))return neighboursdef _merge_regions(r1, r2):new_size = r1["size"] + r2["size"]rt = {"min_x": min(r1["min_x"], r2["min_x"]),"min_y": min(r1["min_y"], r2["min_y"]),"max_x": max(r1["max_x"], r2["max_x"]),"max_y": max(r1["max_y"], r2["max_y"]),"size": new_size,"hist_c": (r1["hist_c"] * r1["size"] + r2["hist_c"] * r2["size"]) / new_size,"hist_t": (r1["hist_t"] * r1["size"] + r2["hist_t"] * r2["size"]) / new_size,"labels": r1["labels"] + r2["labels"]}return rtdef selective_search(im_orig, scale=1.0, sigma=0.8, min_size=50):'''Selective SearchParameters----------im_orig : ndarrayInput imagescale : intFree parameter. Higher means larger clusters in felzenszwalb segmentation.sigma : floatWidth of Gaussian kernel for felzenszwalb segmentation.min_size : intMinimum component size for felzenszwalb segmentation.Returns-------img : ndarrayimage with region labelregion label is stored in the 4th value of each pixel [r,g,b,(region)]regions : array of dict[{'rect': (left, top, right, bottom),'labels': [...]},...]'''assert im_orig.shape[2] == 3, "3ch image is expected"# load image and get smallest regions# region label is stored in the 4th value of each pixel [r,g,b,(region)]img = _generate_segments(im_orig, scale, sigma, min_size)if img is None:return None, {}imsize = img.shape[0] * img.shape[1]R = _extract_regions(img)# extract neighbouring informationneighbours = _extract_neighbours(R)# calculate initial similaritiesS = {}for (ai, ar), (bi, br) in neighbours:S[(ai, bi)] = _calc_sim(ar, br, imsize)# hierarchal searchwhile S != {}:# get highest similarityi, j = sorted(S.items(), cmp=lambda a, b: cmp(a[1], b[1]))[-1][0]# merge corresponding regionst = max(R.keys()) + 1.0R[t] = _merge_regions(R[i], R[j])# mark similarities for regions to be removedkey_to_delete = []for k, v in S.items():if (i in k) or (j in k):key_to_delete.append(k)# remove old similarities of related regionsfor k in key_to_delete:del S[k]# calculate similarity set with the new regionfor k in filter(lambda a: a != (i, j), key_to_delete):n = k[1] if k[0] in (i, j) else k[0]S[(t, n)] = _calc_sim(R[t], R[n], imsize)regions = []for k, r in R.items():regions.append({'rect': (r['min_x'], r['min_y'],r['max_x'] - r['min_x'], r['max_y'] - r['min_y']),'size': r['size'],'labels': r['labels']})return img, regions
- example.py
# -*- coding: utf-8 -*-import matplotlibmatplotlib.use("Agg")import matplotlib.pyplot as pltimport skimage.dataimport skimage.iofrom skimage.io import use_plugin,imreadimport matplotlib.patches as mpatchesfrom matplotlib.pyplot import savefigimport selectivesearchdef main():# loading astronaut image#img = skimage.data.astronaut()use_plugin('pil')img = imread('car.jpg', as_grey=False)# perform selective searchimg_lbl, regions = selectivesearch.selective_search(img, scale=500, sigma=0.9, min_size=10)candidates = set()for r in regions:# excluding same rectangle (with different segments)if r['rect'] in candidates:continue# excluding regions smaller than 2000 pixelsif r['size'] < 2000:continue# distorted rectsx, y, w, h = r['rect']if w / h > 1.2 or h / w > 1.2:continuecandidates.add(r['rect'])# draw rectangles on the original imageplt.figure()fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img)for x, y, w, h in candidates:print x, y, w, hrect = mpatches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1)ax.add_patch(rect)#plt.show()savefig('MyFig.jpg')if __name__ == "__main__":main()
car.jpg原图如下:

结果图如下:

8.2 OverFeat
计算机视觉有三大任务:分类(识别)、定位、检测,从左到右每个任务是下个任务的子任务,所以难度递增。OverFeat是2014年《OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks》中提出的一个基于卷积神经网络的特征提取框架,论文的最大亮点在于通过一个统一的框架去解决图像分类、定位、检测问题,并提出feature map上的一个点可以还原并对应到原图的一个区域,于是一些在原图上的操作可以转到在feature map上做,这点对以后的检测算法有较深远的影响。它在ImageNet 2013的task 3定位任务中获得第一,在检测和分类任务中也有不错的表现。
8.2.1 OverFeat分类任务
文中借鉴了AlexNet的结构,并做了些结构改进和提高了线上inference效率,结构如下:

相对AlexNet,网络结构几乎一样,区别在于:
去掉了LRN层,不做额外归一化操作
使用区域非重叠pooling
前两层使用较小的stride,从而产生较大的feature map,提高了模型精度
- Offset Pooling
分类任务中一大亮点是提出利用Offset Pooling做多尺度分类的概念,在一维情况的解释如下:

a图代表经过第5个卷积层后的feature map有20个神经元,选取stride=3做非重叠pooling,有以下3种方式:(通常我们只使用第一种)
△=0分组:[1,2,3],[4,5,6],[7,8,9],...,[16,17,18]
△=1分组:[2,3,4],[5,6,7],[8,9,10],...,[17,18,19]
△=2分组:[3,4,5],[6,7,8],[9,10,11],...,[18,19,20]
在二维情况下,输入图像在经过FCN及第5个卷积层后得到若干个feature map,使用3x3 filter在feature map上做滑动窗口(注意此时不在原图上做,节省大量计算消耗)。按上图的原理,滑动窗口总共要做9次,从(0,0), (0,1), (0,2), (1,0), (1,1), (1,2), (2,0), (2,1), (2,2)处分别滑动。得到的feature map分别经过后面的3个FC层,得到多组特征,最后拼接起来得到最终特征向量并用于分类。
- Inference自适应输入图片大小
训练模型时往往采用的是固定大小图片(后面的SPP-net、Fast R-CNN等模型通过SPP或ROI pooling可以允许输入大小可变),当inference阶段遇到比规定大小更大的图片时怎么办?可以利用Fully Convolutional Networks(《Fully Convolutional Networks for Semantic Segmentation》)的思想:把卷积层到全连接层映射看成对整张图的卷积操作,把全连接层到全连接层的映射可以看成采用1x1卷积核的卷积操作。以下图说明:

绿色代表卷积核,蓝色代表feature map,当输入大于规定尺寸时,在黄色区域会有额外计算,最终的输出也不是一个值而是一个矩阵,可以用各种策略输出最终结果,比如一种简单做法是用矩阵平均值作为最终分类结果。
8.2.2 OverFeat定位任务
- 回归训练
相对于分类问题,定位问题可以与其共享前1~5层网络结构,这种方式也被后面的模型所借鉴,区别是增加了一个的回归损失函数,基本思路是对同一张图缩放产生多尺度图片做输入,用回归网络预测Bounding Box(后面简写为BB)后再做融合,需要注意回归层是与类别相关的,如果有1000个类则有1000个版本,每类一个。回归示意图如下:

第5层pooling结果作为输入,共256个通道,以FCN的思想理解,先走一个4096通道的全连接层再走一个1024通道的全连接层,与前面类似使用Offet Pooing和滑动窗口对每类生成一个4通道矩阵,4个通道分别代表BB的四条边的坐标。
网络输出
回归网络的输出例子如下,单图下生成多个BB的预测,这些BB倾向于收敛到一个固定位置并且可以定位物体姿势多样化的情况,当然计算复杂度不小,所以没法用到实时检测中。

预测融合策略
a. 同一幅图在6种不同缩放尺度下分别输入分类网络,每种尺度下选top k类别作为标定,用表示;
b. 对任意尺度分别输入BB 回归网络,用表示每个类别对应的BB集合;
c. 将所有合并为大集合;
d. 重复以下过程直到结束:
其中match_score为两个BB的中心点之间的距离及BB重合区域面积之和,box_merge为两个BB坐标均值,过程很好理解:所有分类(如可能有熊、鲸鱼等)的BB被放在一个大集合,多尺度得到的分类集合中,正确分类会占有优势(置信度、匹配度、BB连续度等),随着迭代的过程正确分类的BB被加强,错误分类的BB被减弱直到消失,不过这个方法确实复杂,可以看到在后来的算法有各种改进和替换。

8.2.3 OverFeat检测任务
与分类类似但需要考虑位置信息,同样采用网络结构共享特征提取,在预测分类中还需要加“背景”这一类。
8.2.4 代码实践
可参见:OverFeat
8.3 R-CNN
过去若干年,目标检测使用的都是滑动窗口的方式,这种方式计算效率较差,另外以往CNN在ImageNet比赛分类问题的表现更加突出,如何利用这些成果以及ImageNet的大量训练数据去借力打力也是一个值得研究的课题。R-CNN由Ross Girshick等人在《Rich feature hierarchies for accurate object detection and semantic segmentation》中提出,OverFeat从某种程度可以看做R-CNN的特例,R-CNN在图像检测领域有很大的影响力,该算法的亮点在于:使用Selective Search代替传统滑动窗口方式生成候选框并使用CNN提取特征;把分类和回归方法同时应用在检测中;当训练数据不足时,通过预训练利用领域数据(知识)做transfer learning,在对象数据集上再应用fine-tuning继续训练。
8.3.1 IoU
IoU(intersection over union),是用来衡量Bounding Box定位精度的指标,它的定义类似Jaccard距离,假设A为人工标定的BB,B为预测的BB则:

8.3.2 NMS
NMS(non-maximum suppression)在目标检测中用来依据置信度消除重叠度过高的重复候选框,从而提高检测算法效率。
例如,原图为:

原图+候选框为:

执行NMS后为:

代码可参考:Non-Maximum Suppression for Object Detection in Python
nms.py
# import the necessary packagesimport numpy as np# Felzenszwalb et al.def non_max_suppression_slow(boxes, overlapThresh):# if there are no boxes, return an empty listif len(boxes) == 0:return []# initialize the list of picked indexespick = []# grab the coordinates of the bounding boxesx1 = boxes[:,0]y1 = boxes[:,1]x2 = boxes[:,2]y2 = boxes[:,3]scores = boxes[:, 4]# compute the area of the bounding boxes and sort the bounding# boxes by the bottom-right y-coordinate of the bounding boxarea = (x2 - x1 + 1) * (y2 - y1 + 1)idxs = np.argsort(scores)# keep looping while some indexes still remain in the indexes# listwhile len(idxs) > 0:# grab the last index in the indexes list, add the index# value to the list of picked indexes, then initialize# the suppression list (i.e. indexes that will be deleted)# using the last indexlast = len(idxs) - 1i = idxs[last]pick.append(i)suppress = [last]# loop over all indexes in the indexes listfor pos in xrange(0, last):# grab the current indexj = idxs[pos]# find the largest (x, y) coordinates for the start of# the bounding box and the smallest (x, y) coordinates# for the end of the bounding boxxx1 = max(x1[i], x1[j])yy1 = max(y1[i], y1[j])xx2 = min(x2[i], x2[j])yy2 = min(y2[i], y2[j])# compute the width and height of the bounding boxw = max(0, xx2 - xx1 + 1)h = max(0, yy2 - yy1 + 1)# compute the ratio of overlap between the computed# bounding box and the bounding box in the area listoverlap = float(w * h) / area[j]# if there is sufficient overlap, suppress the# current bounding boxif overlap > overlapThresh:suppress.append(pos)# delete all indexes from the index list that are in the# suppression listidxs = np.delete(idxs, suppress)# return only the bounding boxes that were pickedreturn boxes[pick]
nms_slow.py
# import the necessary packagesfrom pyimagesearch.nms import non_max_suppression_slowimport numpy as npimport cv2# construct a list containing the images that will be examined# along with their respective bounding boxes# 最后一位为:分类置信度*100images = [("images/333.jpg", np.array([(285,293,713,679,96),(9,309,161,719,90),(703,259,959,659,93),(291,309,693,663,90),(1,371,155,621,80),(511,347,681,637,89),(293,587,721,671,70),(757,469,957,641,60)]))]# loop over the imagesfor (imagePath, boundingBoxes) in images:# load the image and clone itprint "[x] %d initial bounding boxes" % (len(boundingBoxes))image = cv2.imread(imagePath)orig = image.copy()# loop over the bounding boxes for each image and draw themfor (startX, startY, endX, endY, c) in boundingBoxes:cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 0, 255), 2)# perform non-maximum suppression on the bounding boxespick = non_max_suppression_slow(boundingBoxes, 0.3)print "[x] after applying non-maximum, %d bounding boxes" % (len(pick))# loop over the picked bounding boxes and draw themfor (startX, startY, endX, endY,c) in pick:cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)# display the imagescv2.imshow("Original", orig)cv2.imshow("After NMS", image)cv2.waitKey(0)
8.3.3 mAP
先介绍什么是AP,以PASCAL VOC CHALLENGE 2010以后的定义做说明。
假设个样本中有个正例,依据包含正例的个数,可以得到个recall值,分别为:,对于每个recall值可以计算出对应的最大precision,然后对这个precision值取平均即得到AP值。
举个例子,假设是否为车的分类,一共有30个测试样本,预测结果及标注如下:
| 编号 | 预测值 | 实际值 |
|---|---|---|
| 1 | 0.88 | 1 |
| 2 | 0.76 | 0 |
| 3 | 0.56 | 0 |
| 4 | 0.92 | 0 |
| 5 | 0.10 | 1 |
| 6 | 0.77 | 1 |
| 7 | 0.23 | 0 |
| 8 | 0.34 | 0 |
| 9 | 0.35 | 0 |
| 10 | 0.66 | 1 |
| 11 | 0.56 | 0 |
| 12 | 0.45 | 1 |
| 13 | 0.93 | 1 |
| 14 | 0.97 | 0 |
| 15 | 0.81 | 1 |
| 16 | 0.78 | 0 |
| 17 | 0.66 | 0 |
| 18 | 0.54 | 0 |
| 19 | 0.43 | 1 |
| 20 | 0.31 | 0 |
| 21 | 0.22 | 0 |
| 22 | 0.12 | 0 |
| 23 | 0.02 | 0 |
| 24 | 0.05 | 1 |
| 25 | 0.15 | 0 |
| 26 | 0.01 | 0 |
| 27 | 0.77 | 1 |
| 28 | 0.37 | 0 |
| 29 | 0.43 | 1 |
| 30 | 0.99 | 1 |
按照预测得分降序排列后如下:
| 编号 | 预测值 | 实际值 |
|---|---|---|
| 30 | 0.99 | 1 |
| 14 | 0.97 | 0 |
| 13 | 0.93 | 1 |
| 4 | 0.92 | 0 |
| 1 | 0.88 | 1 |
| 15 | 0.81 | 1 |
| 16 | 0.78 | 0 |
| 6 | 0.77 | 1 |
| 27 | 0.77 | 1 |
| 2 | 0.76 | 0 |
| 10 | 0.66 | 1 |
| 17 | 0.66 | 0 |
| 3 | 0.56 | 0 |
| 11 | 0.56 | 0 |
| 18 | 0.54 | 0 |
| 12 | 0.45 | 1 |
| 19 | 0.43 | 1 |
| 29 | 0.43 | 1 |
| 28 | 0.37 | 0 |
| 9 | 0.35 | 0 |
| 8 | 0.34 | 0 |
| 20 | 0.31 | 0 |
| 7 | 0.23 | 0 |
| 21 | 0.22 | 0 |
| 25 | 0.15 | 0 |
| 22 | 0.12 | 0 |
| 5 | 0.10 | 1 |
| 24 | 0.05 | 1 |
| 23 | 0.02 | 0 |
| 26 | 0.01 | 0 |
AP计算过程如下(注意与AUC之间的异同):
| 编号 | 预测值 | 实际值 | Precision | Recall(r) | Max Precision with Recall(r'≥r) | AP |
| 30 | 0.99 | 1 | 1/1=1 | 1/12=0.08 | 1 | 0.609 |
| 14 | 0.97 | 0 | 1/2=0.5 | 1/12=0.08 | ||
| 13 | 0.93 | 1 | 2/3=0.67 | 2/12=0.17 | 0.67 | |
| 4 | 0.92 | 0 | 2/4=0.5 | 2/12=0.17 | ||
| 1 | 0.88 | 1 | 3/5=0.6 | 3/12=0.25 | 0.6 | |
| 15 | 0.81 | 1 | 4/6=0.67 | 4/12=0.33 | 0.67 | |
| 16 | 0.78 | 0 | 4/7=0.57 | 4/12=0.33 | ||
| 6 | 0.77 | 1 | 5/8=0.63 | 5/12=0.42 | 0.63 | |
| 27 | 0.77 | 1 | 6/9=0.67 | 6/12=0.5 | 0.67 | |
| 2 | 0.76 | 0 | 6/10=0.6 | 6/12=0.5 | ||
| 10 | 0.66 | 1 | 7/11=0.64 | 7/12=0.58 | 0.64 | |
| 17 | 0.66 | 0 | 7/12=0.58 | 7/12=0.58 | ||
| 3 | 0.56 | 0 | 7/13=0.54 | 7/12=0.58 | ||
| 11 | 0.56 | 0 | 7/14=0.5 | 7/12=0.58 | ||
| 18 | 0.54 | 0 | 7/15=0.47 | 7/12=0.58 | ||
| 12 | 0.45 | 1 | 8/16=0.5 | 8/12=0.67 | 0.5 | |
| 19 | 0.43 | 1 | 9/17=0.53 | 9/12=0.75 | 0.53 | |
| 29 | 0.43 | 1 | 10/18=0.56 | 10/12=0.83 | 0.56 | |
| 28 | 0.37 | 0 | 10/19=0.53 | 10/12=0.83 | ||
| 9 | 0.35 | 0 | 10/20=0.5 | 10/12=0.83 | ||
| 8 | 0.34 | 0 | 10/21=0.48 | 10/12=0.83 | ||
| 20 | 0.31 | 0 | 10/22=0.45 | 10/12=0.83 | ||
| 7 | 0.23 | 0 | 10/23=0.43 | 10/12=0.83 | ||
| 21 | 0.22 | 0 | 10/24=0.42 | 10/12=0.83 | ||
| 25 | 0.15 | 0 | 10/25=0.4 | 10/12=0.83 | ||
| 22 | 0.12 | 0 | 10/26=0.38 | 10/12=0.83 | ||
| 5 | 0.1 | 1 | 11/27=0.41 | 11/12=0.92 | 0.41 | |
| 24 | 0.05 | 1 | 12/28=0.43 | 12/12=1 | 0.43 | |
| 23 | 0.02 | 0 | 12/29=0.41 | 12/12=1 | ||
| 26 | 0.01 | 0 | 12/30=0.4 | 12/12=1 |
mAP是所有类别下的AP求算数平均值的结果。
8.3.4 R-CNN原理
训练阶段 整个过程分4步:

- 候选框生成阶段
利用Selective Search生成2000个候选框(BB),之前很多年人们用的都是滑动窗口方式。需要注意的是,由于候选框图片大小不一,而后续用于提特征的CNN对输入要求是固定大小的(227×227),所以需要做预处理,文中实验效果最好的方法是:不论长宽比例直接将图片缩放到227×227大小,并做padding=16的处理以保留上下文信息。 - 特征提取阶段
利用CNN提取图片特征,文中大部分实验结果采用AlexNet网络结构,小部分采用VGG16,前者训练速度快但精度相对低,后者反之,AlexNet结构如下。
- 有监督预训练
使用ImageNet ILSVRC2012分类任务的1000类训练数据训练一个AlexNet模型,由于CNN主要作用体现在特征提取中,同样是猫狗,在不同数据集上特征是一样的,所以可以在不同问题间共享特征,区别无非在最终任务目标和特征如何组合上; - 基于领域知识的fine-tuning
以上述模型做权重初始化,将softmax层1000类输出改为随机初始化权重的N+1类输出(1为背景类,对VOC,N=20),在目标训练集上继续训练,其中正样本为:与ground truth框IoU≥0.5的样本,其余的为负样本。训练时优化器采用学习率为0.001的SGD,样本采用mini-batch方式学习,大小为128,其中每个batch由采用均匀分布随机抽取的针对所有分类的32个正样本和96个负样本(背景)组成。
- 有监督预训练
- 训练分类器阶段
每一类做一个线性SVM分类器(为配合候选框特征向量的维度,每个SVM分类器为4096个权重),正样本为:每一类的ground truth,负样本为:与ground truth的IoU≤0.3的候选框(0.3这个阈值是通过在{0,0.1,0.2,0.3,0.4,0.5}集合上做grid search后观察验证集效果得到的)。
例如,对于VOC:

- 训练回归器阶段
主要目的是修正BB减少定位错误,借鉴DPM的方法,使用ridge regression修正BB位置,具体方法为:
假设输入为:候选框与ground truth框对集合,用,其中,括号中分别为候选框中心点的坐标及候选框宽与高,选取靠近(IoU≥0.6)ground truth的候选框,目标是学习一个映射使得候选框能被修正到ground truth框。利用SIT(scale-invariant translation)和LST(log-space translation)思想去学习这个变换(这里大家可以想想为什么?):
变换函数与AlexNet最后一个pooling层(4096个特征)的输出关系为:
优化目标函数为:
其中:
以上四个步骤是相互独立的,后验(马后炮)的来看,可以做这些改进:
1)、把分类和回归放在一个网络做共享特征;
2)、网络结构对输入图片大小自适应;
3)、把候选框生成算法也放在同一个网络来做共享特征;
4)、分类器抛弃SVM直接融合在神经网络中;
5)、不用每个候选框都做一次特征提取。
测试阶段过程如下:
- 使用SS提取2000个候选框
- 将候选框大小缩放到227×227
- 每个候选框输入CNN,产生特征后对每一类做SVM分类输出置信度
- 对候选框做基于贪心的NMS
- 每个候选框的BB只做一次预测
8.3.5 代码实践
作者代码能力极强,具体可见:R-CNN: Region-based Convolutional Neural Networks。
8.4 SPP-Net
SPP-Net是何凯明等人在《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》一文中提出,文章亮点是主要解决了两个问题:
1、允许CNN网络的输入图片大小不固定(后面的FCN也可以解决这个问题);
2、借鉴OverFeat只对整张图做一次特征提取,一些操作只在feature map上做而不用在原图进行且feature map上的点可以还原到原图上。
8.4.1 问题回顾
之前的CNN网络的输入都是固定大小的,好处是网络结构相对简单和计算量低,坏处是所有图片都需要做预处理,这个会损失原图信息或引入噪声。训练和预测的一般流程是:

常用的缩放方式有裁剪和缩放,例如:

分析CNN网络结构可以发现,卷积层和pooling层对图片输入大小都没有要求,唯独全连接层需要其输入是固定大小的,所以改进主要针对全连接层的输入,另外通过特征可视化观察到feature map包含了图片的空间信息,所以新方法同样需要包含空间信息,于是文中提出了通过增加SPP层解决问题,新的算法流程变为:

8.4.2 SPP详解
可以把这个问题看做如何找到输入可变,输出固定且能保留空间信息的映射问题,问题三个相关变量:feature map的大小、bin的个数(借鉴BoW《Video Google: A Text Retrieval Approach to Object Matching in Videos》的思想,表示固定特征的维度数)、pooling步长。现在feature map的大小不固定但bin的个数固定,于是唯一能自适应可变的就是pooling步长了。
假设:最后一个卷积层产生的feature map大小为,希望产生个bins,则窗口大小为,步长为,例如:

每个bin的pooling方式可以是max pooling或其他pooling。
SPP同样支持多尺度特征,例如4×4、2×2、1×1三种尺度最后拼成21×256维特征向量:

8.4.3 感受野(Receptive Field)
感受野来源于生物学,Levine and Shefner在《Fundamentals of sensation and perception》中将感受野定义为:由于受到刺激导致特定神经元发生反应的区域。比如人在观察某个物体的某个部分时由于受到刺激,物体会投影到视网膜,之后传到给大脑并激活某个区域(橘色的框框住的区域)。

CNN的任何一个卷积层或pooling层产生的任何一个feature map上的任何一点都会对应到原始图像上的某个区域,那个区域就是该点的感受野。例如,红、绿、橙三个点的感受野不同:

感受野的大小与以下两个因素有关但与是否padding无关:
1、filter的大小;
2、stride的大小。
8.4.4 feature map与原图对应关系转换
由于SPP只对原图做一次特征提取,省去了大量重复劳动,另外由于特征点的可还原性,使得后续对所有对候选框做SPP特征映射操作时只需要在最后一个卷积层产生的feature map上进行即可(否则需要考虑感受野上的所有特征映射将会产生巨大的计算量)。
详情可参考《R-CNN minus R》.
简单的转换方法为:
需要对CNN网络的所有卷积层和pooling层做padding,使得原图中的任何一点与卷积或pooling后的图上的点一一对应(边缘信息也没有丢失)。
假设:
1、任何一层的核大小为;
2、每层padding值为;
3、原图中任何一点坐标为,该点在任何一个feature map上的位置为;
4、从原图到该feature map感受野范围内的所有stride乘积为。
则:
原图候选框左上点的坐标与其在任意feature map上的坐标关系为:
原图候选框右下点的坐标与其在任意feature map上的坐标关系为:
通用的转换方法为:
其中:
是feature map上的特征点在感受野的中心位置坐标;
是当前特征点处于由CNN的第几层产生的feature map中;
第层的stride大小;
第层的filter大小;
第层的padding大小。
反过来可以知道原图任何一个候选框在任何一个feature map上的位置。
感受野大小的计算采用Top to Down的方式,从当前层往靠近输入层的方式逐层传递,具体方法为:
假设:待计算感受野的特征点所在feature map所处层为,为特征点在原图的感受野大小。
则:
以下面两幅图为例:
图一
无padding。

绿色点为第2层feature map上坐标为(1,1)的点,则它在原图的中心点为:
中心点坐标为图中红点:(2.5,2.5)
感受野大小为4:
图二
第一层有padding。

绿色点为第2层feature map上坐标为(1,1)的点,则它在原图的中心点为:
中心点坐标为图中红点:(1.5,1.5)
感受野大小为4:
8.4.5 代码实践
- receptivefield.py
# -*- coding: utf-8 -*-#一层表示为一个三元组: [filter size, stride, padding]import mathdef forword(conv, layerIn):n_in = layerInk = conv[0]s = conv[1]p = conv[2]return math.floor((n_in - k + 2*p)/s) + 1def alexnet():convnet = [[],[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0],[6,1,0], [1, 1, 0]]layer_names = [['input'],'conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5','fc6-conv', 'fc7-conv']return [convnet, layer_names]def testnet():convnet = [[],[2,1,0],[3,3,1]]layer_names = [['input'],'conv1','conv2']return [convnet, layer_names]# layerid >= 1def receptivefield(net, layerid):if layerid > len(net[0]):print '[error] receptivefield:no such layerid!'return 0rf = 1for i in reversed(range(layerid)):filtersize, stride, padding = net[0][i+1]rf = (rf - 1)*stride + filtersizeprint ' 感受野大小为:%d.' % (int(rf))return rfdef anylayerout(net, layerin, layerid):if layerid > len(net[0]):print '[error] anylayerout:no such layerid!'return 0for i in range(layerid):if i == 0:fout = forword(net[0][i+1], layerin)continuefout = forword(net[0][i+1], fout)print '当前层为:%s, 输出节点维度为:%d.' % (net[1][layerid], int(fout))#x,y>=1def receptivefieldcenter(net, layerid, x, y):if layerid > len(net[0]):print '[error] receptivefieldcenter:no such layerid!'return 0al = 1bl = 1for i in range(layerid):filtersize, stride, padding = net[0][i+1]al = al * stridess = 1for j in range(i):fsize, std, pad = net[0][j+1]ss = ss * stdbl = bl + ss * (float(filtersize-1)/2 - padding)xi0 = al * (x - 1) + float(bl)yi0 = al * (y - 1) + blprint ' 该层上的特征点(%d,%d)在原图的感受野中心坐标为:(%.1f,%.1f).' % (int(x), int(y), float(xi0), float(yi0))return (xi0, yi0)# net:为某个CNN网络# insize:为输入层大小# totallayers:为除了输入层外的所有层个数# x,y为某层特征点坐标def printlayer(net, insize, totallayers, x, y):for i in range(totallayers):# 计算每一层的输出大小anylayerout(net, insize, i+1)# 计算每层的感受野大小receptivefield(net, i+1)# 计算feature map上(x,y)点在原图感受野的中心位置坐标receptivefieldcenter(net, i+1, x, y)if __name__ == '__main__':#net = testnet()#printlayer(net, insize=6, totallayers=2, x=1, y=1)net = alexnet()printlayer(net, insize=227, totallayers=8, x=2, y=3)
- 输出

8.5 Fast R-CNN
《Fast R-CNN》的出现解决了R-CNN+SPP中的以下问题:
- 把分类和回归放在一个网络做共享特征,提取的特征向量不用落地
- 借鉴SPP,网络结构对输入图片大小自适应
- 抛弃SVM分类器,利用softmax直接融合在神经网络中
- 借鉴SPP,只做一次全图的特征提取,不用每个候选框都做
8.5.1 算法概述
算法基本步骤为:

- 候选框生成阶段
方法同R-CNN。 - 特征提取阶段
注意整个网络的输入为两部分:整个图和候选框信息。特征提取会对整张图进行,利用输入的候选框坐标及大小信息可以方便低成本的在任何一个feature map上找到任何一个原图点的特征映射点(方法回看SPP-net),大大提高了特征提取效率。 - RoI pooling阶段
借鉴SPP的思想,对每个候选框生成一个自适应候选框大小的固定长度的ROI(region of interest)特征向量,除此之外,大家还可以想想RoI Pooling的更深层次作用。 - 多任务学习阶段
把得到的RoI特征向量用全连接层做组合后分别送入两个分支:一个做分类,一个做Bounding Box回归,并为此设计一个多任务损失函数。
直观对比R-CNN与Fast R-CNN的forward pipeline:

8.5.2 训练阶段
RoI pooling层生成说明
RoI pooling是SPP的特殊形式(金字塔层数为1,pooling采用max pooling),具体原理类比SPP即可,feature map通过该层后会产生大小(例如7 × 7)的特征向量,例如:
某个RoI坐标表示为四元组,其中为RoI最左上角坐标,为其高与宽,则RoI pooling会划分个大小的小网格,之后对每个小网格做max pooling即可。RoI pooling层反向传播
RoI pooling的反向传播比较简单,输入feature map上的任意特征元素的梯度信息为:所有由它产生的roi pooling feature map的特征元素所带梯度信息的累加和。

假设:
1、是 RoI pooling层输入feature map的第个特征元素;
2、是第个RoI的roi pooling后得到feature map的第个特征元素;
3、是第个RoI通过roi pooling得到的feature map上的第个输出特征元素对应原feature map上的子图;
为在上述子图中做max pooling后得到的原feature map元素索引号。
则反向传播得到的原feature map元素的梯度为:
函数表示:如果为真则返回1,否则返回0。多任务损失函数
使用smooth L1函数并融合分类和bounding box回归损失,损失函数如下:
其中:
smooth L1函数对异常点不敏感(在|x|值较大时使用线性分段函数而不是二次函数),如图:

8.5.3 代码实践
fast r-cnn完整代码请参考rbgirshick/fast-rcnn。
- RoI Pooling层实现解析
// ------------------------------------------------------------------// Fast R-CNN// Copyright (c) 2015 Microsoft// Licensed under The MIT License [see fast-rcnn/LICENSE for details]// Written by Ross Girshick// ------------------------------------------------------------------#include <cfloat>#include "caffe/fast_rcnn_layers.hpp"using std::max;using std::min;namespace caffe {template <typename Dtype>// 以下参数解释以VGG16为例,即进入roi pooling前的网络结构采用经典VGG16.// 在Layer类中输入数据用bottom表示, 输出数据用top表示__global__ void ROIPoolForward(const int nthreads, // 任务数,对应通过roi pooling后的输出feature map的神经元节点总数,// 具体为:RoI的个数(m) × channel个数(VGG16的conv5_3的输出为512个) × roi pooling输出宽(配置为7) × roi pooling输出高(配置为7) = 25088×m个const Dtype* bottom_data, // 输入的feature map,原图经过各种卷积、pooling等前向传播后得到(VGG16的conv5_3卷积产生的feature map,大小为:512×14×14)const Dtype spatial_scale, // 由之前所有卷积层的strides相乘得到,在fast rcnn中为1/16,注:从原图往conv5_3的feature map上映射为缩小过程,所以乘以1/16,反之需要乘以16const int channels, // 输入层(VGG16为卷积层conv5_3)feature map的channel个数(512)const int height, // 输入层(VGG16为卷积层conv5_3)feature map的高(14)const int width, // 输入层(VGG16为卷积层conv5_3)feature map的宽(14)const int pooled_height, // roi pooling输出feature map的高,fast rcnn中配置为h=7const int pooled_width, // roi pooling输出feature map的宽,fast rcnn中配置为w=7const Dtype* bottom_rois, // 输入的roi信息,存储所有rois或一个batch的rois,数据结构为[batch_ind,x1,y1,x2,y2],包含roi的:索引、左上角坐标及右下角坐标Dtype* top_data, // 存储roi pooling后得到的feature mapint* argmax_data) { // 为每个roi pooling后的feature map元素存储max pooling后对应conv5_3 feature map元素的索引信息,长度等于nthreads// index为线程索引,个数为roi pooling后的feature map上所有值的个数,索引范围为:[0,nthreads-1]CUDA_KERNEL_LOOP(index, nthreads) {// 该线程对应的top blob(N,C,H,W)中的W,输出roi pooling后feature map的中的宽的坐标,即feature map的第i=[0,k-1]列int pw = index % pooled_width;// 该线程对应的top blob(N,C,H,W)中的H,输出roi pooling后feature map的中的高的坐标,即feature map的第j=[0,k-1]行int ph = (index / pooled_width) % pooled_height;// 该线程对应的top blob(N,C,H,W)中的C,即第c个channel,channel数最大值为输入feature map的channel数(VGG16中为512).int c = (index / pooled_width / pooled_height) % channels;// 该线程对应的是第几个RoI,一共m个.int n = index / pooled_width / pooled_height / channels;// [start, end),指定RoI信息的存储范围,指针每次移动5的倍数是因为包含信息的数据结构大小为5,包含信息为:[batch_ind,x1,y1,x2,y2],含义同上bottom_rois += n * 5;// 将每个原图的RoI区域映射到feature map(VGG16为conv5_3产生的feature mao)上的坐标,bottom_rois第0个位置存放的是roi索引.int roi_batch_ind = bottom_rois[0];// 原图到feature map的映射为乘以1/16,这里采用粗映射而不是上文讲的精确映射,原因你懂的.int roi_start_w = round(bottom_rois[1] * spatial_scale);int roi_start_h = round(bottom_rois[2] * spatial_scale);int roi_end_w = round(bottom_rois[3] * spatial_scale);int roi_end_h = round(bottom_rois[4] * spatial_scale);// 强制把RoI的宽和高限制在1x1,防止出现映射后的RoI大小为0的情况int roi_width = max(roi_end_w - roi_start_w + 1, 1);int roi_height = max(roi_end_h - roi_start_h + 1, 1);// 根据原图映射得到的roi的高和配置的roi pooling的高(这里大小配置为7)自适应计算bin桶的高度Dtype bin_size_h = static_cast<Dtype>(roi_height)/ static_cast<Dtype>(pooled_height);// 根据原图映射得到的roi的宽和配置的roi pooling的宽(这里大小配置为7)自适应计算bin桶的宽度Dtype bin_size_w = static_cast<Dtype>(roi_width)/ static_cast<Dtype>(pooled_width);// 计算第(i,j)个bin桶在feature map上的坐标范围,需要依据它们确定后续max pooling的范围int hstart = static_cast<int>(floor(static_cast<Dtype>(ph)* bin_size_h));int wstart = static_cast<int>(floor(static_cast<Dtype>(pw)* bin_size_w));int hend = static_cast<int>(ceil(static_cast<Dtype>(ph + 1)* bin_size_h));int wend = static_cast<int>(ceil(static_cast<Dtype>(pw + 1)* bin_size_w));// 确定max pooling具体范围,注意由于RoI取自原图,其左上角不是从(0,0)开始,// 所以需要加上 roi_start_h 或 roi_start_w作为偏移量,并且超出feature map尺寸范围的部分会被舍弃hstart = min(max(hstart + roi_start_h, 0), height);hend = min(max(hend + roi_start_h, 0), height);wstart = min(max(wstart + roi_start_w, 0), width);wend = min(max(wend + roi_start_w, 0), width);bool is_empty = (hend <= hstart) || (wend <= wstart);// 如果区域为0返回错误代码Dtype maxval = is_empty ? 0 : -FLT_MAX;// If nothing is pooled, argmax = -1 causes nothing to be backprop'dint maxidx = -1;bottom_data += (roi_batch_ind * channels + c) * height * width;// 在给定bin桶的区域中做max poolingfor (int h = hstart; h < hend; ++h) {for (int w = wstart; w < wend; ++w) {int bottom_index = h * width + w;if (bottom_data[bottom_index] > maxval) {maxval = bottom_data[bottom_index];maxidx = bottom_index;}}}// 为某个roi pooling的feature map元素记录其由对conv5_3(VGG16)的feature map做max pooling后产生元素的索引号及值top_data[index] = maxval;argmax_data[index] = maxidx;}}template <typename Dtype>void ROIPoolingLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom, // 以VGG16为例,bottom[0]为最后一个卷积层conv5_3产生的feature map,shape[1, 512, 14, 14],// bottom[1]为rois数据,shape[roi个数m, 5]const vector<Blob<Dtype>*>& top) { // top为输出层结构, top->count() = top.n(RoI的个数) × top.channel(channel数)// × top.w(输出feature map的宽) × top.h(输出feature map的高)const Dtype* bottom_data = bottom[0]->gpu_data();const Dtype* bottom_rois = bottom[1]->gpu_data();Dtype* top_data = top[0]->mutable_gpu_data();int* argmax_data = max_idx_.mutable_gpu_data();int count = top[0]->count();/*参照caffe-fast-rcnn/src/caffe/layers/roi_pooling_layer.cpp中的代码:template <typename Dtype>void ROIPoolingLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) {channels_ = bottom[0]->channels();height_ = bottom[0]->height();width_ = bottom[0]->width();top[0]->Reshape(bottom[1]->num(), channels_, pooled_height_, pooled_width_);max_idx_.Reshape(bottom[1]->num(), channels_, pooled_height_, pooled_width_);}*//*参照caffe-fast-rcnn/include/caffe/util/device_alternate.hpp中的代码:// CUDA_KERNEL_LOOP#define CUDA_KERNEL_LOOP(i, n) \for (int i = blockIdx.x * blockDim.x + threadIdx.x; \i < (n); \i += blockDim.x * gridDim.x)// CAFFE_GET_BLOCKS// CUDA: number of blocks for threads.inline int CAFFE_GET_BLOCKS(const int N) {return (N + CAFFE_CUDA_NUM_THREADS - 1) / CAFFE_CUDA_NUM_THREADS;}// CAFFE_CUDA_NUM_THREADS// CUDA: thread number configuration.// Use 1024 threads per block, which requires cuda sm_2x or above,// or fall back to attempt compatibility (best of luck to you).#if __CUDA_ARCH__ >= 200const int CAFFE_CUDA_NUM_THREADS = 1024;#elseconst int CAFFE_CUDA_NUM_THREADS = 512;#endif*/ROIPoolForward<Dtype><<<CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS>>>(count, bottom_data, spatial_scale_, channels_, height_, width_,pooled_height_, pooled_width_, bottom_rois, top_data, argmax_data);CUDA_POST_KERNEL_CHECK;}template <typename Dtype>// 反向传播的过程与论文中"Back-propagation through RoI pooling layers"这一小节的公式完全一致__global__ void ROIPoolBackward(const int nthreads, // 输入feature map的元素数(VGG16为:512×14×14)const Dtype* top_diff, // roi pooling输出feature map所带的梯度信息∂L/∂y(r,j)const int* argmax_data, // 同前向,不解释const int num_rois, // 同前向,不解释const Dtype spatial_scale, // 同前向,不解释const int channels, // 同前向,不解释const int height, // 同前向,不解释const int width, // 同前向,不解释const int pooled_height, // 同前向,不解释const int pooled_width, // 同前向,不解释Dtype* bottom_diff, // 保留输入feature map每个元素通过梯度反向传播得到的梯度信息const Dtype* bottom_rois) { // 同前向,不解释// 含义同前向,需要注意的是这里表示的是输入feature map的元素数(反向传播嘛)CUDA_KERNEL_LOOP(index, nthreads) {// 同前向,不解释int w = index % width;int h = (index / width) % height;int c = (index / width / height) % channels;int n = index / width / height / channels;Dtype gradient = 0;// 同论文中公式,任何一个输入feature map的元素的梯度信息为:// 所有max pooling时被该元素落入且该元素值被选中(最大值)的// roi pooling feature map元素的梯度信息累加和// 遍历所有RoI,以判断是否满足上述条件for (int roi_n = 0; roi_n < num_rois; ++roi_n) {const Dtype* offset_bottom_rois = bottom_rois + roi_n * 5;int roi_batch_ind = offset_bottom_rois[0];// 如果RoI的索引号不满足条件则跳过if (n != roi_batch_ind) {continue;}// 找原图RoI在feature map上的映射位置,解释同前向传播int roi_start_w = round(offset_bottom_rois[1] * spatial_scale);int roi_start_h = round(offset_bottom_rois[2] * spatial_scale);int roi_end_w = round(offset_bottom_rois[3] * spatial_scale);int roi_end_h = round(offset_bottom_rois[4] * spatial_scale);// (h,w)不在RoI范围则跳过const bool in_roi = (w >= roi_start_w && w <= roi_end_w &&h >= roi_start_h && h <= roi_end_h);if (!in_roi) {continue;}int offset = (roi_n * channels + c) * pooled_height * pooled_width;const Dtype* offset_top_diff = top_diff + offset;const int* offset_argmax_data = argmax_data + offset;// 同前向int roi_width = max(roi_end_w - roi_start_w + 1, 1);int roi_height = max(roi_end_h - roi_start_h + 1, 1);// 同前向Dtype bin_size_h = static_cast<Dtype>(roi_height)/ static_cast<Dtype>(pooled_height);Dtype bin_size_w = static_cast<Dtype>(roi_width)/ static_cast<Dtype>(pooled_width);// 类比前向,看做一个逆过程int phstart = floor(static_cast<Dtype>(h - roi_start_h) / bin_size_h);int phend = ceil(static_cast<Dtype>(h - roi_start_h + 1) / bin_size_h);int pwstart = floor(static_cast<Dtype>(w - roi_start_w) / bin_size_w);int pwend = ceil(static_cast<Dtype>(w - roi_start_w + 1) / bin_size_w);phstart = min(max(phstart, 0), pooled_height);phend = min(max(phend, 0), pooled_height);pwstart = min(max(pwstart, 0), pooled_width);pwend = min(max(pwend, 0), pooled_width);// 累积所有与当前输入feature map上的元素相关的roi pooling元素的梯度信息for (int ph = phstart; ph < phend; ++ph) {for (int pw = pwstart; pw < pwend; ++pw) {if (offset_argmax_data[ph * pooled_width + pw] == (h * width + w)) {gradient += offset_top_diff[ph * pooled_width + pw];}}}}// 存储当前输入feature map上元素的反向传播梯度信息bottom_diff[index] = gradient;}}template <typename Dtype>void ROIPoolingLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top, // roi pooling输出feature mapconst vector<bool>& propagate_down, // 是否做反向传播,回忆前向传播时的那个bool值const vector<Blob<Dtype>*>& bottom) { // roi pooling输入feature map(VGG16中的conv5_3产生的feature map)if (!propagate_down[0]) {return;}const Dtype* bottom_rois = bottom[1]->gpu_data(); // 原始RoI信息const Dtype* top_diff = top[0]->gpu_diff(); // roi pooling feature map梯度信息Dtype* bottom_diff = bottom[0]->mutable_gpu_diff(); // 待写入的输入feature map梯度信息const int count = bottom[0]->count(); // 输入feature map元素总数caffe_gpu_set(count, Dtype(0.), bottom_diff);const int* argmax_data = max_idx_.gpu_data();// NOLINT_NEXT_LINE(whitespace/operators)ROIPoolBackward<Dtype><<<CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS>>>(count, top_diff, argmax_data, top[0]->num(), spatial_scale_, channels_,height_, width_, pooled_height_, pooled_width_, bottom_diff, bottom_rois);CUDA_POST_KERNEL_CHECK;}INSTANTIATE_LAYER_GPU_FUNCS(ROIPoolingLayer);} // namespace caffe
实现代码参考,GPU版本:roi_pooling_layer.cu和CPU版本:roi_pooling_layer.cpp。
conv5_3及roi相关层配置:
layer {name: "conv5_3"type: "Convolution"bottom: "conv5_2"top: "conv5_3"param {lr_mult: 1}param {lr_mult: 2}convolution_param {num_output: 512pad: 1kernel_size: 3}}layer {name: "relu5_3"type: "ReLU"bottom: "conv5_3"top: "conv5_3"}layer {name: "roi_pool5"type: "ROIPooling"bottom: "conv5_3"bottom: "rois"top: "pool5"roi_pooling_param {pooled_w: 7pooled_h: 7spatial_scale: 0.0625 # 1/16}}
- 一些直观解释

8.6 Faster R-CNN
《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》提出了Region Proposal Network(RPN),解决了基于Region的检测算法需要事先通过Selective Search生成候选框的问题,让候选框生成、分类、bounding box回归公用同一套特征提取网络,从而使这类检测算法真正意义上实现End to End。
8.6.1 算法概述
如上所述,Faster R-CNN设计了RPN使得候选框生成可以共用特征提取网络,算法流程如下:

RPN负责生成Proposal候选框,其他过程类似Fast R-CNN,同样,生成候选框的扫描过程发生在最后一个卷积层产生的feature map上(而不是扫描原图),通过之前讲的坐标换算关系可以将feature map任意一点映射回原图。
8.6.2 RPN
RPN的结构如下:

1、RPN的输入是特征提取器最后一个卷积(pooling)产生的feature map,例如VGG16为conv5_3产生的512维(channel数)的feature map(图中例子是256维);
2、之后以m×m大小的滑动窗口扫描feature map,如果feature map大小为h×w,则扫描h×w次(即以每个像素点为中心做一次),文中m的取值为3,取值与具体网络结构有关,感受野的不同导致候选框的初始大小不同;
3、每做一次滑动窗口会生成k个初始候选框,初始候选框的大小与anchor(原理8.6.3解释)有关,中心点为滑动窗口中心点,即对一次滑动窗口行为,所有利用anchor生成的候选框都有相同的中心点(图中蓝点),一定注意:这里的anchor及利用它生成的候选框都是相对于原图的位置;
4、定义两个分支,第一个分支(左边)是一个二分类器,用来区分当前候选框是否为物体,如果有k个由anchor生成的候选框,则输出2*k个值(2维向量为:[是物体的概率,是背景的概率]);第二个分支(右边)为回归器,用来回归候选框的中心点坐标和宽与高(4维向量[x,y,w,h]),如果有k个由anchor生成的候选框,则输出4*k个值,显然这里候选框的生成要短、平、快,精调细选由后续网络来做。
8.6.3 Anchor
RPN里很重要的一个概念是anchor,可以把它理解为生成候选框的模板,在RPN里只生成一次,anchor是用原图为参照物,以(0,0,指定宽,指定高)四元组采用不同缩放比例和尺度后产生的候选框模板集合,而候选框由滑动窗口(中心点x,中心点y)利用anchor生成。也可以从逆SPP角度去理解,SPP可以把一个feature map通过多尺度变换为金字塔式的多个feature map,反过来任何一个feature map也可利用多尺度变成多个feature map,这么做的好处是压根儿不用在原图上做各种尺度缩放而只用在feature map上做就好,并且这种变换具有不变性(Translation-Invariant Anchor):候选框生成及其预测函数具有可复现性,例如通过k-means聚类得到800个anchor,如果重复做一次实验不一定还是原来那800个,这个性质可以降低模型大小以及过拟合的风险。
以16×16大小为,base anchor[0,0,15,15]为例:
1、只使用_ratio_enum生成候选框如下:

2、只使用_scale_enum生成候选框如下:

3、混合使用生成候选框如下:
这种模板生成只需要做一次,之后大家以此为基准做中心点漂移即可。(所有其他像素点横纵坐标总是大于0的)

代码可参考generate_anchors.py:
# --------------------------------------------------------# Faster R-CNN# Copyright (c) 2015 Microsoft# Licensed under The MIT License [see LICENSE for details]# Written by Ross Girshick and Sean Bell# --------------------------------------------------------import numpy as np# Verify that we compute the same anchors as Shaoqing's matlab implementation:## >> load output/rpn_cachedir/faster_rcnn_VOC2007_ZF_stage1_rpn/anchors.mat# >> anchors## anchors =## -83 -39 100 56# -175 -87 192 104# -359 -183 376 200# -55 -55 72 72# -119 -119 136 136# -247 -247 264 264# -35 -79 52 96# -79 -167 96 184# -167 -343 184 360#array([[ -83., -39., 100., 56.],# [-175., -87., 192., 104.],# [-359., -183., 376., 200.],# [ -55., -55., 72., 72.],# [-119., -119., 136., 136.],# [-247., -247., 264., 264.],# [ -35., -79., 52., 96.],# [ -79., -167., 96., 184.],# [-167., -343., 184., 360.]])# 生成多尺度anchors,默认实现是大小为16,起始anchor位置是(0, 0, 15, 15)[左下角和右上角坐标],宽高比例为1/2,1,2,尺度缩放倍数为8,16,32。def generate_anchors(base_size=16, ratios=[0.5, 1, 2],scales=2**np.arange(3, 6)):"""Generate anchor (reference) windows by enumerating aspect ratios Xscales wrt a reference (0, 0, 15, 15) window."""# 生成起始anchor位置是(0, 0, 15, 15)base_anchor = np.array([1, 1, base_size, base_size]) - 1# 枚举1/2,1,2三种宽高缩放比例ratio_anchors = _ratio_enum(base_anchor, ratios)# 在以上比例的基础上做8,16,32三类尺度缩放,最终生成9个anchor。anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)for i in xrange(ratio_anchors.shape[0])])return anchors# 对给定anchor返回宽、高和中心点坐标(anchor存储的是左下角和右上角)def _whctrs(anchor):"""Return width, height, x center, and y center for an anchor (window)."""w = anchor[2] - anchor[0] + 1h = anchor[3] - anchor[1] + 1x_ctr = anchor[0] + 0.5 * (w - 1)y_ctr = anchor[1] + 0.5 * (h - 1)return w, h, x_ctr, y_ctr# 给定宽、高和中心点,输出anchor的左下角和右上角坐标def _mkanchors(ws, hs, x_ctr, y_ctr):"""Given a vector of widths (ws) and heights (hs) around a center(x_ctr, y_ctr), output a set of anchors (windows)."""ws = ws[:, np.newaxis]hs = hs[:, np.newaxis]anchors = np.hstack((x_ctr - 0.5 * (ws - 1),y_ctr - 0.5 * (hs - 1),x_ctr + 0.5 * (ws - 1),y_ctr + 0.5 * (hs - 1)))return anchors# 枚举anchor的三种宽高比 1:2,1:1,2:1def _ratio_enum(anchor, ratios):"""Enumerate a set of anchors for each aspect ratio wrt an anchor."""w, h, x_ctr, y_ctr = _whctrs(anchor)size = w * hsize_ratios = size / ratiosws = np.round(np.sqrt(size_ratios))hs = np.round(ws * ratios)anchors = _mkanchors(ws, hs, x_ctr, y_ctr)return anchors# 枚举anchor的各种尺度,如:anchor为[0 0 15 15],尺度为[8 16 32]def _scale_enum(anchor, scales):"""Enumerate a set of anchors for each scale wrt an anchor."""w, h, x_ctr, y_ctr = _whctrs(anchor)ws = w * scaleshs = h * scalesanchors = _mkanchors(ws, hs, x_ctr, y_ctr)return anchorsif __name__ == '__main__':import timet = time.time()a = generate_anchors()print time.time() - tprint afrom IPython import embed; embed()
8.6.4 代码实践
集中介绍RPN中proposal层的实现,以特征提取网络采用VGG16在poscal_voc数据集上为例。
网络结构

RPN配置
layer {name: "rpn_conv/3x3"type: "Convolution"bottom: "conv5_3"top: "rpn/output"param { lr_mult: 1.0 }param { lr_mult: 2.0 }convolution_param {num_output: 512kernel_size: 3 pad: 1 stride: 1weight_filler { type: "gaussian" std: 0.01 }bias_filler { type: "constant" value: 0 }}}layer {name: "rpn_relu/3x3"type: "ReLU"bottom: "rpn/output"top: "rpn/output"}layer {name: "rpn_cls_score"type: "Convolution"bottom: "rpn/output"top: "rpn_cls_score"param { lr_mult: 1.0 }param { lr_mult: 2.0 }convolution_param {num_output: 18 # 2(bg/fg) * 9(anchors)kernel_size: 1 pad: 0 stride: 1weight_filler { type: "gaussian" std: 0.01 }bias_filler { type: "constant" value: 0 }}}layer {name: "rpn_bbox_pred"type: "Convolution"bottom: "rpn/output"top: "rpn_bbox_pred"param { lr_mult: 1.0 }param { lr_mult: 2.0 }convolution_param {num_output: 36 # 4 * 9(anchors)kernel_size: 1 pad: 0 stride: 1weight_filler { type: "gaussian" std: 0.01 }bias_filler { type: "constant" value: 0 }}}layer {bottom: "rpn_cls_score"top: "rpn_cls_score_reshape"name: "rpn_cls_score_reshape"type: "Reshape"reshape_param { shape { dim: 0 dim: 2 dim: -1 dim: 0 } }}layer {name: 'rpn-data'type: 'Python'bottom: 'rpn_cls_score'bottom: 'gt_boxes'bottom: 'im_info'bottom: 'data'top: 'rpn_labels'top: 'rpn_bbox_targets'top: 'rpn_bbox_inside_weights'top: 'rpn_bbox_outside_weights'python_param {module: 'rpn.anchor_target_layer'layer: 'AnchorTargetLayer'param_str: "'feat_stride': 16"}}layer {name: "rpn_loss_cls"type: "SoftmaxWithLoss"bottom: "rpn_cls_score_reshape"bottom: "rpn_labels"propagate_down: 1propagate_down: 0top: "rpn_cls_loss"loss_weight: 1loss_param {ignore_label: -1normalize: true}}layer {name: "rpn_loss_bbox"type: "SmoothL1Loss"bottom: "rpn_bbox_pred"bottom: "rpn_bbox_targets"bottom: 'rpn_bbox_inside_weights'bottom: 'rpn_bbox_outside_weights'top: "rpn_loss_bbox"loss_weight: 1smooth_l1_loss_param { sigma: 3.0 }}
- 准备阶段
配置参数和生成anchor模板:
def setup(self, bottom, top):# parse the layer parameter string, which must be valid YAMLlayer_params = yaml.load(self.param_str_)# 获取所有特征提取层stride的乘积。(例如VGG为16)self._feat_stride = layer_params['feat_stride']# 设置初始尺度变换比例为8、16、32。anchor_scales = layer_params.get('scales', (8, 16, 32))# 使用上面介绍的方法生成anchor模板。self._anchors = generate_anchors(scales=np.array(anchor_scales))# anchor数量。(例如:9)self._num_anchors = self._anchors.shape[0]if DEBUG:print 'feat_stride: {}'.format(self._feat_stride)print 'anchors:'print self._anchors# rois blob: holds R regions of interest, each is a 5-tuple# (n, x1, y1, x2, y2) specifying an image batch index n and a# rectangle (x1, y1, x2, y2)top[0].reshape(1, 5)# scores blob: holds scores for R regions of interestif len(top) > 1:top[1].reshape(1, 1, 1, 1)
- 前向传播

以i为中心利用anchor模板生成anchor过程如下(蓝色为模板,用红色为i中心点生成):

实现上就是中心点i的各个坐标直接加到anchor模板的各个坐标即可(anchor模板是以0为中心点的),代码类似:
A = self._num_anchorsK = shifts.shape[0]anchors = self._anchors.reshape((1, A, 4)) + \shifts.reshape((1, K, 4)).transpose((1, 0, 2))anchors = anchors.reshape((K * A, 4))
8.6.5 Faster R-CNN训练流程
采用四阶段交替方式训练(4-Step Alternating Training)
1、使用ImageNet预训练模型权重初始化并fine-tuned训练一个RPN;
2、使用ImageNet预训练模型权重初始化并将上一步产生的候选框(proposal)作为输入训练独立的Faster R-CNN检测模型(此时没有卷积网络共享);
3、生成新的RPN并使用上一步Fast-RCNN模型参数初始化,设置RPN、Fast-RCNN共享的那部分网络权重不做更新,只fine-tuned训练RPN独有的网络层,达到两者共享用于提取特征的卷积层的目的;
4、固定共享的那些卷积层权重,只训练Fast-RCNN独有的网络层。
Faster R-CNN是效果最好的目标检测与分类模型之一,但如果想用于实时监测和前置到客户端则需要做大量模型裁剪、压缩和优化工作,具体做法我以后介绍,目前我们做的比较初步,模型大小压缩到10m左右,准确率损失小于1.5%,线上inference响应时间在500k左右大小图片、k80单机单卡单次请求下为20ms左右(在高并发情况下会通过打batch的方式及其他方法提高并发量)。
未做优化的汽车检测demo:

8.6.6 Faster R-CNN with Caffe
源码地址:Faster R-CNN(rbgirshick版)。一定注意,caffe有个问题(我认为是架构上的设计缺陷,这个问题tensorflow就没有):由于要支持自定义的网络层之类的需求,每个人的caffe版本可能是不一样的,所以在编译时需要注意,比如这里的caffe必须使用0dcd397这个branch,否则编译不通过,因为这里有自定义的proposal层以及相关参数。
目录结构如下:

Centos 7上编译运行caffe及Faster R-CNN
编译准备
1、 为你的账号添加sudo权限gpasswd -a user_name wheel
2、安装编译器
sudo yum install gcc gcc-c++
3、安装 git
sudo yum install git
4、clone代码
5、安装依赖项
sudo yum install snappy-devel opencv-devel atlas-devel boost-devel protobuf-devel
6、安装cmake
sudo yum install cmake
7、安装automake
wget http://ftp.gnu.org/gnu/automake/automake-1.14.tar.gz
tar -xvf automake-1.14.tar.gz
cd automake-1.14
./configure
make -j
sudo make install
8、安装gflags
git clone https://github.com/gflags/gflags
cd gflags
mkdir build && cd build
export CXXFLAGS="-fPIC" && cmake ..
make VERBOSE=1 -j
sudo make install
9、安装glog
git clone https://github.com/google/glog
cd glog
./autogen.sh && ./configure && make && make install
10、安装 lmdb
git clone https://github.com/LMDB/lmdb
cd lmdb/libraries/liblmdb
make -j
sudo make install
11、安装 hdf5
wget https://support.hdfgroup.org/ftp/HDF5/current18/src/hdf5-1.8.19.tar.gz
tar -xvf hdf5-1.8.19.tar.gz
cd hdf5-1.8.19
./configure --prefix=/usr/local
make -j
sudo make install
12、安装 leveldb
git clone https://github.com/google/leveldb
cd leveldb
make -j
sudo cp out-shared/libleveldb.so* /usr/local/lib
sudo cp out-static/.a /usr/local/lib
sudo cp -r include/ /usr/local/include
- 编译caffe
1、下载源码
cd py-faster-rcnn
git clone https://github.com/rbgirshick/caffe-fast-rcnn.git
检查文件/src/caffe/proto/caffe.proto是否与下面文件一致:
2、修改配置
cd caffe-fast-rcnn
cp Makefile.config.example Makefile.config
vim Makefile.config
修改它的几个地方:
1)、指定CUDA_DIR,如:CUDA_DIR := /usr/local/cuda
2)、BLAS := open
3)、WITH_PYTHON_LAYER := 1
3、编译caffe-fast-rcnn
make clean
make all -j
make test -j
make runtest -j
make pycaffe -j
4、编译py-faster-rcnn的lib
cd py-faster-rcnn/lib/
make
5、配置环境变量
vim ~/.bashrc
export PYTHONPATH=/data/liyiran/py-R-FCN/tools/python:$PYTHONPATH
source ~/.bashrc
- 运行示例
1、下载pascal_voc数据集
cd py-faster-rcnn/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
mv VOCtrainval_06-Nov-2007 VOCdevkit2007
2、下载预训练模型
cd py-faster-rcnn/model
wget https://dl.dropboxusercontent.com/s/gstw7122padlf0l/imagenet_models.tgz?dl=0
3、使用VGG16,应用于pascal_voc 2007数据集
sh experiments/scripts/faster_rcnn_end2end.sh 1 VGG16 pascal_voc
8.7 R-FCN
回想之前所有基于Region的检测算法,有一个共同点是:整个网络被分成两部分:共享计算的、与Region无关的全卷积子网络和RoI Pooling之后不共享计算的、与Region相关的子网络(如RPN和BBox Regression网络)。再回想之前所有的分类网络,尤其到残差和GoogLeNet系列,都可以看做是全卷积网络,且在分类问题上的效果已经非常赞了,但当把这些网络直接用于检测问题时,效果往往特别差,甚至不如VGG-16,原因也是明确的:分类问题往往会忽略位置信息,只需要判断是否为某个物体,所以要求提取出来的特征具有平移不变性,不管图片特征放大、缩小还是位移都能很好的适应,而卷积操作、pooling操作都能较好的保持这个性质,并且网络越深模型越对位置不敏感;但在检测问题中,提取的特征还需要能敏锐的捕捉到位置信息,即具备平移变化性,这就尴尬了。为此,大家插入类似RoI Pooling这样的层结构,一方面是的任意大小图片都可以输入,更重要的是一定程度上弥补了位置信息的缺失,所以检测效果也就嗖嗖的上来了。但带来一个副作用是:RoI后每个Region都需要跑一遍后续子网络,计算不共享就导致训练和Inference的速度慢,为此代季峰、何凯明几位提出《R-FCN: Object Detection via Region-based Fully Convolutional Networks》检测框架,用Position-Sensitive RoI Pooling代替原来的RoI Pooling,共享了所有计算,很好的tradeoff了平移不变性和平移变化性,并且由于是全卷积,训练和Inference的速度更快。
以ResNet-101为例,图片来源:

8.7.1 算法概述
1、核心思想
如上所述,算法核心就是position-sentitive RoI pooling的加入,核心思想是这样的:

这里的feature map是过去RoI Pooling前的全卷积特征提取子网络,之后接着的(彩色立方体)是position-sensitive feature map,它其实是一个普通的卷积层,权重通过position-sensitive RoI Pooling层反向传播时修正。假设position-sensitive feature map(后面简写为ps feature map)的大小为k×k,检测分类数为C+1(1为背景类),则ps feature map的通道数为:k×k×(C+1),假如K=3,则每一类的 ps feature map会有k×k=9个,每个feature map含有一类位置特征(如:左上、左中、左右、......,下右,图中用不同颜色代表);接着,通过ps RoI Pooling后,每个RoI Region在C+1的每一类上都会得到一个k×k网格,对每个网格做分类判断,之后所有网格一起投票。最终得到C+1维向量,然后接个softmax做分类。
2、整体结构
考虑RPN子网络,整体结构是这样的:

对RPN来说也是类似,每个Bounding Box候选框的位置为一类(左上角坐标、长和宽),ps feature map的通道数为k×k×4。
3、position-sensitive feature map
以ResNet-101作为基础网络结构为例,做以下结构上的更改:
- 去掉GAP层和所有fc层
- 保留前100层,最后一个卷积层后接一个(1×1)×1024卷积层做降维
为了显示编码位置信息,假如ps feature map网格大小k×k,RoI大小为:,则每个bin大小约为:,对于第(i,j)个bin()做ps RoI Pooling为:
其中:
- 为第c类在第(i,j)个bin的pooling响应值;
- 为是k×k×(C+1)个feature map中的一个;
- 为RoI的左上角坐标;
- 是当前bin中的像素数;
- 是网络所有可学习参数;
- x、y的取值范围为:,;
- pooling采用average、max甚至其他自定义的操作。
损失函数的定义
4、损失函数定义
由分类部分和回归部分损失组成:
其中:
- 是每一类的label,代表背景类;
- ,是交叉熵损失函数;
- ,与Fast R-CNN的定义一致;
5、可视化效果
预测正例:

预测负例:

8.7.2 position-sentitive RoI pooling
- 原图及检测图

- 所有分类下的位置敏感特征图

8.7.3 模型训练
1、训练使用Online Hard Example Mining
OHEM是一种boosting策略,目的是使得训练更加高效,简单说,它不是使用简单的抽样策略,而是对容易判断的样本做抑制,对模型不容易判断的样本重复添加。
在检测中,正样本定义为:与ground-truth的,反之为负样本,应用过程为:
- 前向传播:所有候选框在Inference后做损失排序,选取B(一共N个)个损失最高的候选框,当然,由于临近位置的候选框的损失相近,所以还需要对其做NMS(如取IoU=0.7),然后再选出这B个样本;
- 反向传播:仅用这B个样本做反向传播更新权重。
2、训练参数
- 权重衰减系数:0.0005
- 动量项取值:0.9
- 图像被缩放为600像素
- 每个GPU使用一张图像,选择B=128个候选框做反向传播
- 利用VOC数据做fine-tune
- 采用 Faster R-CNN的四步交替法训练
8.7.4 代码实践
源码可在py-R-FCN下载,需要把下载R-FCN版本caffe,编译方式类似Faster RCNN,目录类似:

- PSROIPooling
// ------------------------------------------------------------------// R-FCN// Copyright (c) 2016 Microsoft// Licensed under The MIT License [see r-fcn/LICENSE for details]// Written by Yi Li// ------------------------------------------------------------------#include <cfloat>#include "caffe/rfcn_layers.hpp"#include "caffe/util/gpu_util.cuh"using std::max;using std::min;namespace caffe {template <typename Dtype>__global__ void PSROIPoolingForward(const int nthreads, // 任务数,对应通过roi pooling后的输出feature map的神经元节点总数,RoI的个数(m) × channel个数(21类) × psroi pooling输出宽(配置为7) × psroi pooling输出高(配置为7) = 1029×m个const Dtype* bottom_data, // 输入的feature map,原图经过各种卷积、pooling等前向传播后得到(ResNet50的rfcn_cls卷积产生的position sensitive feature map,大小为:1029×14×14)const Dtype spatial_scale, // 由之前所有卷积层的strides相乘得到,在rfcn中为1/16,注:从原图往rfcn_cls的feature map上映射为缩小过程,所以乘以1/16,反之需要乘以16const int channels, // 输入层(ResNet50为卷积层rfcn_cls)feature map的channel个数(k×k×(C+1)=7×7×21=1029)const int height, // feature map的宽度(14)const int width, // feature map的高度(14)const int pooled_height, // psroi pooling输出feature map的高,fast rcnn中配置为h=7const int pooled_width, // psroi pooling输出feature map的宽,fast rcnn中配置为w=7const Dtype* bottom_rois, // 输入的roi信息,存储所有rois或一个batch的rois,数据结构为[batch_ind,x1,y1,x2,y2],包含roi的:索引、左上角坐标及右下角坐标const int output_dim, // 输出feature map的维度,psroipooled_cls_rois为21(21个类别),psroipooled_loc_rois为8const int group_size, // k=7Dtype* top_data, // 存储psroi pooling后得到的feature mapint* mapping_channel) {// index为线程索引,个数为psroi pooling后的feature map上所有值的个数,索引范围为:[0,nthreads-1]CUDA_KERNEL_LOOP(index, nthreads) {// 该线程对应的top blob(N,C,H,W)中的W,输出roi pooling后feature map的中的宽的坐标,即feature map的第i=[0,k-1]列int pw = index % pooled_width;// 该线程对应的top blob(N,C,H,W)中的H,输出roi pooling后feature map的中的高的坐标,即feature map的第j=[0,k-1]行int ph = (index / pooled_width) % pooled_height;// 该线程对应的top blob(N,C,H,W)中的C,即第c个channel,channel数最大值为21(包含背景类的类别数)int ctop = (index / pooled_width / pooled_height) % output_dim;// 该线程对应的是第几个RoI,一共m个.int n = index / pooled_width / pooled_height / output_dim;// [start, end),指定RoI信息的存储范围,指针每次移动5的倍数是因为包含信息的数据结构大小为5,包含信息为:[batch_ind,x1,y1,x2,y2],含义同上bottom_rois += n * 5;// 将每个原图的RoI区域映射到feature map(VGG16为conv5_3产生的feature mao)上的坐标,bottom_rois第0个位置存放的是roi索引.int roi_batch_ind = bottom_rois[0];// 原图到feature map的映射为乘以1/16,这里采用粗映射而不是上文讲的精确映射,原因你懂的.Dtype roi_start_w = static_cast<Dtype>(round(bottom_rois[1])) * spatial_scale;Dtype roi_start_h = static_cast<Dtype>(round(bottom_rois[2])) * spatial_scale;Dtype roi_end_w = static_cast<Dtype>(round(bottom_rois[3]) + 1.) * spatial_scale;Dtype roi_end_h = static_cast<Dtype>(round(bottom_rois[4]) + 1.) * spatial_scale;// 强制把RoI的宽和高限制在1x1,防止出现映射后的RoI大小为0的情况Dtype roi_width = max(roi_end_w - roi_start_w, 0.1);Dtype roi_height = max(roi_end_h - roi_start_h, 0.1);// 根据原图映射得到的roi的高和配置的psroi pooling的高(这里大小配置为7)自适应计算bin桶的高度Dtype bin_size_h = roi_height / static_cast<Dtype>(pooled_height);// 根据原图映射得到的roi的宽和配置的psroi pooling的宽(这里大小配置为7)自适应计算bin桶的宽度Dtype bin_size_w = roi_width / static_cast<Dtype>(pooled_width);// 计算第(i,j)个bin桶在feature map上的坐标范围,需要依据它们确定后续pooling的范围int hstart = floor(static_cast<Dtype>(ph) * bin_size_h+ roi_start_h);int wstart = floor(static_cast<Dtype>(pw)* bin_size_w+ roi_start_w);int hend = ceil(static_cast<Dtype>(ph + 1) * bin_size_h+ roi_start_h);int wend = ceil(static_cast<Dtype>(pw + 1) * bin_size_w+ roi_start_w);// 确定max pooling具体范围,注意由于RoI取自原图,其左上角不是从(0,0)开始,// 所以需要加上 roi_start_h 或 roi_start_w作为偏移量,并且超出feature map尺寸范围的部分会被舍弃hstart = min(max(hstart, 0), height);hend = min(max(hend, 0), height);wstart = min(max(wstart, 0),width);wend = min(max(wend, 0), width);bool is_empty = (hend <= hstart) || (wend <= wstart);int gw = pw;int gh = ph;// 计算第C类的(ph,pw)位置索引 = ctop×group_size×group_size + gh×gh×group_size + gw// 例如: ps feature map上第C[=1]类的第(i,j)[=(1,1)]位置,c=1×7×7 + 1×1×7+1=57int c = (ctop*group_size + gh)*group_size + gw;// 逐层做average poolingbottom_data += (roi_batch_ind * channels + c) * height * width;Dtype out_sum = 0;for (int h = hstart; h < hend; ++h){for (int w = wstart; w < wend; ++w){int bottom_index = h*width + w;out_sum += bottom_data[bottom_index];}}// 计算第(i,j)bin桶在feature map上的面积Dtype bin_area = (hend - hstart)*(wend - wstart);// 若第(i,j)bin桶宽高非法则设置为0,否则为平均值top_data[index] = is_empty? 0. : out_sum/bin_area;// 记录此次迭代计算ps feature map上的索引位置mapping_channel[index] = c;}}template <typename Dtype>void PSROIPoolingLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom, // 以ResNet50为例,bottom[0]为最后一个卷积层rfcn_cls产生的feature map,shape[1, 1029, 14, 14],// bottom[1]为rois数据,shape[roi个数m, 5]const vector<Blob<Dtype>*>& top) { // top为输出层结构, top->count() = top.n(RoI的个数) × top.channel(channel数)// × top.w(输出feature map的宽) × top.h(输出feature map的高)const Dtype* bottom_data = bottom[0]->gpu_data();const Dtype* bottom_rois = bottom[1]->gpu_data();Dtype* top_data = top[0]->mutable_gpu_data();int* mapping_channel_ptr = mapping_channel_.mutable_gpu_data();int count = top[0]->count();caffe_gpu_set(count, Dtype(0), top_data);caffe_gpu_set(count, -1, mapping_channel_ptr);// NOLINT_NEXT_LINE(whitespace/operators)PSROIPoolingForward<Dtype> << <CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS >> >(count, bottom_data, spatial_scale_, channels_, height_, width_, pooled_height_,pooled_width_, bottom_rois, output_dim_, group_size_, top_data, mapping_channel_ptr);CUDA_POST_KERNEL_CHECK;}template <typename Dtype>__global__ void PSROIPoolingBackwardAtomic(const int nthreads, // 输入feature map的元素数const Dtype* top_diff, // psroi pooling输出feature map所带的梯度信息∂L/∂y(r,j)const int* mapping_channel, // 同前向,不解释const int num_rois, // 同前向,不解释const Dtype spatial_scale, // 同前向,不解释const int channels, // 同前向,不解释const int height, // 同前向,不解释const int width, // 同前向,不解释const int pooled_height, // 同前向,不解释const int pooled_width, // 同前向,不解释const int output_dim, // 同前向,不解释Dtype* bottom_diff, // 保留输入feature map每个元素通过梯度反向传播得到的梯度信息const Dtype* bottom_rois) { // 同前向,不解释// 含义同前向,需要注意的是这里表示的是输入feature map的元素数(反向传播嘛)CUDA_KERNEL_LOOP(index, nthreads) {// 同前向,不解释int pw = index % pooled_width;int ph = (index / pooled_width) % pooled_height;int n = index / pooled_width / pooled_height / output_dim;// 找原图RoI在feature map上的映射位置,解释同前向传播bottom_rois += n * 5;int roi_batch_ind = bottom_rois[0];Dtype roi_start_w = static_cast<Dtype>(round(bottom_rois[1])) * spatial_scale;Dtype roi_start_h = static_cast<Dtype>(round(bottom_rois[2])) * spatial_scale;Dtype roi_end_w = static_cast<Dtype>(round(bottom_rois[3]) + 1.) * spatial_scale;Dtype roi_end_h = static_cast<Dtype>(round(bottom_rois[4]) + 1.) * spatial_scale;// 同前向Dtype roi_width = max(roi_end_w - roi_start_w, 0.1); //avoid 0Dtype roi_height = max(roi_end_h - roi_start_h, 0.1);// 同前向Dtype bin_size_h = roi_height / static_cast<Dtype>(pooled_height);Dtype bin_size_w = roi_width / static_cast<Dtype>(pooled_width);int hstart = floor(static_cast<Dtype>(ph)* bin_size_h+ roi_start_h);int wstart = floor(static_cast<Dtype>(pw)* bin_size_w+ roi_start_w);int hend = ceil(static_cast<Dtype>(ph + 1) * bin_size_h+ roi_start_h);int wend = ceil(static_cast<Dtype>(pw + 1) * bin_size_w+ roi_start_w);// 同前向hstart = min(max(hstart, 0), height);hend = min(max(hend, 0), height);wstart = min(max(wstart, 0), width);wend = min(max(wend, 0), width);bool is_empty = (hend <= hstart) || (wend <= wstart);// 计算第C类ps feature map权重值,梯度信息会被平均分配int c = mapping_channel[index];Dtype* offset_bottom_diff = bottom_diff + (roi_batch_ind * channels + c) * height * width;Dtype bin_area = (hend - hstart)*(wend - wstart);Dtype diff_val = is_empty ? 0. : top_diff[index] / bin_area;for (int h = hstart; h < hend; ++h){for (int w = wstart; w < wend; ++w){int bottom_index = h*width + w;caffe_gpu_atomic_add(diff_val, offset_bottom_diff + bottom_index);}}}}template <typename Dtype>void PSROIPoolingLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top, // psroi pooling输出feature mapconst vector<bool>& propagate_down, // 是否做反向传播,回忆前向传播时的那个bool值const vector<Blob<Dtype>*>& bottom) { // psroi pooling输入feature map(ResNet中的rfcn_cls产生的feature map)if (!propagate_down[0]) {return;}const Dtype* bottom_rois = bottom[1]->gpu_data(); // 原始RoI信息const Dtype* top_diff = top[0]->gpu_diff(); // psroi pooling feature map梯度信息Dtype* bottom_diff = bottom[0]->mutable_gpu_diff(); // 待写入的输入feature map梯度信息const int bottom_count = bottom[0]->count(); // 输入feature map元素总数const int* mapping_channel_ptr = mapping_channel_.gpu_data();caffe_gpu_set(bottom[1]->count(), Dtype(0), bottom[1]->mutable_gpu_diff());caffe_gpu_set(bottom_count, Dtype(0), bottom_diff);const int count = top[0]->count();// NOLINT_NEXT_LINE(whitespace/operators)PSROIPoolingBackwardAtomic<Dtype> << <CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS >> >(count, top_diff, mapping_channel_ptr, top[0]->num(), spatial_scale_,channels_, height_, width_, pooled_height_, pooled_width_, output_dim_,bottom_diff, bottom_rois);CUDA_POST_KERNEL_CHECK;}INSTANTIATE_LAYER_GPU_FUNCS(PSROIPoolingLayer);} // namespace caffe
- PS feature map可视化
#!/usr/bin/env python# -*- coding: utf-8 -*- 2"""Demo script showing detections in sample images.See README.md for installation instructions before running."""import matplotlibmatplotlib.use('Agg')import matplotlib.pyplot as pltimport _init_pathsfrom fast_rcnn.config import cfgfrom fast_rcnn.test import im_detectfrom fast_rcnn.nms_wrapper import nmsfrom utils.timer import Timerimport numpy as npimport scipy.io as sioimport caffe, os, sys, cv2import argparseCLASSES = ('__background__','aeroplane', 'bicycle', 'bird', 'boat','bottle', 'bus', 'car', 'cat', 'chair','cow', 'diningtable', 'dog', 'horse','motorbike', 'person', 'pottedplant','sheep', 'sofa', 'train', 'tvmonitor')NETS = {'ResNet-101': ('ResNet-101','resnet101_rfcn_final.caffemodel'),'ResNet-50': ('ResNet-50','resnet50_rfcn_final.caffemodel')}def parse_args():"""Parse input arguments."""parser = argparse.ArgumentParser(description='Faster R-CNN demo')parser.add_argument('--gpu', dest='gpu_id', help='GPU device id to use [0]',default=0, type=int)parser.add_argument('--cpu', dest='cpu_mode',help='Use CPU mode (overrides --gpu)',action='store_true')parser.add_argument('--net', dest='demo_net', help='Network to use [ResNet-101]',choices=NETS.keys(), default='ResNet-101')args = parser.parse_args()return argsdef vis_square(data, i):"""Take an array of shape (n, height, width) or (n, height, width, 3)and visualize each (height, width) thing in a grid of size approx. sqrt(n) by sqrt(n)"""# normalize data for displaydata = (data - data.min()) / (data.max() - data.min())# force the number of filters to be squaren = int(np.ceil(np.sqrt(data.shape[0])))padding = (((0, n ** 2 - data.shape[0]),(0, 1), (0, 1)) # add some space between filters+ ((0, 0),) * (data.ndim - 3)) # don't pad the last dimension (if there is one)data = np.pad(data, padding, mode='constant', constant_values=1) # pad with ones (white)# tile the filters into an imagedata = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])plt.imshow(data); plt.axis('off')plt.savefig('feature-' + str(i) + '.jpg')def vis_demo(net, image_name):"""可视化位置敏感特征图."""# Load the demo imageim_file = os.path.join(cfg.DATA_DIR, 'demo', image_name)im = cv2.imread(im_file)# Detect all object classes and regress object boundstimer = Timer()timer.tic()scores, boxes = im_detect(net, im)timer.toc()print ('Detection took {:.3f}s for ''{:d} object proposals').format(timer.total_time, boxes.shape[0])conv = net.blobs['data'].data[0]ave = np.average(conv.transpose(1, 2, 0), axis=2)plt.imshow(ave); plt.axis('off')plt.savefig('featurex.jpg')# Visualize detections for each classCONF_THRESH = 0.8NMS_THRESH = 0.3for cls_ind, cls in enumerate(CLASSES[1:]):cls_ind += 1 # because we skipped backgroundcls_boxes = boxes[:, 4:8]cls_scores = scores[:, cls_ind]dets = np.hstack((cls_boxes,cls_scores[:, np.newaxis])).astype(np.float32)keep = nms(dets, NMS_THRESH)dets = dets[keep, :]print cls_ind, ' ', cls# rfcn_cls[0, 0:49] 是第0类的7×7map,rfcn_cls[0, 49:98] 是第1类的7×7map,以此类推。feat = net.blobs['rfcn_cls'].data[0, cls_ind*49:(cls_ind+1)*49]vis_square(feat, cls)if __name__ == '__main__':cfg.TEST.HAS_RPN = True # Use RPN for proposalsargs = parse_args()prototxt = os.path.join(cfg.MODELS_DIR, NETS[args.demo_net][0],'rfcn_end2end', 'test_agnostic.prototxt')caffemodel = os.path.join(cfg.DATA_DIR, 'rfcn_models',NETS[args.demo_net][132])if not os.path.isfile(caffemodel):raise IOError(('{:s} not found.\n').format(caffemodel))if args.cpu_mode:caffe.set_mode_cpu()else:caffe.set_mode_gpu()caffe.set_device(args.gpu_id)cfg.GPU_ID = args.gpu_idnet = caffe.Net(prototxt, caffemodel, caffe.TEST)for layer_name, blob in net.blobs.iteritems():print layer_name + '\t' + str(blob.data.shape)print '\n\nLoaded network {:s}'.format(caffemodel)# Warmup on a dummy imageim = 128 * np.ones((300, 500, 3), dtype=np.uint8)for i in xrange(2):_, _= im_detect(net, im)im_names = ['car.jpg']for im_name in im_names:print '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~'print 'Demo for data/demo/{}'.format(im_name)vis_demo(net, im_name)# obtain the output probabilitiesoutput_prob = net.blobs['cls_prob'].data[0]print 'probabilities:'print output_prob
8.8 DenseNet
8.9 Mask-R-CNN
8.10 YOLO
8.11 SSD
8.12 YOLO 9000
9. 语义分割
9.1 FCN
FCN在《Fully Convolutional Networks for Semantic Segmentation》中第一次被提出,个人认为是实现图像end to end语义分割的开山之作,第一次做到了低成本的像素级分类预测(end-to-end, pixels-to-pixels),另外这个方法用在目标检测、识别上效果好于传统新方法(如:Faster R-CNN)。
所谓语义分割简单说就是不但要知道你属于哪一类,还要知道你在哪儿:

9.1.1 算法概述
CNN网络无疑是特征提取的利器,尤其在图像领域,回顾我们的做法:CNN做特征提取+全连接层做特征组合+分类/回归,为了能提高模型预测能力,需要通过多个全连接层(做笛卡尔积)做特征组合,这里是参数数量最多的地方,成为模型训练,尤其是inference时的最大瓶颈(所以模型压缩和剪枝算法会把第一把刀放在全连接层),而由于全连接层的存在,导致整个网络的输入必须是固定大小的:由于卷积和采样操作更本不关心输入大小如何,试想如果输入大小不一,不同图片到了全连接层时其输入节点数是不一样的,而网络的定义必须事先定义好,所以没法儿玩儿了,于是有了前面的SPP及RoI pooling来解决这个问题,FCN则是解决这个问题的另一个思路。
总结该算法要解决的问题如下:
1、取消网络对输入数据大小必须固定的限制;
2、提高模型效果且加快其训练和inference速度。
相比于传统CNN,FCN把全连接层全部替换成卷积层,并在feature map(可以是其中任何一个)上做上采样,使其恢复到原始图片大小,这样不但保留了每个像素的空间信息,而且每个像素都会有一个分类预测。比如下图中pixelwise prediction那一层,小猫、小狗、电视、背景都会在像素级别做分类预测:

9.1.2 1×1卷积回顾
前面我们在介绍各种经典识别网络中介绍了1×1卷积核,回顾下它的作用,尤其对多通道而言:
1、每个1×1卷积核会有一个参数,利用它们可以做跨通道特征融合,即对多个通道的feature map做线性组合;
2、具有降维或升维作用,如:在GoogleNet中它可以跟在pooling层后面做降维,也可以直接通过减少通道数做降维,大大减少了参数量;
3、可以在不损失feature map信息的前提下利用后面的激活函数增加模型非线性表征能力,可以低成本的把网络变深。
9.1.3 全卷积网络
使用传统CNN做像素级分类的问题:
1、为了考虑上下文信息,需要一个滑动窗口,利用滑动窗口内的feature map对每个像素做分类,分类效果及存储空间随滑动窗口的大小上升;
2、为了考虑上下文信息,导致相邻两个窗口之间有大量的像素重复,意味着大量计算重复;
3、原图的空间信息没有被很好的利用;
4、原图需要固定大小,图像的resize(本质就是图像的下采样)导致信息损失。
FCN则很好的解决了上面几个问题。

上图是传统CNN工作流程,下图是FCN工作流程,它最终可以得到关于目标的热图,这种变换除了在语义分割、检测、识别上用到,也会在feature map可视化上用来帮助分析特征。
一张图说明:

理解FCN最关键的一步是理解上采样(upsampling)。
9.1.4 Nyquist–Shannon采样定理
关于采样,这个话题可大可小,从定义上说,采样是这么一个过程:在尽可能减少信息损失的情况下,将信号从一种采样率下的形态转换为另外一种,对于图片,这个过程叫做图像缩放。详细定义参见Resampling。
对计算机而言无法处理连续信号(读者想想为什么?),必须通过采样做信号离散化,那就必须回答一个问题:理想情况下,以什么样的频率采样能完美重构连续信号的信息。
Nyquist–Shannon采样定理回答了上面的问题:当对信号均匀间隔离散采样且信号的带宽小于采样率的一半时,原始连续信号可以被其得到的采样样本完全重构,不满足该条件则会出现混叠(Aliasing)现象。
理论上连续信号可以通过以下公式重构(信息重构器):

其中采样率为:1/T,s(n*T)是s(x)的采样样本,sinc(x)是采样核(resampling kernel)。
一般来说 信息重构器有以下性质:
1、确实是信号的样本;
2、;
3、resampling kernel:;
4、resampling kernel:是对称的,;
5、resampling kernel:是处处可微的。
当然还有其他形式的resampling kernel,比如bilinear resampling kernel,满足上述性质2、3、4:

这个函数在FCN里广泛用到。
我利用scikit-image library给个简单的bilinear resampling示例:
import skimage.transformfrom numpy import ogrid, repeat, newaxisfrom skimage import iodef upsample_with_skimage(img, factor):# order=1表示bilinear resampling,参见:http://scikit-image.org/docs/dev/api/skimage.transform.html。# order的含义:# 0: Nearest-neighbor# 1: Bi-linear (default)# 2: Bi-quadratic# 3: Bi-cubic# 4: Bi-quartic# 5: Bi-quinticreturn skimage.transform.rescale(img,factor,mode='constant',cval=0,order=1)if __name__ == '__main__':target = upsample_with_skimage(img=io.imread("feature_map.jpg"), factor=5)io.imsave("upsampling.png", target, interpolation='none')

9.1.5 转置卷积(Transposed Convolution)
很多人把这个过程叫做“反卷积(deconvolution)”,但我认为这么叫是错误的,它的过程并不是对卷积的逆运算,它除了用在FCN中还会用在卷积可视化、对抗神经网络中。
原理如下:

假设,输入为4×4、输出为2×2、卷积核为3×3,则把输出、输入和卷积核按照从左到右、从上到下展开为向量,前向传播的卷积过程相当于输入与以下稀疏矩阵的乘积:
前向传播过程就表述为:
误差反向传播(如果记不清了可以回看5.1节):
那么反过来,我们希望从4维向量映射回16维向量怎么做呢:把上面过程逆反一下(当然该做padding还得做):
前向传播:
反向传播:
整个过程平滑柔顺,多种情况下的详细解释可以看:《Convolution arithmetic tutorial》
keras下做转置卷积,输入feature map及最终效果与8.7.4。
# -*- coding: utf-8 -*-from __future__ import divisionimport numpy as npimport tensorflow as tffrom skimage import ioimport skimageimport ioimport osimport keras.backend as Kdef get_kernel_size(factor):"""给定上采样因子,返回核大小,上采样因子大小等于转置卷积步长。"""return 2 * factor - factor % 2def upsample_filt(size):"""返回上采样bilinear kernel矩阵。"""factor = (size + 1) // 2if size % 2 == 1:center = factor - 1else:center = factor - 0.5og = np.ogrid[:size, :size]return (1 - abs(og[0] - center) / factor) * \(1 - abs(og[1] - center) / factor)def bilinear_upsample_weights(factor, channel):"""使用bilinear filter初始化转置卷积权重矩阵。"""filter_size = get_kernel_size(factor)weights = np.zeros((filter_size,filter_size,channel,channel), dtype=np.float32)upsample_kernel = upsample_filt(filter_size)for i in xrange(channel):weights[:, :, i, i] = upsample_kernelreturn weightsdef upsample_keras(factor, input_img):SCALE = 256channel = input_img.shape[2]scale_height = input_img.shape[0] * factorscale_width = input_img.shape[1] * factorexpanded_img = np.expand_dims(input_img, axis=0)with tf.device("/gpu:1"):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)os.environ["CUDA_VISIBLE_DEVICES"] = "1"sess = tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))input_value = tf.placeholder(tf.float32)trans_filter = tf.placeholder(tf.float32)upsample_filter_np = bilinear_upsample_weights(factor, channel)res = K.conv2d_transpose(input_value, trans_filter,output_shape=[1, scale_height, scale_width, channel],padding='same',strides=(factor, factor))final_result = sess.run(res,feed_dict={trans_filter: upsample_filter_np,input_value: expanded_img})if channel != 1:return final_result.squeeze() / SCALEreturn final_result.squeeze()upsampled_img_keras = upsample_keras(factor=5, input_img=skimage.io.imread("feature_map.jpg"))skimage.io.imsave("bilinear_feature_map.jpg",upsampled_img_keras, interpolation='none')
9.1.6 代码实践
开源代码可参见:Keras-FCN,虽然缺点是训练有点慢,模型有点大,但对于理解如何实现很有帮助。
里面实现了五种模型,两种基于vgg-16,两种基于resnet-50,一种基于densenet。
上采样操作做为一个新的网络层意味着它需要能够前向传播、反向传播、更新权重,其实现在代码中为BilinearUpSampling.py。
inference.py的代码需要稍微变下:
import numpy as npimport matplotlib.pyplot as pltfrom pylab import *import osimport sysimport cv2from PIL import Imagefrom keras.preprocessing.image import *from keras.models import load_modelimport keras.backend as Kfrom keras.applications.imagenet_utils import preprocess_inputfrom models import *def inference(model_name, weight_file, image_size, image_list, data_dir, label_dir, return_results=True, save_dir=None,label_suffix='.png',data_suffix='.jpg'):current_dir = os.path.dirname(os.path.realpath(__file__))# mean_value = np.array([104.00699, 116.66877, 122.67892])batch_shape = (1, ) + image_size + (3, )save_path = os.path.join(current_dir, 'Models/'+model_name)model_path = os.path.join(save_path, "model.json")checkpoint_path = os.path.join(save_path, weight_file)# model_path = os.path.join(current_dir, 'model_weights/fcn_atrous/model_change.hdf5')# model = FCN_Resnet50_32s((480,480,3))#config = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True))#session = tf.Session(config=config)#K.set_session(session)model = globals()[model_name](batch_shape=batch_shape, input_shape=(512, 512, 3))model.load_weights(checkpoint_path, by_name=True)model.summary()results = []total = 0for img_num in image_list:img_num = img_num.strip('\n')total += 1print('#%d: %s' % (total,img_num))image = Image.open('%s/%s%s' % (data_dir, img_num, data_suffix))image = img_to_array(image) # , data_format='default')label = Image.open('%s/%s%s' % (label_dir, img_num, label_suffix))label_size = label.sizeimg_h, img_w = image.shape[0:2]# long_side = max(img_h, img_w, image_size[0], image_size[1])pad_w = max(image_size[1] - img_w, 0)pad_h = max(image_size[0] - img_h, 0)image = np.lib.pad(image, ((pad_h/2, pad_h - pad_h/2), (pad_w/2, pad_w - pad_w/2), (0, 0)), 'constant', constant_values=0.)# image -= mean_value'''img = array_to_img(image, 'channels_last', scale=False)img.show()exit()'''# image = cv2.resize(image, image_size)image = np.expand_dims(image, axis=0)image = preprocess_input(image)result = model.predict(image, batch_size=1)result = np.argmax(np.squeeze(result), axis=-1).astype(np.uint8)result_img = Image.fromarray(result, mode='P')result_img.palette = label.palette# result_img = result_img.resize(label_size, resample=Image.BILINEAR)result_img = result_img.crop((pad_w/2, pad_h/2, pad_w/2+img_w, pad_h/2+img_h))# result_img.show(title='result')if return_results:results.append(result_img)if save_dir:result_img.save(os.path.join(save_dir, img_num + '.png'))return resultsif __name__ == '__main__':with tf.device('/gpu:1'):gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1, allow_growth=True)os.environ["CUDA_VISIBLE_DEVICES"] = "1"tf.Session(config=K.tf.ConfigProto(allow_soft_placement=True,log_device_placement=True,gpu_options=gpu_options))model_name = 'AtrousFCN_Resnet50_16s'weight_file = 'checkpoint_weights.hdf5'image_size = (512, 512)data_dir = os.path.expanduser('~/.keras/datasets/VOC2012/VOCdevkit/VOC2012/JPEGImages')label_dir = os.path.expanduser('~/.keras/datasets/VOC2012/VOCdevkit/VOC2012/SegmentationClass')image_list = sys.argv[1:]#'2007_000491'results = inference(model_name, weight_file, image_size, image_list, data_dir, label_dir, save_dir="result")for result in results:result.show(title='result', command=None)
9.2 FCN-CRF
9.3 SegNet
9.4 UberNet
10. 物体跟踪
10.1 卡尔曼滤波器
10.2 CamShift
10.3 DLT
10.4 SO-DLT
10.5 FCNT
10.6 MDNet
10.7 RTT
10.8 DeepTracking
11. 强化学习
12. BOT
12.1 BOT架构
12.2 DSL
13. OCR
13.1 基于字符分割
13.2 基于行分割
13.3 CTC
14. 机器学习工具
14.1 机器学习架构设计
14.2 Keras
14.2.1 Keras设计思想
Keras是一个简化的、高抽象层的模型定义接口(比较完善的文档,英文:https://keras.io/;中文:https://keras-cn.readthedocs.io/en/latest/),作为优秀的前端封装,可以让开发人员方便、快速的上手神经网络相关模型构建,后端支持Theano与Tensorflow,鉴于我们主要使用Tensorflow,后面的介绍默认Keras的Backend为Tensorflow。指定Keras的层和模型与原生TensorFlow的tensor完全兼容,故它可以直接做TensorFlow模型定义,以及与其他TensoFlow库协同工作。
14.2.2 Keras处理大数据量
14.2.3 Keras单机多GPU
14.2.4 Keras多机多GPU
14.2.5 Keras与Tensorflow混合编程
14.3 Tensorflow
14.3.1 TF架构
14.3.2 TF in Docker
14.4 Kaldi
15. 自动驾驶
15.1 Openpilot
15.1.1 项目简介
Comma.ai是由天才黑客George Hotz(第一个破解iPhone、PS 3的人,相关介绍:https://www.bloomberg.com/features/2015-george-hotz-self-driving-car/)创立的专注自动驾驶的公司,目标是1000刀实现自动驾驶,但公司由于受到美国国家公路交通安全管理局的严格管制,于是“一怒之下”的把整个系统开源,取名openpilot,从功能上完全具备了目前特斯拉的autopilot具有的能力,主要表现在ACC和LKAS上。目前为止所有自动驾驶汽车都属于level 2,包括Waymo、Cruise、comma.ai、Ford、Tesla,特点是需要驾驶员坐在驾驶位且持续关注行车状态并随时接管汽车,实验室车辆在我看来也就Leve 2+,Level 3阶段,在特定路段驾驶员可以完全不用关注汽车行驶状态,目前没有厂商实现L3。openpilot目前主要能力是在6min内无需人的干预(但人需要盯着)控制本田和讴歌某几款车的加速、刹车、转向,从效果看,是我个人目前最看好的开源项目,且与我之前的构想一致:无需对汽车进行改造,无需昂贵的硬件设备,即插即用实现自动辅助驾驶。另外消费者不一定买同一品牌汽车,他们的数据也可以互相共享,从而降低自动驾驶造成的事故发生几率。
15.1.2 基本概念
1、CAN
CAN总线:(Controller Area Network, CAN)即控制器局域网络,是由以研发和生产汽车电子产品著称的德国BOSCH公司开发的,并最终成为国际标准(ISO 11898),是国际上应用最广泛的现场总线之一。不仅用于汽车,也广泛运用于工业,商业等领域。
在汽车领域,CAN是用于连接电子控制单元[ECU]的多主串行总线标准(通讯总线)。CAN网络需要两个或多个节点进行通信。节点的复杂性可以从简单的I / O设备到具有CAN接口和复杂软件的嵌入式计算机。节点还可以是允许标准计算机通过USB或以太网端口与CAN网络上的设备进行通信的网关。所有节点通过两线总线相互连接。电线为120Ω额定双绞线。

2、LIN
LIN总线:(Local Interconnect Network)本地互联网,是一种低成本的串行通讯网络,用于实现汽车中的分布式电子系统控制。LIN 的目标是为现有汽车网络(例如CAN 总线)提供辅助功能,因此LIN总线是一种辅助的总线网络。在不需要CAN 总线的带宽和多功能的场合,比如智能传感器和制动装置之间的通讯使用LIN 总线可大大节省成本。
在汽车电控系统中,数据交换主要经由CAN总线完成,LIN总线是其补充与完善,不仅仅是出于成本的考量,更是(当今通讯技术发展条件下)充分保证高速数据交互效率的完美结合。
3、NEO
一个开源机器人软件开发平台,目前和 Neo 适配的智能手机只有中国厂商一加生产的一加 3 手机,只有这部手机权限足够开放,而且相机和芯片 (高通骁龙820)都符合要求,且会利用该手机的GPS。硬件成本700刀。
4、panda
通用汽车接口软件,用来控制与CAN和LIN的通信。
15.1.3 系统架构

- 汽车平台
目前只支持本田旗下几款车(且它们并没有公司间合作):
Acura ILX 2016 with AcuraWatch Plus、Honda Civic 2016 with Honda Sensing、Honda CR-V Touring 2015-2016这几款车型。通过几个接口可以扩展到其他车型,https://comma.ai/bounties.html为鼓励计划,目前看汽车本身无需安装其他硬件设备。 - 硬件平台
1、NEO/Panda用于支持CAN/LIN通信,前者是一个机器人软件开发平台,后者是与汽车通信接口软硬件,平台开源可以方便支持OpenXC 、 Kvaser、 CANBus Triple。目前在本田上的所有通信实现只依赖2个CAN总线,1个车辆CAN、1个雷达CAN。

2、雷达
使用车载雷达即可,无需安装其他雷达
3、摄像头、GPS、智能手机
没有使用独立的摄像头和GPS模块,而是通过一部智能手机支持,目前全球能够支持的只有一加3手机,因为其权限足够开放,配备骁龙820、6GB RAM、以及光学+电子防抖,但目前看能够承担的运算不能太复杂,例如:车道检测和车辆识别的inference部分,车道线合并等。
相关视频:
https://www.youtube.com/watch?v=3lIc3WnAxw8
https://www.youtube.com/watch?v=64Wvt5pYQmE&feature=youtu.be
https://www.youtube.com/watch?v=EQJZvVeihZk - 软件平台
1、openpilot
框架比较清晰的软件架构,后面介绍
2、opendbc
依据车型订制的CAN通信消息封装接口
3、panda
与panda硬件配合的用于和汽车CAN/LIN通信的接口,关于它的详细说明:https://medium.com/@comma_ai/a-panda-and-a-cabana-how-to-get-started-car-hacking-with-comma-ai-b5e46fae8646 - 服务平台
1、仿真平台
仿真对于自动驾驶来说至关重要,openpilot目前无UI界面,通过后端跑仿真测试样例,并将结果绘图方式展示:

加速仿真:

距离仿真:

踏板仿真:

加速度仿真:

2、chffr
众包的数据收集app应用,目前有 1,000,000 miles的用户上传数据,通过积分、现金鼓励的方式运营,性价比比较高,另外还有一个比较牛的东西是automatic ground truthing engine(未开源),可以自动把chffr上的数据或任意视频数据做自动gt标注。

不过大体做法也许可以参考下面论文,基本思路还是利用语义分割做:
http://www.es.ele.tue.nl/~sander/publications/icip14.pdf
http://vladlen.info/papers/playing-for-data.pdf
ps:常规的思路是例如https://commacoloring.herokuapp.com/ 这样的人工标注平台,不过光它产生的这些数据就值不少钱。
15.1.4 软件架构

代码层面,由c/c++和python完成。
15.1.5 汽车基础组建
1、Panda
一个独立的开源项目,与panda硬件配合,是汽车通信的硬件接口,支持手机/pc与汽车的CAN/LIN通信,整个硬件仅需要88刀。
2、Opendbc
封装标准的CAN通信消息,依据车型订制,消息结构为:
identifier +11-bit标准段+29-bit扩展段,整个消息长度可扩展到8 bytes。

BO_ 228 STEERING_CONTROL: 5 ADASSG_ STEER_TORQUE : 7|16@0- (1,0) [-3840|3840] "" EPSSG_ STEER_TORQUE_REQUEST : 23|1@0+ (1,0) [0|1] "" EPSSG_ CHECKSUM : 39|4@0+ (1,0) [0|15] "" EPSSG_ COUNTER : 33|2@0+ (1,0) [0|3] "" EPS
第一行表示该消息是转向控制,标识符为228.后面四行为与转向相关消息。每个车型的消息结构可能都不一样,所以需要各自封装:

Dbc文件抽象及其格式解析的通用代码分别在:
https://github.com/commaai/openpilot/blob/v0.3.2/common/dbc.py
https://github.com/commaai/openpilot/blob/v0.3.2/selfdrive/car/honda/can_parser.py
15.1.6 公共组件
这里封装公用库函数,例如:卡尔曼滤波器、dbc文件管理、异常管理、车系管理、计算加速、参数封装、实时时间读写封装等,全为python代码。
15.1.7 手机组件
智能手机是openpilot的最大硬件,所有通信、数据收集、计算、展现都是通过手机作为载体。整个openpilot采用cap’n proto做消息序列化封装,使用ZMQ做消息通信,很高效,整体架构提前做了ROS 2.0想做的事。
can’n proto(https://capnproto.org/)的效率更加适用于这种嵌入式场景:

ZMQ(ZeroMQ,http://zeromq.org/)是跨平台、高效的分布式消息队列,同样很适用于嵌入式场景。
- cereal
封装所有用于手机端日志记录的消息接口,由两部分组成:
log.capnp,封装了手机日志记录相关接口;
car.capnp,车相关抽象层,核心是CarStateCarControl接口,如果想新加一种车,需要实现这个。 - phonelibs
封装手机相关库,纯基于c的,有些库只有so。
15.1.8 自动驾驶组件
自适应巡航使用传统方法,这里不讲,主要讲车道辅助驾驶部分,整体结构如下:

- 感知
在openpilot中感知主要是车道检测和传感器数据处理,前者使用的是一个深度神经网路,但网络结构没有开源,API开源,所以允许你定义模型:
struct ModelData {frameId @0 :UInt32;path @1 :路径数据;leftLane @2 :左行车道;rightLane @3 :右行车道;lead @4 :前方引领车辆;...
- 定位
未看到实现 - 预测
在openpilot中预测主要是路径预测,先预测前方某个长度路径是直的还是弯的,然后将这些局部路径合成一个长路径。 - 决策
依据当前车道信息、前车距离信息、自动驾驶时长信息做控制命令生成。 - 路径规划
一个独立进程,并没有做什么规划动作,主要是根据预测阶段产生的路径及决策信息决定后续路径。 - 控制
依据前面的信息产生后续动作并通过CAN/LIN接口执行消息发送以控制汽车姿态。
代码中:
○ 底层支持层
Assets用于UI字体支持;
Common为封装的公共组件函数;
Logcatd为独立进程,做Android日志管理,基于zmq和cap’nproto做消息通信;
Proclogd为独立进程,做进程日志管理,基于zmq和cap’nproto做消息通信.
○ 对外交互层
Boardd为独立进程,用于车、机USB消息交换;
Sensord为GPS/IMU接口代码,但未开源;
Visiond为车道检测算法,前面有讲;
○ 行为执行层
Loggerd用于记录车辆行驶过程中的数据,用于后续模型训练;
Car为封装的汽车抽象层前面有介绍;
Controls为控制单元,是这一层的核心,包括了自适应巡航、距离控制、路径规划等;
Radar为交互接口。
○ 前端表现层
UI用于绘制前端显示的行车线、车辆检测框、校准线等;
Debug用于调试;
Test/plant为相对简单的仿真后台。
15.1.9 总结
总的来说,自动驾驶最终解决方案一定不是不计成本的硬件投入,而是基于普通摄像头和车载雷达的低成本高性能解决方案。
所以我认为自动驾驶的技术核心是:
1、工程架构能力:如何满足可扩展性、高性能等要求;
2、核心模块的算法能力:主要是基于深度学习,需要tradeoff性能与效果,在嵌入式环境哪怕1ms都需要争取;
3、数据能力:两方面,收集数据的能力和数据标注的能力;
4、仿真能力:决定模型效果迭代能走多快。
目前开源软件能让我们达到Level 2,但要实现更高级别必须解决上面4个问题。
百度的apollo工程架构上设计比较合理,各子系统松耦合,但是目前整个项目是个空壳子,没有相关算法支撑,仿真系统也很粗糙,另外需要车载电脑等硬件支持,在通信性能方面我也有疑虑。
Openpilot在工程架构上比较合理,在资源消耗上比较小,硬件需求不强,我认为思路是未来的发展方向之一,缺点是没有大公司支持,属于个人英雄主义,且很多东西未开源。
整体来说开源自动驾驶技术方面大家都不完善,而自动驾驶的场景很重要,只研究技术是不够的,在我看来未来围绕着它有三大角色:
1、平台
2、主机厂
3、运营商
虽然趋势是合作共赢,但未来大家在这方面人才上的竞争会愈发激烈。
16. CUDA编程与高性能计算
17. References
如有遗漏请提醒我补充:
1、《Understanding the Bias-Variance Tradeoff》
http://scott.fortmann-roe.com/docs/BiasVariance.html
2、《Boosting Algorithms as Gradient Descent in Function Space》
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.51.6893&rep=rep1&type=pdf
3、《Optimal Action Extraction for Random Forests and
Boosted Trees》
http://www.cse.wustl.edu/~ychen/public/OAE.pdf
4、《Applying Neural Network Ensemble Concepts for Modelling Project Success》
http://www.iaarc.org/publications/fulltext/Applying_Neural_Network_Ensemble_Concepts_for_Modelling_Project_Success.pdf
5、《Introduction to Boosted Trees》
https://homes.cs.washington.edu/~tqchen/data/pdf/BoostedTree.pdf
6、《Machine Learning:Perceptrons》
http://ml.informatik.uni-freiburg.de/_media/documents/teaching/ss09/ml/perceptrons.pdf
7、《An overview of gradient descent optimization algorithms》
http://sebastianruder.com/optimizing-gradient-descent/
8、《Ad Click Prediction: a View from the Trenches》
https://www.eecs.tufts.edu/~dsculley/papers/ad-click-prediction.pdf
9、《ADADELTA: AN ADAPTIVE LEARNING RATE METHOD》
http://www.matthewzeiler.com/pubs/googleTR2012/googleTR2012.pdf
9、《Improving the Convergence of Back-Propagation Learning with Second Order Methods》
http://yann.lecun.com/exdb/publis/pdf/becker-lecun-89.pdf
10、《ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION》
https://arxiv.org/pdf/1412.6980v8.pdf
11、《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》
http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf
11、《Sparse Allreduce: Efficient Scalable Communication for Power-Law Data》
https://arxiv.org/pdf/1312.3020.pdf
12、《Asynchronous Parallel Stochastic Gradient Descent》
https://arxiv.org/pdf/1505.04956v5.pdf
13、《Large Scale Distributed Deep Networks》
https://papers.nips.cc/paper/4687-large-scale-distributed-deep-networks.pdf
14、《Introduction to Optimization —— Second Order Optimization Methods》
https://ipvs.informatik.uni-stuttgart.de/mlr/marc/teaching/13-Optimization/04-secondOrderOpt.pdf
15、《On the complexity of steepest descent, Newton’s and regularized Newton’s methods for nonconvex unconstrained optimization》
http://www.maths.ed.ac.uk/ERGO/pubs/ERGO-09-013.pdf
16、《On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes 》
http://papers.nips.cc/paper/2020-on-discriminative-vs-generative-classifiers-a-comparison-of-logistic-regression-and-naive-bayes.pdf
17、《Parametric vs Nonparametric Models》
http://mlss.tuebingen.mpg.de/2015/slides/ghahramani/gp-neural-nets15.pdf
18、《XGBoost: A Scalable Tree Boosting System》
https://arxiv.org/abs/1603.02754
19、一个可视化CNN的网站
http://shixialiu.com/publications/cnnvis/demo/
20、《Computer vision: LeNet-5, AlexNet, VGG-19, GoogLeNet》
http://euler.stat.yale.edu/~tba3/stat665/lectures/lec18/notebook18.html
21、François Chollet在Quora上的专题问答:
https://www.quora.com/session/Fran%C3%A7ois-Chollet/1
22、《将Keras作为tensorflow的精简接口》
https://keras-cn.readthedocs.io/en/latest/blog/keras_and_tensorflow/
23、《Upsampling and Image Segmentation with Tensorflow and TF-Slim》
https://warmspringwinds.github.io/tensorflow/tf-slim/2016/11/22/upsampling-and-image-segmentation-with-tensorflow-and-tf-slim/
