@vivounicorn
2020-11-06T10:08:41.000000Z
字数 42247
阅读 2260
机器学习与人工智能技术分享-第六章 循环神经网络
机器学习 RNN LSTM 第六章
回到目录


6. 循环神经网络
6.1 RNN
6.1.1 基本原理
序列类问题是我们日常生活中常见的一类问题:我们读的文章,我们说话的语音等等,要么是在空间上的序列,要么是在时间的序列,序列的每个单元之间有前驱后继的语义或序列相关性,比如:当我们说,“这是我们伟大的××”,这里××是“祖国”的概率远远大于“板凳”,所以在NLP领域,应用大概可以分为几种:
1、根据当前上下文语义预测接下来出现某个文本的概率;
2、通过语言模型生成新的文本;
3、文本的通用NLP任务,例如词性标注、文本分类等;
4、机器翻译;
5、文本表示及编码解码。
传统的神经网络并没有很好的解决这种序列问题,于是Recurrent Neural Networks这种网络被提了出来:

乍一看就是节点自带环路的网络,广义来看,可以在这个节点上展开,只是这种展开和输入的字数有关,比如输入为10个字,则展开10层。
从一个角度看,不同于传统神经网络会假设所有输入及输出是相互独立的,RNN正相反,认为节点间天然有相关性;另一个角度是,认为RNN具有“记忆”能力,它能把历史上相关节点状态“全部”记住,但实际情况是,我们当前说的一句话和较久前说的话未必有很强的关系,如果“全部”记住,一没必要、二计算量巨大。
6.1.2 BPTT 原理
以最简单的RNN为例,说明背后算法原理:

定义以下符号:
:输入层第个节点;
:前一个状态的隐藏层第个节点;
:当前状态的隐藏层第个节点;
:输出层第个节点;
:输入层到隐藏层权重矩阵;
:前一状态隐藏层到后一状态隐藏层权重矩阵;
:隐藏层到输出层权重矩阵;
:隐藏层激活函数;
:输出层激活函数。
网络的前向传播关系为:
输入层到隐藏层
常用的函数为Sigmoid类函数,如:隐藏层到输出层
常用的函数为指数族函数,如:
这里需要注意的一个关键点是:、、权重矩阵在不同时刻是共享的。
网络的反向传播关系:
只要网络的损失函数可微,那么任意一个前馈神经网络都可以通过误差反向传播(BP)做参数学习,BP本质是利用链式求导,使用梯度下降(GD)算法的最优化求解过程,而翻看前面第四章最优化原理,其求解就是给定目标函数,确定搜索步长和搜索方向的故事,GD的权重更新公式为(其中O为目标函数):
同样回看第四章,目标函数多种多样,比如常见的有:
SSE:
cross entropy:
但不管哪种目标函数,一般总可以分为线性部分(变量的线性组合)和非线性部分(激活函数),显然求导过程中线性部分最简单,非线性部分最复杂,所以上述权重更新公式可以拆解为:
显然:很容易计算,而比较难计算,定义:
为每个节点的误差向量,那么整个权重的更新核心考量就是怎么计算和传播。
- 输出层任意一个节点
- 隐藏层任意一个节点
基于以上推导得到:
- 当前状态隐藏层到输出层权重更新公式
- 输入层到当前状态隐藏层权重更新公式
- 上一状态隐藏层到当前状态隐藏层权重更新公式
- 任一隐层在某个时间状态下的误差
注意,有意思的来了:
对RNN做展开后如图:

其中状态前后依赖,所以类似的逻辑,误差会按照时间向后传播,如图:

于是误差反向传播公式变为:
其中:是在时刻的任何一个隐层节点,是在时刻的任何一个隐层节点,高层的可以通过循环递归的计算出来,所有计算完毕后累加求和并应用在、的权重更新中。
6.1.3 代码实践
问题描述:给定一个字符,生成(预测)之后的n个字符,并使得整个句子看上去有语义含义。
1、训练数据生成如下图:

2、过程说明如下图:

# -*- coding:utf-8 -*-import numpy as npimport osimport pickleclass RnnModeling:bert_len = 768 # length of bert nector.txt_data_size = 0 # text data size of char level.iteration = 1000 # iteration of training.sequence_length = 5 # window of text context.batch_size = 0 # training batch.input_size = 0 # size of input layer.hidden_size = 100 # size of hidden layer.output_size = 0 # size of output layer.learning_rate = 0.001 # learning rate of optimization algorithm.bert_path = "" # the path of bert model,you can download it through https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip.word2vec_path = "" # the path of word2vec model,you can download the pre-train model from internet.chars_set = [] # all chars in text data.check_point_dir = "" # path of check point.char_to_int = {} # char level encoding, char->intint_to_char = {} # char level decoding, int->charchar_encoded = {} # one hot encodingV = [] # weight matrix: from input to hidden.U = [] # weight matrix: from hidden to hidden.W = [] # weight matrix: from hidden to output.b_h = [] # bias vector of hidden layer.b_y = [] # bias vector of output layer.h_prev = [] # previous hidden state.def __init__(self):passdef set_fine_tuning_path(self, bert_path="", word2vec_path="", check_point_dir=""):self.bert_path = bert_pathself.word2vec_path = word2vec_pathself.check_point_dir = check_point_dirif word2vec_path != "" and not os.path.exists(word2vec_path):print("[Error] the path of word2vec is not exists.")exit(0)if bert_path != "" and not os.path.exists(bert_path):print("[Error] the path of bert is not exists.")exit(0)if check_point_dir != "" and not os.path.exists(check_point_dir):print("[Info] the path of check point is not exists, we'll create make it.")os.makedirs(check_point_dir)def copy_model(self, rnn):self.bert_len = rnn.bert_lenself.txt_data_size = rnn.bert_lenself.iteration = rnn.iterationself.sequence_length = rnn.sequence_lengthself.batch_size = rnn.batch_sizeself.input_size = rnn.input_sizeself.hidden_size = rnn.hidden_sizeself.output_size = rnn.output_sizeself.learning_rate = rnn.learning_rateself.chars_set = rnn.chars_setself.char_to_int = rnn.char_to_intself.int_to_char = rnn.int_to_charself.char_encoded = rnn.char_encodedself.V = rnn.Vself.U = rnn.Uself.W = rnn.Wself.b_h = rnn.b_hself.b_y = rnn.b_yself.h_prev = rnn.h_prevdef training_data_analysis(self, txt_data, mode):self.txt_data_size = len(txt_data)chars = list(set(txt_data))self.output_size = len(chars)self.char_to_int = dict((c, i) for i, c in enumerate(chars))self.int_to_char = dict((i, c) for i, c in enumerate(chars))if mode == "one-hot":self.input_size = len(chars)for i, c in enumerate(chars):letter = [0 for _ in range(len(chars))]letter[self.char_to_int[c]] = 1self.char_encoded[c] = np.array(letter)elif mode == "bert":self.input_size = self.bert_lenfrom bert_serving.client import BertClientbc = BertClient(timeout=1000)# start server: bert-serving-start -model_dir=D:\Github\bert\chinese_L-12_H-768_A-12 -num_worker=1for i, c in enumerate(chars):if not c.strip():self.char_encoded[c] = np.array(bc.encode(['<S>']))else:self.char_encoded[c] = np.array(bc.encode([c]))if i % 100 == 0:print('[Debug] bert vector length: %d' % (len(self.char_encoded)))elif mode == "w2v":import gensimmodel = gensim.models.KeyedVectors.load_word2vec_format(self.word2vec_path, binary=False)self.input_size = model.vector_sizefor i, c in enumerate(chars):if model.__contains__(c):self.char_encoded[c] = np.array(model[c])else:self.char_encoded[c] = np.zeros((self.input_size, 1))else:print("[Error] mode type error. it should be one-hot or bert or w2v.")exit(0)def model_building(self, itr, seq_len, lr, h_size):self.iteration = itrself.sequence_length = seq_lenself.learning_rate = lrself.batch_size = round((self.txt_data_size / self.sequence_length) + 0.5)self.hidden_size = h_sizeself.V = np.random.randn(self.hidden_size, self.input_size) * 0.01 # weight input -> hidden.self.U = np.random.randn(self.hidden_size, self.hidden_size) * 0.01 # weight hidden -> hiddenself.W = np.random.randn(self.output_size, self.hidden_size) * 0.01 # weight hidden -> outputself.b_h = np.zeros((self.hidden_size, 1))self.b_y = np.zeros((self.output_size, 1))self.h_prev = np.zeros((self.hidden_size, 1))def forwardprop(self, labeling, inputs, h_prev):x, s, y, p = {}, {}, {}, {}s[-1] = np.copy(h_prev)loss = 0for t in range(len(inputs)): # t is a "time step".x[t] = self.char_encoded[inputs[t]].reshape(-1, 1) # input vector.s[t] = np.tanh(np.dot(self.V, x[t]) + np.dot(self.U, s[t - 1]) + self.b_h) # hidden state. f(x(t)*V + s(t-1)*U + b), f=tanh.y[t] = np.dot(self.W, s[t]) + self.b_y # f(s(t)*W + b), f=x.p[t] = np.exp(y[t]) / np.sum(np.exp(y[t])) # softmax. f(x)=exp(x)/sum(exp(x))loss += -np.log(p[t][self.char_to_int[labeling[t]]]) # cross-entropy loss.return loss, p, s, xdef backprop(self, p, labeling, inputs, s, x):dV, dU, dW = np.zeros_like(self.V), np.zeros_like(self.U), np.zeros_like(self.W) # make all zero matrices.dbh, dby = np.zeros_like(self.b_h), np.zeros_like(self.b_y)delta_pj_1 = np.zeros_like(s[0])# error reversedfor t in reversed(range(len(inputs))):dy = np.copy(p[t]) # "dy" means "δpk"dy[self.char_to_int[labeling[t]]] -= 1 # when using cross entropy loss, δpk=d-y.dW += np.dot(dy, s[t].T) # dw/η=δpk * s(t)dby += dydelta_pk_w = np.dot(self.W.T, dy) + delta_pj_1 # δpk * w.delta_pj = (1 - s[t] * s[t]) * delta_pk_w # δpj = δpk * w * f'(x); f(x)=tanh; f'(x)= tanh'(x) = 1-tanh^2(x)dbh += delta_pjdV += np.dot(delta_pj, x[t].T) # dv/η = δpj * x(t)dU += np.dot(delta_pj, s[t - 1].T) # du/η = δpj * s(t-1)delta_pj_1 = np.dot(self.U.T, delta_pj) # δpj (t-1) = δpj * ufor dparam in [dV, dU, dW, dbh, dby]:np.clip(dparam, -1, 1, out=dparam)return dV, dU, dW, dbh, dbydef model_reading(self, model_read_path):if not os.path.exists(model_read_path):print("[Error] the model path %s is not exists." % model_read_path)exit(0)f = open(model_read_path, 'rb')rnn = pickle.load(f)ce = pickle.load(f)rnn.char_encoded = cef.close()self.copy_model(rnn)def model_saving(self, model_save_path):if not os.path.exists(model_save_path):os.system(r"touch {}".format(model_save_path))f = open(model_save_path, 'wb')pickle.dump(self, f, protocol=-1)pickle.dump(self.char_encoded, f, protocol=-1)f.close()def model_training(self, txt_data, ischeck=False):chk_path = self.check_point_dir + "/final.p"if ischeck and os.path.exists(chk_path):rnn.model_reading(chk_path)mV, mU, mW = np.zeros_like(self.V), np.zeros_like(self.U), np.zeros_like(self.W)mbh, mby = np.zeros_like(self.b_h), np.zeros_like(self.b_y)loss = 0.0for i in range(self.iteration):self.h_prev = np.zeros((self.hidden_size, 1))data_pointer = 0for b in range(self.batch_size):inputs = [ch for ch in txt_data[data_pointer:data_pointer + self.sequence_length]]targets = [ch for ch in txt_data[data_pointer + 1:data_pointer + self.sequence_length + 1]]if (data_pointer + self.sequence_length + 1 >= len(txt_data) and b == self.batch_size - 1):targets.append(' ')loss, ps, hs, xs = self.forwardprop(targets, inputs, self.h_prev)dV, dU, dW, dbh, dby = self.backprop(ps, targets, inputs, hs, xs)for weight, g, his in zip([self.V, self.U, self.W, self.b_h, self.b_y],[dV, dU, dW, dbh, dby],[mV, mU, mW, mbh, mby]):his += g * g # RMSProp updatae = 0.5 * his / (i + 1) + 0.5 * g * g # RMSProp updataweight += -self.learning_rate * g / np.sqrt(e + 1e-8) # RMSProp updatedata_pointer += self.sequence_lengthif i % 100 == 0:print('[Debug] iteration %d, loss value: %f' % (i, loss))if ischeck:self.model_saving(self.check_point_dir+"/chk"+str(i)+".p")self.model_saving(chk_path)self.model_saving(chk_path)def model_inference(self, test_char, length):x = self.char_encoded[test_char].reshape(-1, 1)idx = []h = np.zeros((self.hidden_size,1))for t in range(length):h = np.tanh(np.dot(self.V, x) + np.dot(self.U, h) + self.b_h)y = np.dot(self.W, h) + self. b_yp = np.exp(y) / np.sum(np.exp(y))ix = list(p).index(max(list(p)))x = self.char_encoded[self.int_to_char[ix]].reshape(-1, 1)idx.append(ix)txt = ''.join(self.int_to_char[i] for i in idx)print ('[Debug] %s-%s' % (test_char, txt))def run(self, txt_data, bert_path="", word2vec_path="", check_point_path="", ischeck=True, model_type="bert", \itr=1000, seq_len=10, lr=0.001, h_size=100):self.set_fine_tuning_path(bert_path, word2vec_path, check_point_path)if not ischeck:self.training_data_analysis(txt_data, model_type)self.model_building(itr, seq_len, lr, h_size)self.model_training(txt_data, ischeck)if __name__ == "__main__":txt_data = "当地时间6月17日,第53届巴黎-布尔歇国际航空航天展览会(即巴黎航展)开幕。 开幕当天,法国总统马克龙亲自为法国、德国与西班牙三国联合研制的“新一代战斗机”(NGF)的全尺寸模型揭幕。法、德、西三国防长也出席了模型揭幕仪式,并在仪式后签署了三方合作协议,正式欢迎西班牙加入“新一代战机”的联合研制。NGF与美国的F-22、F-35、俄罗斯的苏-57以及中国的歼-20一样,同属第五代战斗机。"rnn = RnnModeling()rnn.set_fine_tuning_path(check_point_dir="e://", word2vec_path='E:\\BaiduNetdiskDownload\\zhwiki\\zhwiki_2017_03.sg_50d.word2vec')rnn.run(txt_data, ischeck=False, check_point_path="e://")rnn.model_inference('法', 10)rnn.model_inference('巴', 10)rnn.model_inference('歼', 10)rnn.model_inference('新', 10)
训练及测试结果:
[Debug] iteration 0, loss value: 28.059744
[Debug] iteration 100, loss value: 2.966153
[Debug] iteration 200, loss value: 1.247683
[Debug] iteration 300, loss value: 0.931227
[Debug] iteration 400, loss value: 0.848960
[Debug] iteration 500, loss value: 0.812240
[Debug] iteration 600, loss value: 0.791726
[Debug] iteration 700, loss value: 0.779109
[Debug] iteration 800, loss value: 0.770437
[Debug] iteration 900, loss value: 0.764572
[Debug] 法-国、德国与美国的F-
[Debug] 巴-黎航展)开幕。 开幕
[Debug] 歼--20一样,同属第五
[Debug] 新-一代战斗机”(NGF
6.2 混沌理论
关于混沌(Chaos)一词,西方和东方在哲学认知和神话传说上惊人的相似。例如古希腊神话中描述的:万物之初,先有混沌,是一个无边无际、空空如也的空间,在发生某种扰动后,诞生了大地之母Gaea等等,世界从此开始。中国古代神话中,天地未开之前,宇宙以混沌状模糊一团,盘古开天辟地后世界从此开始。
而在现代自然科学中,混沌理论的发展反映了人们对客观世界认知一步步演化的过程。人类对自然规律的认知,也从确定性(Deterministic)认知主导逐步演进到概率性(Probabilistic)认知主导。
- 经典力学与机械决定论
牛顿1686年创立了基于万有引力定律和三大定律的古典力学,即:第一定律,在沒有被外力作用下的物体,会保持静止或匀速直线运动状态;第二定律,物体的加速度与物体所受外力的合力成成正比,与物体本身的质量成反比,且加速度方向与合力方向相同;第三定律,两个物体间的作用力和反作用力大小相等方向相反。牛顿的这种基于确定性认知的绝对时空观在很长一段时间占据主导位置,例如拉普拉斯甚至认为:没有什么是不确定的,宇宙的现在是由其过去决定的,只要给定初始条件,智者可以用一个公式概括整个宇宙,预测宇宙未来的发展。拉普拉斯对于概率论有着巨大的贡献,但他认为概率论只是对决定论的补充而已。 - 三体问题
在那个年代,虽然人们对太阳、地球、月亮的运动规律了解的比较清楚,但对三个天体在长时间运动过程中,状态是否保持稳定、能否永远稳定运行等相关问题却没有什么认知,即理论上认为确定性的事情,而事实上却无法用已知的数学模型表达,这个就是天体力学中的经典模型——三体问题。19世纪末,人们已经知道,在一般三体问题中每个天体在其他两个天体引力作用下的运动方程都可以表示成6个一阶常微分方程,这意味着总共需要求18个完全积分才能获得完整解析解,而理论上只能得到10个完全积分,即描述三个或三个以上天体运动的方程组不可积分,更不能得到解析解。
虽然后来欧拉和拉格朗日分别在给定约束条件下求得了限制性三体问题的5个特殊解,即著名的拉格朗日点,但通用三体问题依然无解。 - 庞加莱的错误
庞加莱(就是那个提出庞加莱猜想的庞加莱)在1887年参加瑞典国王发起的“太阳系是稳定的么”的竞赛中,对限定性三体问题发表了一篇论文,初稿出来后,一个名叫弗拉格曼的26岁年轻人发现了其中有不明确的部分,而庞加莱在修改过程中发现了原来的证明有错误,于是在深思熟虑后彻底抛弃了原来通过定量分析求解的方法,转而以定性分析求解并成功给出三体问题的定性解答,而那个错误是由于初始条件的微小误差导致最终结果的南辕北辙,这个观察清晰而定性的开辟了混沌理论。 - 蝴蝶效应
现代科学史中,真正意义上的混沌理论是MIT的洛伦茨(Lorenz)提出的,在此之前人们原本以为,只要配上动力学公式和超级计算机,就能模拟出自然界的各种现象,1961年,洛伦茨用Royal McBee LGP-30计算机(16k内存,每秒60次乘法运算)做气象动力学模拟实验时,由于一个偶然的对初始值做四舍五入的处理,导致模拟结果大相径庭。基于这次实验,1963年,洛伦茨在《气象学报》发表了《確定性的非周期流》系列,以物理意义更加明确的数学模型表示和发展了混沌理论。

洛伦茨系统
简单看一个关于流体热力传导的问题:

当温差较小时,热力会以传导的方式从热的板块到冷的板块,当温差较大时,下面的暖流体上升,上面的冷流体下沉,冷、热板块会产生对流滚动。针对这个问题,洛伦茨将他原始方程中除三个傅立叶系数外的其他系数都设为0,得到了简化的微分方程:
其中是Prandtl系数、是Rayleigh系数、是系统参数,决定了循环的宽度(图中与质检的距离)、与循环流体的流苏成正比,且时流体顺时针对流,时流体逆时针对流、与温差成正比、与垂直温度曲线与平衡温度曲线的失真成正比。
洛伦茨发现,当且时,只要Rayleigh系数超过,系统就会表现为"混沌",即所有的解似乎对初始条件都很敏感,几乎所有的解显然既不是周期性解,也不收敛于周期性解。换句话说,洛伦茨用一个确定性的方程告诉我们一个热力学动态系统的不可预知性。
回想电视剧里看到的离奇故事:
1、因为一滴雨水掉在了马的眼睛里,马摔倒了;
2、恰好骑马的是一名斥候,斥候受伤了;
3、斥候受伤导致手上的情报没有被及时送到军营,军队战败了;
4、军队战败导致重要城市丢失,敌军长驱直入进入都城;
5、都城被灭,皇帝被杀,国家灭亡。
混沌理论的核心思想是:初始条件的微小差别或变化,可以导致最终结果发生剧烈的变化。
下面从理论方面做一些简单介绍,帮助理解未来我们会用到的一些概念。
6.2.1 一维映射
1、动态系统(Dynamical System)
一个动态系统由一组可能的状态组成,再加上一个用过去的状态来确定现在的状态的规则。最典型的动态系统是时间离散动态系统(discrete-time dynamical system)和时间连续动态系统(m continuous-time dynamical system),前面我们介绍的RNN就是一种离散动态系统。
很多现实当中问题往往是随着时间演化的动态系统,例如:模拟细菌生长过程,在给定初始细菌数后,随着时间流逝,细菌数量增长的模型如下:
表示初始细菌数,表示随时间演化,显然这个增长过程是以指数增长的。
2、固点(Fixed Points)
如果动态系统有映射,且满足,则被称为固点。还以上面细菌生长过程为例,几何意义如下图表示:

利用直线发现动态系统的固点只有x=0这一点,画出动态系统的演化轨迹(虚线部分),随着时间流逝,细菌种群规模趋向于正无穷。
但真实情况是,受限于环境、资源等因素,细菌种群规模不可能无限大,所以修改动态系统为:
几何意义如下图表示:

利用直线发现动态系统的固点有x=0和x=0.5这两个点,画出动态系统的演化轨迹(虚线),随着时间流逝,不管初始种群取多少,细菌种群规模最终趋向于0.5(被吸引到0.5),用R做个简单模拟:
g <- function(x){return(2*x*(1-x))}gk <- function(k, x){for(i in 1:k){x = g(x)print(x)}}k=10for (i in 1:10){x=runif(1)gk(k, x)print("=====")}
部分结果如下:
| t | y(x=0.941631) | y(x=0.6455615 ) | y(x=0.1207315 ) |
|---|---|---|---|
| 1 | 0.1099241 | 0.4576237 | 0.2123107 |
| 2 | 0.1956815 | 0.4964085 | 0.3344698 |
| 3 | 0.3147805 | 0.4999742 | 0.4451995 |
| 4 | 0.4313875 | 0.5 | 0.4939938 |
| 5 | 0.4905846 | 0.5 | 0.4999279 |
| 6 | 0.4998227 | 0.5 | 0.5 |
| 7 | 0.4999999 | 0.5 | 0.5 |
| 8 | 0.5 | 0.5 | 0.5 |
| 9 | 0.5 | 0.5 | 0.5 |
| 10 | 0.5 | 0.5 | 0.5 |
3、稳定的固点(Stability of Fixed Points)
假设动态系统的映射为,几何形态如下:

利用直线发现动态系统的固点有和和这三个点,画出动态系统的演化轨迹(虚线),其中和两个点被称为稳定固点,在和两个值的某个邻域内,y会分别收敛于1和-1两个值,为不稳定固点,在它的+邻域内y会被推到上半区,-邻域内y会被推到下半区。
4、吸引固点(Sink)与排斥固点(Source)
首先对点定义它的邻域:
其次,假设动态系统有映射,点为实数值,且满足,如果存在的邻域,使得所有邻域内的点会被吸引到点,即:
则点被称作Sink,反之如果邻域内的点会被排斥远离点,则点被称作Source。
数学化表示如下,记住这个表示,未来解释为什么RNN无法利用梯度下降学到长依赖关系时会用到:
如果是一个在实数集上的平滑映射,假设是的固点,则:
1、如果,则是吸引固点Sink;
2、如果,则是排斥固点Source。
证明:
假设是介于和1之间的任意实数,对于:
存在一个的邻域,使得:
换句话说,相比,更接近,也说明,如果,则,以此类推,、也满足此性质,归纳下变成:
所以是一个吸引固点Sink。
换一个角度,从一阶泰勒展开式或导数的定义来看:
在点的一阶泰勒展开式:
1、如果,则是吸引固点Sink;
2、如果,则是排斥固点Source。
5、k周期点
举一个例子:,其图形如下:

利用直线发现动态系统的固点有和两个点,而这两个点都是排斥固点,那么吸引固点去哪儿了呢?做一个简单模拟:
g <- function(x){return(3.3*x*(1-x))}gk <- function(k, x){for(i in 1:k){x = g(x)print(x)}}k=20for (i in 1:10){x=runif(1)gk(k, x)print("=====")}
部分结果如下:
| t | y(x=0.1156445) | y(x=0.3317354) | y(x=0.0.9131461) |
|---|---|---|---|
| 1 | 0.3374938 | 0.7315672 | 0.2617241 |
| 2 | 0.7378527 | 0.6480429 | 0.6376411 |
| 3 | 0.6383061 | 0.7526749 | 0.7624812 |
| 4 | 0.7618757 | 0.6143128 | 0.5976419 |
| 5 | 0.5986897 | 0.7818775 | 0.793538 |
| 6 | 0.7928592 | 0.5627987 | 0.540657 |
| 7 | 0.5419706 | 0.8119858 | 0.8195451 |
| 8 | 0.8191869 | 0.5037939 | 0.48804 |
| 9 | 0.488795 | 0.8249525 | 0.824528 |
| 10 | 0.8245857 | 0.4765394 | 0.4774493 |
| 11 | 0.4773257 | 0.8231837 | 0.8233218 |
| 12 | 0.8233034 | 0.4803226 | 0.4800279 |
| 13 | 0.4800672 | 0.8237222 | 0.8236837 |
| 14 | 0.8236889 | 0.4791729 | 0.4792553 |
| 15 | 0.4792442 | 0.8235686 | 0.8235799 |
| 16 | 0.8235784 | 0.4795012 | 0.479477 |
| 17 | 0.4794803 | 0.8236133 | 0.8236101 |
| 18 | 0.8236105 | 0.4794056 | 0.4794125 |
| 19 | 0.4794116 | 0.8236004 | 0.8236013 |
| 20 | 0.8236012 | 0.4794332 | 0.4794312 |
一个有意思的现象出现,和交替出现且为吸引固点,换个角度就是:,,也就是吸引固点以2为周期出现,在两个点间循环往复。
形式化定义为:
假设动态系统有实数集上的映射,点为实数值,且满足,为正整数,则被称为k周期点。
扩展下之前吸引固点的定义到k周期点:
如果是一个在实数集上的平滑映射,假设构成了的周期点,则:
1、如果,则是吸引固点Sink;
2、如果,则是排斥固点Source。
还是上面的那个例子:
则有:
k周期点为:
因为,所以它是吸引固点。
6.2.2 二维映射
把一维映射扩展到多维映射,看看会出现什么有趣的现象,由于二维映射是多维映射的最简单形式且各种性质与多维映射一致,固以此为基础讨论。
1、邻域
扩展一维映射时的邻域概念如下:
在欧式空间实数域下,向量的范数定义为:
对定义它的邻域:
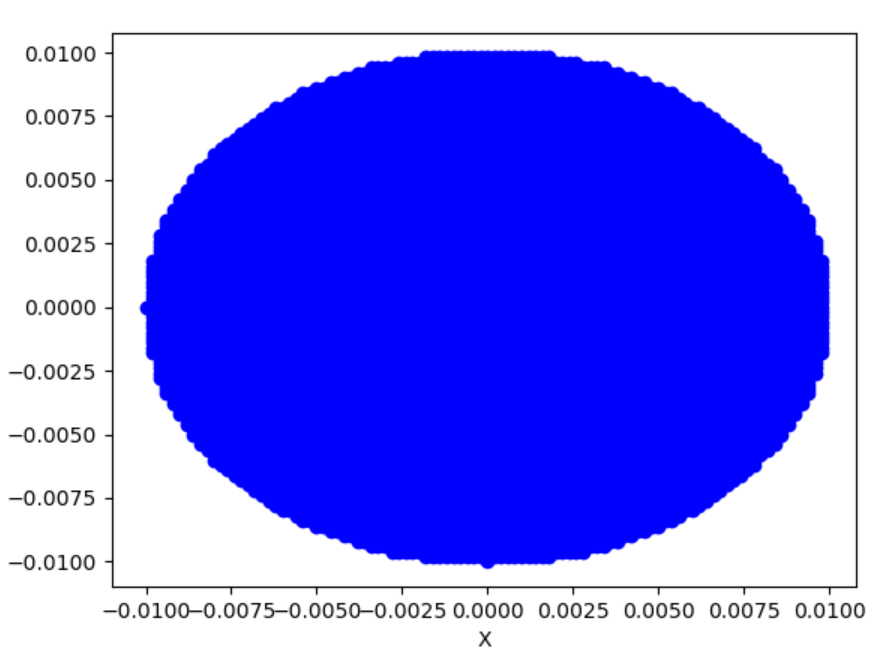
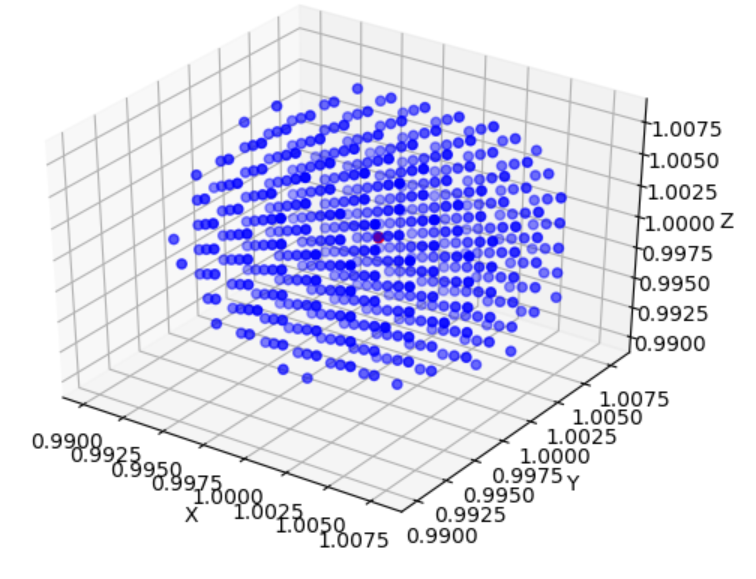
有时候也叫的-,举个例子。
二维下():
三维下():
2、固点
其次,假设动态系统有实数域的映射,为实数域固点,即满足,如果存在的邻域,使得所有邻域内会被吸引到,即:
则被称作Sink,反之如果邻域内的点会被排斥远离点,则点被称作Source。
在二维映射下还会出现一个一维映射时不会出现的固点,叫做鞍点(Saddle),可以把它看做介于吸引固点和排斥固点间的一种状态,它拥有至少一个吸引方向和至少一个排斥方向。

图中代表映射,代表点的邻域。图代表是一个吸引固点,进入其邻域的点会被吸引到点、图代表是一个排斥固点,进入其邻域的点会被排斥而远离点、图代表是一个鞍点,进入其邻域的点先会被吸引到点,然后会被排斥而远离点。来个更直观的图:

在《最优化原理-梯度下降》这一章我们曾经介绍过常用的一阶最优化方法,给定初始值后,不同的优化方法的优化轨迹不一样,但大的方向都是先被迭代吸引到鞍点,然后再从鞍点被排斥走,而因为待优化问题往往有很多局部最优点,所以我们希望优化算法能尽可能跳出当前点去寻找更优的局部最优点。
综上所述,显然排斥固点Source和鞍点Saddle的最大特点是:它们都是固点,都不是稳定固点,因为它们对初始条件很敏感,但对研究一个动态系统它们很重要。
6.2.3 线性映射
1、线性映射
所谓线性映射是指:
给定实数及实数向量,有的映射满足:
显然原点(0,0)是所有线性映射的固点,且是稳定的,如果它邻域内的点在迭代映射时都趋向于接近固点,则该固点是一个吸引子,稍微正式点的定义如下:
在一个随时间演变的动态系统中,吸引子是一个代表某种稳定状态的数值集合,在给定动态系统初始状态后,系统有着朝该集合所表示的稳态演化的趋势,在吸引子的某个邻域(basin of attraction)范围内,即使系统受到扰动,也会趋向于该稳态。
后面会大量出现吸引子这个概念。
2、鞍点
如果实数和实数向量满足:
则它们分别被称为A的特征值和特征向量。
假设有以下向量关系:
则有递推关系:
以上的映射为例:
表示成矩阵形式:
以上过程迭代了次后得到:
这里就有意思了,迭代了次后,把它映射在一个二维平面上,看上去应该是个椭圆形,其中横坐标长度为,纵坐标为,对于原点的某个邻域同样也是个椭圆,横纵坐标长度分别为和,假设,则会有三种情况:
1、如果,则整个椭圆会收缩到原点(0,0),原点是Sink;
2、如果,则整个椭圆会无限过大并远离原点(0,0),原点是Source;
3、如果,则整个椭圆的横坐标会无限扩大,而纵坐标会收缩到0,此时原点既不是Sink也不是Source,人们把它叫做Saddle(鞍点)。

假设取:,则:
经过次迭代后,得到下图:


3、双曲(hyperbolic)
假设A是实数域矩阵,基于它定义了的线性映射,则:
如果的所有特征值的绝对值都小于1,则原点是一个吸引固点Sink;
如果的所有特征值的绝对值都大于1,则原点是一个排斥固点Source;
如果的所有特征值中至少有一个其绝对值大于1,且最少有一个其绝对值小于1,则原点是一个鞍点Saddle。
如果一个映射,没有一个特征值的绝对值等于1,则我们把叫做是双曲的,显然有三类双曲映射:Sink、Source、Saddle。
6.2.4 非线性映射
真实世界中,非线性系统远远多于线性系统,而当非线性程度足够高时,系统将出现混沌状态,不过从概念和定义上与线性映射区别不大。前面说的吸引固点和k周期吸引固点都是运动状态可预测的,它们被叫做平庸吸引子,而运动状态不可预测的叫做奇异吸引子(Strange Attractor)。
同样利用泰勒展开式,在非线性高维空间,导数被扩展为雅克比矩阵(Jacobian matrix):
其中:
1、是上的映射,
2、雅可比矩阵为:
假设为固点,满足,则:
即,在点邻域内对其做一个微小扰动,输出会有的变化,显然类似线性映射,可以有下面结论:
假设:是上的映射,且,满足,则:
1、如果没有取值为1的特征值,则被称作双曲(hyperbolic)的,这个词很重要,会在后面多次出现,直观的也挺好理解,1的多少次方都还是1,只有大于1或小于1才会在某个方向上要么吸引要么排斥;
2、如果的每个特征值的绝对值都小于1,那么是一个吸引固点Sink,也有人叫做双曲吸引子(hyperbolic attractor);
3、如果的每个特征值的绝对值都大于1,那么是一个排斥固点Source;
4、如果且是双曲的,至少有一个特征值的绝对值大于1且至少有一个特征值的绝对值小于1,则是一个鞍点Saddle。
举个例子:
有非线性映射:
因为,则有且
所以有两个固点:
其雅克比矩阵为:
于是:
特征值为:
特征值为:和,显然,为双曲吸引子,为鞍点。
6.2.5 混沌的演化及结构
用一个简单的抛物线做说明:
将其转化为迭代形式(一般来说,越复杂的非线性方程越无解析解,常常用数值计算中的迭代方法得到解):
程序模拟迭代过程:
import numpy as npimport matplotlib.pyplot as plt# 抛物线函数def parabola(r, x):return 1 - r * x**2def plot_bifu(iterations, r, x0, last):ax = plt.subplot(111)x = x0for i in range(iterations):x = parabola(r, x)if i >= (iterations - last):ax.plot(r, x, ',k', alpha=.25)ax.set_xlim(0, 2)ax.set_title("Bifurcation: y=1-rx^2")plt.show()def main():n = 10000r = np.linspace(0, 2.0, n)iterations = 1000 # 迭代次数last = 200 # 输出最后若干次迭代x0 = 0.1 * np.ones(n) # 初始点plot_bifu(iterations, r, x0, last)
其分叉图如下,结构上按照指数级周期性分裂,当时,系统进入混沌状态:

对下图红框部分放大看,可以发现一个有趣的东西:

放大的部分其结构与开始时的整体结构相同,一般叫做分形,于是在混沌中再次出现周期性:

随着复杂度的提升,系统经历了:稳定态->周期态->类周期态->混沌态。
还可以再次放大类似的红框区域,但会发现一个普适的规律:
其中是发生混沌现象时的分界点。上面这个常数叫做Feigenbaum常数,它可能是比圆周率更神秘的常数,我没有做更深入的了解,详情可参见论文《Quantitative universality for a class of nonlinear transformations》,换句话说,混沌演化的过程中存在内部规律性,且这种演化过程存在某种“普适性”。
6.2.6 RNN长依赖学习问题
这一节主要基于对Yoshua Bengio《Learning Long-Term Dependencies with Gradient Descent is Difficult》一文的学习,个人认为它是少有的对长依赖学习做出精彩理论研究和证明的文章。
文章从实验和理论角度证明了:梯度下降算法无法有效学习长依赖(模型在时间t的输出依赖更早时间时的系统状态)。
一个能学习长依赖的动态系统,至少应该满足以下几个条件:
1、系统能够存储任意时长的信息;
2、系统鲁棒性强,即使对系统输入做随机波动也不影响系统做出正确输出;
3、系统参数可在合理有限的时间内学习到。
单节点RNN实验
设计一个满足以上条件的简单的序列二分类问题:
给定任意序列:,二分类器,且分类结果只与序列的前()个输入有关,即:
显然,之后的信息都是噪声(文中实验采用高斯噪声),如果系统不能有效存储任意时长的信息则无法做正确分类。换句话说,分类器内置了一个latching subsystem(暂且翻译为锁存子系统),这个子系统可以提取分类的关键信息,并存储于子系统的状态变量中。

当时,为可学习调整的参数,当时,为高斯噪声,损失函数为:
其中是训练序列的索引,是目标输出,取值0.8代表分类1,取值-0.8代表分类0,代表抽取了分类关键信息后的计算结果,显然,直接学习要比用原始输入学习 来的容易,而且不管以上哪种方式,传播误差梯度的方法一样,如果因为梯度消失导致都学不出来,更别说了。
以最简单的RNN为例:

如果,则以上动态系统有两个双曲吸引子,即下图的:

依据《Unified integration of explicit rules and learning by example in recurrent networks》的证明,假设初始状态是,则存在使得:
1、如果,,的符号可以保持不变,即在负向吸引子邻域的点会被吸引;
2、存在有限步数,如果,,使得,即超过吸引子邻域的点会被吸引到正向吸引子。
当取固定值时, 随着 增加而减小。
总结如下:
1、上述简单的系统可以锁存1 bit信息(即输出的符号变化与否);
2、系统通过对一个大的输入保持足够长的时间来存储信息();
3、对输入做微小的噪声扰动,即使时间很长也不会改变激活函数输出的符号。
4、也是可学习的,当时,要求,此时会生成正负向两个吸引子,且越大,相应的阈值越大,因此系统鲁棒性越强。

上图加粗的点展示了系统成功学出来的3个()。
5、实验结果:
1)、下图a,取,做实验,发现随着高斯噪声的标准差增大,变小,系统收敛性越来越差。
2)、下图b,取高斯噪声,做实验,发现随着 的增加,系统收敛性越来越差,即在这么简单的系统中,梯度下降算法想长时间稳定的存储1 bit信息都很困难。

混沌理论角度的解释

回忆前几节关于映射及吸引子、双曲吸引子的说明,围绕着吸引子(attractor)有几个相关定义:
1、basin of attractor:其实就是吸引子的邻域:
2、reduced attractor set:其实就是被双曲吸引子强吸引的点集合:
直观展示它们的关系如上图,显然:
如果任意时刻对一个锁存子系统的输入做微小扰动后都落在该系统双曲吸引子的reduced attractor set中,即图中,则该锁存系统具有鲁棒性。
3、对于双曲吸引子邻域内的点,如果在但不在中,则不确定性会随着的增加而呈指数增加,最终微小的扰动会让远离而进入其他吸引子的邻域,如下图:

证明:
假设,满足及,则根据泰勒展开式,对一个很小的值有:
对一个开放集合,存在一个很小的值,使得,且。另,则根据三角不等式有:
而:
所以有:
从而得到:
即:对的微小扰动会使得的变化“幅度”增大。
4、一个具有鲁棒性的锁存子系统特点是:即使对系统输入有微小扰动,只要每次迭代时都在双曲吸引子的内,则最终会被吸引收敛到双曲吸引子附近。如下图:

5、动态系统要想做到鲁棒性的锁存信息,则会出现梯度消失现象(gradient vanishing),鱼与熊掌不可兼得。
一个通用的动态系统可以表示为:
其中和分别是时刻系统状态向量和时刻外部输入向量,根据导数的定义和双曲吸引子的性质有:
显然,当时,,梯度消失!
6.3 LSTM
上面两节从原理角度说明了RNN为什么很难学到长依赖,而本节的LSTM是一个伟大的和具有里程碑的模型,最著名的论文是Sepp Hochreiter 与 Jurgen Schmidhuber的《Long Short-Term Memory 》(没错,就是那位怼天怼地怼各种权威的Schmidhuber),从原理上分析解决了RNN学习长依赖中的梯度爆炸(blow up)和梯度消失(vanish)问题,大部分文章只介绍了LSTM的结构,我希望通过本文能抛砖引玉,了解作者为什么这么设计结构。
6.3.1 基本原理
回忆6.1节末的RNN任意两层隐藏层
其中:是在时刻的任何一个隐层节点,是在时刻的任何一个隐层节点,高层的可以通过循环递归的计算出来,所有计算完毕后累加求和并应用在、的权重更新中。
误差从时刻的隐藏层节点经过任意步往时刻的隐藏层节点做反向传播的传播速度如下:
把上面式子完全展开后得到:
大家会发现整个误差反向传播速度是由决定的:
1、如果,则连乘的结果会随着的增加呈指数形式增大,误差反向传播出现梯度爆炸;
2、如果,则连乘的结果会随着的增加呈指数形式减小,误差反向传播出现梯度消失。
假设以最简单的RNN为例,即:
在时刻的反向误差传播为:
其中:。要想不出现梯度爆炸或消失,只能满足:
对上式积分下,得到:
这意味着,函数必须是线性的,显然,当时,有恒等映射函数,上述关系也叫constant error carrousel(CEC),CEC在LSTM的结构设计中举足轻重。
以输入权重为例,由于实际场景中除了自连接节点外,还会有其他输入节点,为简单起见,我们只关注一个额外的输入权重 。假设通过响应某个输入而开启神经网络单元,并为了减少总误差,希望它能被长时间激活。显然,对同一个输入权重一方面要存储某些输入范式,一方面又要忽略其他输入范式,而涉及节点的函数(上面的CEC)又是线性的,所以对而言,这些信号会试图让它既得通过开启单元对输入做存储又需要防止单元被其他输入关闭,这种情况使得学习变得困难。

对于输出权重,也存在类似的输出冲突,这里就不在赘述。
为了解决上面的输入和输出冲突,LSTM抽象了1个记忆单元(Memory Cel l)、设计了1个基础结构——遗忘门(Forget Gate)和2个组合结构——输入门(Input Gate)和输出门(Output Gate)来解决冲突。
1、记忆单元是对包含CEC线性单元的抽象,如下图(以RNN作为对比),包含当前时刻输入、上个隐层节点的状态、当前时刻输出、当前时刻隐层节点状态。:


1、遗忘门的结构如下图:它将上一个隐层的状态和当前输入合并后送入logistic函数,由于该函数输出为0~1之间,输出接近1的被保留,接近0的被丢掉,也就是说,遗忘门决定了哪些历史信息要被保留。

2、输入门的结构如下图:它将上一个隐层的状态和当前输入合并后送入Logistic函数,输出介于0~1之间,同样的,0表示信息不重要,1表示信息重要;同时,和合并后的输入被送入Tanh函数,输出介于-1~1之间,Logistic的输出与Tanh的输出相乘后决定哪些Tanh的输出信息需要保留,哪些要丢掉,也就是说,输入门决定了哪些新的信息要被加进来。

前一个记忆单元的输出与遗忘门输出相乘后,可以选择性忘记不重要的信息,之后与输入门的结果相加,把新的输入信息纳入进来,最终得到当前记忆单元的输出,比较好解决了输入冲突,如下图:

3、输出门的结构如下图:它主要解决隐藏层状态的输出冲突问题,它将上一个隐层的状态和当前输入合并后送入Logistic函数,输出介于0~1之间,然后与当前记忆单元的输出通过Tanh函数变换后的结果相乘,得到当前隐藏层的状态,也就是说,输出门决定了当前隐藏层要携带哪些历史信息,比较好解决了输出冲突。

以上图片来源于:《Understanding LSTM Networks》一文,非常不错的一篇LSTM入门文章。后续也有各种各样对经典LSTM的改进(如GRU),但整体上不如LSTM经典(截止2020.10.10在Google Scholar上查寻到该论文已经被引用了37851次,成为20世纪“最火论文”)。
除了比较完美解决了输入输出冲突外,LSTM的计算和存储复杂度并不高,权重更新计算的复杂度为O(W),即与权重总个数线性相关;存储方面也不像使用全流程BPTT的传统方法,要存储大量历史节点信息,LSTM只需要存储一定历史时间步的局部信息。
6.3.2 代码实践
本节以经典的《古诗词生成》为例子,介绍下LSTM的一种应用,以下例子只供娱乐使用。
问题描述如下:
给定五言绝句的首句,生成整首共4句的五言绝句。
例如,输入:“月暗竹亭幽,”,输出“月暗竹亭幽,碧昏时尽黄。园春歌雪光,云落分白草。”。
完整代码在:https://github.com/vivounicorn/LstmApp.git,其中,data文件夹里包含了训练好的word2vec模型和迭代了2k+次的模型,可以直接做fine-tune。
1、算法步骤
Step-1:爬取古诗词作为原始数据;
Step-2:清洗原始数据,去掉不符合五言绝句的诗词;
Step-3:准备训练数据和相应的标注;
Step-4:若使用word2vec生成的词向量,则需要生成相关模型;
Step-5:构建以LSTM层和全连接层为主的神经网络;
Step-6:训练和验证模型,并做应用。
2、实现详情
- Step-1,爬取古诗词作为原始数据
用开源工具爬取:https://www.gushiwen.org/上的诗句。解析结果的基本格式为:“诗词标题:诗词内容”。 - Step-2,数据清洗
def _build_base(self,file_path,vocab=None,word2idx=None,idx2word=None) -> None:"""To scan the file and build vocabulary and so on.:param file_path: the file path of poetic corpus, one poem per line.:param vocab: the vocabulary.:param word2idx: the mapping of word to index.:param idx2word: the mapping of index to word:return: None."""# 去掉无关字符pattern = re.compile(u"_|\(|(|《")with open(file_path, "r", encoding='UTF-8') as f:for line in f:try:line = line.strip(u'\n')title, content = line.strip(SPACE).split(u':')content = content.replace(SPACE, u'')idx = re.search(pattern, content)if idx is not None:content = content[:idx.span()[0]]# 把指定长度的诗词选出来,如:五言绝句。if len(content) < self.embedding_input_length: # Filter data according to embedding input# length to improve accuracy.continuewords = []for i in range(0, len(content)):word = content[i:i + 1]if (i + 1) % self.embedding_input_length == 0 and word not in [',', ',', ',', '.', '。']:words = []breakwords.append(word)self.all_words.append(word)if len(words) > 0:self.poetrys.append(words)except Exception as e:log.error(str(e))# 生成词汇表,保留出现频次top n的字if vocab is None:top_n = Counter(self.all_words).most_common(self.vocab_size - 1)top_n.append(SPACE)self.vocab = sorted(set([i[0] for i in top_n]))else:top_n = list(vocab)[:self.vocab_size - 1]top_n.append(SPACE)self.vocab = sorted(set([i for i in top_n])) # cut vocab with threshold.log.debug(self.vocab)# 生成“字”到“编号”的映射,把每个字做了唯一编号,“空格”也做编号if word2idx is None:self.word2idx = dict((c, i) for i, c in enumerate(self.vocab))else:self.word2idx = word2idx# 生成“编号”到“字”的映射if idx2word is None:self.idx2word = dict((i, c) for i, c in enumerate(self.vocab))else:self.idx2word = idx2word# Function of mapping word to index.# 以 “字” 查找 “编号”的函数,没在词汇表的“字”用“空格”的编号代替self.w2i = lambda word: self.word2idx.get(str(word)) if self.word2idx.get(word) is not None \else self.word2idx.get(SPACE)# Function of mapping index to word.# 以 “编号”查找 “字” 的函数,找不到的“字”用“空格”代替self.i2w = lambda idx: self.idx2word.get(int(idx)) if self.idx2word.get(int(idx)) is not None \else SPACE# Full vectors.# 把文本表示的诗词变成由“编号”表示的向量,如:“床前明月光,”变成[1,2,3,4,5,6]self.poetrys_vector = [list(map(self.w2i, poetry)) for poetry in self.poetrys]self._data_size = len(self.poetrys_vector)self._data_index = np.arange(self._data_size)
- Step-3:准备训练数据
原理是:根据指定的输入长度(input length)截取序列并生成特征数据,指定这个序列的下一个字为“标注”。
例如:“菩提本无树,明镜亦非台。”,以五言绝句为例,输入长度为6(包括标点符号),可以生成以下样本:
| 特征 | 标注 |
|---|---|
| 菩提本无树, | 明 |
| 提本无树,明 | 镜 |
| 本无树,明镜 | 亦 |
| 无树,明镜亦 | 非 |
| 树,明镜亦非 | 台 |
| ,明镜亦非台 | 。 |
对每个字,支持两种编码方式:基于词汇表的one hot和基于语义distributed representation的word2vec。
1、One-hot
def _one_hot_encoding(self, sample):"""One-hot encoding for a sample, a sample will be split into multiple samples.:param sample: a sample. [1257, 6219, 3946]:return: feature and label. feature:[[0,0,0,1,0,0,......],[0,0,0,0,0,1,......],[1,0,0,0,0,0,......]];label: [0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0......]"""if type(sample) != list or 0 == len(sample):log.error("type or length of sample is invalid.")return None, Nonefeature_samples = []label_samples = []idx = 0# embedding_input_length即为输入窗口长度,五言绝句为6,当然也可以取其他值,但会影响训练精度和时间。while idx < len(sample) - self.embedding_input_length:feature = sample[idx: idx + self.embedding_input_length]label = sample[idx + self.embedding_input_length]label_vector = np.zeros(shape=(1, self.vocab_size),dtype=np.float)# 序列的下一个字为标注label_vector[0, label] = 1.0feature_vector = np.zeros(shape=(1, self.embedding_input_length, self.vocab_size),dtype=np.float)# 根据词汇表,相应的编号赋值为1,其余都是0.for i, f in enumerate(feature):feature_vector[0, i, f] = 1.0idx += 1feature_samples.append(feature_vector)label_samples.append(label_vector)return feature_samples, label_samples
假设输入长度为6,词汇表维度为8000,则,对于一个样本有:
特征矩阵为:1×6*8000
标注向量为:1*8000

2、Word2vec
def _word2vec_encoding(self, sample):"""word2vec encoding for sample, a sample will be split into multiple samples.:param sample: a sample. [1257, 6219, 3946]:return: feature and label.feature:[[0.01,0.23,0.05,0.1,0.33,0.25,......],[0.23,0.45,0.66,0.32,0.11,1.03,......],[1.22,0.99,0.68,0.7,0.8,0.001,......]];label: [0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0......]"""if type(sample) != list or 0 == len(sample):log.error("type or length of sample is invalid.")return None, Nonefeature_samples = []label_samples = []idx = 0while idx < len(sample) - self.embedding_input_length:feature = sample[idx: idx + self.embedding_input_length]label = sample[idx + self.embedding_input_length]if self.w2v_model is None:log.error("word2vec model is none.")return None, Nonelabel_vector = np.zeros(shape=(1, self.vocab_size),dtype=np.float)# 序列的下一个字为标注label_vector[0, label] = 1.0feature_vector = np.zeros(shape=(1, self.embedding_input_length, self.w2v_model.size),dtype=np.float)# 用训练好的word2vec模型获取相应“字”的语义向量for i in range(self.embedding_input_length):feature_vector[0, i] = self.w2v_model.get_vector(feature[i])idx += 1feature_samples.append(feature_vector)label_samples.append(label_vector)return feature_samples, label_samples
假设输入长度为6,词的语义向量维度为200,则,对于一个样本有:
特征矩阵为:1×6*200
标注向量为:1*8000

- Step-4:基于word2vec训练词向量
使用dump函数将训练数据相关数据结构dump下来,其中poetrys_words.dat文件可直接作为word2vec的训练数据(注:要训练的是字粒度的语义向量),文件内容类似这样,一行一首诗,字与字空格分割:
寒 随 穷 律 变 , 春 逐 鸟 声 开 。 初 风 飘 带 柳 , 晚 雪 间 花 梅 。 碧 林 青 旧 竹 , 绿 沼 翠 新 苔 。 芝 田 初 雁 去 , 绮 树 巧 莺 来 。
晚 霞 聊 自 怡 , 初 晴 弥 可 喜 。 日 晃 百 花 色 , 风 动 千 林 翠 。 池 鱼 跃 不 同 , 园 鸟 声 还 异 。 寄 言 博 通 者 , 知 予 物 外 志 。
def dump_data(self) -> None:"""To dump: poetry's words list, poetry's words vectors, poetry's words vectors for training,poetry's words vectors for testing, poetry's words vectors for validation,poetry's words vocabulary, poetry's word to index mapping,poetry's index to word mapping.:return: None"""org_filename = self.dump_dir + 'poetrys_words.dat'self._dump_list(org_filename, self.poetrys)vec_filename = self.dump_dir + 'poetrys_words_vector.dat'self._dump_list(vec_filename, self.poetrys_vector)train_vec_filename = self.dump_dir + 'poetrys_words_train_vector.dat'self._dump_list(train_vec_filename, self.poetrys_vector_train)valid_vec_filename = self.dump_dir + 'poetrys_words_valid_vector.dat'self._dump_list(valid_vec_filename, self.poetrys_vector_valid)test_vec_filename = self.dump_dir + 'poetrys_words_test_vector.dat'self._dump_list(test_vec_filename, self.poetrys_vector_test)vocab_filename = self.dump_dir + 'poetrys_vocab.dat'self._dump_list(vocab_filename, list(self.vocab))w2i_filename = self.dump_dir + 'poetrys_word2index.dat'self._dump_dict(w2i_filename, self.word2idx)i2w_filename = self.dump_dir + 'poetrys_index2word.dat'self._dump_dict(i2w_filename, self.idx2word)
模型方面直接使用gensim包,定义如下,根据参数不同,可以训练得到基于CBOW或SkipGram的语义向量,我们这种规模下,本质上没有太大差别,我们这里使用SkipGram。
#!/usr/bin/env python3# -*- coding: utf-8 -*-import gensimfrom gensim.models import Word2Vecfrom gensim.models.word2vec import LineSentenceimport multiprocessingimport numpy as npfrom src.config import Configfrom src.utils import Loggerclass Word2vecModel(object):"""Word2vec model class."""def __init__(self,cfg_path='/home/zhanglei/Gitlab/LstmApp/config/cfg.ini',is_ns=False):"""To initialize model.:param cfg_path: he path of configration file.:param model_type:"""cfg = Config(cfg_path)global loglog = Logger(cfg.model_log_path())self.model = Noneself.is_ns = is_nsself.vec_out = cfg.vec_out()self.corpus_file = cfg.corpus_file()self.window = cfg.window()self.size = cfg.size()self.sg = cfg.sg()self.hs = cfg.hs()self.negative = cfg.negative()def train_vec(self) -> None:"""To train a word2vec model.:return: None"""output_model = self.vec_out + 'w2v_size{0}_sg{1}_hs{2}_ns{3}.model'.format(self.size,self.sg,self.hs,self.negative)output_vector = self.vec_out + 'w2v_size{0}_sg{1}_hs{2}_ns{3}.vector'.format(self.size,self.sg,self.hs,self.negative)# 是否做负采样if not self.is_ns:self.model = Word2Vec(LineSentence(self.corpus_file),size=self.size,window=self.window,sg=self.sg,hs=self.hs,workers=multiprocessing.cpu_count())else:self.model = Word2Vec(LineSentence(self.corpus_file),size=self.size,window=self.window,sg=self.sg,hs=self.hs,negative=self.negative,workers=multiprocessing.cpu_count())self.model.save(output_model)self.model.wv.save_word2vec_format(output_vector, binary=False)def load(self, path):"""To load a word2vec model.:param path: the model file path.:return: success True otherwise False."""try:self.model = gensim.models.Word2Vec.load(path)return Trueexcept:return Falsedef most_similar(self, word):"""Return the most similar words.:param word: a word.:return: similar word list."""word = self.model.most_similar(word)for text in word:log.info("word:{0} similar:{1}".format(text[0], text[1]))return word# 获取某个字 的语义向量def get_vector(self, word):"""To get a word's vector.:param word: a word.:return: word's word2vec vector."""try:return self.model.wv.get_vector(str(word))except KeyError:return np.zeros(shape=(self.size,),dtype=np.float)# 也可以直接把keras的embedding层给拿出来,# 为了直观,我这里没有直接用它,如果要用,记着把语义向量的权重冻结下。def get_embedding_layer(self, train_embeddings=False):"""To get keras embedding layer from model.:param train_embeddings: if frozen the layer.:return: embedding layer."""try:return self.model.wv.get_keras_embedding(train_embeddings)except KeyError:return None
- Step-5:构建LSTM模型
def _build(self,lstm_layers_num,dense_layers_num):"""To build a lstm model with lstm layers and densse layers.:param lstm_layers_num: The number of lstm layers.:param dense_layers_num:The number of dense layers.:return: model."""units = 256model = Sequential()# 样本特征向量的维度,onehot为词汇表大小,word2vec为语义向量维度if self.mode == WORD2VEC:dim = self.data_sets.w2v_model.sizeelif self.mode == ONE_HOT:dim = self.vocab_sizeelse:raise ValueError("mode must be word2vec or one-hot.")# embedding_input_length为输入序列窗口大小,如:五言绝句取为6model.add(Input(shape=(self.embedding_input_length, dim)))# 可以加多个LSTM层提取序列特征,这里会把之前每隔时刻的隐层都输出出来for i in range(lstm_layers_num - 1):model.add(LSTM(units=units * (i + 1),return_sequences=True))model.add(Dropout(0.6))# 注意这里我只要最后一个隐层的输出model.add(LSTM(units=units * lstm_layers_num,return_sequences=False))model.add(Dropout(0.6))# 可以加多个稠密层,用于对之前提取出来特征的组合for i in range(dense_layers_num - 1):model.add(Dense(units=units * (i + 1)))model.add(Dropout(0.6))# 最后一层,用softmax做分类model.add(Dense(units=self.vocab_size,activation='softmax'))# 使用交叉熵损失函数,优化器选择默认参数的adam(ps:随便选的,没做调参)model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])model.summary()# 可视化输出模型结构plot_model(model, to_file='../model.png', show_shapes=True, expand_nested=True)self.model = modelreturn model
例如:使用200维语义向量、输入长度6、词汇量8000、两层LSTM,一层Dense的模型结构如下:

- Step-6:模型训练和应用
#!/usr/bin/env python3# -*- coding: utf-8 -*-from src.lstm_model import LstmModelfrom src.data_processing import PoetrysDataSetfrom src.word2vec import Word2vecModeldef train_word2vec(base_data) -> None:w2v = Word2vecModel()w2v.train_vec()# test.a = w2v.most_similar(str(base_data.w2i('床')))for i in range(len(a)):print(base_data.i2w(a[i][0]), a[i][1])def train_lstm(base_data, finetune=None, mode='word2vec'):model = LstmModel(cfg_file_path, base_data, mode)# fine tune.if finetune is not None:model.load(finetune)model.train_batch(mode=mode)return modeldef test_lstm(base_data, sentence, model_path=None, mode='word2vec'):model = LstmModel(cfg_file_path, base_data, mode)if model_path is not None:model.load(model_path)return model.generate_poetry(sentence, mode=mode)if __name__ == '__main__':cfg_file_path = '/home/zhanglei/Gitlab/LstmApp/config/cfg.ini'w2vmodel_path = '/home/zhanglei/Gitlab/LstmApp/data/w2v_models/w2v_size200_sg1_hs0_ns3.model'model_path = '/home/zhanglei/Gitlab/LstmApp/data/models/model-2117.hdf5'base_data = PoetrysDataSet(cfg_file_path)train_word2vec(base_data)base_data.load_word2vec_model(w2vmodel_path)train_lstm(base_data=base_data, finetune=model_path)sentence = '惜彼落日暮,'print(test_lstm(base_data=base_data, sentence=sentence, model_path=model_path))
在model.log里会看到训练时的中间信息,如下,随着迭代次数变多,效果会越来越好,包括标点符号的规律也会学进去:
[2020-11-05 12:58:48,723] - lstm_model.py [Line:127] - [DEBUG]-[thread:140045784893248]-[process:29513] - begin training[2020-11-05 12:58:48,723] - lstm_model.py [Line:132] - [DEBUG]-[thread:140045784893248]-[process:29513] - batch_size:32,steps_per_epoch:355,epochs:5000,validation_steps152[2020-11-05 12:59:10,260] - lstm_model.py [Line:194] - [INFO]-[thread:140045784893248]-[process:29513] - ==================Epoch 0, Loss 7.93123197555542=====================[2020-11-05 12:59:11,968] - lstm_model.py [Line:197] - [INFO]-[thread:140045784893248]-[process:29513] - 欲别牵郎衣,粳酗蓦釱北,鈒静槃遍衫。恸阳日搦蛆,[2020-11-05 12:59:12,816] - lstm_model.py [Line:197] - [INFO]-[thread:140045784893248]-[process:29513] - 金庭仙树枝,莨行查娇乂。具撅日霈韂,帝鸟 维。。[2020-11-05 12:59:13,659] - lstm_model.py [Line:197] - [INFO]-[thread:140045784893248]-[process:29513] - 素艳拥行舟,母 佶翕何,藁澡 。一 钺辗。,[2020-11-05 12:59:14,494] - lstm_model.py [Line:197] - [INFO]-[thread:140045784893248]-[process:29513] - 白鹭拳一足,芾 乡诏秩,启窑 展赢,酪溜劫騊 ,[2020-11-05 12:59:15,385] - lstm_model.py [Line:197] - [INFO]-[thread:140045784893248]-[process:29513] - 恩酬期必报,闾瞢,颾钏。啾,。耴望,薖,州耒朿。[2020-11-05 12:59:16,277] - lstm_model.py [Line:197] - [INFO]-[thread:140045784893248]-[process:29513] - 君去方为宰,沈乡看一帷,柳跂 仁柳,营空长日韍。[2020-11-05 12:59:16,278] - lstm_model.py [Line:198] - [INFO]-[thread:140045784893248]-[process:29513] - ==================End=====================......[2020-11-06 02:12:12,971] - lstm_model.py [Line:194] - [INFO]-[thread:140348029687616]-[process:31309] - ==================Epoch 2106, Loss 7.458868980407715=====================[2020-11-06 02:12:13,732] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 新开窗犹偏,回雨草花天。谁因家群应,人年功日未。[2020-11-06 02:12:14,498] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 此心非一事,白物郡期旧。相爱含将回,更相日见光。[2020-11-06 02:12:15,274] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 刻舟寻已化,有恨多两开。去闻难乱东,地中当如来。[2020-11-06 02:12:16,069] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 带水摘禾穗,鸟独光冥客。拂船不自已,远年必年非。[2020-11-06 02:12:16,846] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 茕茕孤思逼,此前路去地。如事别自以,闻阳近高酒。[2020-11-06 02:12:17,613] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 西陆蝉声唱,日衣烟东云。春出不饥家,马白贵风御。[2020-11-06 02:12:17,614] - lstm_model.py [Line:198] - [INFO]-[thread:140348029687616]-[process:31309] - ==================End=====================[2020-11-06 02:13:56,069] - lstm_model.py [Line:194] - [INFO]-[thread:140348029687616]-[process:31309] - ==================Epoch 2112, Loss 7.728175163269043=====================[2020-11-06 02:13:56,946] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 旅泊多年岁,发知期东今。君自舟岁未,应当折君新。[2020-11-06 02:13:57,731] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 吾师师子儿,花其重前相。鸟千人身一,清相无道因。[2020-11-06 02:13:58,532] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 和吹度穹旻,此外更高可。来闻人成独,故去深看春。[2020-11-06 02:13:59,317] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 下直遇春日,独与时相飞。江君贤犹名,清清曲河人。[2020-11-06 02:14:00,089] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 月暗竹亭幽,碧昏时尽黄。园春歌雪光,云落分白草。[2020-11-06 02:14:00,861] - lstm_model.py [Line:197] - [INFO]-[thread:140348029687616]-[process:31309] - 睢阳陷虏日,远平然多岩。公水三共朝,月看同出人。[2020-11-06 02:14:00,861] - lstm_model.py [Line:198] - [INFO]-[thread:140348029687616]-[process:31309] - ==================End=====================[2020-11-06 02:15:22,836] - lstm_model.py [Line:148] - [DEBUG]-[thread:140348029687616]-[process:31309] - end training
