@vivounicorn
2021-07-27T09:35:21.000000Z
字数 32052
阅读 5277
机器学习与人工智能技术分享-第四章 最优化原理
机器学习 最优化 第四章
回到目录


4. 最优化原理
4.1 泰勒定理
满足一定条件的函数可以通过泰勒展开式对其做近似:
4.1.1 泰勒展开式
泰勒展开式原理如下,主要采用分部积分推导:
4.1.2 泰勒中值定理
需要注意泰勒中值定理是一个严格的等式:
4.2 梯度下降法
4.2.1 基本原理
梯度下降是一种简单、好用、经典的使用一阶信息的最优化方法(意味着相对低廉的计算成本),其基本原理可以想象为一个下山问题,当下降方向与梯度方向一致时,目标函数的方向导数最大,即此时目标函数在当前起点位置的下降速度最快。
1、一个小例子
假设有单变量实值函数,其图形如下:

在自变量x发生微小变化时,目标函数值的变化可以这么描述:
针对上图有以下三种情况:
(1)、点位置,此时,在 点做微小正向变化:,显然有,这说明在点往轴正向有可以使目标函数值增大点存在;
(2)、点位置,此时,在 点做微小负向变化:,显然有,这说明在点往轴负向有可以使目标函数值增大点存在;
(3)、点位置,此时,不管在 点做微小负向变化还是正向变化都有,这说明在点是一个最优解。
实际上,在一维情况下目标函数的梯度就是,它表明了目标函数值变化方向。
2、梯度与方向导数
方向导数
以二元函数:为例,设它在点的某个邻域内有定义,以点出发引射线l,为上的且在邻域内的任意点,则方向导数的定义为:
其中表示和两点之间的欧氏距离:
从这个式子可以看到:方向导数与某个方向有联系、方向导数是个极限值、方向导数与偏导数似乎有联系。
实际上,如果在点可微,则:
其中和分别是两个维度上的方向角
这里需要注意的一个细节是:沿某个维度的方向导数存在时,其偏导数不一定存在,原因就是方向导数只要求半边极限存在(),而偏导数则要求双边都存在。梯度
把方向导数变换一下形式:
函数在点的梯度就被定义为向量:
与射线l同方向的单位向量被定义为:
于是方向导数变成了:
我的理解是:方向导数描述了由各个维度方向形成的合力方向上函数变化的程度,当这个合力方向与梯度向量的方向相同时,函数变化的最剧烈,我想这就是为什么在梯度上升算法或者梯度下降算法中选择梯度方向或者负梯度方向的原因吧。换句话说就是:函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。

某个函数和它的等高线,图中标出了a点的梯度上升方向
3、多维无约束问题
将开篇的那个小例子扩展到多维的情况,目标函数值将会成为一个向量,向任意个维度方向做微小变动都将对目标函数值产生影响,假设有n个维度,可以用下面的式子描述:
令
(1)、当,此时,因此可以从点移动使得目标函数值增加;
(2)、当,此时,因此可以从点移动使得目标函数值减少;
(3)、当 ,梯度向量和正交(任一向量为0也视为正交),不管从点怎样移动都找不到使目标函数值发生变化的点,于是x点就是目标函数的最优解。
由于可以是任意方向向量,只要点x的梯度向量不为零,从点x出发总可以找到一个变化方向使得目标函数值向我们希望的方向变化(比如就找梯度方向,此时能引起目标函数值最剧烈地变化),理论上当最优解出现时就一定有(实际上允许以某个误差结束),比如,对于梯度下降算法,当时迭代结束,此时的为最优解(可能是全局最优解也可能是局部最优解)
总结来说,基于梯度的优化算法通常有两个核心元素:搜索方向和搜索步长,并且一般都会和泰勒定理有某种联系,从泰勒中值定理可以得到下面的等式:
抽象出迭代框架如下:
4.2.2 拉格朗日乘数法和KKT条件
假设目标函数和约束在某点可微,用符号代替符号。
1、等式约束

在约束条件的作用下,与点(它是个向量)可移动方向相关的向量就不像无约束问题那样随便往哪个方向都能移动了,此时只能沿着约束曲线移动,例如,在、处,和不正交,说明还有使目标函数值更小的等高线存在,所以点还有移动的余地,当移动到位置时和正交,得到最优解。那么在最优解处和约束有什么关系呢?因为此时,,显然此时有(其中是常数),也就是说约束的梯度向量与目标函数的梯度向量在最优解处一定平行。
想到求解此类优化问题时最常用的方法——拉格朗日乘数法,先要构造拉格朗日函数:
其中,是常数
为什么求解拉格朗日函数得到的最优解就是原问题的最优解呢?
假设、为的最优解,那么就需要满足:
第一个式子印证了约束的梯度向量与目标函数的梯度向量在最优解处一定平行,第二个式子就是等式约束本身。
于是:
2、不等式约束
实际情况中,约束条件可能是等式约束也可能是不等式约束或者同时包含这两种约束,下面描述为更一般地情况:
依然使用拉格朗日乘数法,构造拉格朗日函数:
在这里不得不说一下Fritz John 定理了,整个证明就不写了(用局部极小必要条件定理、Gordan 引理可以证明)。
定理1:
依然假设为上述问题的极小值点,问题中涉及到的各个函数一阶偏导都存在,则存在不全为零的\lambda _i使得下组条件成立:
这个定理第一项的形式类似于条件极值必要条件的形式,如果则有效约束 会出现正线性相关,由Gordan 引理知道此时将存在可行方向,就是将不是原问题的极值点,因此令 则线性无关则 。
这个条件又叫互不松弛条件(Complementary Slackness),SVM里的支持向量就是从这个条件得来的。
由Fritz John 定理可知 线性无关则 ,让每一个拉格朗日乘子除以,即,得到下面这组原问题在点处取得极小值一阶必要条件。
定理2:
假设为上述问题的极小值点,问题中涉及到的各个函数一阶偏导都存在,有效约束 线性无关,则下组条件成立:
这组条件就是Karush-Kuhn-Tucker条件,满足KKT条件的点就是KKT点,需要注意的是KKT条件是必要条件(当然在某些情况下会升级为充要条件,比如凸优化问题)。
由此也可以想到求解SVM最大分类间隔器时,不管是解决原问题还是解决对偶问题,不管是用SMO方法或其它方法,优化的过程就是找到并优化违反KKT条件的最合适的乘子。
KKT条件与对偶理论有密切的关系,依然是解决下面这个问题:
构造拉格朗日函数:
令,原问题可以表示为下面这个形式:
这个式子比较容易理解,当x违反原问题约束条件时有:
于是原问题等价为下面这个问题:
它的最优解记为
令,则有以下形式:
它的最优解记为
上面这两个形式很像,区别只在于和的顺序,实际上和互为对偶问题。因为,打个不太恰当的比喻,这就像瘦死的骆驼比马大,具体的证明就不写了,所以,这个就是弱对偶性,此时存在对偶间隙,它被定义为:。
有弱对偶性就有强对偶性,它指的是在某些条件下有,比如在以下条件下满足强对偶性:
目标函数和所有不等式约束函数是凸函数,等式约束函数是仿射函数(形如),且所有不等式约束都是严格的约束(大于或小于)。
KKT条件和强对偶性的关系是:
KKT条件是强对偶性成立的必要条件,特别的,当原问题是凸优化问题时,KKT条件就是充要条件,强对偶性存在时KKT点既是原问题的解也是对偶问题的解,这个时候对偶间隙为0。
4.2.3 批量梯度下降
按照上面等式,每次迭代,为计算梯度值都需要把所有样本扫描一遍,收敛曲线类似下图:

它的优点如下:
- 模型学习与收敛过程通常是平滑的和稳定的;
- 关于收敛条件有成熟完备的理论;
- 针对它有不少利用二阶信息加速收敛的技术,例如conjugate gradient;
- 对样本噪声点相对不敏感。
它的缺点如下:
- 收敛速度慢;
- 对初始点敏感;
- 数据集的变化无法被学习到; captured.
- 不太适用于大规模数据。
4.2.4 随机梯度下降
完全随机梯度下降(Stochastic Gradient Descent,可以想想这里为什么用Stochastic而不用Random?)每次选择一个样本更新权重,这样会带来一些噪声,但可能得到更好的解,试想很多问题都有大量局部最优解,传统批量梯度下降由于每次收集所有样后更新梯度值,当初始点确定后基本会落入到离它最近的洼地,而随机梯度下降由于噪声的引入会使它有高概率跳出当前洼地,选择变多从而可能找到更好的洼地。
收敛曲线类似下图:

完全随机梯度下降和批量梯度下降的优缺点几乎可以互换:
- SGD的收敛速度更快;
- SGD相对来说对初始点不敏感,容易找到更优方案;
- SGD相对适合于大规模训练数据;
- SGD能够捕捉到样本数据的变化;
- 噪声样本可能导致权重波动从而造成无法收敛到局部最优解,步长的设计对其非常重要。
实践当中,很多样本都有类似的模式,所以SGD可以使用较少的抽样样本学习得到局部最优解,当然完全的批量学习和完全的随机学习都太极端,所以往往采用对两者的折中。
4.2.5 小批量梯度下降
小批量梯度下降(Mini-batch Gradient Descent)是对SGD和BGD的折中,采用相对小的样本集学习,样本集大小随着学习过程保持或逐步加大,这样既能有随机带来的好处,又能使用二阶优化信息加速收敛,目前主流机器学习工具几乎都支持小批量学习。
小批量学习收敛过程如下:

梯度下降的另外一个任务是寻找合适的学习率,关于它有很多方法,介绍如下:
4.2.6 牛顿法
从泰勒展开式可以得到带最优步长的迭代式:
但最优的学习率需要计算hessian矩阵,计算复杂度为,所以这种方法不怎么用。
为方便起见,使用 代替 .
4.2.7 Momentum
SGD的一大缺点是 只和当前样本有关系,如果样本存在噪声则会导致权重波动,一种自然的想法就是即考虑历史梯度又考虑新样本的梯度:
对动量的运行过程说明如下:
- 在初始阶段,历史梯度信息会极大加速学习过程(比如n=2时);
- 当准备穿越函数波谷时,差的学习率会导致权重向相反方向更新,于是学习过程会发生回退,这时有动量项的帮助则有可能越过这个波谷;
- 最后在梯度几乎为0的时候,动量项的存在又可能会使它跳出当前局部最小值,于是可能找到更好的最优值点。
Nesterov accelerated gradient 是对动量法的一种改进,具体做法是:首先在之前的方向上迈一大步(棕色向量),之后计算在该点的梯度(红色向量),然后计算两个向量的和,得到的向量(绿色向量)作为最终优化方向。

4.2.8 AdaGrad
Adagrad同样是基于梯度的方法,对每个参数给一个学习率,因此对于常出现的权重可以给个小的更新,而不常出现的则给予大的更新,于是对于稀疏数据集就很有效,这个方法常用于大规模神经网络,Google的FTRL-Proximal也使用了类似方法,可参见:Google Ad Click Prediction a View from the Trenches和Follow-the-Regularized-Leader and Mirror Descent:
Equivalence Theorems and L1 Regularization。
这个方法有点像L2正则,其运作原理如下:
- 在学习前期,梯度比较小regularizer比较大,所以梯度会被放大;
- 在学习后期,梯度比较大regularizer比较小,所以梯度会被缩小。
但它的缺点是,当初始权重过大或经过几轮训练后会导致正则化太小,所以训练将被提前终止。
4.2.9 AdaDelta
Adadelta是对Adagrad的改进,解决了以下短板:
- 经过几轮的训练会导致正则化太小;
- 需要设置一个全局学习率;
- 当我们更新,等式左边和右边的单位不一致。
对于第一个短板,设置一个窗口,仅使用最近几轮的梯度值去更新正则项但计算 太复杂,所以使用类似动量法的策略:
对其他短板,AdaDelta通过以下方法解决。
对SGD与Momentum(里面的注释是理解这个变换的关键):
对牛顿法:
所以二阶方法有正确的单位且快于一阶方法。
来源于Becker 和 LeCuns' 的hessian估计法:
完整的算法描述如下:

对以上算法的比较如下:
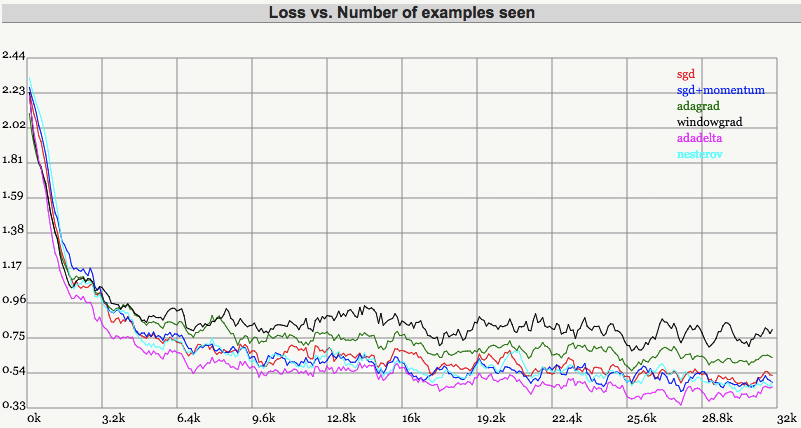

From SGD optimization on loss surface contours
4.2.10 Adam
Adam是对Adadelta的改进,原理如下:
算法伪代码如下:

4.3 并行SGD
SGD相对简单并且被证明有较好的收敛性质和精度,所以自然而然就想到将其扩展到大规模数据集上,就像Hadoop/Spark的基本框架是MapReduce,并行机器学习的常见框架有两种: AllReduce 和 Parameter Server(PS)。
4.3.1 AllReduce
AllReduce的思想来源于MPI,它可以被看做Reduce操作+Broadcast操作,例如:
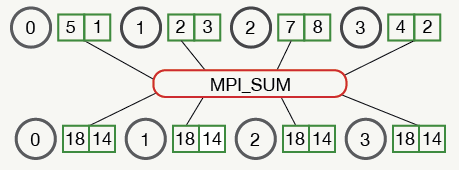
其他AllReduce的拓扑结构如下:

非常好的开源实现有John Langford的vowpal wabbit和陈天奇的Rabit(轻量级、可容错)。并行计算的关键之一是如何在大规模数据集下计算目标函数的梯度值,AllReduce框架很适合这种任务,比如:vw通过构建一个二叉树来管理机器节点,其中一个节点会被当做master,其他节点作为slave,master管理着slave并定期接受它们的心跳,每个子节点的计算结果会被其父节点收集,到达根节点后累加并广播到其所有子节点,一个简单的例子如下:
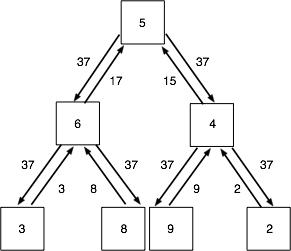
使用mini-batch的并行SGD算法伪代码如下:
4.3.2 参数服务器(Parameter Server)
参数服务器强调模型训练时参数的并行异步更新,最早是由Google的Jeffrey Dean团队提出,为了解决深度学习的参数学习问题,其基本思想是:将数据集划分为若干子数据集,每个子数据集所在的节点都运行着一个模型的副本,通过独立 部署的参数服务器组织模型的所有权重,其基本操作有:Fatching:每隔n次迭代,从参数服务器获取参数权重,Pushing:每隔m次迭代,向参数服务器推送本地梯度更新值,之后参数服务器会更新相关参数权重,其基本架构如下:
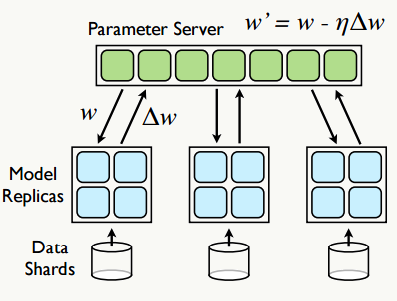
每个模型的副本都是,为减少通信开销,每个模型副本在迭代次后向参数服务器请求参数跟新,反过来本地模型每迭代次后向参数服务器推送一次梯度更新值,当然,为了折中速度和效果,梯度的更新可以选择异步也可以是同。
参数服务器是一个非常好的机器学习框架,尤其在深度学习的应用场景中,有篇不错的文章: 参数服务器——分布式机器学习的新杀器。开源的实现中比较好的是bosen项目和李沐的ps-lite(现已集成到DMLC项目中)。
下面是一个Go语言实现的多线程版本的参数服务器(用于Ftrl算法的优化),源码位置:Goline:
// data structure of ftrl solver.type FtrlSolver struct {Alpha float64 `json:"Alpha"`Beta float64 `json:"Beta"`L1 float64 `json:"L1"`L2 float64 `json:"L2"`Featnum int `json:"Featnum"`Dropout float64 `json:"Dropout"`N []float64 `json:"N"`Z []float64 `json:"Z"`Weights util.Pvector `json:"Weights"`Init bool `json:"Init"`}// data structure of parameter server.type FtrlParamServer struct {FtrlSolverParamGroupNum intLockSlots []sync.Mutexlog log4go.Logger}// fetch parameter group for update n and z value.func (fps *FtrlParamServer) FetchParamGroup(n []float64, z []float64, group int) error {if !fps.FtrlSolver.Init {fps.log.Error("[FtrlParamServer-FetchParamGroup] Initialize fast ftrl solver error.")return errors.New("[FtrlParamServer-FetchParamGroup] Initialize fast ftrl solver error.")}var start int = group * ParamGroupSizevar end int = util.MinInt((group+1)*ParamGroupSize, fps.FtrlSolver.Featnum)fps.LockSlots[group].Lock()for i := start; i < end; i++ {n[i] = fps.FtrlSolver.N[i]z[i] = fps.FtrlSolver.Z[i]}fps.LockSlots[group].Unlock()return nil}// fetch parameter from server.func (fps *FtrlParamServer) FetchParam(n []float64, z []float64) error {if !fps.FtrlSolver.Init {fps.log.Error("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.")return errors.New("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.")}for i := 0; i < fps.ParamGroupNum; i++ {err := fps.FetchParamGroup(n, z, i)if err != nil {fps.log.Error(fmt.Sprintf("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.", err.Error()))return errors.New(fmt.Sprintf("[FtrlParamServer-FetchParam] Initialize fast ftrl solver error.", err.Error()))}}return nil}// push parameter group for upload n and z value.func (fps *FtrlParamServer) PushParamGroup(n []float64, z []float64, group int) error {if !fps.FtrlSolver.Init {fps.log.Error("[FtrlParamServer-PushParamGroup] Initialize fast ftrl solver error.")return errors.New("[FtrlParamServer-PushParamGroup] Initialize fast ftrl solver error.")}var start int = group * ParamGroupSizevar end int = util.MinInt((group+1)*ParamGroupSize, fps.FtrlSolver.Featnum)fps.LockSlots[group].Lock()for i := start; i < end; i++ {fps.FtrlSolver.N[i] += n[i]fps.FtrlSolver.Z[i] += z[i]n[i] = 0z[i] = 0}fps.LockSlots[group].Unlock()return nil}// push weight update to parameter server.func (fw *FtrlWorker) PushParam(param_server *FtrlParamServer) error {if !fw.FtrlSolver.Init {fw.log.Error("[FtrlWorker-PushParam] Initialize fast ftrl solver error.")return errors.New("[FtrlWorker-PushParam] Initialize fast ftrl solver error.")}for i := 0; i < fw.ParamGroupNum; i++ {err := param_server.PushParamGroup(fw.NUpdate, fw.ZUpdate, i)if err != nil {fw.log.Error(fmt.Sprintf("[FtrlWorker-PushParam] Initialize fast ftrl solver error.", err.Error()))return errors.New(fmt.Sprintf("[FtrlWorker-PushParam] Initialize fast ftrl solver error.", err.Error()))}}return nil}// to do update for all weights.func (fw *FtrlWorker) Update(x util.Pvector,y float64,param_server *FtrlParamServer) float64 {if !fw.FtrlSolver.Init {return 0.}var weights util.Pvector = make(util.Pvector, fw.FtrlSolver.Featnum)var gradients []float64 = make([]float64, fw.FtrlSolver.Featnum)var wTx float64 = 0.for i := 0; i < len(x); i++ {item := x[i]if util.UtilGreater(fw.FtrlSolver.Dropout, 0.0) {rand_prob := util.UniformDistribution()if rand_prob < fw.FtrlSolver.Dropout {continue}}var idx int = item.Indexif idx >= fw.FtrlSolver.Featnum {continue}var val float64 = fw.FtrlSolver.GetWeight(idx)weights = append(weights, util.Pair{idx, val})gradients = append(gradients, item.Value)wTx += val * item.Value}var pred float64 = util.Sigmoid(wTx)var grad float64 = pred - yutil.VectorMultiplies(gradients, grad)for k := 0; k < len(weights); k++ {var i int = weights[k].Indexvar g int = i / ParamGroupSizeif fw.ParamGroupStep[g]%fw.FetchStep == 0 {param_server.FetchParamGroup(fw.FtrlSolver.N,fw.FtrlSolver.Z,g)}var w_i float64 = weights[k].Valuevar grad_i float64 = gradients[k]var sigma float64 = (math.Sqrt(fw.FtrlSolver.N[i]+grad_i*grad_i) - math.Sqrt(fw.FtrlSolver.N[i])) / fw.FtrlSolver.Alphafw.FtrlSolver.Z[i] += grad_i - sigma*w_ifw.FtrlSolver.N[i] += grad_i * grad_ifw.ZUpdate[i] += grad_i - sigma*w_ifw.NUpdate[i] += grad_i * grad_iif fw.ParamGroupStep[g]%fw.PushStep == 0 {param_server.PushParamGroup(fw.NUpdate, fw.ZUpdate, g)}fw.ParamGroupStep[g] += 1}return pred}
4.4 二阶优化方法
4.4.1 概览
大部分的优化算法都是基于梯度的迭代方法,其迭代式来源为泰勒展开式,迭代的一般式为:
其中 被称作步长,向量 被称作搜索方向,它一般要求是一个能使目标函数值(最小化问题)下降的方向,即满足:
进一步说, 的通项式有以下形式:
是一个对称非奇异矩阵(大家请问为什么?)。
- 在 Steepest Descent 法中 是一个单位矩阵;
- 在 Newton 法中, 是一个精确的Hessian 矩阵 ;
- 在 Quasi-Newton 法中, 是对Hessian矩阵的估计。
这类优化方法大体分两种,要么是先确定优化方向后确定步长(line search),要么是先确定步长后确定优化方向(trust region)。

以常用的line search为例,如何找到较好的步长 呢?好的步长它需要满足以下条件:
- Armijo 条件
充分下降条件,即要使步长在非精确一维搜索中能保证目标函数 下降,则它需要满足以下不等式:
一般选取一个较小的值,例如:。
Armijo 条件的几何解释如下:

常用求解方法如下:
- Curvature 条件
不只要求步长能使目标函数下降,还要求其程度,这个要求有点严格,一般只要做到Armijo条件就好了,不等式如下:

- Wolfe 条件
步长同时满足Armijo 条件和Curvature 条件则被称为其满足Wolfe 条件。
4.4.2 牛顿法(Newton Method)
- 以点开始寻找的解,在该点做切线,得到新的起点:
- 迭代,直到满足精度条件得到的最优解.
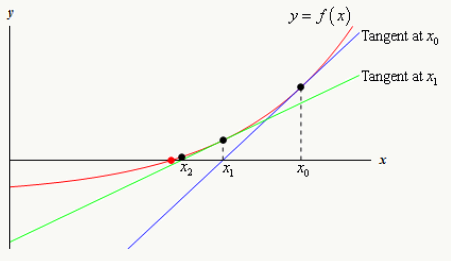
从泰勒展开式得到牛顿法的基本迭代式:
对牛顿法的改进之一是使用自适应步长 :

但总的来说牛顿法由于需要求解Hessian 矩阵,所以计算代价过大,对问题规模较大的优化问题力不从心。
4.4.3 拟牛顿法(Quasi-Newton Method)
为解决Hessian 矩阵计算代价的问题,想到通过一阶信息去估计它的办法,于是涌现出一类方法,其中最有代表性的是DFP和BFGS(L-BFGS),其原理如下:
一些有用的资料:
- 最优化相关书籍首推:《Numerical Optimization 2nd ed (Jorge Nocedal, Stephen J.Wright)》
- vw源码:vowpal_wabbit
- John Langford的博客
思考一个问题:为什么通常二阶优化方法收敛速度快于一阶方法?

4.5 OWL-QN算法
4.5.1 BFGS算法回顾
算法思想如下:
Step1: 取初始点 ,初始正定矩阵,允许误差,令;
Step2: 计算;
Step3: 计算,使得 ;
Step4: 令;
Step5: 如果,则取为近似最优解;否则转下一步;
Step6: 计算
令,转Step2.
优点:
1、不用直接计算Hessian矩阵;
2、通过迭代的方式用一个近似矩阵代替Hessian矩阵的逆矩阵。
缺点:
1、矩阵存储量为,因此维度很大时内存不可接受;
2、矩阵非稀疏会导致训练速度慢。
4.5.2 L-BFGS算法
针对BFGS的缺点,主要在于如何合理的估计出一个Hessian矩阵的逆矩阵,L-BFGS的基本思想是只保存最近的m次迭代信息,从而大大降低数据存储空间。对照BFGS,我重新整理一下用到的公式:
于是估计的Hessian矩阵逆矩阵如下:
把
带入上式,得:
假设当前迭代为,只保存最近的次迭代信息,(即:从),依次带入,得到:
公式1:
算法第二步表明了上面推导的最终目的:找到第k次迭代的可行方向,满足:
为了求可行方向,有下面的:
two-loop recursion算法:
该算法的正确性推导:
1、令:
,递归带入:
相应的:
2、令:
于是:
这个two-loop recursion算法的结果和公式1*初始梯度的形式完全一样,这么做的好处是:
1、只需要存储;
2、计算可行方向的时间复杂度从降低到了,当远小于时为线性复杂度。
总结L-BFGS算法的步骤如下:
Step1:选初始点,允许误差,存储最近迭代次数(一般取6);
Step2:;
Step3:如果 则返回最优解,否则转Step4;
Step4:计算本次迭代的可行方向:;
Step5: 计算步长,对下面式子进行一维搜索:
Step6:更新权重:
Step7: 如果 只保留最近m次的向量对,需删除();
Step8:计算并保存:
Step9:用two-loop recursion算法求得:
,转Step3。
需要注意的地方,每次迭代都需要一个 ,实践当中被证明比较有效的取法为:
4.5.3 OWL-QN算法原理
1、问题描述
对于类似于Logistic Regression这样的Log-Linear模型,一般可以归结为最小化下面这个问题:
其中,第一项为loss function,用来衡量当训练出现偏差时的损失,可以是任意可微凸函数(如果是非凸函数该算法只保证找到局部最优解),后者为regularization term,用来对模型空间进行限制,从而得到一个更“简单”的模型。
根据对模型参数所服从的概率分布的假设的不同,regularization term一般有:L2-norm(模型参数服从Gaussian分布);L1-norm(模型参数服从Laplace分布);以及其他分布或组合形式。
L2-norm的形式类似于:
L1-norm的形式类似于:
L1-norm和L2-norm之间的一个最大区别在于前者可以产生稀疏解,这使它同时具有了特征选择的能力,此外,稀疏的特征权重更具有解释意义。
对于损失函数的选取就不在赘述,看两幅图:

图1 - 红色为Laplace Prior,黑色为Gaussian Prior

图2 直观解释稀疏性的产生
对LR模型来说损失函数选取凸函数,那么L2-norm的形式也是的凸函数,根据最优化理论,最优解满足KKT条件,即有:
,但是L1-norm的regularization term显然不可微,怎么办呢?
2、Orthant-Wise Limited-memory Quasi-Newton
OWL-QN主要是针对L1-norm不可微提出的,它是基于这样一个事实:任意给定一个维度象限,L1-norm 都是可微的,因为此时它是一个线性函数:

图3 任意给定一个象限后的L1-norm
OWL-QN中使用了次梯度决定搜索方向,凸函数不一定是光滑而处处可导的,但是它又符合类似梯度下降的性质,在多元函数中把这种梯度叫做次梯度,见维基百科http://en.wikipedia.org/wiki/Subderivative
举个例子:

图4 次导数
对于定义域中的任何,我们总可以作出一条直线,它通过点,并且要么接触f的图像,要么在它的下方。这条直线的斜率称为函数的次导数,推广到多元函数就叫做次梯度。
次导数及次微分:
凸函数在点的次导数,是实数c使得:
对于所有I内的x。可以证明,在点x0的次导数的集合是一个非空闭区间[a, b],其中a和b是单侧极限
它们一定存在,且满足。所有次导数的集合称为函数在的次微分。
OWL-QN和传统L-BFGS的不同之处在于:
利用次梯度的概念推广了梯度
定义了一个符合上述原则的虚梯度,求一维搜索的可行方向时用虚梯度来代替L-BFGS中的梯度:
怎么理解这个虚梯度呢?见下图:
对于非光滑凸函数,那么有这么几种情况:

图5

图6

图7 otherwise
一维搜索要求不跨越象限
要求更新前权重与更新后权重同方向:

图8 OWL-QN的一次迭代
总结OWL-QN的一次迭代过程:
- Find vector of steepest descent
- Choose sectant
- Find L-BFGS quadratic approximation
- Jump to minimum
- Project back onto sectant
- Update Hessian approximation using gradient of loss alone
最后OWL-QN算法框架如下:

与L-BFGS相比,第一步用虚梯度代替梯度,第二、三步要求一维搜索不跨象限,也就是迭代前的点与迭代后的点处于同一象限,第四步要求估计Hessian矩阵时依然使用loss function的梯度(因为L1-norm的存在与否不影响Hessian矩阵的估计)。
References
如有遗漏请提醒我补充:
1、《Understanding the Bias-Variance Tradeoff》
http://scott.fortmann-roe.com/docs/BiasVariance.html
2、《Boosting Algorithms as Gradient Descent in Function Space》
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.51.6893&rep=rep1&type=pdf
3、《Optimal Action Extraction for Random Forests and
Boosted Trees》
http://www.cse.wustl.edu/~ychen/public/OAE.pdf
4、《Applying Neural Network Ensemble Concepts for Modelling Project Success》
http://www.iaarc.org/publications/fulltext/Applying_Neural_Network_Ensemble_Concepts_for_Modelling_Project_Success.pdf
5、《Introduction to Boosted Trees》
https://homes.cs.washington.edu/~tqchen/data/pdf/BoostedTree.pdf
6、《Machine Learning:Perceptrons》
http://ml.informatik.uni-freiburg.de/_media/documents/teaching/ss09/ml/perceptrons.pdf
7、《An overview of gradient descent optimization algorithms》
http://sebastianruder.com/optimizing-gradient-descent/
8、《Ad Click Prediction: a View from the Trenches》
https://www.eecs.tufts.edu/~dsculley/papers/ad-click-prediction.pdf
9、《ADADELTA: AN ADAPTIVE LEARNING RATE METHOD》
http://www.matthewzeiler.com/pubs/googleTR2012/googleTR2012.pdf
9、《Improving the Convergence of Back-Propagation Learning with Second Order Methods》
http://yann.lecun.com/exdb/publis/pdf/becker-lecun-89.pdf
10、《ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION》
https://arxiv.org/pdf/1412.6980v8.pdf
11、《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》
http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf
11、《Sparse Allreduce: Efficient Scalable Communication for Power-Law Data》
https://arxiv.org/pdf/1312.3020.pdf
12、《Asynchronous Parallel Stochastic Gradient Descent》
https://arxiv.org/pdf/1505.04956v5.pdf
13、《Large Scale Distributed Deep Networks》
https://papers.nips.cc/paper/4687-large-scale-distributed-deep-networks.pdf
14、《Introduction to Optimization —— Second Order Optimization Methods》
https://ipvs.informatik.uni-stuttgart.de/mlr/marc/teaching/13-Optimization/04-secondOrderOpt.pdf
15、《On the complexity of steepest descent, Newton’s and regularized Newton’s methods for nonconvex unconstrained optimization》
http://www.maths.ed.ac.uk/ERGO/pubs/ERGO-09-013.pdf
16、《On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes 》
http://papers.nips.cc/paper/2020-on-discriminative-vs-generative-classifiers-a-comparison-of-logistic-regression-and-naive-bayes.pdf
17、《Parametric vs Nonparametric Models》
http://mlss.tuebingen.mpg.de/2015/slides/ghahramani/gp-neural-nets15.pdf
18、《XGBoost: A Scalable Tree Boosting System》
https://arxiv.org/abs/1603.02754
19、一个可视化CNN的网站
http://shixialiu.com/publications/cnnvis/demo/
20、《Computer vision: LeNet-5, AlexNet, VGG-19, GoogLeNet》
http://euler.stat.yale.edu/~tba3/stat665/lectures/lec18/notebook18.html
21、François Chollet在Quora上的专题问答:
https://www.quora.com/session/Fran%C3%A7ois-Chollet/1
22、《将Keras作为tensorflow的精简接口》
https://keras-cn.readthedocs.io/en/latest/blog/keras_and_tensorflow/
23、《Upsampling and Image Segmentation with Tensorflow and TF-Slim》
https://warmspringwinds.github.io/tensorflow/tf-slim/2016/11/22/upsampling-and-image-segmentation-with-tensorflow-and-tf-slim/
