@tony-yin
2019-05-04T16:36:52.000000Z
字数 4637
阅读 3639
利用软 RAID 实现系统盘高可用
HA RAID

一套完善的系统理论上是不应该存在任何的单点故障,但是系统盘往往被人所忽略,而系统盘又恰恰是最重要的一个点。本文主要讲解如何利用软RAID实现系统盘高可用,并且实现自动换盘、自动告警和自动恢复。
系统盘组成
所有挂载点全部采用RAID1方式保证数据冗余,即使其中一块盘损坏,也不会影响操作系统的正常运行,只需要替换一块新盘,即可重新进行数据同步。
| Mount point | Raid | 容量 |
|---|---|---|
| / | Raid1 | 100 GB |
| /boot | Raid1 | 512 MB |
| /boot/efi | Raid1 | 200 MB |
| swap | Raid1 | 50 GB |
| /var/log | Raid1 | 50 GB |
系统盘软 RAID 配置
进入引导页面,选择UEFI安装方式,因为传统的BIOS方式在容量和分区上都存在限制,具体请阅读【聊聊 BIOS、UEFI、MBR、GPT、GRUB……】。
配置软raid阶段,UEFI存在一个ESP(EFI system partition), 即/boot/efi分区,RAID等级设置为raid1。
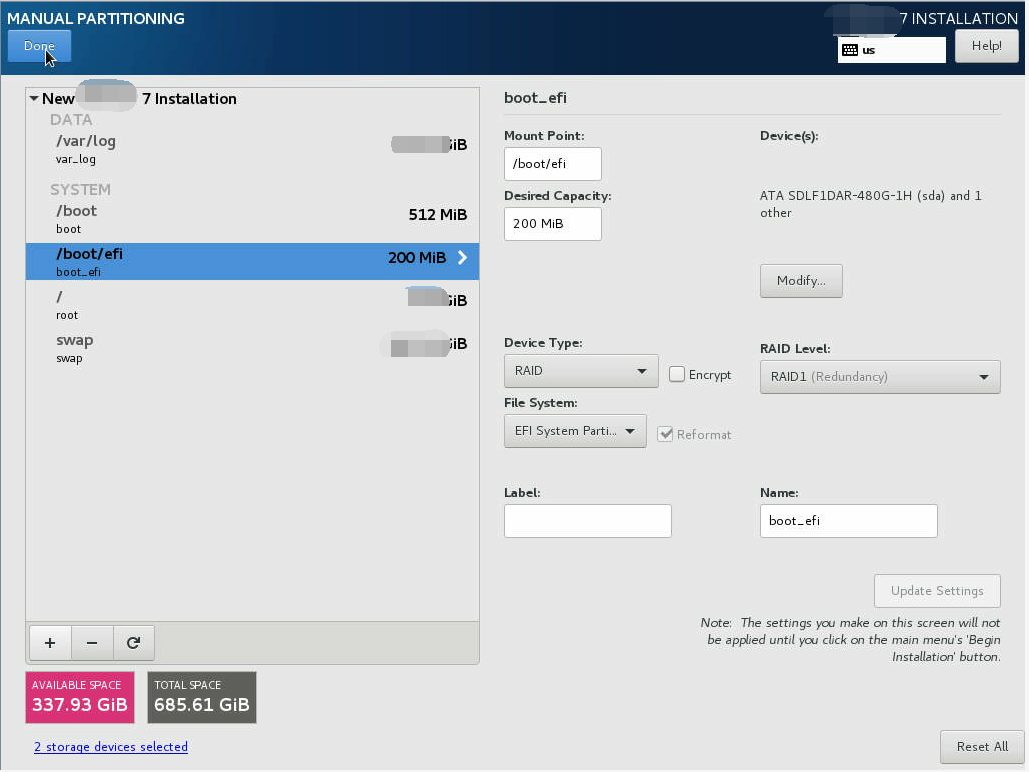
其他的挂载点也都选择RAID1即可。
sda 8:0 0 447.1G 0 disk├─sda4 8:4 0 201M 0 part│ └─md123 9:123 0 201M 0 raid1 /boot/efi├─sda2 8:2 0 50.1G 0 part│ └─md127 9:127 0 50.1G 0 raid1 [SWAP]├─sda5 8:5 0 50G 0 part│ └─md124 9:124 0 50G 0 raid1 /var/log├─sda3 8:3 0 513M 0 part│ └─md126 9:126 0 512.4M 0 raid1 /boot├─sda1 8:1 0 100.1G 0 part└─md125 9:125 0 100G 0 raid1 /sdb 8:0 0 447.1G 0 disk├─sdb4 8:4 0 201M 0 part│ └─md123 9:123 0 201M 0 raid1 /boot/efi├─sdb2 8:2 0 50.1G 0 part│ └─md127 9:127 0 50.1G 0 raid1 [SWAP]├─sdb5 8:5 0 50G 0 part│ └─md124 9:124 0 50G 0 raid1 /var/log├─sdb3 8:3 0 513M 0 part│ └─md126 9:126 0 512.4M 0 raid1 /boot├─sdb1 8:1 0 100.1G 0 part└─md125 9:125 0 100G 0 raid1 /
换盘流程
以系统盘为sda和sdb,并且sdb为更换的硬盘为例。
拔盘 & 插盘
因为所有挂载点都是RAID1,软RAID中拥有数据冗余的阵列是允许其中一块盘丢失的,所以不会存在磁盘占用的问题,进而不会导致磁盘乱序的问题。所以可以直接热插拔换盘。
克隆磁盘分区表信息
新插入的sdb理论上是没有分区的,需要将sda上面的分区完完全全的克隆过来。gpt磁盘分区表的磁盘应该采用parted或sgdisk工具。
# 将sda的分区信息克隆到sdb上sgdisk -R /dev/sdb /dev/sdasleep 5
最好sleep几秒,因为它克隆后底层同步工作并没有立即完成。
生成新的GUID
克隆分区信息后,为sdb生成新的GUID,否则会因为克隆分区表导致sdb和sda的GUID一样。
sgdisk -G /dev/sdb
内核重新加载分区表
partprobe /dev/sdb
复制引导程序
注意:
这一步非常关键,可以说这是所有流程中最关键并且最容易忽略的一个步骤。因为软RAID数据冗余,并不会对操作系统引导程序有效,即RAID1不会对BIOS中的MBR做冗余,也不会对UEFI中的ESP分区做冗余。这里说的不冗余是指软RAID不会对其做数据冗余,需要另外做冗余。
如果引导方式是传统的bios,则需要复制MBR,即硬盘的前512字节。
[root@ ~]# dd if=/dev/sda of=/dev/sdb bs=512 count=1
需要注意的是,我们这里采用了UEFI的引导方式,跟BIOS是完全不一样的,所以如果同样拷贝硬盘的前512字节是不会生效的。UEFI的引导程序在ESP中,需要复制整个ESP分区。
[root@ ~]# dd if=/dev/sda of=/dev/sdb
你以为这就结束了吗?
UEFI引导方式仅仅复制ESP分区还不够,还需要将系统盘添加到启动项中。因为当一块磁盘拔了再插上后,原先这块盘就会从启动项中移除,插盘后需要将新盘再添加到启动项中。
[root@ ~]# efibootmgr -c -g -d /dev/sdb -p 1 -L "Centos #2" -l '\EFI\centos\grubx64.efi'
想对efibootmgr有更深入了解,可以阅读:
数据同步
将替换的磁盘的分区对应加入RAID1中,这样就可以将sda中的数据同步至sdb中,同步完成后,所有阵列又将拥有数据冗余的效果。
[root@ ~]# mdadm /dev/md123 -a /dev/sdb4[root@ ~]# mdadm /dev/md124 -a /dev/sdb5[root@ ~]# mdadm /dev/md125 -a /dev/sdb1[root@ ~]# mdadm /dev/md126 -a /dev/sdb3[root@ ~]# mdadm /dev/md127 -a /dev/sdb2
同步配置文件
每次修改软RAID后,都要实时更新配置文件,方便查看RAID配置或利用配置文件重新组装阵列。
[root@ ~]# mdadm -Ds > /etc/mdadm.conf
获取进度值
通过查看/proc/mdstat查看RAID当前信息,如果存在数据同步,会有recovery的字样,并且[1/2]表示还未同步,[_U]表示前面一个设备不是活跃状态,后一个设备为活跃状态。所以recovery同行的进度值并不是整体RAID同步进度值,只是当前的RAID的进度,所有阵列的同步进度值可以通过 Finish Blocks / All Blocks来计算。
[root@ ~]# cat /proc/mdstatPersonalities : [raid0] [raid1]md123 : active raid1 sdb4[1] sda4[0]205760 blocks super 1.0 [1/2] [_U]bitmap: 0/1 pages [0KB], 65536KB chunkmd124 : active raid1 sda5[0] sdb5[1]20971520 blocks super 1.2 [1/2] [_U]bitmap: 1/1 pages [4KB], 65536KB chunkmd125 : active raid1 sda1[0] sdb1[1]83886080 blocks 64K chunks 2 near-copies [1/2] [_U] [=======>........] recovery = 35.6% (29863444/83886080) finish=0.1min speed=93472K/secbitmap: 1/1 pages [4KB], 65536KB chunkmd126 : active raid1 sdb3[1] sda3[0]524736 blocks super 1.2 [1/2] [_U]bitmap: 0/1 pages [0KB], 65536KB chunkmd127 : active raid1 sda2[0] sdb2[1]104923136 blocks super 1.2 [1/2] [_U]bitmap: 1/1 pages [4KB], 65536KB chunkunused devices: <none>
监控 & 告警
要达到对系统盘更好的维护,监控和告警是必不可少的。
磁盘健康告警
可以通过smartctl工具获取磁盘健康状态,不同型号的磁盘获取到的健康信息可能会不一致,如果磁盘状态健康,一般会返回PASSED或OK,如果状态不健康,直接调用邮件接口即可。
[root@ ~]# smartctl -H /dev/sdasmartctl 6.2 2017-02-27 r4394 [x86_64-linux-4.14.78-201.1.el7.x86_64] (local build)Copyright (C) 2002-13, Bruce Allen, Christian Franke, www.smartmontools.org=== START OF READ SMART DATA SECTION ===SMART STATUS RETURN: incomplete response, ATA output registers missingSMART overall-health self-assessment test result: PASSEDWarning: This result is based on an Attribute check.
磁盘拔插告警
通过udev的机制,编写add和remove两个action的rules文件即可监听磁盘拔出或插入的事件,然后调用告警接口即可。
[root@ ~]# cat /etc/udev/rules.d/50-ssd-monitor.rulesKERNEL=="sd[a-z]+$", ACTION=="remove", SUBSYSTEM=="block", RUN+="/usr/bin/python /usr/lib/python2.7/site-packages/disk_watcher/os_disk.py %k pullout"KERNEL=="sd[a-z]+$", ACTION=="add", SUBSYSTEM=="block", RUN+="/usr/bin/python /usr/lib/python2.7/site-packages/disk_watcher/os_disk.py %k insert"
总结
本文主要介绍了如何利用软RAID实现系统盘高可用,在其中一块系统盘损坏后如何换盘并数据同步做了详细描述,同时也对监控告警做了讲解。总体来说,整个流水线基本上覆盖到了,具体细节部分还需多实践。
Refer
- How To Copy a GPT Partition Table to Another Disk using sgdisk
- SuSE的软Raid中一块硬盘坏掉后的修复方法
- How to install Ubuntu 14.04/16.04 64-bit with a dual-boot RAID 1 partition on an UEFI/GPT system?
- mdadm: device or resource busy
- Linux硬盘盘符分配
- UEFI via software RAID with mdadm in Ubuntu 16.04
- What's the difference between creating mdadm array using partitions or the whole disks directly
- XenServer 6.2 with Software RAID
- UEFI boot fails when cloning image to new machine
- How to correctly install GRUB on a soft RAID 1?
- How to boot after RAID failure (software RAID)?
- mdadm raid 1 grub only on sda
- Can the EFI system partition be RAIDed?
- Partitioning EFI machine with two SSD disks in mirror
