@llqintel
2016-11-15T06:55:59.000000Z
字数 1606
阅读 1792
前端代码保护
前端安全 页面信息加密 防止信息抓取
前言
在我们的web系统中,客户端的输入,源码的暴露,便捷的抓包调试工具等都无疑给web系统带来了极高的风险点。但我们期望构建一个较为安全的系统,能够保护把恶意行为控制在一定的范围之类,或者提高恶意行为的成本,从而提高系统的安全性。
信息加密的必要性
恶意请求
web系统安全首要问题就是保证输入数据的安全性。但是由于web的开放特性,前端作为数据采集的最前线,js代码始终暴露在外,在这种情况下,防止恶意伪造请求变得非常困难。尤其是与支付相关的带有密钥或加密规则的代码,如果该代码被窃取,风险更高。
防止竞争对手功能复制
随着前后端分离的逐步推进,业务逻辑在前端代码中体现的细节越来越多。如果被别有用心的竞争对手利用,拷贝业务功能,甚至是运营规则的窃取。比如锤子手机天猫预售乘3事件
如何解决
我们这里的切入点是通过混淆js代码来提高代码识别的成本。
现状
在web系统发展早期,js在web系统中承担的职责并不多,只是简单的提交表单,js文件非常简单,也不需要任何的保护。
随着js文件体积的增大,为了缩小js体积,加快http传输速度,开始出现了很多对js的压缩工具,比如uglify、compressor、clouser。。。它们的工作主要是
· 合并多个js文件
· 去除js代码里面的空格和换行
· 压缩js里面的变量名
· 剔除掉注释
虽然压缩工具出发点都是为了减少js文件的体积,但是压缩替换后的代码已经比源代码可读性差了很多,间接起到了代码保护的作用,于是压缩js文件成为了前端发布的标配之一。但是后来市面上主流浏览器chrome、Firefox等都提供了js格式化的功能,能够很快的把压缩后的js美化,再加上现代浏览器强大的debug功能,单纯压缩过的js代码对于真正怀有恶意的人,已经不能起到很好的防御工作,出现了"防君子不防小人"的尴尬局面,js混淆则可以进一步缓解这个问题。
如何实现js混淆
js混淆器大致有两种:
· 通过正则替换实现的混淆器
· 通过语法树替换实现的混淆器
第一种实现成本低,但是效果也一般,适合对混淆要求不高的场景。第二种实现成本较高,但是更灵活,而且更安全,可以自定义规则。基于语法层面的混淆器其实类似于编译器,基本原理和编译器类似。
编译器工作流程
当我们读入一段字符串文本(source code),词法分析器会把它拆成一个一个小的单位(token),比如数字1 是一个token, 字符串'abc'是一个token等等。接下来语法分析器会把这些单位组成一颗树状结构(AST),这个树状结构就代表了token们的组成关系。比如 1 + 2 就会展示成一棵加法树,左右子节点分别是token - 1 和token - 2 ,中间token表示加法。编译器根据生成的AST转换到中间代码,最终转换成机器代码。
混淆工作流程
我们的目标是什么,是修改原有的js代码结构,在这里面这个结构对应的是什么呢?就是AST。任何一段正确的js代码一定可以组成一颗AST,同样,因为AST表示了各个token的逻辑关系,我们也可以通过AST反过来生成一段js代码。所以,你只需要构造出一颗AST,就能生成任何js代码!
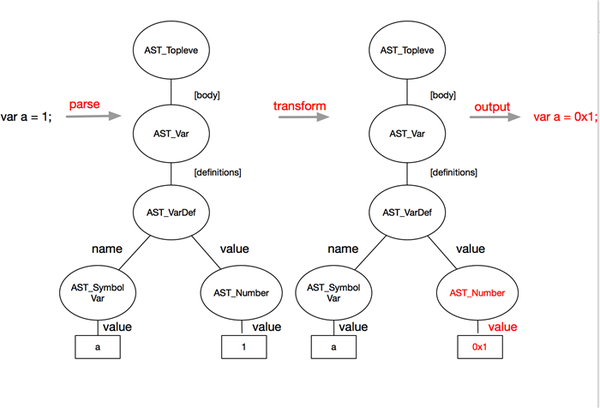
设计自己的规则
比如:
打乱了变量的定义顺序,包括方法的位置
对于大部分赋值语句,使用了函数包裹赋值的方式
在for循环 ,if等条件语句中,加了很多无用的语句
数字变成16进制运算
规则由于是自定义的,不同的版本都可以组合变化,加大了破解的难度。
词法分析和语法分析的实现成本非常大,我们这里借助UglifyJS工具来实现我们的混淆。
测试
因为在混淆过程中我们改变了js代码的结构,所以必须经过严格的测试。jquery,zepto等库有完善的测试用例,可以拿混淆后的代码去跑它们的单元测试,保证和混淆前执行结果完全一样。
集成到前端构建工作流中
集成到gulp,fis的工作流中,对代码统一打包,处理,减少重复的工作量。
