@lijiansheng
2017-06-13T03:28:30.000000Z
字数 2877
阅读 2680
OpenStack Sahara 之基本原理
OpenStack 云计算 开源
介绍
Apache Hadoop 俨然是业界标准,MapReduce 的实现基本上都在采用 Hadoop,也是被各企业越来越多的使用的数据处理框架。Sahara项目的初衷是希望用户能够在OpenStack 云平台下非常容易的部署和管理 Hadoop 及其相关的数据处理框架集群。这里必须要提及的是,亚马逊云服务已经提供的Hadoop 数据处理服务—— Amazon Elastic MapReduce (EMR)好多年了,是AWS营收的主要来源之一。
Sahara 希望通过指定一系列诸如版本、集群拓扑、硬件节点细节等就可以部署Hadoop、Spark、Storm 等集群,用户只需要提供上述这些参数,在几分钟之内就可以搭建好自己的集群,是不是足够的简单、易用。还有,Sahara 还可以在已有的集群按需添加、删除节点。
Sahara 的解决方案可以满足如下几种场景:
- 快速的将数据处理集群部署到OpenStack中,用来做开发和质量保证(QA)。
- 可以充分的利用通用型 OpenStack IaaS 云平台中未利用起来的资源。
- 分析即服务,ad-hoc 或者是 bursty 的分析业务(类似于 AWS 的EMR)。
其中关键的特性有:
- 作为 OpenStack 的一个组件来设计的。
- 可通过REST API来管理,用户界面也集成到了OpenStack仪表盘的一部分。
- 支持多种数据处理框架:
- 多个Hadoop的版本
- Apache Spark和Storm
- Hadoop 安装引擎是可插拔架构
- 整合了供应商的管理工具,比如Apache Ambari、Cloudera Management Console。
- 预先定义的可以修改参数的模版。
细节
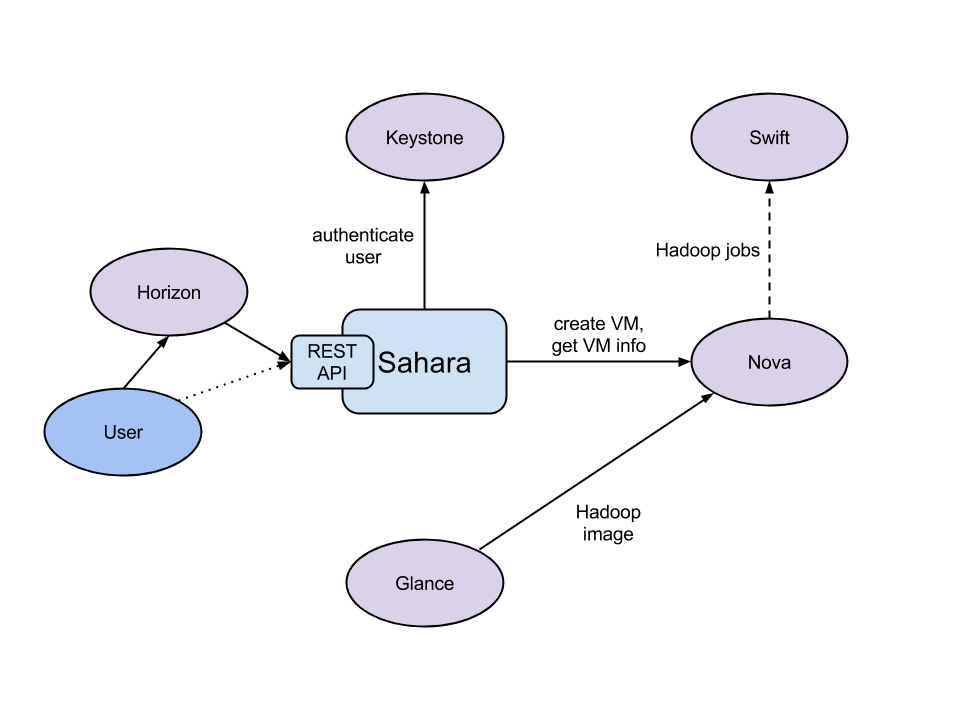
Sahara 组件会和以下OpenStack 的其它组件进行通信:
- 仪表盘(Horizon):提供了图形界面操作,可以配置所有Sahara的参数。
- 认证(keystone):对用户进行身份验证,和OpenStack很好的配合,获得安全令牌,限制用户的权限等。
- 计算(Nova):用于为数据处理集群启动虚拟机。
- 编排(Heat):用于为数据处理集群启动和编排部署。
- 镜像(Glance):存储虚拟机镜像,没个镜像都是预安装了操作系统和数据处理的发型版或者是框架。
- 对象存储(Swift):用来存储任务的脚本,或者是即将处理的数据,或者是分析完成后的结果数据。
- 块存储(Cinder):为虚拟机实例提供块存储。
- 网络(Neturon):为数据处理集群提供网络服务。
- DNS 服务(designate):为集群实例和Hadoop 服务之间提供通过主机名称的互联互通。
- 计量(ceilometer):为了计量和监控的目的所收集的集群使用量。
- 共享文件系统(manila):用来存储任务的脚本,或者是即将处理的数据,或者是分析完成后的结果数据。
工作流程
Sahara 从web 的图形界面和API 实现了对于 Hadoop 的两种场景,分别是集群部署和分析即服务。
我们先来看下集群自动化部署这部分的工作流程,下一节我们探讨分析即服务的流程。
- 首先需要做的是选择一个Hadoop(框架)的版本(开源或商业)。
- 选择一个镜像(是否预先安装了数据处理框架均可)
- 针对已经预先安装了数据处理框架的基本镜像,Sahara会提供供应商特定的工具集,
- 可以从Mirantis网站上下载 http://sahara-files.mirantis.com/images/upstream/
- 定义集群的配置,其中包括集群的规模、拓扑、以及框架的参数(举个例子:heap的大小):
Sahara提供了这个配置参数。 - 部署集群,sahara 会部署虚拟机,以及安装和配置数据处理框架。
- 在集群内部进行添加和删除节点的操作。
- 当集群不再需要的时候,将此集群销毁,并回收资源。
分析即服务,这才是用户最终使用的功能,其流程如下:
- 选择一个原先定义好的数据处理流程的版本。
- 配置任务:
- 选择任务的类型:pig,hive,jar-file,等等
- 提供任务脚本的源或者是jar的具体位置
- 选择数据输入和输出的位置
- 设置集群规模的限制
- 执行任务:
- 所有部署集群的过程和任务执行的过程,对于用户都是透明的。
- 当任务完成后,集群会自动的移除。
- 获得计算的结果(举例来说,存放在了对象存储系统之上)。
用户视角
当通过 Sahara 部署一套数据处理集群时,用户可以操作的是三种类型的条目,此三种类型分别是:节点组模版、集群模版和集群。
节点组模版,是集群内的一组节点的描述,它包含了一组 Hadoop 的处理器,每个处理器将会在此组内启动一台实例。另外,节点组模版还可能为这些处理器提供节点范围,此种类型的模版会封装一些硬件参数(flavor),用于节点的虚拟机,以及运行在此节点上的数据处理框架的配置。
设计集群模版的初衷就是在一个集群内将节点组模版组合起来,一个集群模版会定义节点组会包含什么,以及每个集群将会启动多少台实例。有时,某些数据处理框架的配置是不允许在单台实例中的,但是可以在整个集群来配置。用户可以在集群模版中指定这种类型的配置,Sahara 可让用户在一个集群模版中指定某些数据框架到哪个anti-affinit组中。如果某个处理器是出现在了anti-affinity组中的话,它就意味着运行这些处理器的虚拟机实例需启动到不同硬件上。
集群表示的是一组虚拟机实例所安装是同样的数据处理框架。它的主要特点是由一个虚拟机镜像生成的,而这些镜像是预安装了数据处理框架的,用户可以选择一个预先定义好的集群模版来启动集群。当然,在集群启动之后,用户若想访问虚拟机实例的话,是需要指定的密钥对的。
Sahara 还在集群框架拓扑上提供了很多的约束,用户可以在对应的插件文档中查阅相应的约束。
每个集群都属于一个由用户决定的认证服务项目。用户所能访问的他在此项目下能够访问的对象,用户可以编辑和删除他们的项目下的对象。当然,按照OpenStack的设计,管理员用户对所有的对象都具有完全的访问权限。Sahara 是符合通常情况下的OpenStack 访问策略的。
和对象存储整合
在 Open Stack 环境中,项目 Swift 提供的是一套标准的对象存储服务,它是对亚马逊 S3 的开源实现。它是部署在裸机架构中的,在OpenStack中,若是存储和处理数据的话,自然而然的或当仁不让的应该考虑Swift,Sahara 为此向Hadoop 社区提出了需求:HADOOP-8545,并解决了它:变更 I6b1ba25b ,实现了Hadoop对于对象、帐户、容器的端点的访问。如此的集成,使得开发者可以基于数据的位置信息来编写应用,有效的避免了额外的网络开销。
关于如何启用Swfit 的支持的详细信息,请访问Sahara用户手册中的Swift 集成部分。
插件式的部署和监控
若是要加入对特定的 Hadoop 管理工具的监控的话,Sahara 提供了插件式的集成诸如 Nagios 或 Zabbix 的监控系统。
无论是部署还是监控工具,均可安装在独立的虚拟机中。这样就实现了一次性的单个实例来管理和监视多个集群的功能。
原文链接:Rationale
