@Wayne-Z
2017-12-28T13:23:30.000000Z
字数 7385
阅读 3962
Object Dectection
模式识别
Background
Image information is an important source of knowledge for us to understand the world. In many cases, information transmitted by image is richer, more real and specific than other forms of information. The cooperation between the human eye and the brain makes people get, process and understand the visual information. Human beings use visual perception to perceive the information of the environment very efficiently. Thus, as the main carrier of human information, the computer must also be able to deal with the information of the image to be intelligent. Especially in recent years, image data processing, characterized by large capacity of graphics, image and video, is widely applied in the fields of medicine, transportation, industrial automation and so on.
All images in nature are continuous simulated images. In daily life, moving objects in these images are often concerned with us, such as pedestrians, driving vehicles and other objects. Thus, object detection becomes a popular direction in computer vision, and widely applied in many fields, such as robot navigation, intelligent video surveillance, industrial detection, aerospace and so on. Its purpose is to detect the target in the monitoring video or images quickly and accurately, that is, to extract the target from the sequence image.
Application
- Self-driving car
Autonomous cars can use object detection to detect their surroundings, using the visual sensor. Advanced control systems interpret sensory information to identify appropriate navigation paths, as well as obstacles and relevant signage. - Visual Search Engine
Using object detection to establish category for different parts. So when you search for some item such as a handbag, you can find pictures that contains the handbag under different situation. - Aerial Image Analysis
Now with more drones and satellites, we have great amount of aerial image data. And we can use these image to count cars, plants, boats. By analyzing the result we can get useful information such as traffic density.
Challenges
- Variable number of objects
When training the machine learning model, we usually represent the data in fixed size vector. But for a picture, we do not know the number of objects in it, so we need some extra processing, which increase the complexity. - Resizing
When we do the classification, we need to handle all possible object size, we want to find both large objects as well as small objects. - Modeling
We need to build the model in a reasonable way to handle location and classfication requirements, so as to increase the accuracy and efficiency.
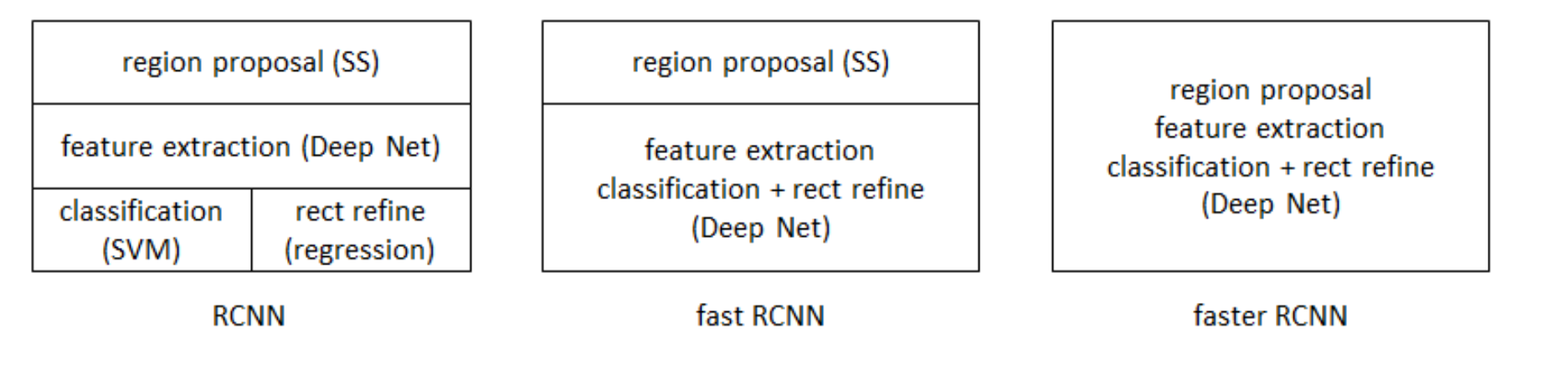
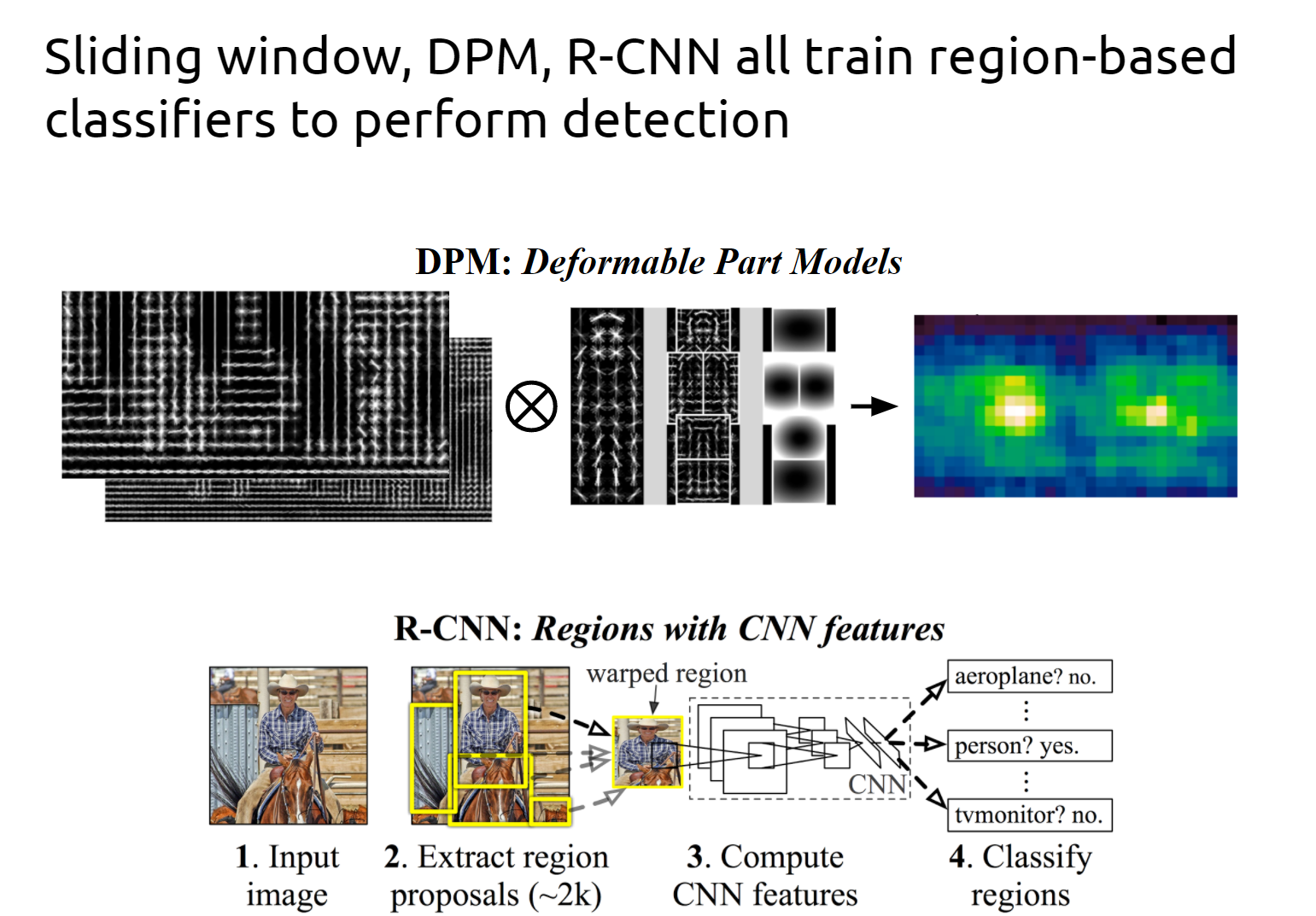
Former work: R-CNN
To fix the problems above, R-CNN proposed CNN(Covlutional Neural Network) for feature extraction on the original architecture, not using the old SIFT, HOG.
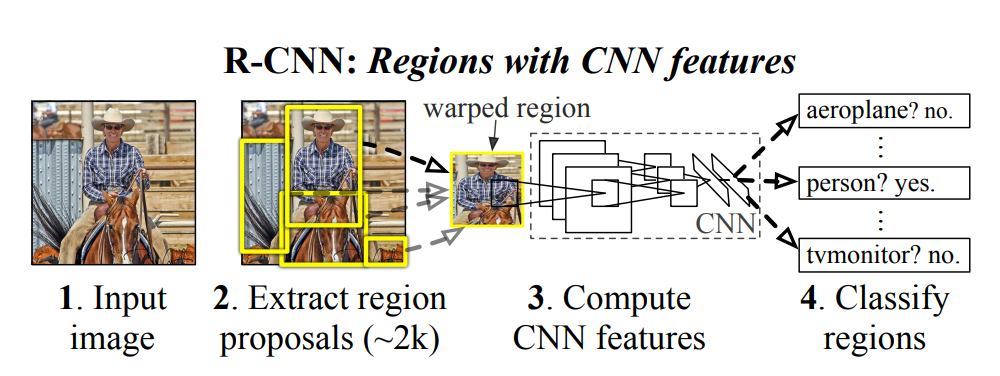
There are four obvious problems in RCNN:
1. The images of multiple candidate regions need to be extracted in advance, which takes up large disk space.
2. In view of the traditional CNN needs the fixed size of the input image, the crop/warp (normalization) produces the object truncation or stretching, which will result in the information loss of the input CNN.
3. Every ProposalRegion needs to enter CNN network computing. Thousands of Region have a large number of overlaps. Repeated feature extraction brings huge computation waste.
4. R-CNN needs to run CNN model for two times. The result of classification is obtained through softmax or SVM for the first time, and it get nms+b-box regression at second times.
Faster R-CNN
From then on, the author Ross Girshick (rbg) proposed several improvement. He proposed Fast-RCNN firstly, it can complete both classification and b-box regression at the same time. But the steps of region proposals still restrict performance. So he proposed Faster R-CNN this year.
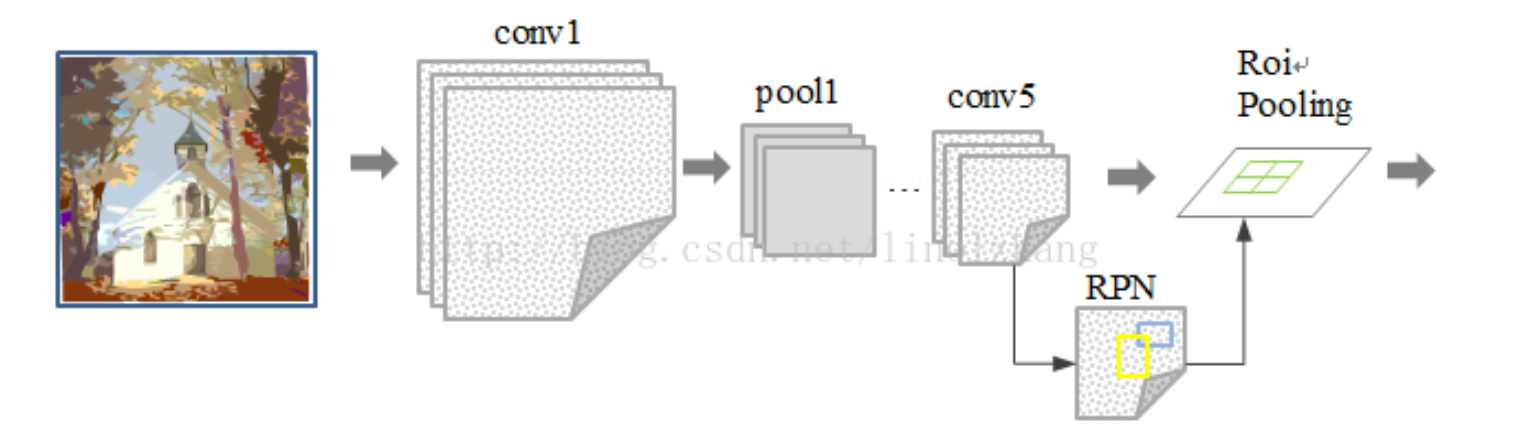
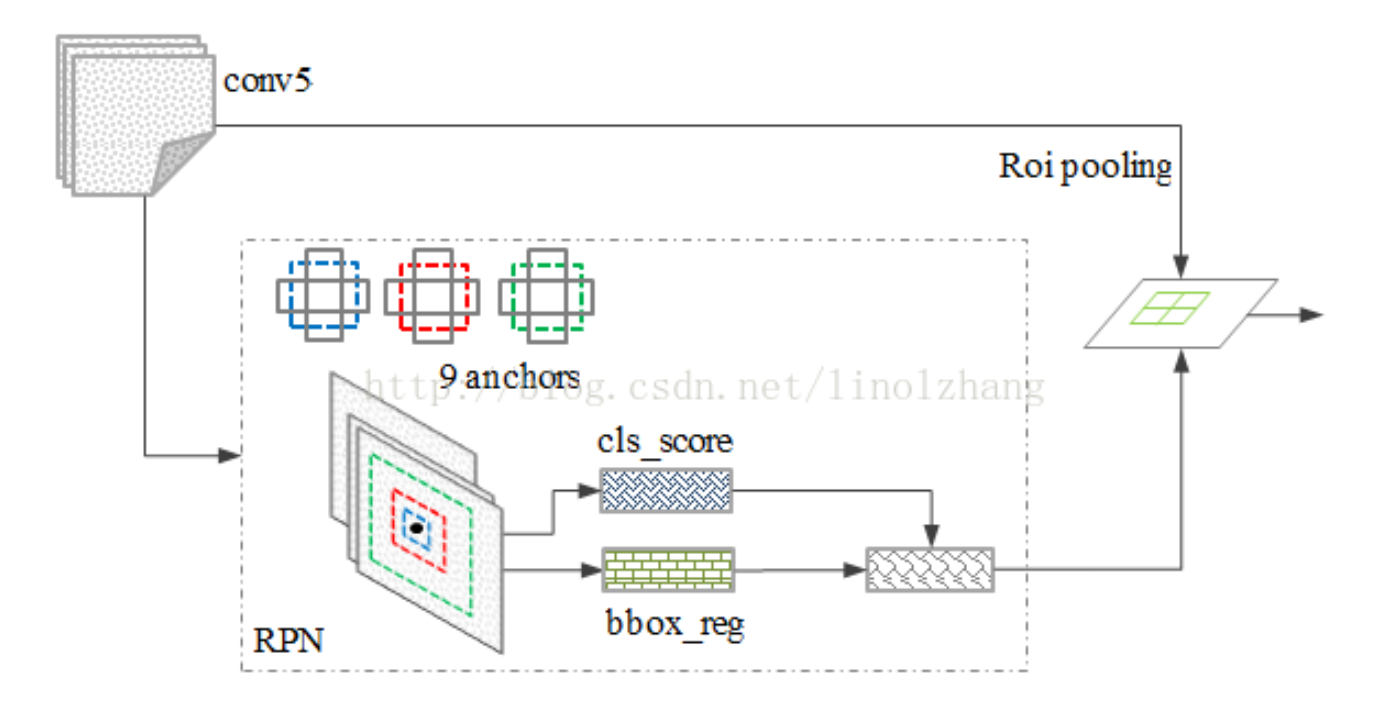
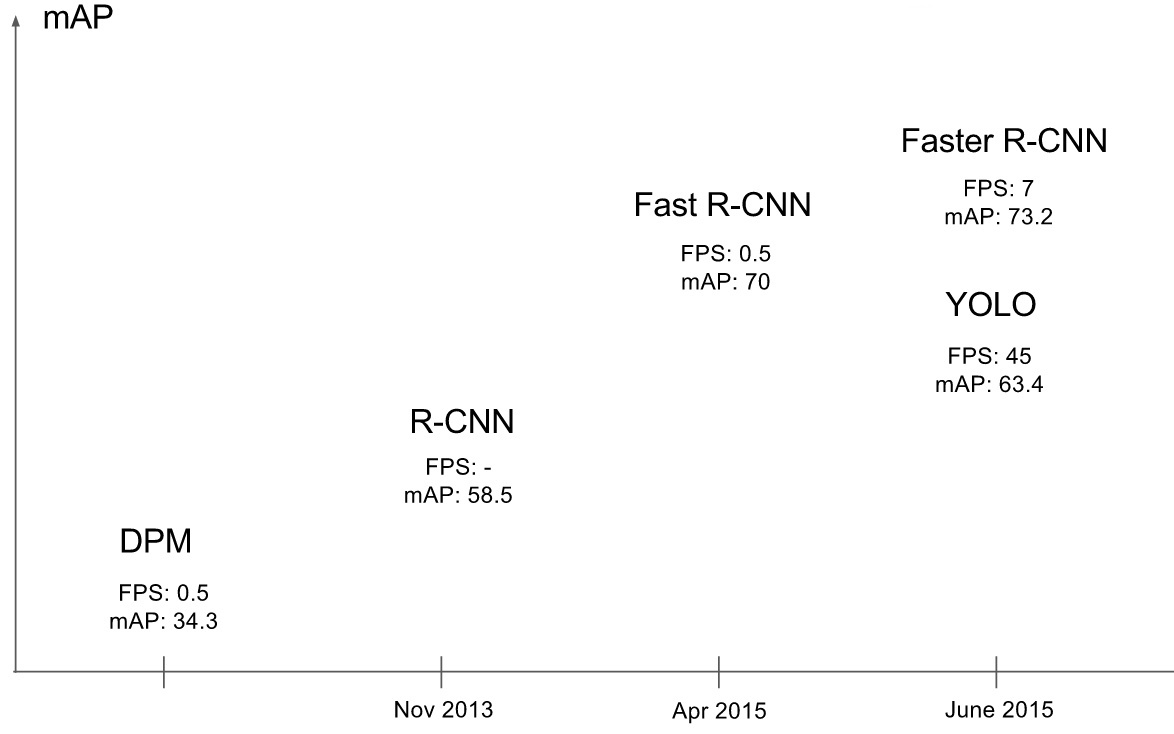
The whole way the author get there is shown below.
As a whole, Faster R-CNN implement high accuracy, but its real time performance is not very ideal. It can only process 7 frames per second using GPU Titan X, so we need a better solution, which ensure both accuracy and efficiency.
Former work: YOLO
Faster R-CNN finally implements the end to end detection and almost achieves the best effect, but there is still room for speed improvement, so YOLO is born.
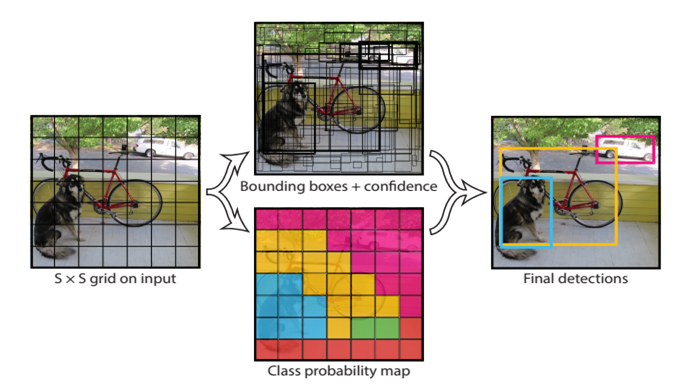
Also, the R-CNN serials still need to do classification work and bounding box work as two task use different channel and method, though they finally use one network. But in YOLO, an image is divided into SxS cell (grid cell), and if the center of a object falls in this grid, the grid is responsible for predicting the object. And then the whole picture is processed by the network and give output for each grid.
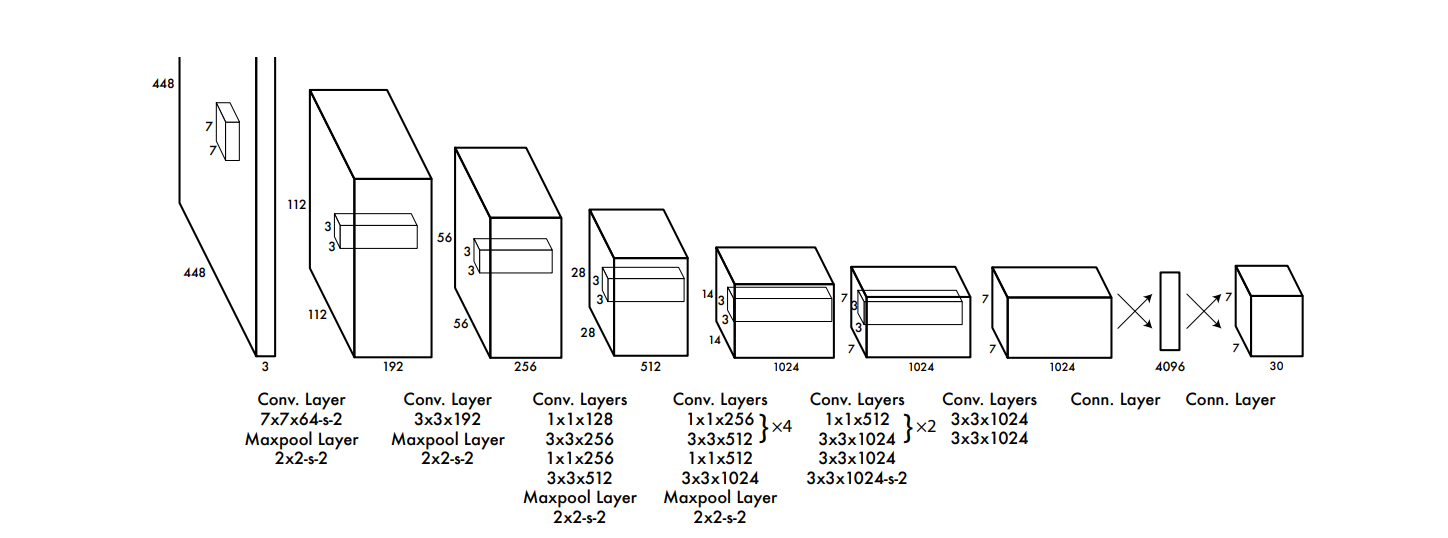
And here is the architecture of YOLO.
Advantages
- Faster than R-CNN and Faster R-CNN
- Use the whole image as the context information, less Background error.
- Good Generalization
Problem
However, YOLO still has several problems.
1. Can not perform well with objects that are near to each other, neither with small objects, because it only predicts two boxes in a grid, and belongs to only one class.
2.The new uncommon ratio of length and width to the same class of objects in the test image is the same. Generalization ability is weak.
3. Because of the problem of loss function, the location error is the main reason that affects the detection effect. In particular, the processing of large and small objects remains to be strengthened.
As a whole, the location of YOLO method is not accurate enough. The contribution is to propose a new idea for target detection, and let us see the real possibility of target detection in practical applications.
Proposal: Mask RCNN
MaskR-CNN, extends Faster R-CNN by adding a branch for predicting segmentation masks on each Region of Interest. It has very good performance both in efficiency and accuracy, thus proposed.
Looking from the structure, this can be seen as a plus output in the Faster RCNN: the original classification and b-box regression represents have two output, now add a mask (for pixel segmentation), then the tasks of the object detection and segmentation are fused together. Because these two jobs both need to use a large base layer to extract features, this improves the speed at the task level.
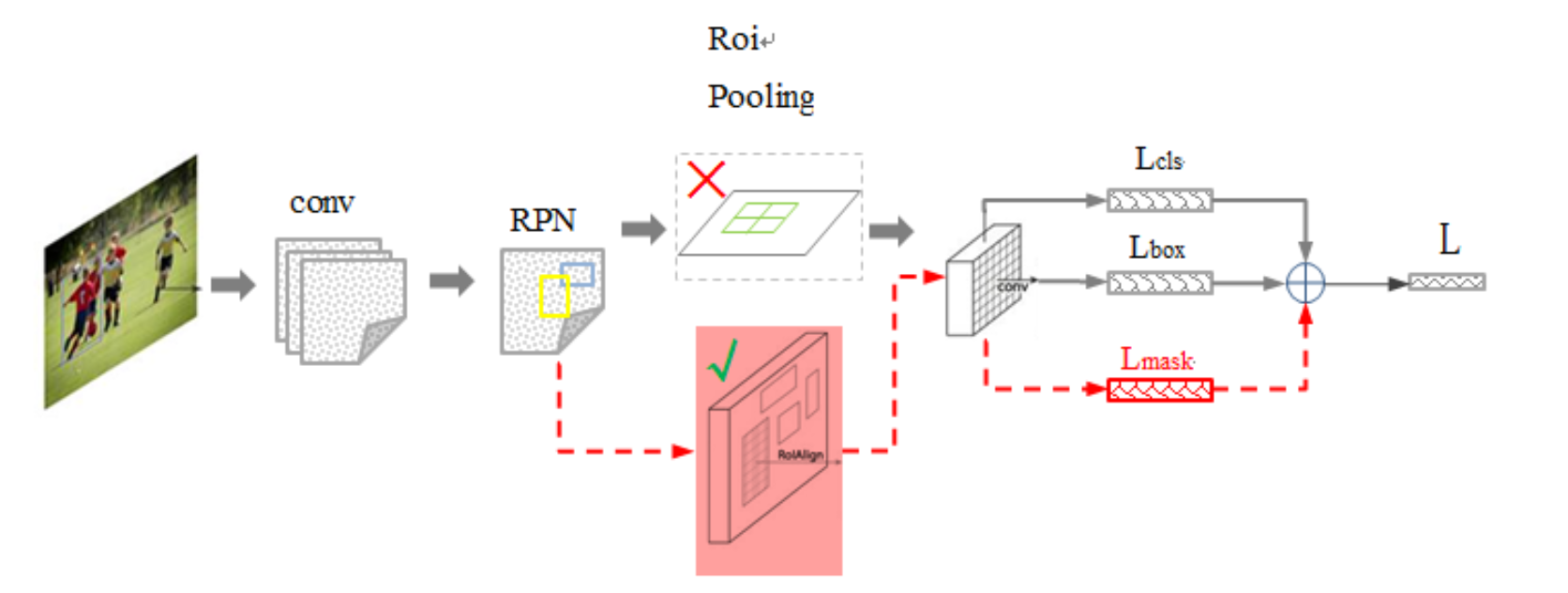
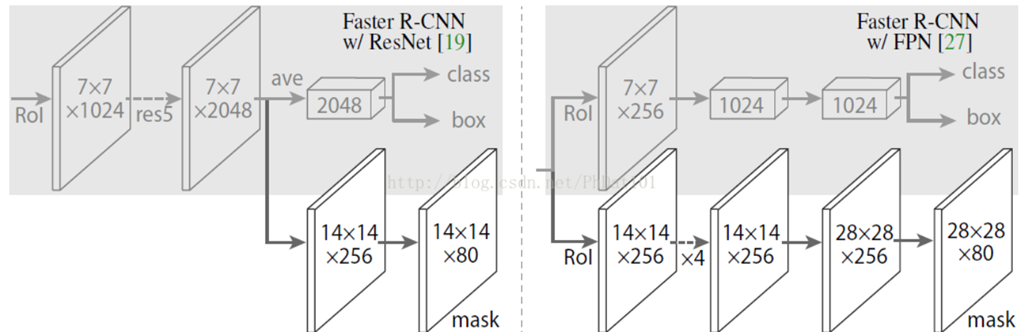
Improvements
- Enhancement of the basic network, ResNet->FPN->ResNeXt
- change the ROIpooling that has been used to ROIAlign: because ROIpooling is a loss deformation, and it loses a pixel on the top feature maps, which reflects the image on the bottom layer. ROIAlign uses bilinear interpolation (bilinear interpolation) to solve this problem and improves the final effect.
- take mask as a single head, and each class has a corresponding mask (a class occupies the final feature map, a channel), so that the "inter class competition" is avoided.
Experiments
The network has been trained and tested on several datasets using different hyper parameters. And they all get the best outcome.
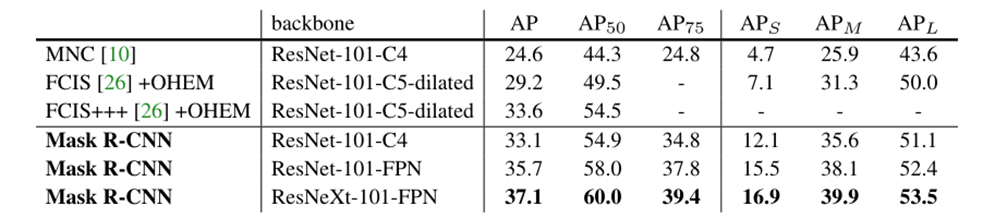
Experiments on Instance Segementation
This is the Instance segmentation mask AP on COCO test-dev. MNC and FCIS are the winners of the COCO 2015 and 2016 segmentation challenges, respectively. Without bells and whistles, Mask R-CNN outperforms the more complex FCIS+++, which includes multi-scale train/test, horizontal flip test, and OHEM [35]. All entries are single-model results.

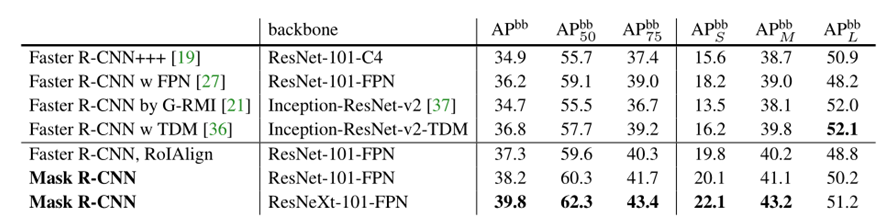
Experiments on Object Detextion
This is the Object detection single-model results (bounding box AP), vs. state-of-the-art on test-dev. Mask R-CNN using ResNet-101-FPN outperforms the base variants of all previous state-of-the-art models (the mask output is ignored in these experiments). The gains of Mask R-CNN over come from using RoIAlign (+1.1 AP bb ), multitask training (+0.9 AP bb ), and ResNeXt-101 (+1.6 AP bb ).
Experiments on Keypoint Detection
This is Keypoint detection results on COCO test using Mask R-CNN (ResNet-50-FPN), with person segmentation masks predicted from the same model. This model has a keypoint AP of 63.1 and runs at 5 fps.

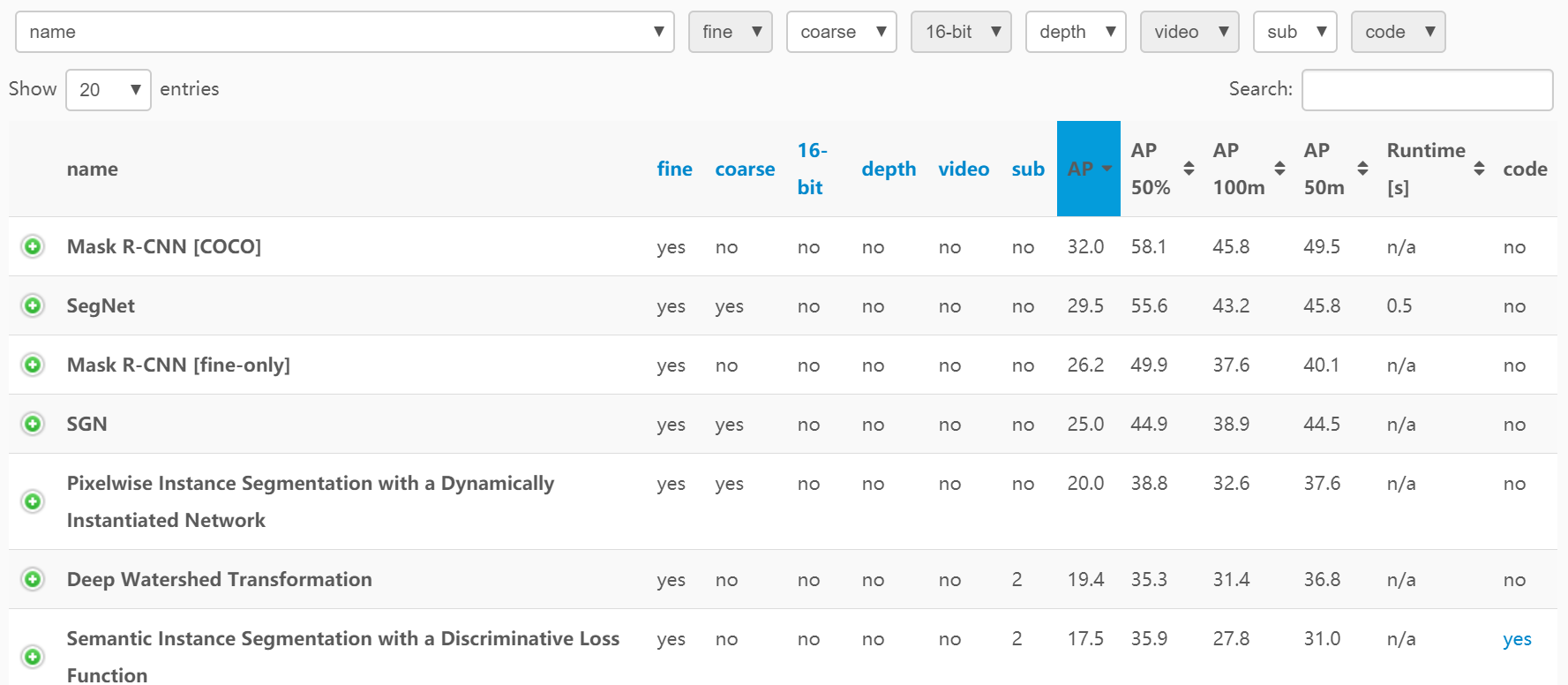
Experiments on Cityscapes
We apply our Mask R-CNN models with the ResNet-FPN-50 backbone; And it got the best result.

And the model got the best benchmark.
Reference
Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
Fast R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
You Only Look Once: Unified, Real-Time Object Detection
Mask R-CNN
图解YOLO
论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
深度学习RCNN系列详解
简介物体检测从RCNN到Mask RCNN的网络构型变化
