@Wayne-Z
2017-09-22T08:20:52.000000Z
字数 4715
阅读 2471
Report 1 for Compiler Construction
编译原理
Reading
Reviewed what has been learned last semester by reading the chapter 1&2 of book Compiler Construction.
Also read Pragmatic.The Definitive ANTLR 4 Reference book and then finished reading the short-course.
And this article has been published in Jianshu.
Prepare Experiment
I have configured the antlr work environment in two ways.
PowerShell Environment
Download the file from the website, and then move it to a directory for 3rd party java libraries, mine is
C:\javalib
then write two scripts as following.
This is antlr4.bat
@echo offjava org.antlr.v4.Tool %*
And this is grun.bat
@echo offjava org.antlr.v4.gui.TestRig %*
After this two file were all put into system32,
Then we can test it by type command in PowerShell at any position
antlr
and
grun
It seems works fine, then test the example.
Example of Hello
In a test directory, put the following grammar inside file Hello.g4: Hello.g4
// Define a grammar called Hellogrammar Hello;r : 'hello' ID ; // match keyword hello followed by an identifierID : [a-z]+ ; // match lower-case identifiersWS : [ \t\r\n]+ -> skip ; // skip spaces, tabs, newlines
type
antlr4 Hello.g4
we can see 6 new files named:
- Hello.tokens
- HelloBaseListener.java
- HelloListener.java
- HelloLexer.java
- HelloLexer.tokens
- HelloParser.java
And then compile and test it, I meet thie bug
PS D:\tution\解释器构造\test1> javac *.javaPS D:\tution\解释器构造\test1> grun hello r -treeWarning: TestRig moved to org.antlr.v4.gui.TestRig; calling automaticallyCan't load Hello as lexer or parser
It just seems I forgot to add'.' into the classpath. After add'.' to the class path, it just works well.
IDEA Environment
Just add plugins of antlr4 into this IDE and we can work with it.
create a new file named hello.g4, and then write the same grammer shown above, right click r, choose to test rule r. Then we can see the picture below.
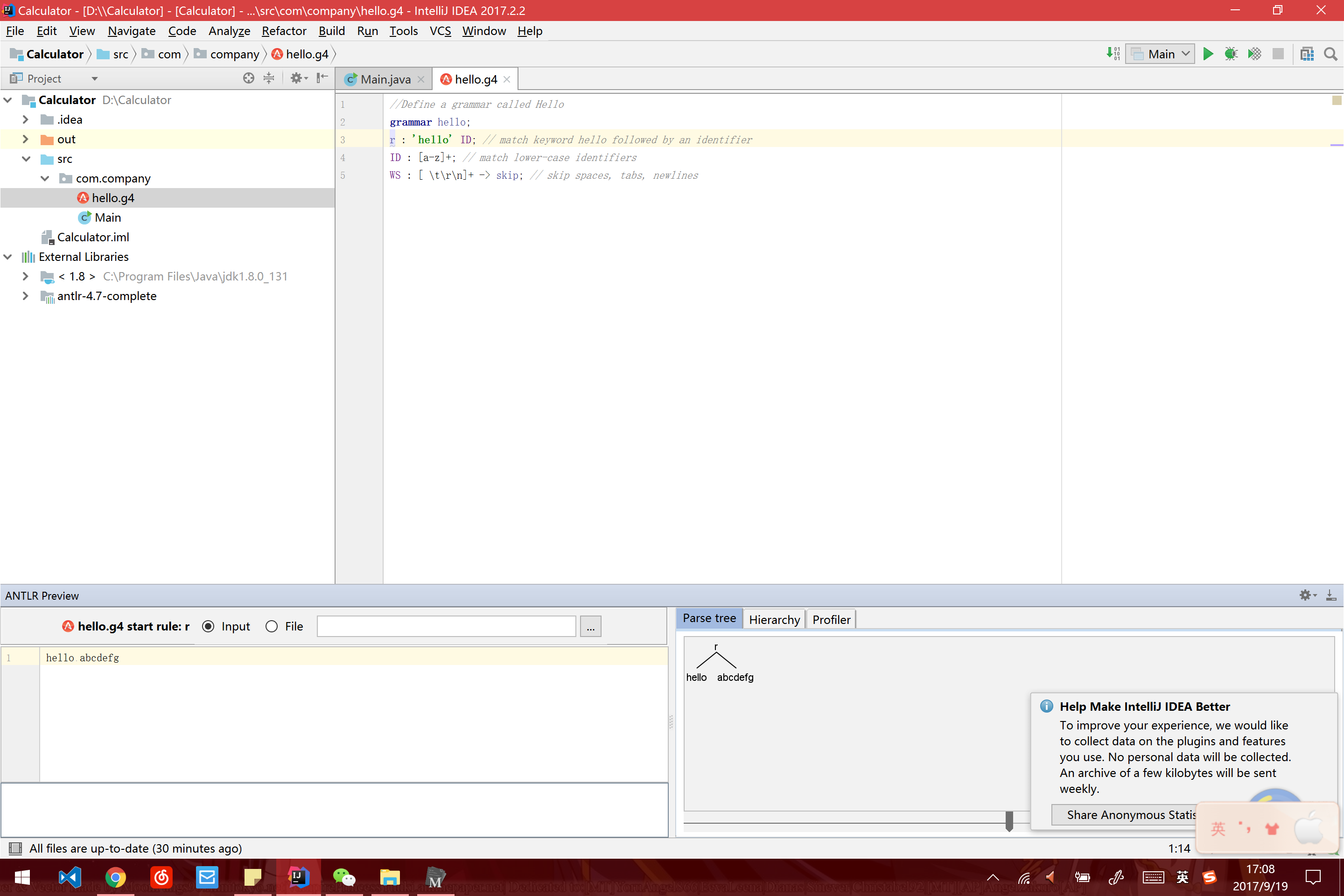
Calculator
thoughts
Change the thoughts used before, after reading blogs and materials, I found that what I need to do is just define a completed grammar, and then try to to search the abstract grammar tree, and then I can get the calculated outcome.
Grammar
Since the grammar used before is not well-defined, I tried several grammars, and I found a well-defined grammar like below. The discussion of grammars can be found in the foreum(Yeah, it is me :) ).
grammar Calc;options {language=Java;output=AST;ASTLabelType=CommonTree;}// PARSER RULESprog : ( ( assign | out ) SEMICOLON)+;assign : VAR EQUA expr # assignment;out : (PRINT '('expr ')' )+ # printExpr;expr : expr op=(MULT | DIV) expr # MulDiv| expr op=(MINUS |PLUS) expr # AddSub| NUMBER # number| VAR # varaible| '(' expr ')' # parens;//LEXER RULESPRINT : 'print';NUMBER : INT | FLOAT ;VAR : [a-zA-Z][a-zA-Z0-9]*;WHITESPACE : ( '\t' | ' ' | '\r' | '\n'| '\u000C' )+ ->skip ;INT : [0-9] | [1-9][0-9]+ ;FLOAT : [0-9]+ POINT [0-9]+ ;PLUS : '+' ;MINUS : '-' ;MULT : '*' ;DIV : '/' ;SEMICOLON : ';' ;EQUA : '=' ;POINT : '.' ;
Parse-Tree Visitor
The symbol '#' is important, like '# assignment' in line 12, this lable let the antlr creater different visit methods for each rule, and we will override these methods to implement the calculator.
When generate java code using antlr, we should add -no-listener option like since we do not need the listener for now. In command line, the commond is like this.
antlr4 -no-listener -visitor Calc.g
In idea, we should set the antlr generation configuration like the picture below
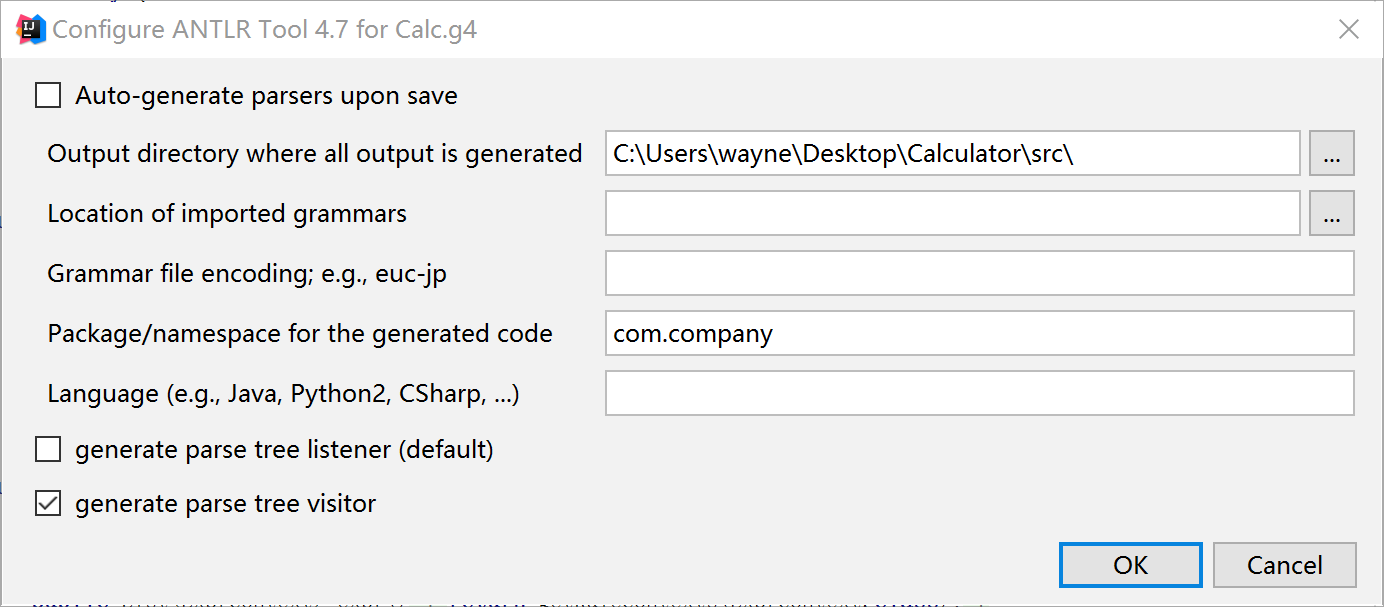
choose to generate the parse tree vistor.
After generated, we can find that in the CalcBaseVisitor.java, there

Then we create our own class file to execute the calculate. Like the function shown below:
//Still need a hashmap to record all the variables to check if they are used before declared.Map<String, BigDecimal > memory = new HashMap<String,BigDecimal>();public BigDecimal visitAssignment(CalcParser.AssignmentContext ctx) {String var = ctx.VAR().getText();BigDecimal value = visit(ctx.expr());memory.put(var, value);return value;}
I tried to use the BigDecimal class to fix the precision problem of the float number, but for now I still can not fix it out. And we can see all I did in this function and others is just use the ctx created already , and visit it, do calculation. And we also need to add some codes to check bugs like divition of zero etc.
Main Function
The most important code in the main function is shown like below
// This method seems to be deprecated, but still can be used for nowANTLRInputStream input = new ANTLRInputStream(is);// create a lexerCalcLexer lexer = new CalcLexer(input);// record all the tokensCommonTokenStream tokens = new CommonTokenStream(lexer);// do parse work to tokensCalcParser parser = new CalcParser(tokens);// create Parse-TreeParseTree tree = parser.prog();// visit the Parse TreeEvalVistor eval = new EvalVistor();eval.visit(tree);
Test
After all of whork mentioned above, we finally create a calculator support decimal calculation. Then we can test use the test cases used in last semester
In test.in
a=(10.44*356+1.28)/2+1024*1.6;b=a*2-a/2;c123=a+b*b/5-(a-a*2)/b;print(a);print(b);print(c123);print(1+2-3*4/5);
The output is like below

And error1.in, it miss a semicolon
a=(10.44*356+1.28)/2+1024*1.6;b=a*2-a/2print(a);print(b);
The output is like below 
error2.in divid zero
a=(10.44*356+1.28)/2-1024*1.6;print(a);print(1/0);
The output is like below

