@TaoSama
2026-03-22T14:00:59.000000Z
字数 3894
阅读 59
Deep Learning
Machine-Learning
Neural Networks and Deep Learning
Introduction to Deep Learning
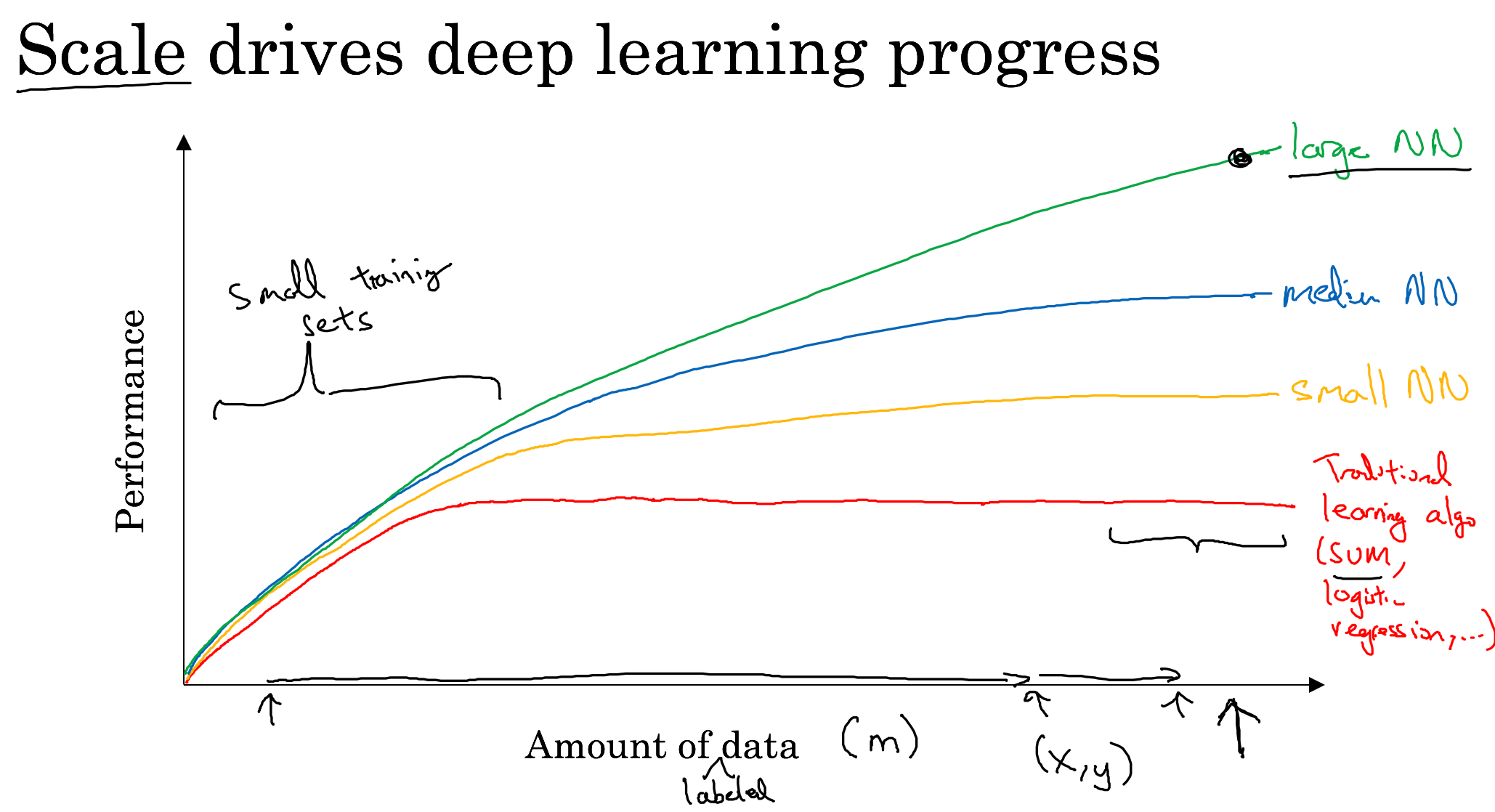
Neural Networks Basics
Logistic Regression as a Neural Network


Python and Vectorization
SIMD: single instruction, multiple data
IID: identically independently distributed
# Whenever possible, avoid explicit for-loops.# Python broadcasting# For a m×n matrix, the general principle:(m, n) +-*/ (m, 1) -> (m, n)(m, n) +-*/ (1, n) -> (m, n)
Sweets
This past week there was an article in Mashable about a 16-year-old in United Kingdom, who is one of the leaders on Kaggle competitions.
And it just said, he just went out and learned things, found things online, learned everything himself and never actually took any formal course per se.
And there is a 16-year-old just being very competitive in Kaggle competition, so it's definitely possible.
We live in good times. If people want to learn.
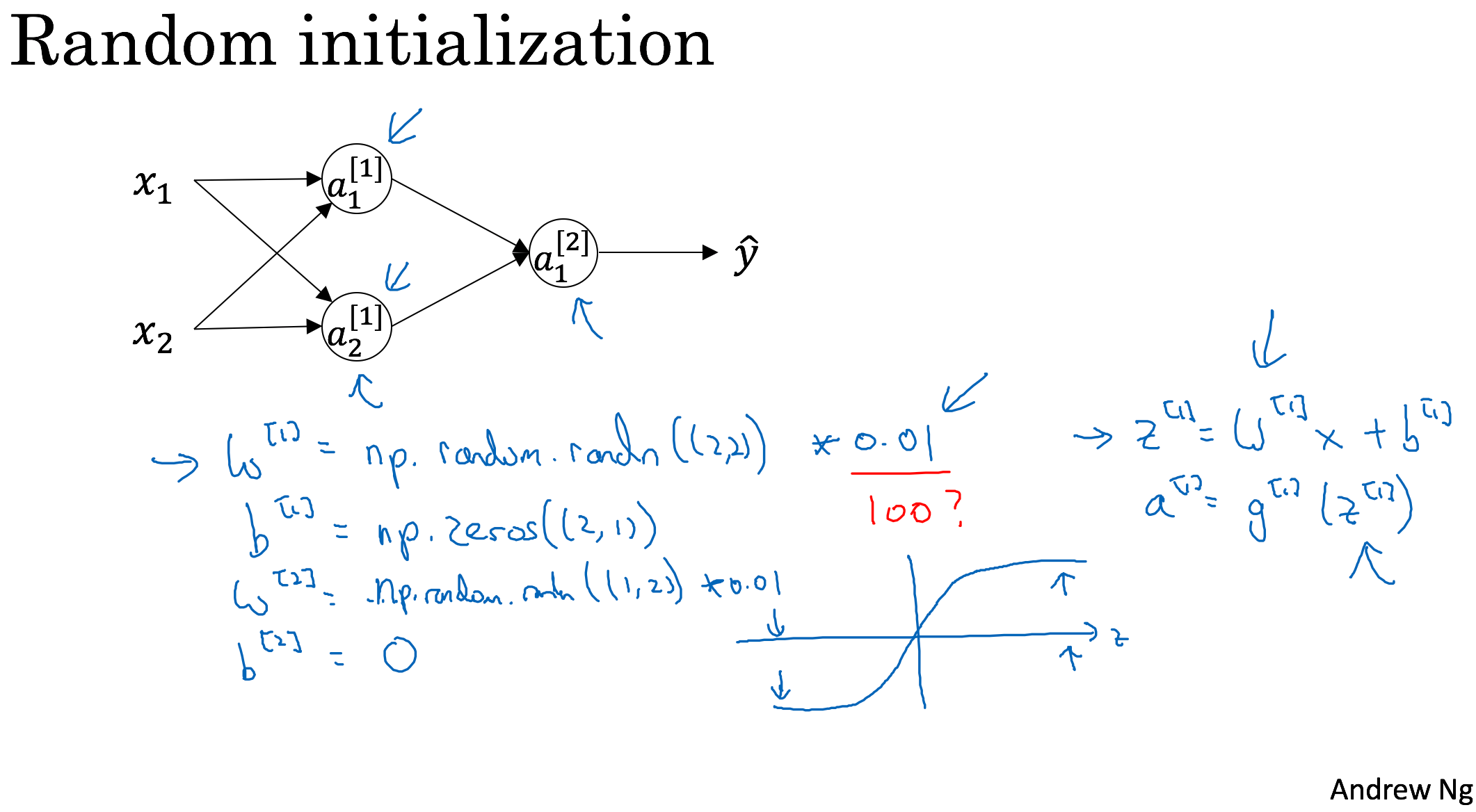
Shallow Neural Network
Derivatives of activation functions
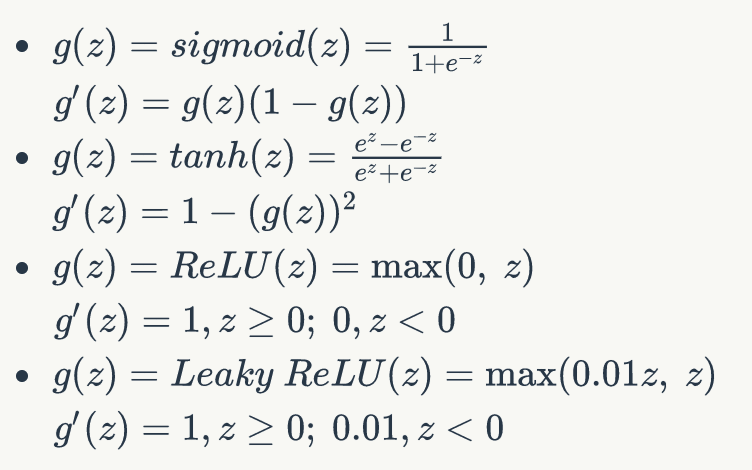
Gradient decsent for Neural Networks

Random Initialization
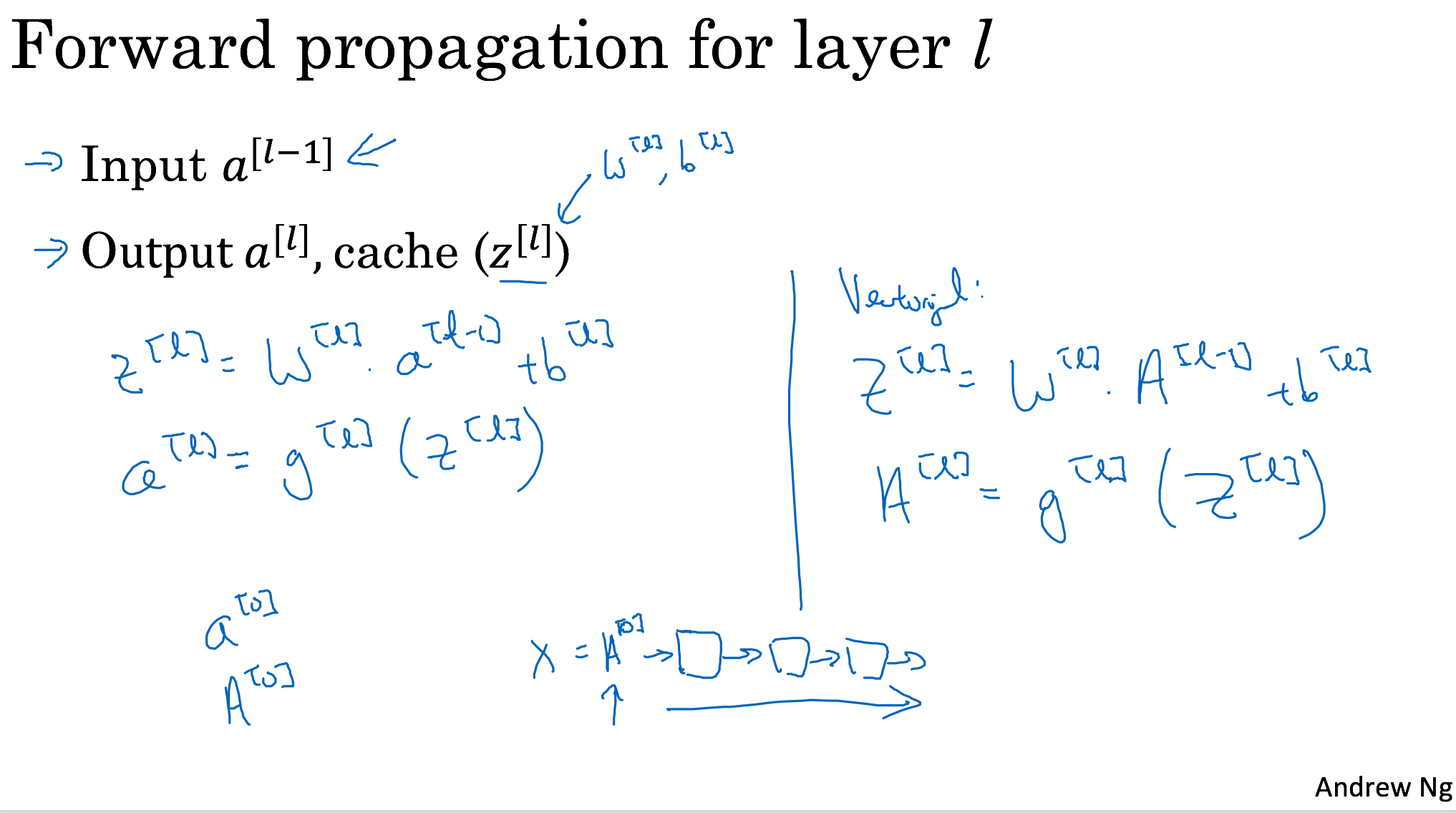
Deep Neural Network

Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
Setting up your Machine Learning Application
Train/dev/test sets
- previous era:
70%/30% 60%/20%/20% (100-1000-10000)
- big data era:
98%/1%/1% [980000-20000 10000 1000] (100,0000) - make sure dev and test set come from same distribution
- big data era:
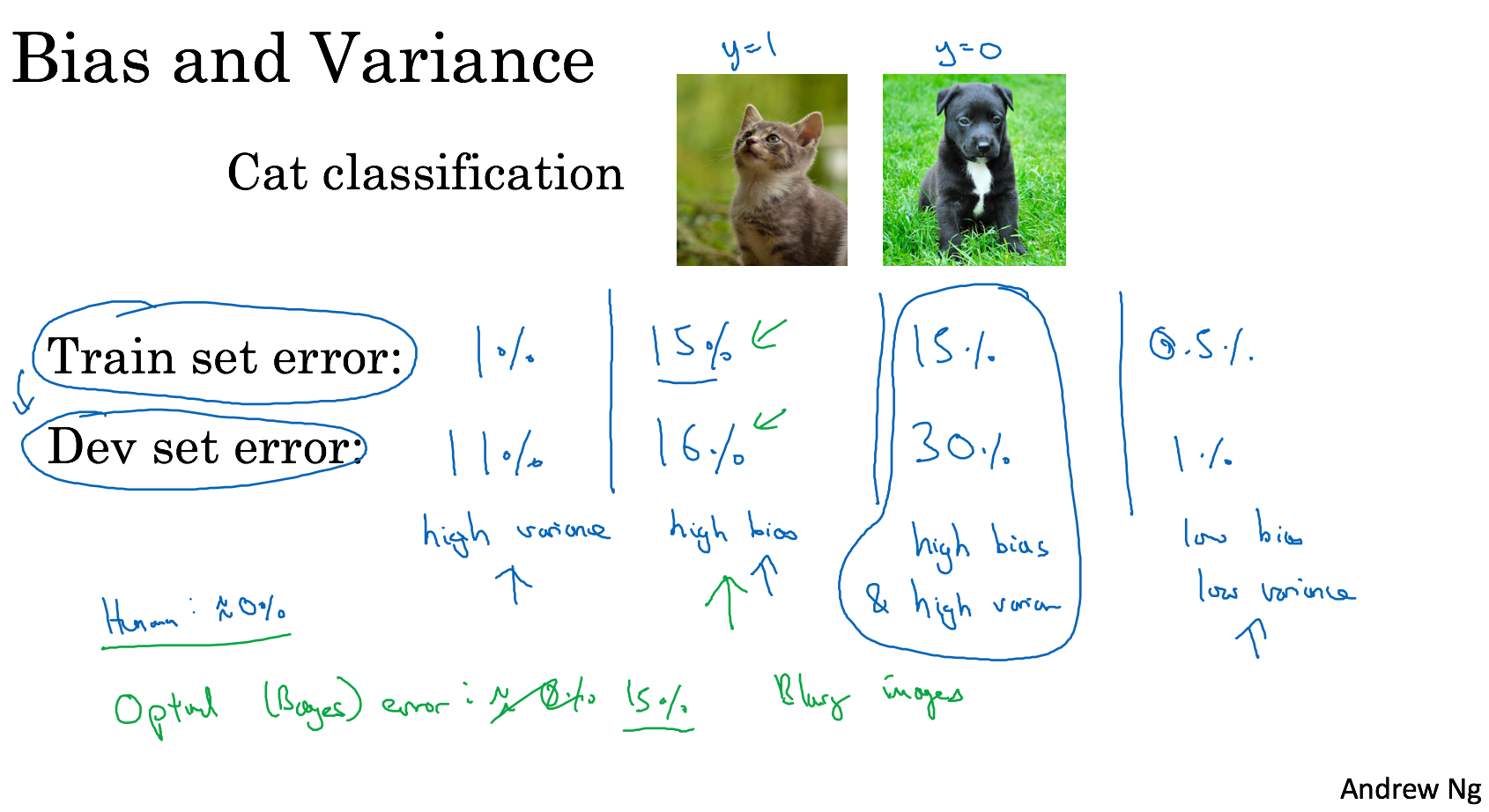
Bias/Variance
Regularizing your neural network
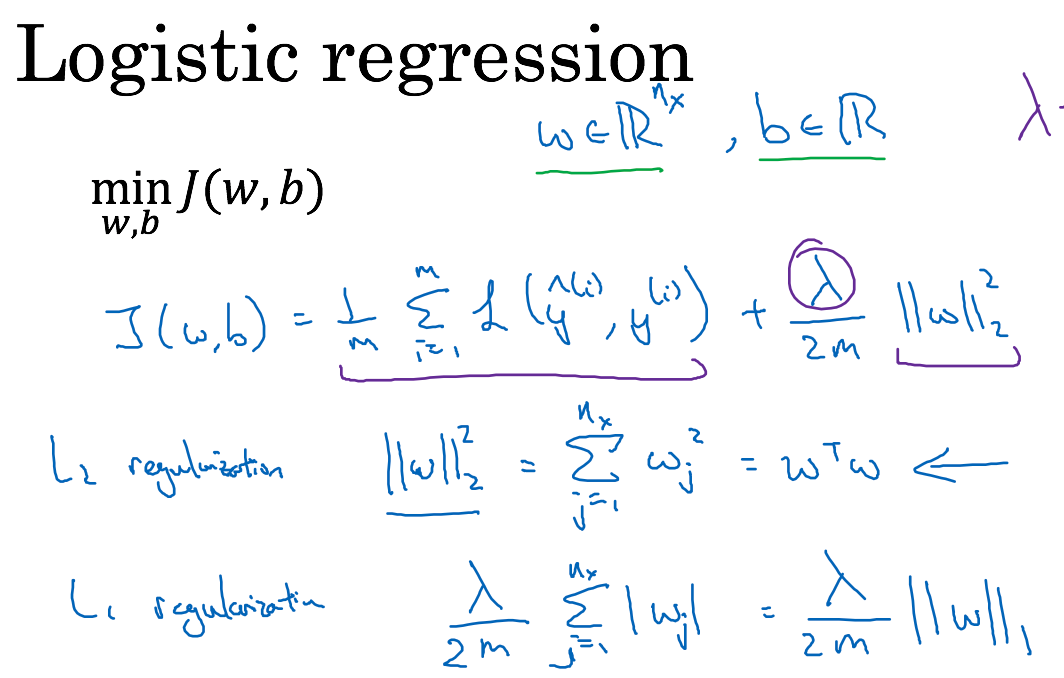

Dropout regularization
Intuition: Can’t rely on any one feature, so have to
spread out weights.

Other regularization
- Data augmentation
- Early stopping
Setting up your optimization problem
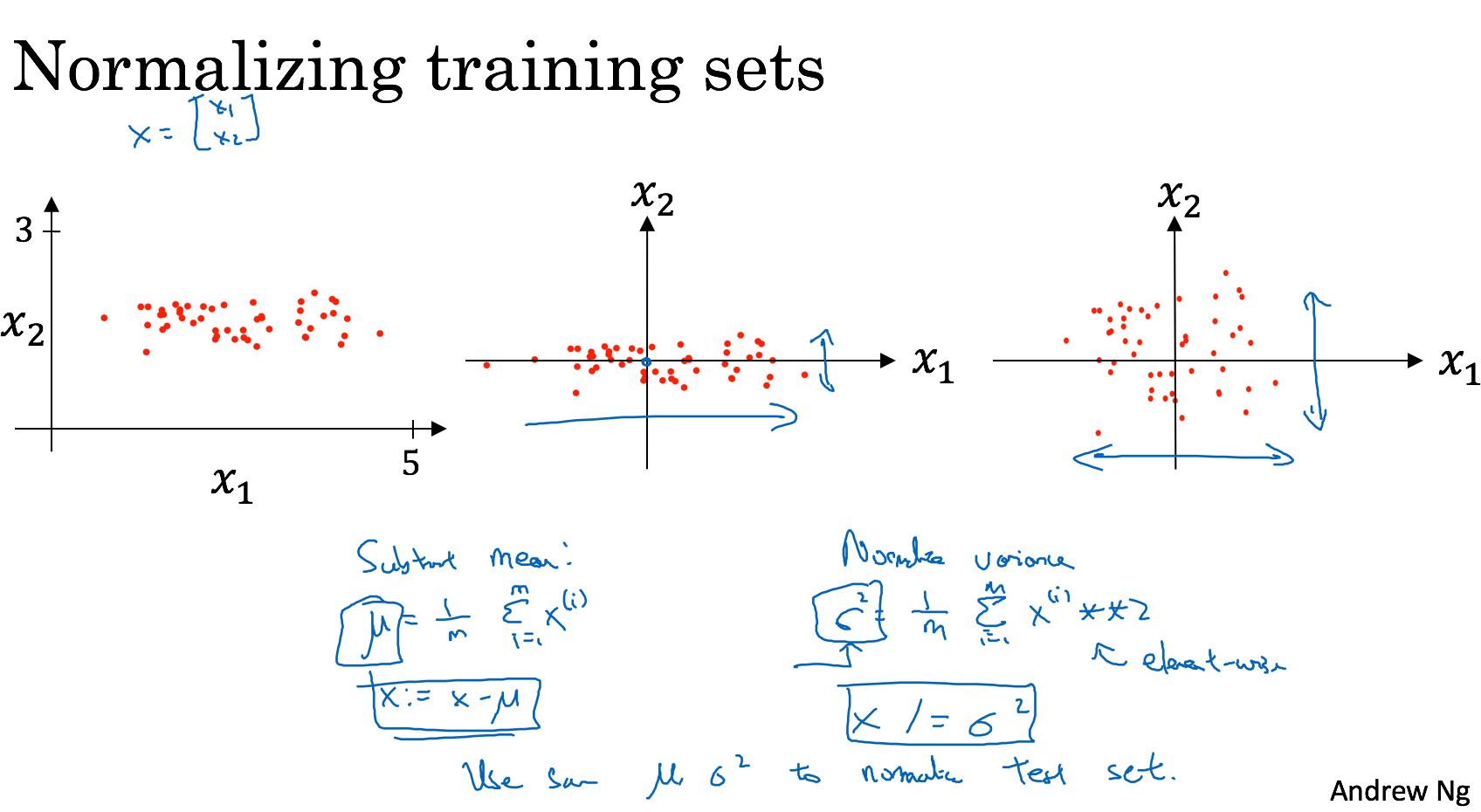
Normalizing inputs
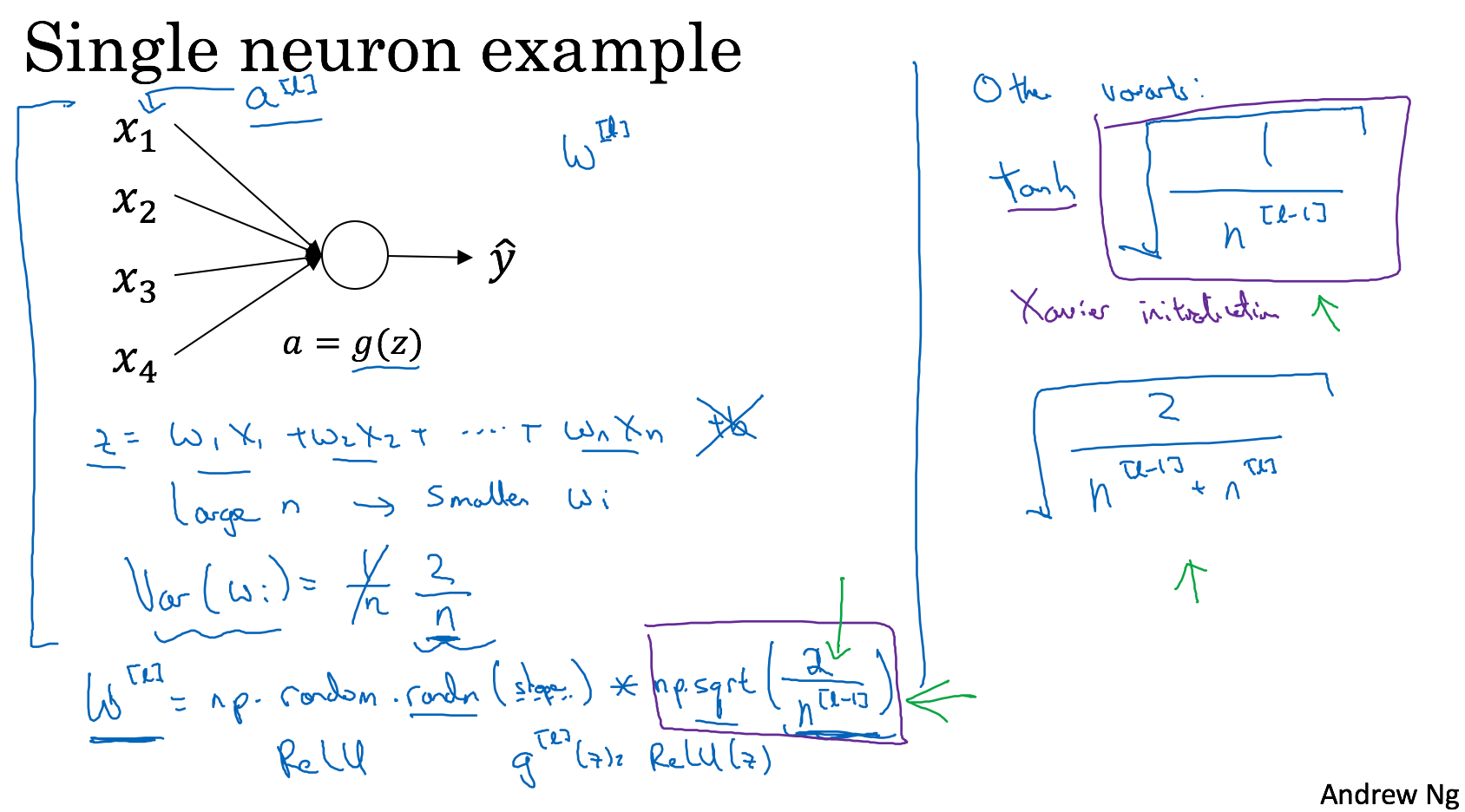
Weight initialization for deep networks
Numerical approximation of gradients and gradient checking

Optimization algorithms
Mini-batch gradient descent

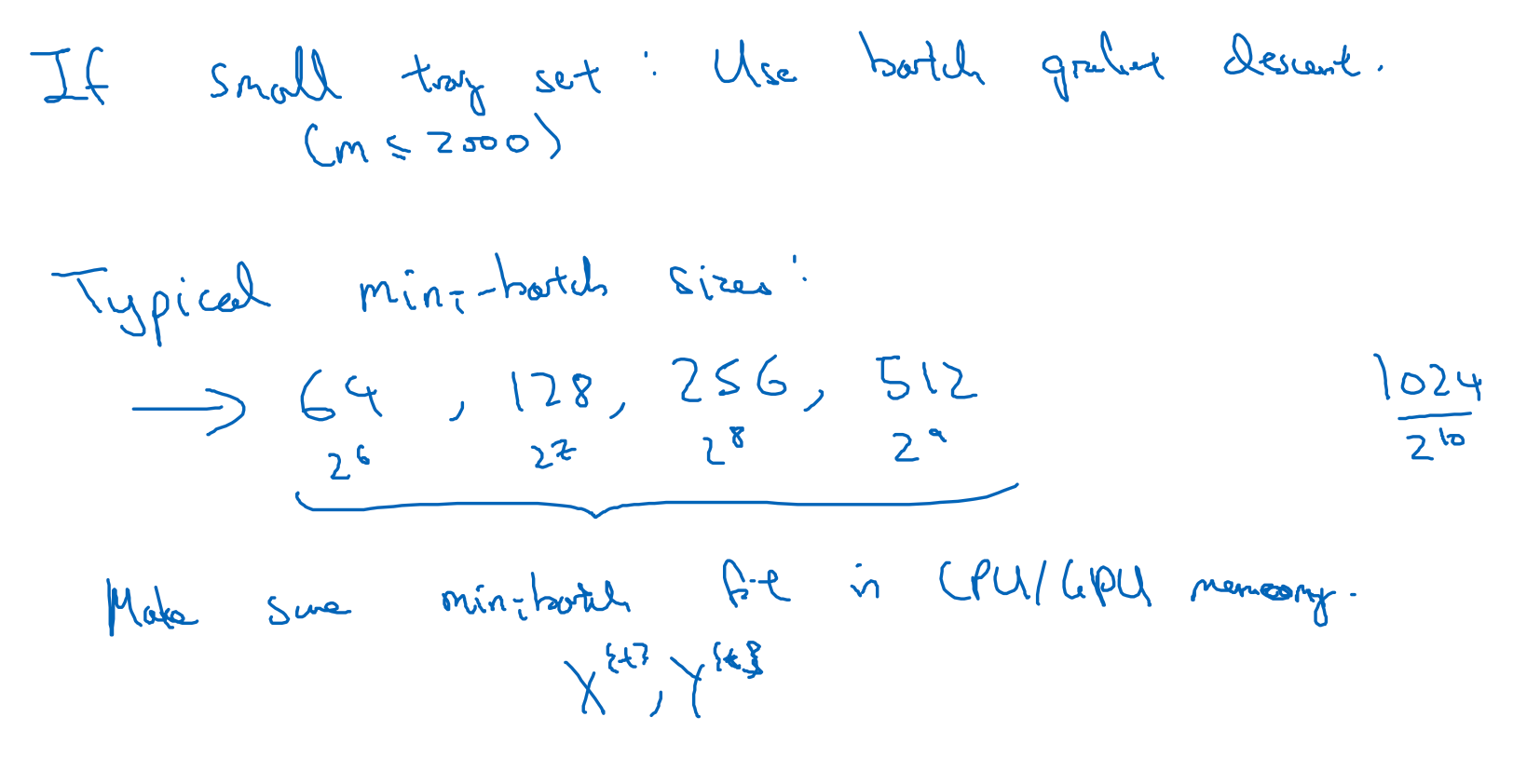
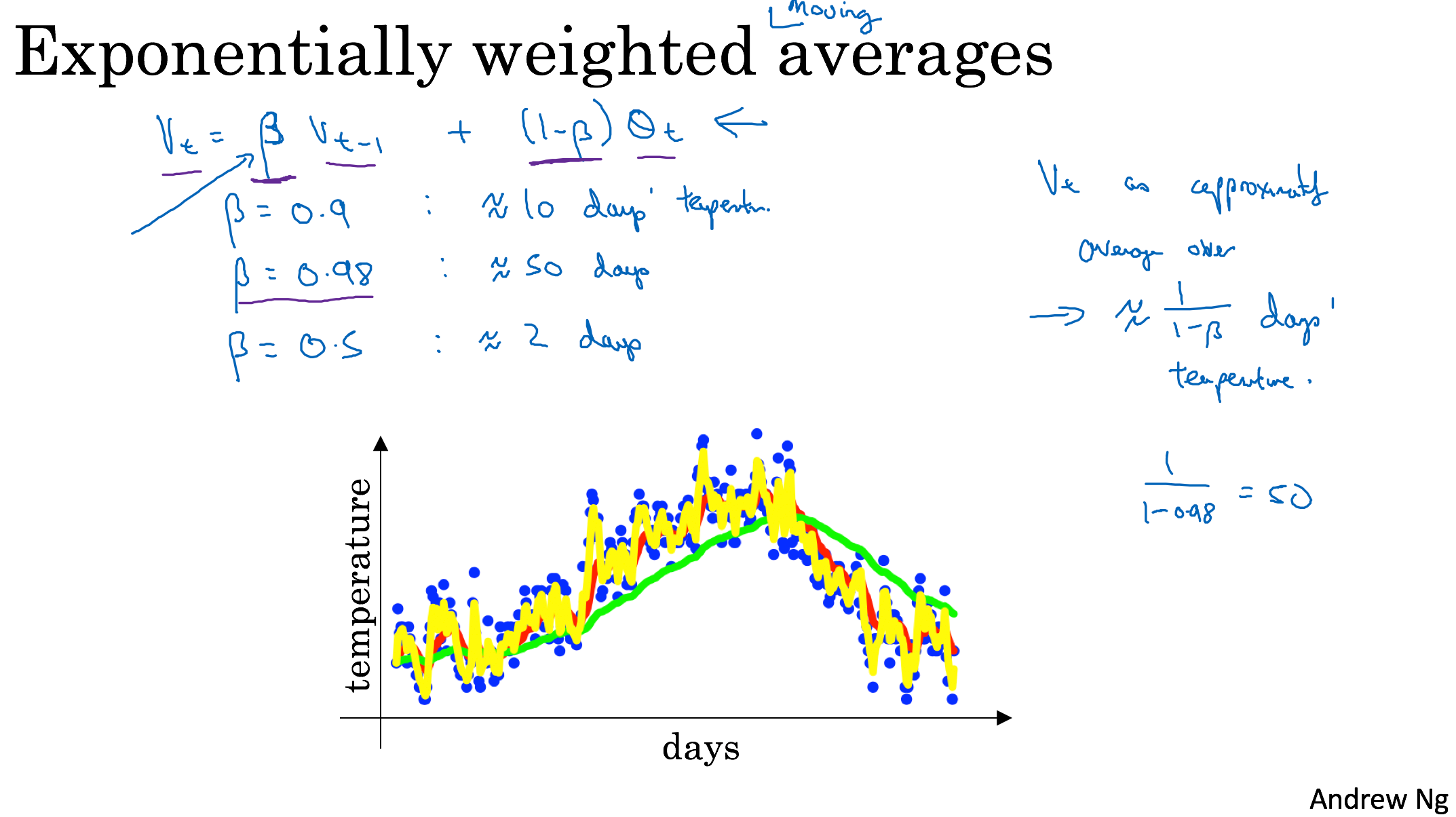
Exponentially weighted averages
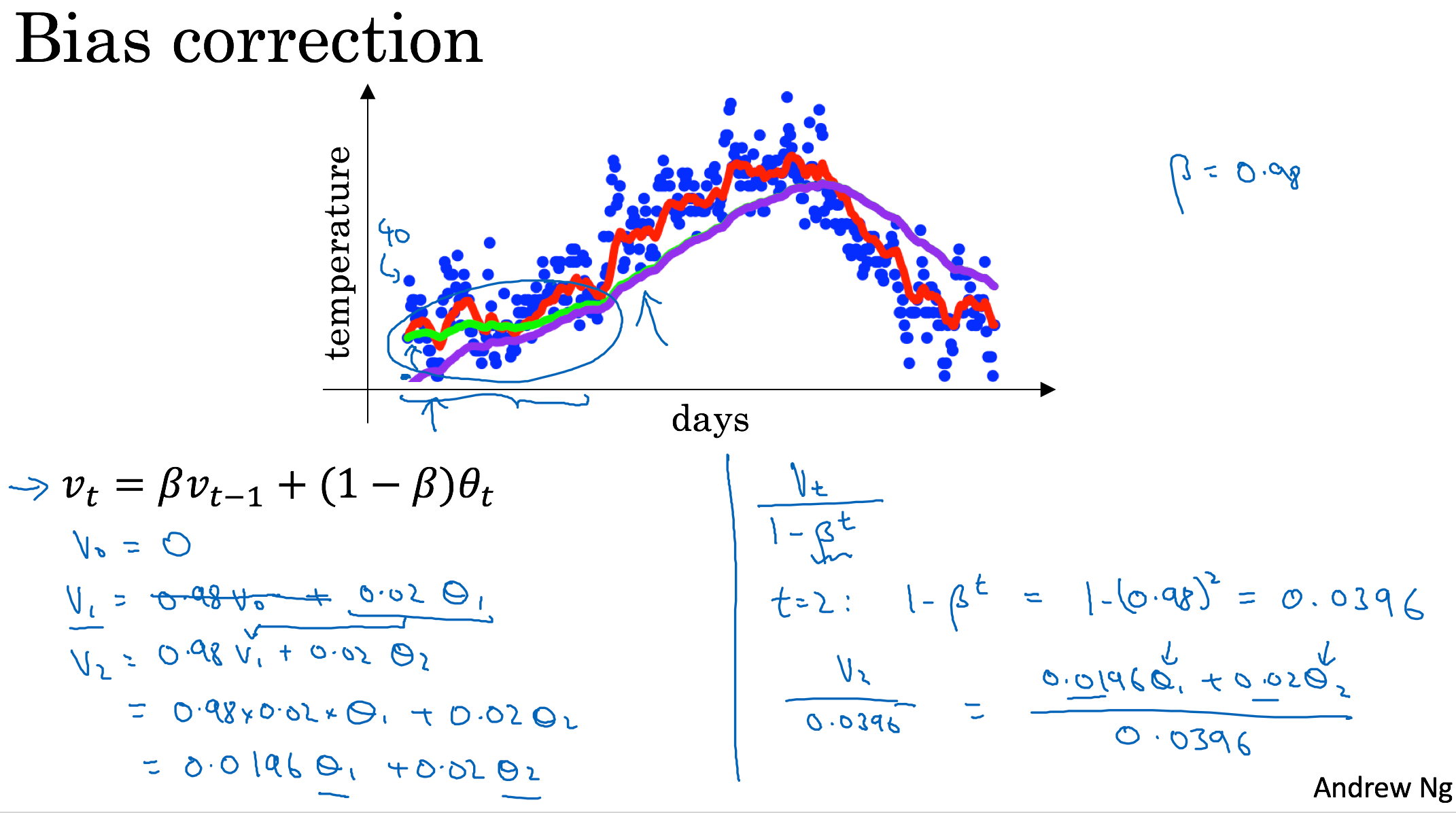
Bias correction in exponentially weighted average
Gradient descent with momentum

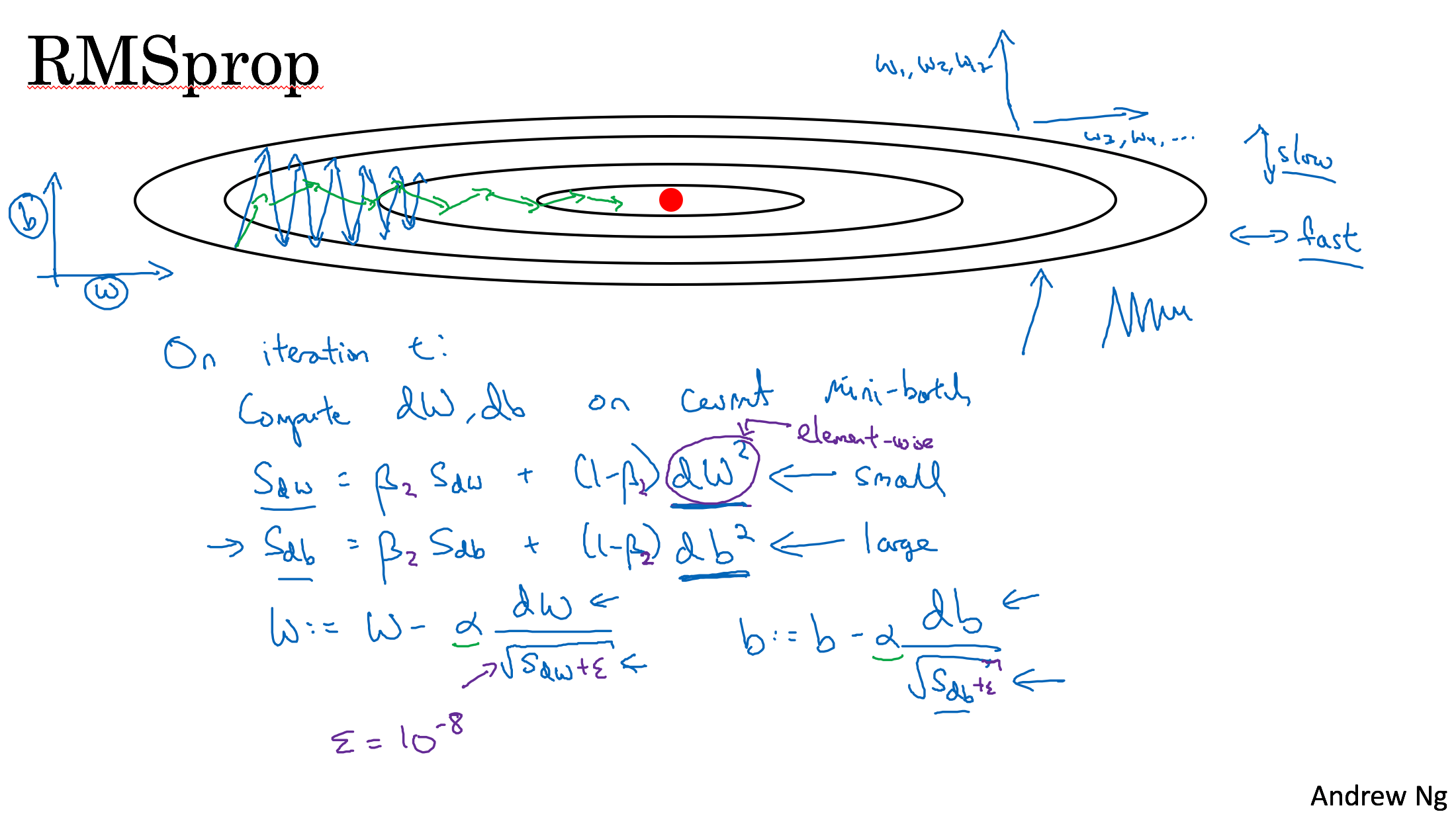
RMSprop
Adam


Learning rate decay
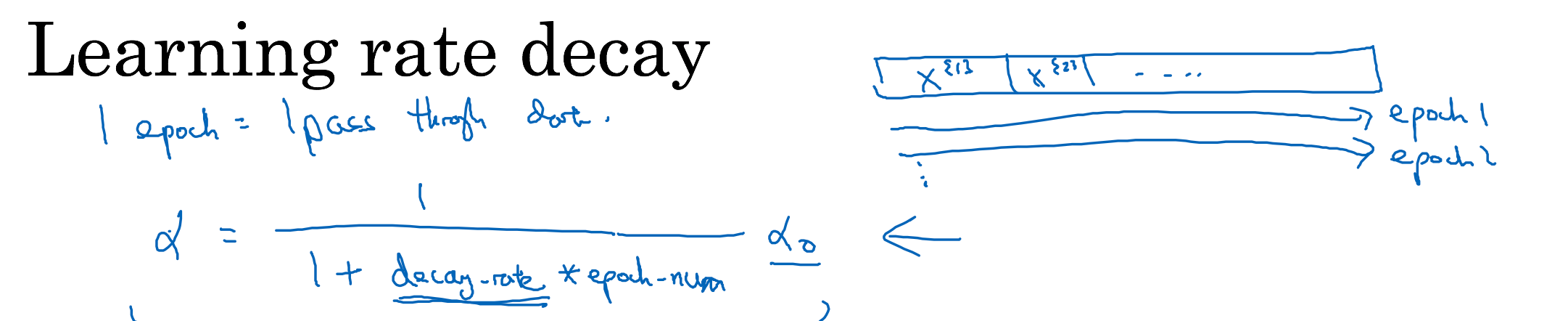

Hyperparameter tuning, Batch Normalization and Programming Frameworks
Tuning process
red->orange->purple->none

- random sampling
- optionally consider implementing a coarse to fine search process
Using an appropriate scale to pick hyperparameters
Learning rate
- random alpha [0.0001, 1]
- a=log10(0.0001)=-4, b=log10(1)=0
- r=-4*np.random.rand()
- alpha=10^r
Hyperparameters for exponentially weighted averages
- random beta [0.9, 0.999]
- beta=1-beta
- do as above
Batch Normalization

Softmax Regression
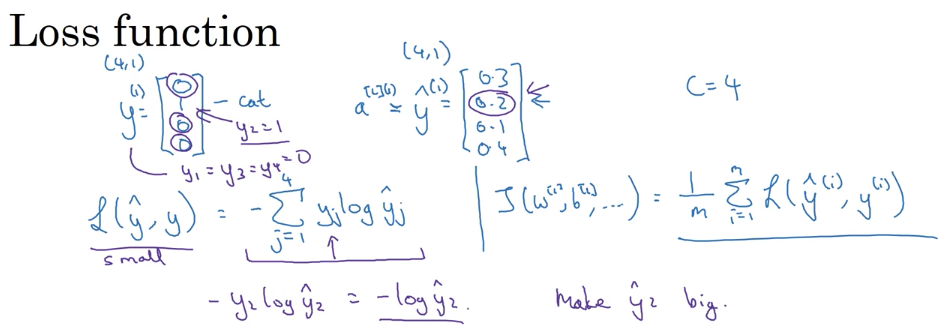
TensorFlow
```python
import numpy as np
import tensorflow as tf
coefficients = np.array([[1], [-20], [25]])
w = tf.Variable([0],dtype=tf.float32)
x = tf.placeholder(tf.float32, [3,1])
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0] # (w-5)**2
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as session:
for i in range(1000):
session.run(train, feed_dict={x:coefficients})
print(session.run(w))
```
Structuring Machine Learning Projects
Chain of assumptions in ML
Orthogonalization
Orthogonalization or orthogonality is a system design property that assures that modifying an instruction or a component of an algorithm will not create or propagate side effects to other components of the system.
It becomes easier to verify the algorithms independently from one another, it reduces testing and development time.
Assumptions
When a supervised learning system is design, these are the 4 assumptions that needs to be true and orthogonal.
- Fit training set well in cost function
If it doesn’t fit well, the use of a bigger neural network or switching to a better optimization algorithm might help.
- Fit development set well on cost function
If it doesn’t fit well, regularization or using bigger training set might help.
- Fit test set well on cost function
If it doesn’t fit well, the use of a bigger development set might help
- Performs well in real world
If it doesn’t perform well, the development test set is not set correctly or the cost function is not evaluating the right thing.
- Performs well in real world
- Fit test set well on cost function
- Fit development set well on cost function
Error Analysis
Carrying out error analysis
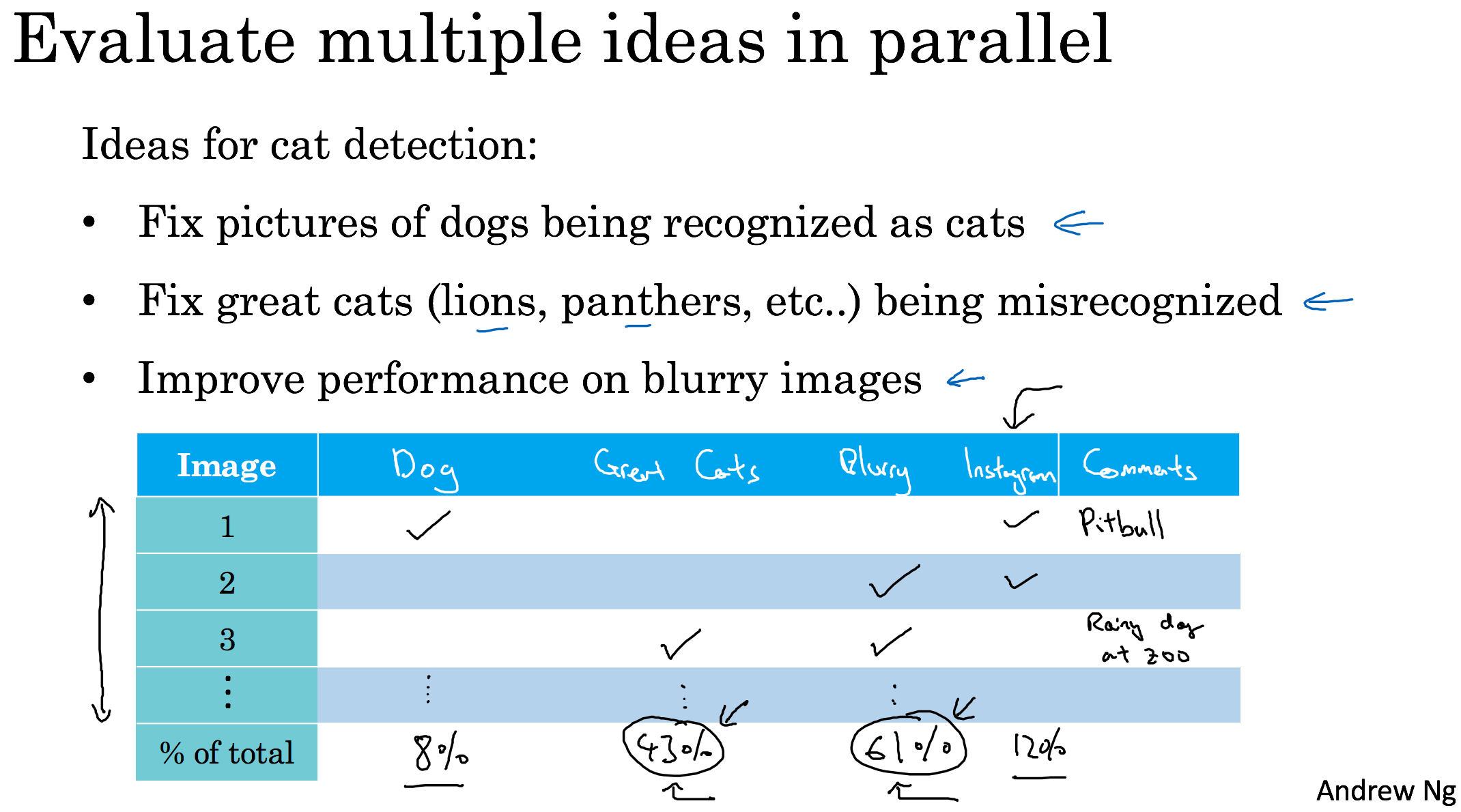
Build your first system quickly, then iterate

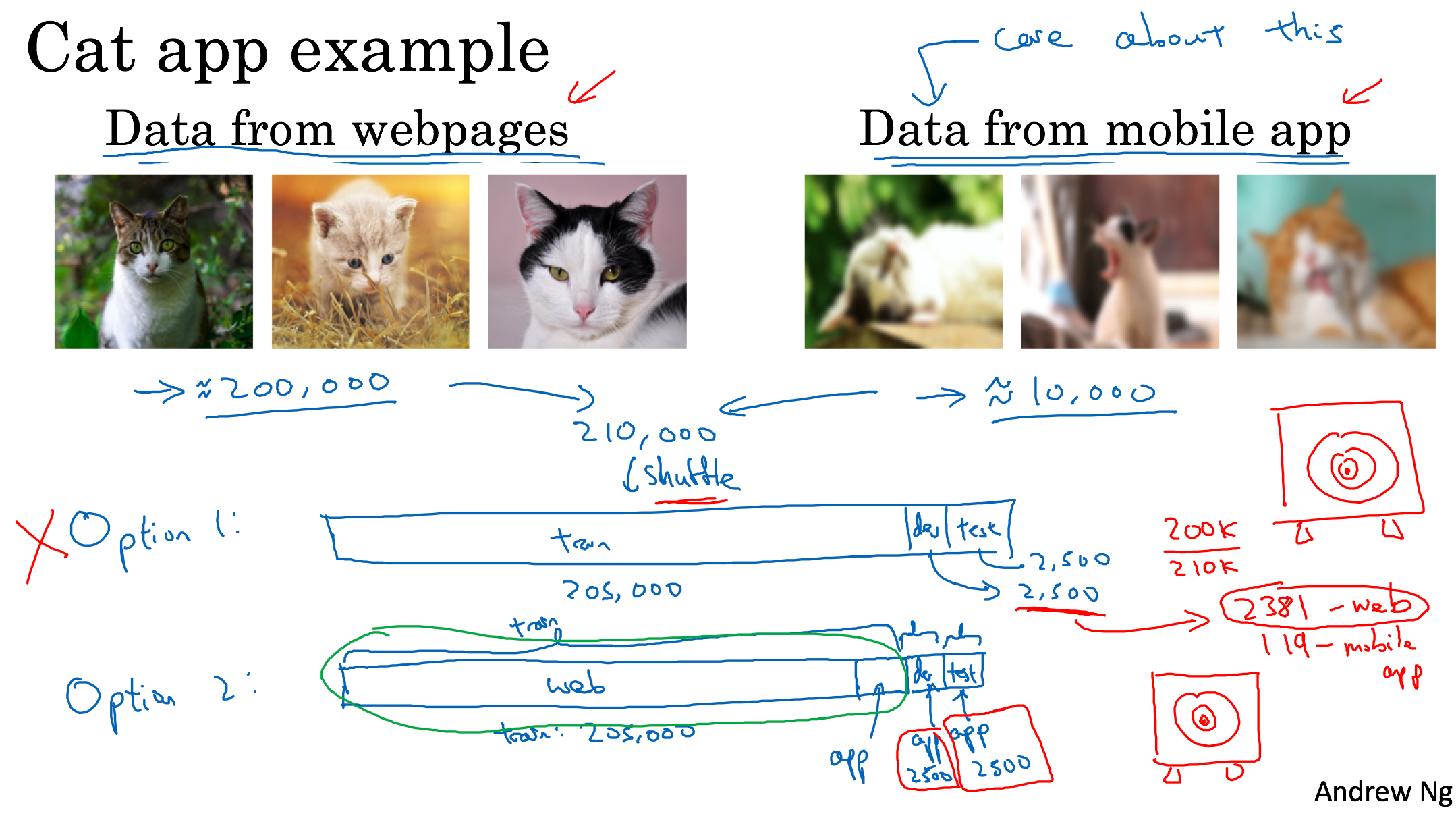
Mismatched training and dev/test data
Training and testing on different distributions
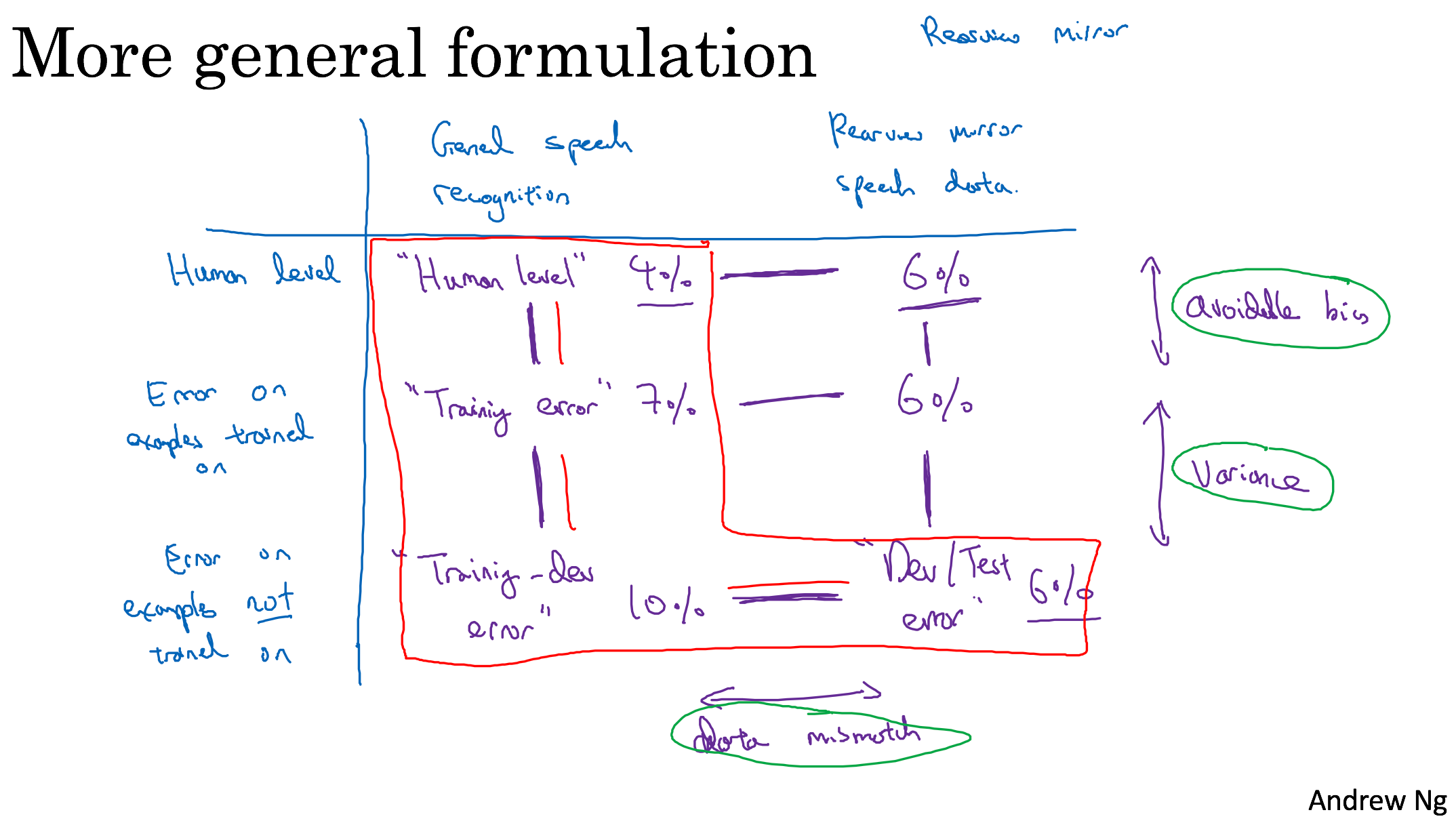
Bias and Variance with mismatched data distributions
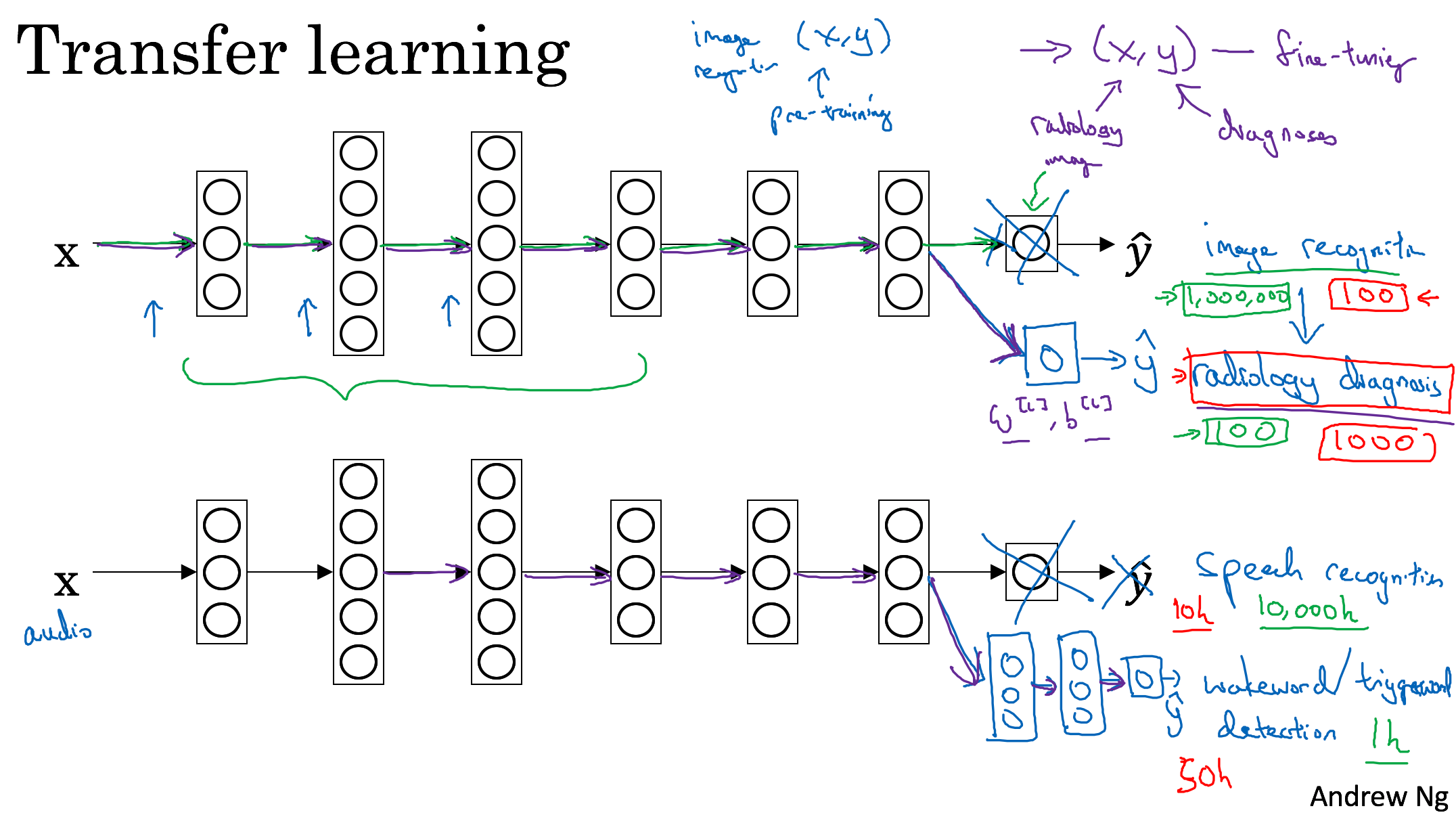
Learning from multiple tasks
Transfer learning

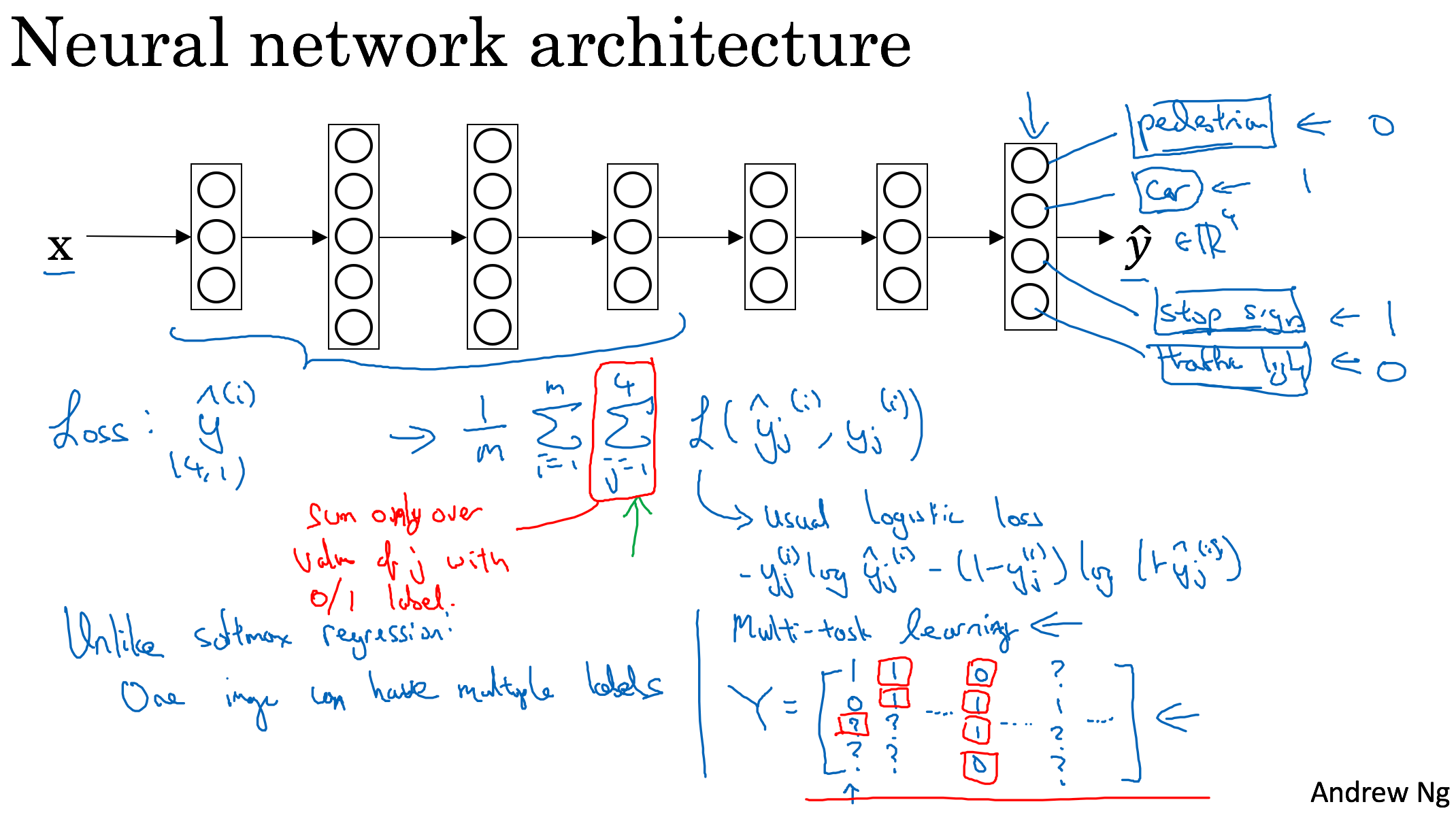
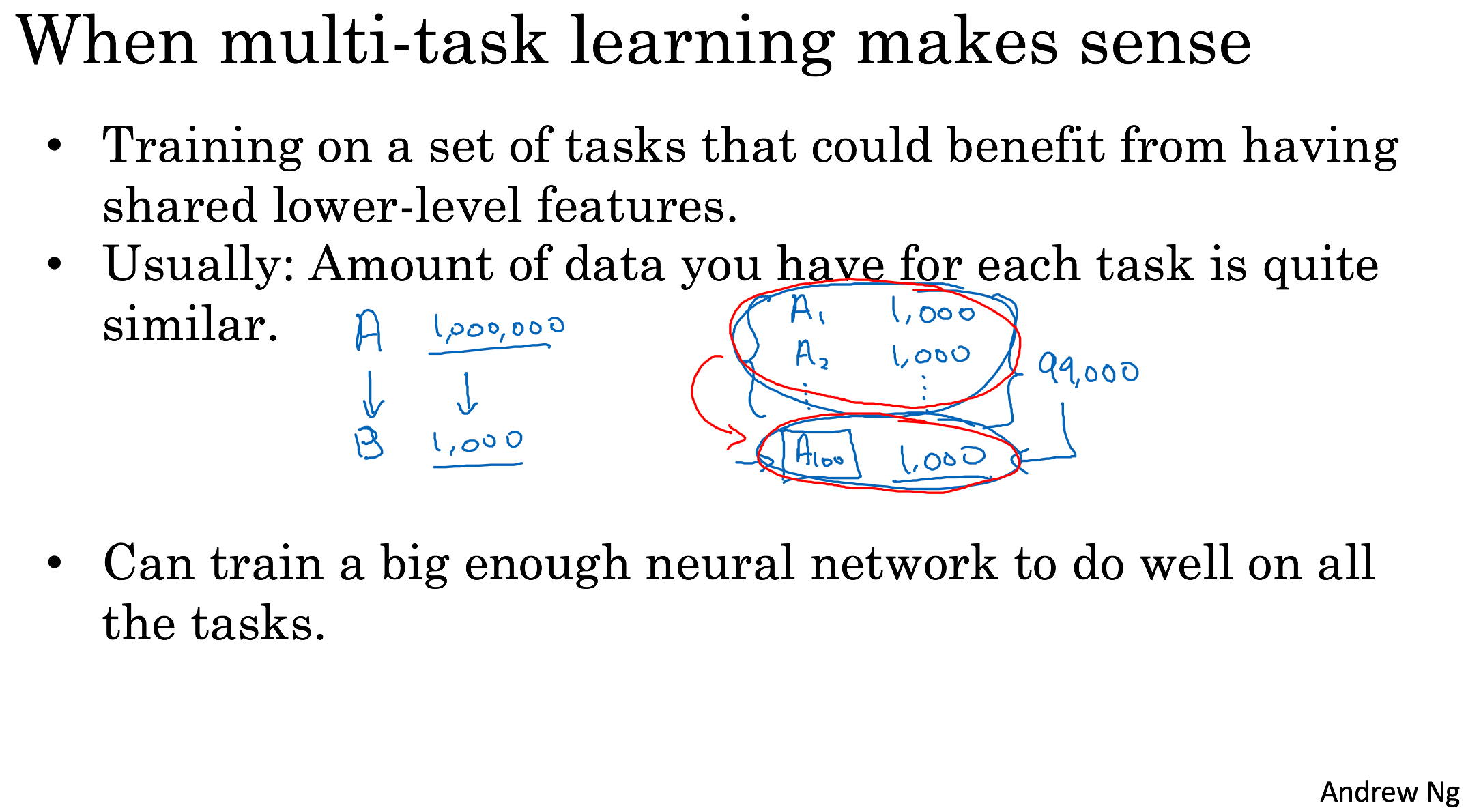
Multi-task learning
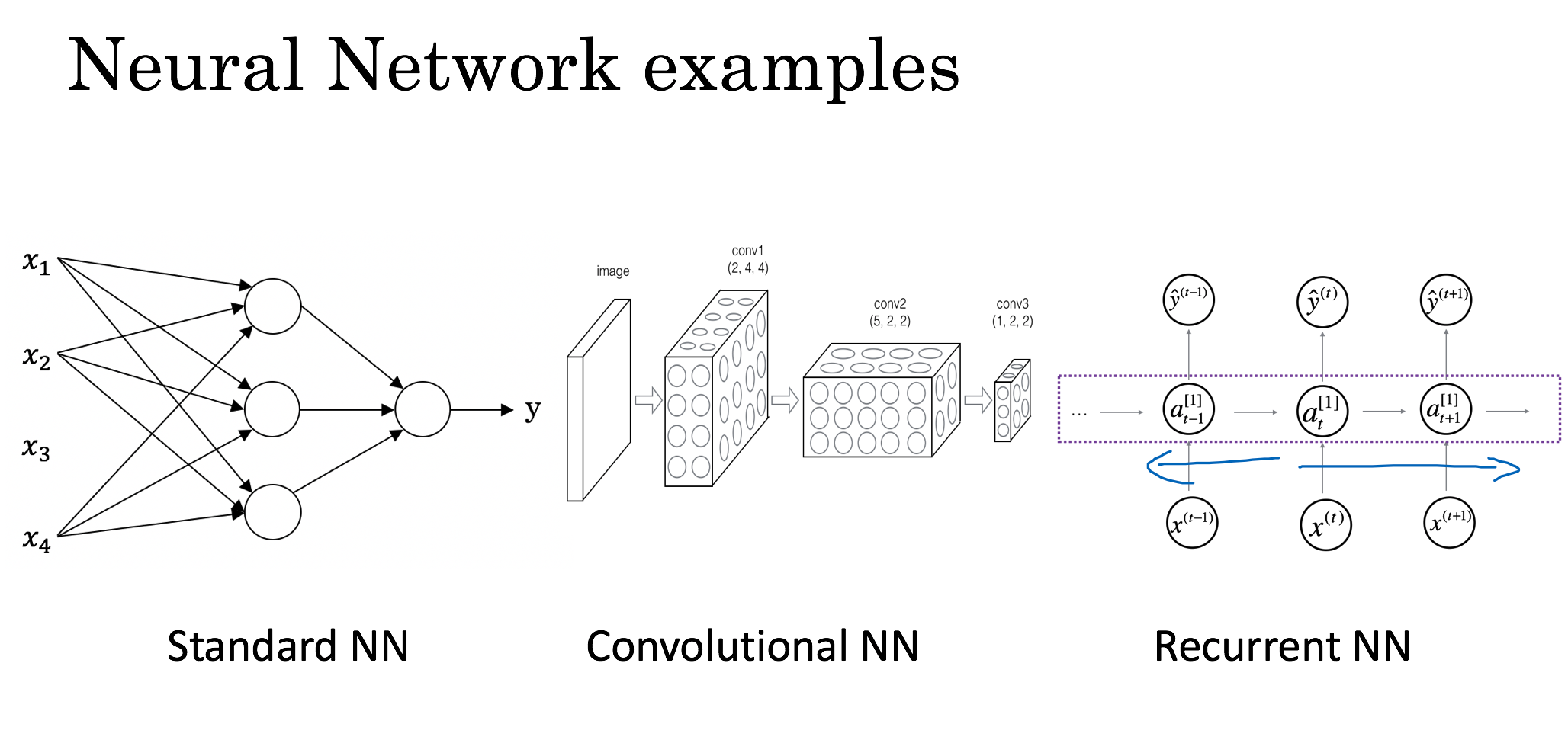
End-to-end deep learning