@Catyee
2021-05-28T14:10:00.000000Z
字数 5546
阅读 752
二叉树算法题
数据结构与算法
一、二叉搜索树
二叉搜索数的一个重要特性:中序遍历是升序的
leetcode 230 二叉搜索树中第k小的数
int result = Integer.MIN_VALUE;int current = 0;public int kthSmallest(TreeNode root, int k) {calKthSmallest(root, k);return result;}public void calKthSmallest(TreeNode root, int k) {if (root == null || result != Integer.MIN_VALUE) {return;}calKthSmallest(root.left, k);if (++current == k) {result = root.val;}calKthSmallest(root.right, k);}
利用中序遍历升序的特点进行遍历,当遍历到第k个节点的时候就是要找的节点,不用再继续遍历了。
leetcode 538 转化累加树
给出二叉搜索树的根节点,该树的节点值各不相同,将该树转化为累加树,使新树的每个节点的新值等于原树中大于或等于node.val的值的和。
TreeNode last = null;public TreeNode convertBST(TreeNode root) {convert(root);return root;}public void convert(TreeNode root) {if (root == null) {return;}convert(root.right);int newVal = root.val;if (last != null) {newVal += last.val;}root.val = newVal;last = root;convert(root.left);}
下图是leetcode中给出的示例:
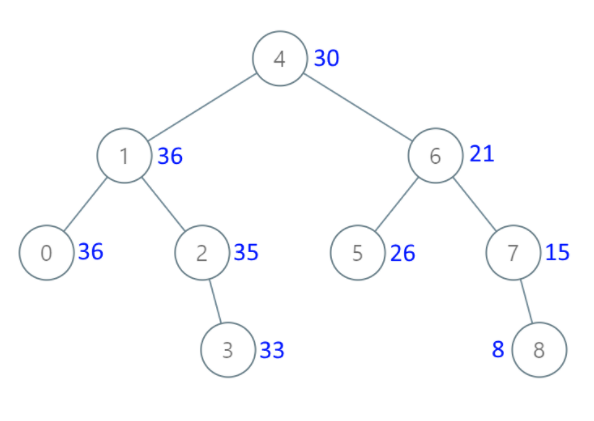
由于要处理每个节点的值,每个节点都要访问到,所以总是要进行树的遍历的,树的遍历就只有前序、中序、后序、层次这四种,不妨把遍历顺序和最终结果都写出来找找规律,这里就只写中序遍历的结果了:
| 节点原值 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 最终值 | 36 | 36 | 35 | 33 | 30 | 26 | 21 | 15 | 8 |
发现了吗?当前节点的最终值是下一个节点的最终值+当前节点的原值,如果我们将中序反过来,也就是说先遍历右子树,然后访问当前节点,再访问左子树,那么当前节点的最终值就是上一个访问的节点的最终值+当前节点的原值,我们只需要一个额外的节点记录上一次访问的节点就可以了。
leetcode 98 验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
二叉搜索树是这样一棵树,如果左子树不为空,则左子树的所有节点的值都小于根节点,如果右子树不为空,则右子树的所有节点都大于根节点,同时左子树和右子树也都是二叉搜索树。
根据题目的意思,我们很可能将代码写成如下的样子:
public boolean isVaildBST(TreeNode root) {if (root == null) {return true;}if (root.left != null && root.left.val >= root.val) {return false;}if (root.right != null && root.right.val <= root.val) {return false;}return isVaildBST(root.left) && isVaildBST(root.right);}
但是要注意!!二叉搜索树的根节点大于所有左子树节点,小于所有右子树节点,并不仅仅是大于左子树的根节点,也不仅仅是小于右子树的根节点。上面这段代码只是比较了根节点和左孩子右孩子的值,这是不够的。比如这样一棵树:
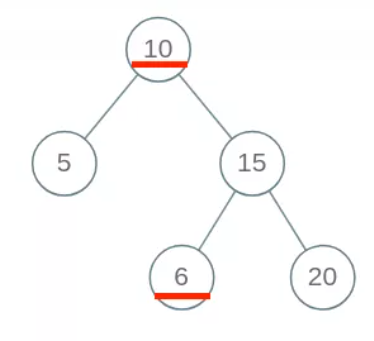
这棵树显然不是一棵二叉搜索树,但是上面的代码将返回true。
正确的做法就是在递归的时候传入子树节点的取值范围来加强约束:
public boolean isVaildBST(TreeNode root) {return isVaildBST(root, null, null);}public boolean isVaildBST(TreeNode root, TreeNode min, TreeNode max) {if (root == null) {return true;}if (min != null && min.val >= root.val) {return false;}if (max != null && max.val <= root.val) {return false;}return isVaildBST(root.left, min, root) && isVaildBST(root.right, root, max);}
leetcode 701 二叉搜索树中的插入操作
二叉搜索树的插入操作是比较简单的,因为最终插入的位置总是叶子节点的位置。
public TreeNode insertIntoBST(TreeNode root, int val) {if (root == null) {return new TreeNode(val);}insert(root, val);return root;}public void insert(TreeNode root, int val) {if (val < root.val) {if (root.left != null) {insert(root.left, val);} else {TreeNode node = new TreeNode(val);root.left = node;}} else if (val > root.val) {if (root.right != null) {insert(root.right, val);} else {TreeNode node = new TreeNode(val);root.right = node;}} else {throw new RuntimeException("unexpect error");}}
leetcode 450 删除二叉搜索树中的节点
删除二叉树的节点要比插入麻烦许多,因为一个节点直接删除之后可能会破坏二叉搜索树的性质,所以要考虑清楚如何删除:
有三种情况:
- 1、待删除节点的左右孩子都为空(也就是叶子节点) ——> 可以直接删除节点
- 2、待删除节点的左右孩子中有一个为空 ——> 删除节点,并用不为空的孩子代替它的位置
- 3、待删除节点的左右孩子都不为空 ——> 删除节点,用左子树的最大值或者右子树的最小值代替它的位置
三种情况分析完了之后我们看"删除节点"这个行为,如果"被删除的节点"有父节点,则需要将父节点原来指向"被删除节点"的指针指向替代它的节点,同时将"被删除节点"的左右孩子置为空,还要保证替代它的节点左右指针的指向也要正确。如果被删除的节点没有父节点,则说明被删除的节点就是根节点。
小技巧:在上面第三种情况中:"删除节点,然后用左子树的最大值或者右子树的最小值代替它的位置"可以进一步简化,这里以左子树的最大值为例,只要把左子树的最大值赋给"待删除的节点",然后删掉左子树最大值所在的节点,由于左子树最大值所在的节点要么是叶子节点,要么是右孩子为空的节点,所以第三种情况转化为了前两种情况。
代码:
/*** deleteNode方法的定义:删除二叉搜索树中的一个节点,然后返回删除之后树的根节点* 要记住这个定义,递归的时候不要陷入递归栈中,而应该把握递归方法的定义,相信这个方法能完成的工作*/public TreeNode deleteNode(TreeNode root, int key) {if (root == null) {return null;}if (key == root.val) { // 相等表示root即使要删除的节点/* 处理左右孩子有空节点的情况,也就是上面列举的前两种情况 */if (root.left == null) {return root.right;}if (root.right == null) {return root.left;}/* 处理左右孩子节点都不为空的情况,也就是上面列举的第三种情况 */TreeNode leftMaxNode = getMaxNode(root.left);// 把左子树的最大值赋给待删除的节点root.val = leftMaxNode.val;// 在左子树中删除左子树最大值所在的节点,相信deleteNode方法的定义,所以返回的是删除之后左子树的根节点,重新连接上root.left = deleteNode(root.left, leftMaxNode.val);} else if (key < root.val) {// 到左子树上去删除,相信deleteNode方法的定义,所以返回的是删除之后左子树的根节点,重新连接上root.left = deleteNode(root.left, key);} else if (key > root.val) {// 到右子树上去删除,相信deleteNode方法的定义,所以返回的是删除之后右子树的根节点,重新连接上root.right = deleteNode(root.right, key);}return root;}private TreeNode getMaxNode(TreeNode root) {while (root.right != null) {root = root.right;}return root;}
这种实现优雅、巧妙,但是如果真实的开发环境,可能每个节点都有着复杂的值,“赋值操作”反而麻烦,进行引用的操作反而简单,下面提供修改引用的方式:
/*** deleteNode方法的定义:删除二叉搜索树中的一个节点,然后返回删除之后树的根节点* 要记住这个定义,递归的时候不要陷入递归栈中,而应该把握递归方法的定义,相信这个方法能完成的工作*/public TreeNode deleteNode(TreeNode root, int key) {if (root == null) {return null;}if (key == root.val) {/* 处理左右孩子有空节点的情况,也就是上面列举的前两种情况 */if (root.left == null) {return root.right;}if (root.right == null) {return root.left;}/* 处理左右孩子节点都不为空的情况,也就是上面列举的第三种情况 */TreeNode leftMaxNode = getMaxNode(root.left);leftMaxNode.left = deleteNode(root.left, leftMaxNode.val);leftMaxNode.right = root.right;root.left = null;root.right = null;// 用左子树最大值所在节点替换要删除的节点,所以返回的也是左子树最大值所在节点return leftMaxNode;} else if (key < root.val) {root.left = deleteNode(root.left, key);} else if (key > root.val) {root.right = deleteNode(root.right, key);}return root;}private TreeNode getMaxNode(TreeNode root) {while (root.right != null) {root = root.right;}return root;}
非递归的实现方式:
private TreeNode parrent = null;private TreeNode node = null;public TreeNode deleteNode(TreeNode root, int key) {findNode(root, key);if (node == null) {return root;}TreeNode current = null;if (node.left != null && node.right != null) {current = findAndDeleteLeftMax(node.left);if (current != node.left) {current.left = node.left;}current.right = node.right;} else {current = node.left == null ? node.right : node.left;}node.left = null;node.right = null;if (parrent == null) {return current;}if (parrent.left == node) {parrent.left = current;}if (parrent.right == node) {parrent.right = current;}return root;}public TreeNode findAndDeleteLeftMax(TreeNode root) {TreeNode last = null;while (root.right != null) {last = root;root = root.right;}if (last != null) {last.right = root.left;root.left = null;}return root;}public void findNode(TreeNode root, int key) {if (root == null || node != null) {return;}if (root.val == key) {node = root;return;}if (key < root.val) {parrent = root;findNode(root.left, key);}if (key > root.val) {parrent = root;findNode(root.right, key);}}
