@Catyee
2021-08-10T06:16:00.000000Z
字数 14839
阅读 765
Spring常见面试题
Spring
其实面试题是其次,更重要的是理解Spring的设计思想和实现细节,这里虽然以面试题的形式写了这篇文章,但目的还是阐释Spring的设计思想和原理,希望对大家有帮助。
一、谈一谈你对spring的认识
Spring是一个为Java应用程序开发提供基础性支持的Java框架,Spring致力于帮助开发者解决开发中一些基础性的问题,让开发者可以更加专注于具体业务的开发,其根本目的是为了简化程序员的开发工作。发展至今,Spring已经成为一个生态体系,打开Spring的官网,会发现有多个Spring的子项目,各个子项目都专注于简化一部分领域的开发工作。这里面最为核心的模块就是spring framework,Spring Framework中包含了一系列IoC容器的设计与实现,同时也集成了AOP功能,这也是Spring为了简化程序开发最为重要的两个策略。IoC即控制反转,控制反转就是指原先需要由程序员自己实现各种类,控制各种对象之间复杂的耦合关系,但是现在IoC容器把对象生命周期和依赖关系的管理从程序员手里接管过来,让程序员能够聚焦具体业务的开发。AOP即面向切面编程,AOP可以减少模板代码的开发,以一种优雅的非侵入式的方式来增强服务的功能,这方面最典型的应用场景是Spring事务管理,Spring的声明式事务使用Aop来实现,使用起来非常简单优雅。
二、什么是控制反转(IoC)、依赖注入(DI)和依赖查找(DL)
控制反转就是指原先需要由程序员自己实现各种类,控制各种对象之间复杂的耦合关系,但是现在IoC容器把对象生命周期和依赖关系的管理从程序员手里接管过来,让程序员能够聚焦具体业务的开发。控制反转其实包含两部分的内容:一是管理对象的生命周期(创建、使用、销毁),二是处理对象之间的依赖关系,依赖注入就是解决对象之间的依赖关系的一种方式,可以认为是控制反转的一种实现策略,依赖注入指的是bean对象实例化完成之后把依赖的对象也都设置完成,当我们使用一个Bean的时候,这个Bean的依赖关系已经是完整的了,在这个Bean中使用某个依赖对象的时候不需要从容器中查找,直接使用即可,这就是依赖注入。
依赖注入之外还有另外一种实现控制反转的策略,也就是依赖查找,依赖查找指的是在创建bean的时候不进行依赖bean的注入,而是在使用Bean的时候如果需要用到某个依赖的bean,此时才去容器中查找这个依赖的bean,这就需要容器提供容器环境和查找bean的方法,而开发者需要手动调用这些方法获取依赖的bean。Spring中依赖查找的实现方式也很简单,我们只要实现ApplicationContextAware接口就可以获取到Spring容器,然后就可以在需要的时候从容器中手动查找Bean。相对于依赖注入,这是一种更加传统的控制反转实现方式,使用起来也更加麻烦,一般只要在Spring环境中我们都可以使用依赖注入而不需要依赖查找,所以依赖查找使用场景非常少,但这并不意味着依赖查找完全没有用武之地了,刚刚说过在spring环境中我们都可以使用依赖注入,但如果想在spring环境之外使用spring容器中的bean,这个时候依赖查找就派上用场了,下面列举了一种在Spring环境之外使用spring容器中bean的方式:
// 实现ApplicationContextAware接口,获取到spring容器,并保存到类的静态属性中@Componentpublic class BeanHubMgr implements ApplicationContextAware {private static ApplicationContext applicationContext;@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {// 将容器保存在静态属性中,可以方便使用BeanHubMgr.applicationContext = applicationContext;}public static ApplicationContext getApplicationContext() {return applicationContext;}// 根据类型获取beanpublic static <T> T getBean(Class<T> className) {return applicationContext.getBean(className);}}// 这是一个普通的java对象,并不受spring管理,也就是说这个类的对象在spring环境之外// 如果我们想要使用Spring容器里的bean,就可以通过BeanHubMgr中保存的容器来查找bean,也就是依赖查找public class BusinessExample {public void besiness() {BeanA beanA = BeanHubMgr.getBean(BeanA.class)...}}
三、Spring Bean的生命周期
3.1 什么是spring bean
首先要弄清楚Spring Bean和普通Java对象在概念上的区别:
- POJO:plian ordinary java object, 即简单java对象,除了属性的get、set方法以及toString、hashcode、equals等简单的方法,没有其它方法
- Spring Bean:由Spring管理生命周期的java对象,bean也是对象,只不过由Spring创建并管理,bean可能有复杂的业务,这一点和POJO不一样。
3.2 bean的类型
Spring的bean可以配置scope,根据scope可以划分为不同类型的bean, Spring的bean类型也是一个不断发展的过程,在Spring 5.3.7版本中有如下这些scope:
- singleton:单例bean,对应设计模式中的单例模式(注册式单例),对于单例bean,Spring只会进行一次创建,创建完之后就会缓存起来,以后每次使用都从缓存中获取,这是Spring默认的scope,也是使用最多的方式。
- prototype:原型bean,对应设计模式中的原型模式,Spring每次调用getBean()方法的时候都会创建一个新的bean对象。原型模式指的是依照一个原型来创建一个新的对象,一般设计模式中的原型模式要求原型对象实现clone方法,clone的时候又要注意深克隆和浅克隆的问题,一般来说使用clone方法由于不需要通过构造器就可以构建一个新的对象,所以效率要更高。不过Spring并不需要原型bean实现clone方法,因为其底层并不是通过clone方法来创建新的bean,创建原型bean和创建单例bean调用的是同样的方法(AbstractBeanFactory类中的createBean方法,这个方法在doGetBean方法中调用),不同的是单例bean只会调用一次进行创建,创建完就缓存,而原型bean每次都会重复调用这个方法,每次都创建一个新的bean,所以原型bean和一般而言的原型模式是有些区别的,不过原型模式只是一种设计模式,设计模式是一种指导思想,并没有确定的代码实现规范,只要符合其设计思想就可以称之为原型模式,所以原型bean依然是原型模式的体现,我们可以将BeanDefinition视为bean的原型。
- request:每一次HTTP请求都会产生一个新的bean,这个bean只能在当前的请求中使用,请求结束之后这个bean的生命周期也就结束了
- session:在一个http session的生命周期中只会创建一个bean,这个bean只能在这个session中使用,session结束bean的生命周期也就结束了
- application:在一个ServletContext的生命周期中只会创建一个bean
- websocket:在一个WebSocket的生命周期中只会创建一个bean
request,session,application和websocket只能在web应用上下文中才可以使用,比如WebApplicationContext。
在spring的官网可以找到这些描述:Spring 5.3.7官方文档对bean scope的描述
3.3 单例bean的生命周期
Spring框架最终都是围绕Spring Bean展开的,我们知道Spring被称为容器,容器从字面上理解就是装东西的器皿,那Spring装了什么东西呢?答案就是Bean,Spring会全面接管Bean的创建、使用和销毁的过程,这就是Bean的生命周期,这也是控制反转思想的具体体现。所以bean的生命周期可以说就是Spring最为核心的部分,尤其是bean创建和销毁的过程,当面试官问到spring的生命周期的时候,不仅仅是为了考验面试者对bean创建、销毁各个阶段的熟悉程度,更重要的是考验面试者对spring的理解,以及是否看过Spring的源码。
但bean的生命周期也是颇为复杂的一部分,所以这里用一个单独的篇章来讲解。详见:
源码解析Spring Bean的生命周期
三、Spring中有哪些Bean注入的方式
Spring Bean本质上就是由Spring容器管理的java对象,bean之间的依赖关系实际就是对象之间的引用关系,我们说A依赖B,实际上是指A中的一个属性保持了对B的引用,所以Bean的依赖注入本质上就是java对象属性的填充。在java对象中我们要怎么填充一个属性呢?一种是在构造方法中设置,另外一种是先把对象实例化出来,然后通过属性的set方法设置,Spring bean作为java对象自然也逃不出这两种方式,Spring中有构造器注入和set方法注入两种依赖注入方式,这两种依赖注入方式分别与java对象填充属性的两种方式对应。
构造器注入和set方法注入这两种依赖注入都有多种使用方式,我们可以通过注解或者xml配置文件来自动注入,也可以通过xml配置文件来手动注入,还可以将自动注入和手动注入混用,注意这里所谓自动注入指的是IoC容器自己判断需要注入哪些Bean,而手动注入指的是由开发者在配置文件中显示指定注入哪些Bean。
上面提到的构造器注入和set方法注入都是一次性的,一旦注入完成,被注入的bean一般不会再变,应对的是一个单例bean依赖其它单例bean的场景,也是最常见的场景。但假如依赖的bean是原型模式,我们本意是每次都使用一个不同的bean,但现在每次使用的都是同一个bean,这就失去了原型模式的意义,那么怎么办呢?一种方式是我们每次使用这个bean的时候都重新从容器中获取,实际上就是依赖查找。另外一种方式就是使用Spring提供的方法注入,方法注入又分为查找方法注入和替代方法注入。
所以Spring从大的分类来看有依赖注入和方法注入两种,依赖注入又分为构造器注入和set方法注入,方法注入又分为查找方法注入和替代方法注入。
3.1 依赖注入
spring的依赖注入分为构造器注入和set方法注入,网上有人还提到接口注入,其实就依赖注入这项技术本身而言确实是有构造器注入、set方法注入和接口注入这三种常用的依赖注入方式,但是查看Spring的文档,会发现Spring只提到了构造器注入和set方法注入,没有提及接口注入,所以Spring是不支持接口注入这种方式的。另外在Spring by Example网站中有明确提到spring暂不支持接口注入,虽然这个网站已经很久没更新了,但是可以稍作参考:
This is not implemented in Spring currently, but by Avalon. It’s a different type of DI that involves mapping items to inject to specific interfaces.
地址:[Spring官网对于接口注入的描述]
依据此理由,我们认为Spring的依赖注入只有构造器注入和set方法注入两种方式。
3.1.1 构造器注入
构造器注入有多种使用方式:使用注解的自动注入,以及使用xml配置文件的自动注入和手动注入,下面分别进行讲解:
a. 在构造器上加@Autowired注解来进行自动注入
@Componentpublic class BeanExample {// 注意final关键字private final BeanA beanA;@Autowiredpublic BeanExample(BeanA beanA) {this.beanA = beanA;}}
上面的示例即通过注解的构造器注入,在构造函数上添加@Autowired的注解来让spring使用指定的构造器,在spring5之前的版本如果不指定@Autowired注解spring默认会使用无参构造器,但是Spring5即以后的版本甚至可以省略构造器上面的@Autowired注解,Spring可以推断构造器来完成注入。通过@Autowired注解的构造器注入也是Spring官方推荐的方式,原因就在于注入的Bean可以声明为final,这样bean的引用不会被更改,并且确保注入的依赖对象不为空,相对而言是更加安全的。
当然通过注解的构造器注入也是会有缺陷的,主要是以下两点:
- 1、要注入的对象过多,构造器就会显得很臃肿
- 2、可能出现循环依赖(启动的时候就会发现)
所以也要根据实际情况进行选择。
b. 在xml配置文件中指定autowire属性为constructor进行自动注入
<bean id="beanExample" class="com.catyee.spring.example.BeanExample" autowire="constructor"/>
以上就是一个通过xml配置文件的构造器注入方式,配置文件中配置了autowire的属性,也就是自动注入的方式。这个autowire属性有多个值可以选则:
- constructor
- byType
- byName
- no
- default
只有指定constructor的时候才是构造器注入,spring会根据构造器方法中的参数类型去寻找bean,如果找到多个会根据参数名进行确定。这种方式不需要bean有set方法。
如果指定byName或者byType则是通过set方法进行自动注入,这种方式要求这个bean有一个无参的构造器,并且要有set方法,原因也很简单,spring需要知道set方法的信息,所以一定要有set方法。实际上Spring会去解析当前类把所有方法都解析出来,得到对应的PropertyDescriptor对象,注意PropertyDescriptor并不是Spring中的类,而是java.beans包下类,也就是jdk自带的类,PropertyDescriptor中有几个属性:
- 1、name:这个name并不是方法的名字,而是拿方法名字进过处理后的名字
a. 如果方法名字以“get”开头,比如“getXXX”,那么name=XXX
b. 如果方法名字以“is”开头,比如“isXXX”,那么name=XXX
c. 如果方法名字以“set”开头,比如“setXXX”,那么name=XXX - 2、readMethodRef:表示get方法的Method对象的引用
- 3、readMethodName:表示get方法的名字
- 4、writeMethodRef:表示set方法的Method对象的引用
- 5、writeMethodName:表示set方法的名字
- 6、propertyTypeRef:如果有get方法那么对应的就是返回值的类型,如果是set方法那么对应的就是set方法中唯一参数的类型
spring先通过无参构造器进行实例化,然后通过set方法解析依赖的bean的名称,如果是byName则直接根据解析出来的名称去获取bean,如果是byType则是根据解析出来的名称获取到PropertyDescriptor对象,通过PropertyDescriptor对象获取到set方法中参数的类型,再根据类型去容器中获取bean,如果找到多个bean,会直接报错。
如果指定为no,则表示关闭autowire。
default则要和beans标签上的autowire属性配合使用,autowire属性除了可以用在bean标签上,也可以用在beans标签上,如果bean标签中autowire属性指定的是default,代表这个bean将会使用上层beans标签上设置的autowire值,举例:
<beans ... default-autowire="byType"><bean id="beanExample" class="com.catyee.spring.example.BeanExample" autowire="default"/></beans>
上面就是一个使用default的示例。
c. 在xml配置文件中通过constructor-arg标签指定构造器的参数进行手动注入
<bean name="beanExample" class="com.catyee.spring.example.BeanExample"><constructor-arg index="0" ref="beanA"/><constructor-arg type="username" value="user1"/><constructor-arg name="java.lang.String" value="pass1"/></bean>
上面仍然是一个通过xml配置文件的构造器注入,但是配置文件中没有配置autowire属性,而是手动指定了构造器的参数,所以是一种手动注入的方式。指定参数时,可以使用参数在方法中的位置(index),也可以使用参数的type或者参数的name,这三种方式可以混合使用,但目的是为了让spring找到合适的构造器,如果有多个构造器,配置文件中参数的数量和顺序将作为spring选择构造器的依据。
3.1.2 Set方法注入
set方法注入也有多种使用方式:通过@Autowired注解自动注入,通过xml自动注入或者手动注入。
a. 通过@Autowired注解自动注入
我们可以将@Autowired注解直接加在属性或者set方法上进行自动注入。
// 将@Autowired注解直接加在set方法上@Componentpulic class BeanExample {private BeanA beanA;@Autowiredpublic void setBeanA(BeanA beanA) {this.beanA = beanA;}}
如上,将@Autowired注解放在set方法上即通过注解的set方法注入。这种方式中,Spring先根据set方法的参数的类型去容器中找依赖的bean,如果找到多个,再根据参数名称确定一个,确定bean之后是通过Method的invoke方法这种反射方式(也就是通过反射调用了set方法)来完成注入的。
这种方式不强制要求类有一个无参构造器,但是如果没有无参构造器,而又有其它有参构造器,spring就会使用有参构造器,如果有参构造器中的参数没有注入就会实例化bean失败。所以还是要清楚背后的原理,这样才能知道如何使用才是正确且符合自己需求的。
在实际开发中,我们经常将@Autowired注解放到属性上,而不是set方法上,如下:
// 将@Autowired注解直接加在属性上@Componentpulic class BeanExample {@Autowiredprivate BeanA beanA;}
其实这种方式已经不属于set方法注入了,将@Autowired注解放到属性上,Spring先根据属性类型去容器中找依赖的bean,如果找到多个,再根据bean的名称确定一个,确定bean之后是通过Filed的set(Object obj, Object value)方法这种反射方式(也就是通过反射直接给属性设置值)来完成注入的,根本不需要调用bean的set方法,所以也不需要这个bean有set方法,既然不是通过bean的set方法来设置值,自然也不能称为set方法注入了。这种方式其实既不属于构造器注入,也不属于set方法注入,所以如果要起一个名字,我愿意称之为"属性注入(Filed injection)",但spring官方没有这样称呼过,所以还是不要使用这样一个概念,只要理解背后的原理就可以了。
为什么加上一个@AutoWired注解就可以完成依赖注入?
加上@Autowired注解实际是显示告诉spring这是一个注入点,spring启动的时候通过AutowiredAnnotationBeanPostProcessor的postProcessMergedBeanDefinition()方法找出注入点,这些注入点包括放在属性上或方法上的@Autowired注解,spring找出这些注入点之后会放入到缓存中(Set<InjectedElement>),之后Spring在AutowiredAnnotationBeanPostProcessor的postProcessProperties()方法中遍历Set&It;InjectedElement>中的注入点进行注入,@Autowired没有byType或者byName的说法,@Autowired先是按照类型去容器找Bean,如果找到多个,会再按照名称来进行唯一确定,但不能说是byType和byName的结合,byType和byName是xml配置时候autowire属性的选项值,但不是@Autowired的实现原理。
b. 在xml配置文件中指定autowire属性为byType或byName进行自动注入
<bean id="beanExample" class="com.catyee.spring.example.BeanExample" autowire="byType"/>
上面有提到xml配置文件中,如果设置autowire属性的值为byType或者byName,则是set方法注入,要求这个类有无参构造器和set方法。
c. 在xml配置文件中通过property标签指定属性值进行手动注入
<bean name="beanExample" class="com.catyee.spring.example.BeanExample"><property name="beanATest" ref="beanA"/></bean>
在XML中定义Bean时,直接通过property标签指定属性的值,这是一种手动注入的方式,因为是开发者手动给某个属性指定了值。这种方式也是通过set方法注入的,所以也要求这个类有无参构造器和set方法。
3.1.3 依赖注入的接口注入方式
之前提到过就依赖注入这项技术本身而言是有三种最为普遍的方式的,除了构造器注入和set方法注入之外,还有一种方式是接口注入,但是Spring官方文档只提到了构造器注入和set方法注入,没有提及接口注入,所以我们认为Spring是不支持接口注入方式的(至少是不推荐的)。但是这里还是稍微提一下这种方式:
所谓接口注入就是说依赖的并不是某一个确定的对象,而是一个接口,这个接口可能有多种实现,容器会根据情况注入不同实现的对象。举例:
// 接口public interface TestInterface {void print();}// 接口实现1public class TestA implements TestInterface {@Overridepublic void print() {System.out.println("this is testA");}}// 接口实现2public class TestB implements TestInterface {@Overridepublic void print() {System.out.println("this is testB");}}public class Example {// 这个方法依赖了TestInterface接口,接口有两种实现,容器会根据情况自动注入某一种实现// 通常容器会有某种机制来让用户设置什么情况注入什么实现public void print(TestInterface bean) {bean.print();}}
3.2 方法注入
假如一个Bean是单例bean,这个单例bean依赖一个原型bean,如果我们使用构造器注入或者set方法注入的方式来注入原型bean,一旦注入结束,实际上单例bean中依赖的原型bean是不会再改变的,这与我们的期望不符合,因为我们使用原型bean就是想每次都使用一个新的bean,要解决这个问题有两种方式,第一种可以获取容器上下文,每次需要使用原型bean的时候都通过容器上下文获取bean,这实际上是依赖查找。第二种方式就是使用spring的方法注入,方法注入又分为两种,一种是查找方法注入,通过@Lookup注解或xml配置中的lookup-method标签来使用;另外一种是替代方法注入,通过xml配置中的replace-method标签来使用。
3.2.1 查找方法注入
查找方法注入可以通过使用@Lookup注解或xml配置中的lookup-method标签来使用,这里以@Looup注解为例,下面这段代码中ClassA是单例bean,而ClassB是原型bean。
@Componentpublic class ClassA {public void printClass() {// 每次使用classB都要调用被@Lookup标注的方法ClassB classB = getClassB();...}@Lookuppublic ClassB getClassB() {return null;}}
@Lookup注解是作用在方法上的,被其标注的方法会被重写,每次调用这个方法的时候spring都会根据方法返回值的类型去容器中获取bean,如果这个bean是原型模式的,每次返回的bean都不一样。
被@Lookup标注的方法要满足如下的签名格式:
<public|protected> [abstract] <return-type> theMethodName(no-arguments);
如果使用xml配置的方式,可以使用lookup-method的标签,作用是一样的。
个人觉得虽然名字叫做查找方法注入,但依然是一种依赖查找的实现。
3.2.2 替代方法注入
替代方法注入要使用xml配置中的replace-method标签,没有对应的注解。替代方法注入顾名思义就是对bean的某个方法实现进行替代,需要bean实现MethodReplacer:
public class MyReplacer implements MethodReplacer {@Overridepublic Object reimplement(Object obj, Method method, Object[] args) throws Throwable {System.out.println("替代"+obj+"中的方法,方法名称:" + method.getName());System.out.println("执行新方法中的逻辑");return null;}}
注意替代方法注入的作用是完全替代一个方法的实现,而不能试图调用原有的方法,上面这段代码,在reimplement()方法中如果尝试使用method.invoke(obj, args)的方式调用原方法会陷入死循环。所以说替代方法注入不是AOP,不能用于增强一个方法,而是原有方法的完全替代,这种使用场景非常少。
四、Spring中bean的循环依赖
所谓循环依赖是指两个或两个以上的bean互相引用对方,最终形成了一个依赖的闭环。
Spring接管了bean的全生命周期,bean之间的依赖关系又是多种多样的,从理论来说总是有可能出现循环依赖的情况,所以循环依赖是Spring创建Bean中必须要面对的一环。同时开发者要认识到代码中出现循环依赖并不代表着代码有问题,开发者可以尽量避免,但如果遇到某些情况实在避免不了也没关系,Spring能自动处理循环依赖的大部分情况,只有一些特殊的情况无法处理,只要合理使用Spring即使有循环依赖也可以正常运行,关键就在于开发者要弄清楚哪些循环依赖的情况是spring能够自动处理,哪些情况是spring无法自动处理的。
spring中处理循环依赖依然是比较复杂的一部分,所以也使用一个单独的章节来讲解:
源码解析Spring循环依赖
五、BeanFactory和ApplicationContext的区别
BeanFactory是Spring IOC容器的顶层接口,BeanFactory定义了容器应该具有的基础行为,为Spring管理Bean提供了一套通用的、基础的规范,可以认为实现了BeanFactory的类就是Spring容器。
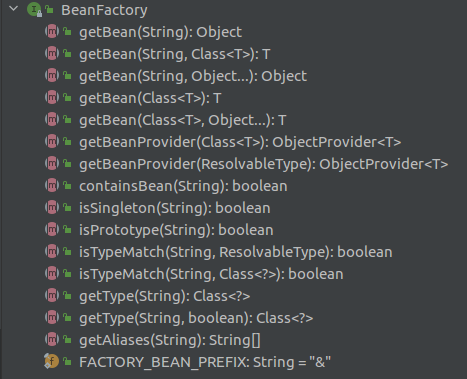
从上面的图也可以看到BeanFactory接口中定义的方法并不多,基本都是最最基础的,但是Spring是复杂的,如果想扩展容器的功能,就需要继承或组合BeanFactory接口。
ApplicationContext就是这样一个继承了BeanFactory的接口,并且组合了一些其它的接口,所以ApplicationContext接口扩展了容器的行为,我们称实现了BeanFactory接口的类为容器,实现ApplicationContext也就实现了BeanFactory接口,所以实现ApplicationContext的类也是容器,只是这个容器会具有更多的行为,使用起来会更加方便。

从上图可以看到ApplicationContext的继承关系,由于组合了ApplicationEventPublisher接口,ApplicationContext具有了发布事件的能力;由于组合了ResourcePatternResolver接口,ApplicationContext具有了加载资源的能力,诸如此类的扩展,让ApplicationContext具有更多样的功能。
一个正在运行的spring应用只会有一个容器,但是jvm中可以同时有beanFactory和aplicationContext对象,这是不矛盾的,这种情况下beanFactory对象是aplicationContext对象的一个属性,相当于aplicationContext对象静态代理了beanFactory对象,这属于实现上的细节。我们知道BeanFactoryAware和ApplicationContextAware接口可以让我们获取到BeanFaxtory对象和ApplicationContext对象,正因为jvm中可以同时有beanFactory和aplicationContext对象,所以我们也可以在一个bean上同时实现BeanFactoryAware和ApplicationContextAware接口,虽然这么做没有意义。
六、BeanFactory和FactoryBean的区别
BeanFactory:我们都比较熟悉BeanFactory,BeanFactory是Spring IOC容器的顶层接口,BeanFactory为Spring管理Bean提供了一套通用的规范。可以认为实现了BeanFactory的类就是Spring容器。
FactoryBean可能就要陌生多了,FactoryBean也是一个接口,看源码:
public interface FactoryBean<T> {String OBJECT_TYPE_ATTRIBUTE = "factoryBeanObjectType";// 返回这个FactoryBean所创建的对象。@NullableT getObject() throws Exception;// 返回这个FactoryBean所创建的对象的类型@NullableClass<?> getObjectType();// FactoryBean所创建的对象是否为单例default boolean isSingleton() {return true;}}
可以看到FactoryBean只有3个接口方法,从接口来看FactoryBean也是用来创建bean的,确实如此,FactoryBean用来定制化Bean的创建逻辑,但是Spring已经有了用xml配置文件或者主键来定义bean的方式,为什么还需要FactoryBean呢?其实在Spring早期,只有通过xml的方式来配置bean,但如果这个bean是一个复杂的bean,可能需要大量的配置信息,直接使用代码创建会更加简单,这就需要一个能够往spring容器中注册普通java对象,并使普通java对象成为可以被spring管理的bean的方式,FactoryBean应运而生。所以在Spring早期,当一个Bean属性很多,实例化复杂的时候,使用FactoryBean是很必要的,这样可以规避我们去使用冗长的XML配置。不过后来Spring推出了注解的方式,使用注解也可以以编码的方式来定义复杂的bean,而且比FactoryBean更加方便。其实使用FactoryBean的最主要的一个理由就是规避xml配置文件中复杂的配置,规避的方式就是把复杂的实例化流程或初始化流程在代码中实现,但按照这个思路其实还有更多的规避方式,比如使用InitializingBean,在afterProperties方法中来对bean进行初始化等等。所以现在用到FactoryBean的场景已经非常少了,不过Spring本身仍然有很多bean是通过FactoryBean创建的,此外还有一个典型的例子,就是mybatis整合spring的SqlSessionFactoryBean类:
<!-- spring和MyBatis整合, SqlSessionFactoryBean本身很复杂,但是SqlSessionFactoryBean实现了FactoryBean,在代码中实现了复杂的实例化流程,规避了很多复杂的配置,可以看到xml中只有少量的配置--><bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="dataSource"/><!-- 自动扫描mapping.xml文件 --><property name="mapperLocations" value="classpath:mapper/*.xml"></property></bean>
FactoryBean有另外一个作用,那就是把一个已经创建好的对象交给Spring容器管理,在getObject方法中返回已经创建好的对象就可以了;但是这个功能还可以通过@Bean注解来实现,通过@Bean注解标注的方法直接返回已经创建好的对象,Spring容器就会管理这个对象。@Bean注解进一步压缩了FactoryBean的使用空间。
关于FactoryBean还有一个要注意的点:
通过FactoryBean的name从容器中获取的实际上是FactoryBean的getObject方法返回的对象,而不是FactoryBean本身,如果要获取FactoryBean对象,需要在name前面加一个&符号。
举个例子:假如定义了一个FactoryBean,名为myFactoryBean,当我们调用getBean("myFactoryBean")方法时返回的并不是这个FactoryBean对象,而是这个FactoryBean中getObject方法返回的对象,如果我们想获取到这个FactoryBean对象本身就这样调用:getBean("&myFactoryBean")
总结:
FactoryBean是Spring中一种特殊的Bean,主要有两个作用,一是定制化bean的创建逻辑,从而规避xml配置文件中复杂的配置;另外一个作用是把一个已经创建好的对象交给spring容器管理,但是这两个功能都有更好的替换方式,所以使用FactoryBean的机会比较少。
