@zhangnian88123
2016-09-26T09:14:14.000000Z
字数 1388
阅读 2709
数据库设计思路和要点
架构 设计 数据库 MySQL
基本概念
- 单库
分片
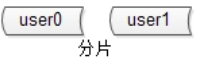
解决单个数据表数据量太大的问题,将单个表的数据均匀的放入多个表中
复制
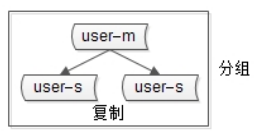
用于实现主从同步,主库的更新操作(insert/update/delete)向从库(1个或多个)进行同步,同步成功完成后主库和从库的数据是一致的,但是在同步过程的时间窗口内,主从数据是不一致的。
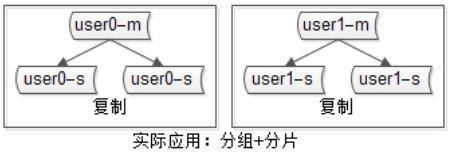
分片 + 分组
路由
根据userid或PK将SQL请求路由至正确的分片实例中,常见的路由策略有:
- 号段
算法:比如[1, 1kw]为一个分片,[1kw,2kw]为一个分片。
优点:实现简单,数据分布均匀
缺点:请求可能不均匀,比如有些业务场景下新增的用户请求量更大。 - Hash
算法:Hash(userid) % 分片个数
优点:实现简单,数据分布均匀,请求分布均匀
缺点:新增分片需要迁移数据,可采用一致性Hash减少需要迁移的数据量
- 号段
可用性
读高可用
解决办法::
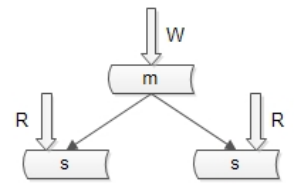
互联网应用的特点是绝大部分请求都是读请求,通过一主多从、冗余从库、读写分离的方式,通过增加从库数量,可以有效的提升读请求的性能和可靠性。主库只处理写请求,从库处理读请求。
存在问题:
- 写库是单点,无法保障高可用
- 主从同步需要时间,在这段同步的时间窗口内,读请求可能会读到旧数据
写高可用
解决办法一:双主
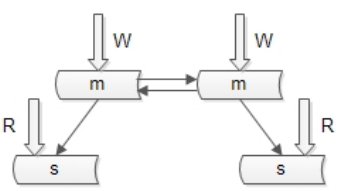
通过冗余写库的方式实现写库的高可用,写库之间进行数据复制:
缺点:
1. 多个写库之间的同步容易出现冲突,从而导致同步失败或数据不一致,一般比较少采用这种方式。
解决办法二:主主同步 + Virtual IP
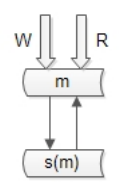
通过VIP的方式,正常情况下读写都在其中一个主库上,同时主库向另一台备用主库同步数据,当这台主库宕机后,VIP浮动到备用主库,备用主库处理后续的读写请求。
优点:
1. 对应用层透明,应用层只需通过VIP访问数据库即可
2. 故障自动切换,当检测到主库故障时,VIP会自动浮动到备用主库上
缺点:
1. 资源利用率只有50%
2. 读写流量都落在主库上,没有通过从库的方式提高读性能
读高性能
解决办法一:冗余从库、读写分离
解决办法二:缓存
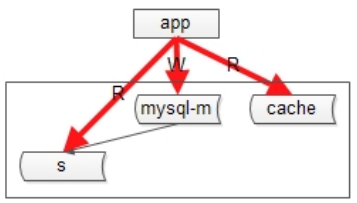
引入Cache后应用层的读写流程变为:
读流程:
1. 读Cache
2. 成功读到数据后直接返回,Cache Miss则读DB
3. 用从DB读到的数据去更新Cache
写流程:
1. 淘汰Cache
2. 更新DB
注意,这里在极端情况下,会出现读写一致性问题:写请求淘汰了Cache,但是还未更新DB成功,这时另一个读请求到来,读请求读Cache时Miss,从而去DB加载数据,而此时的数据还是旧数据,因为写流程中更新DB那一步骤还未完成,所以此时读请求读到的是旧数据,并且将旧数据也放入了Cache中,导致后续所有的读请求都读到旧数据,直到下一次写请求到来。
解决这个问题的办法有两种:
1. 为每个缓存项设置过期时间,过期时间到达之后该缓存项会失效,从而导致读请求穿透到DB,从而强制去DB加载一次最新数据。
2. 在写流程中增异步淘汰缓存的流程(双淘汰):
写流程变为:
1. 淘汰Cache
2. 更新DB
3. 异步淘汰Cache,比如:利用定时器或定时队列,在60s后主动淘汰Cache,导致读请求穿透到DB去强制加载一次最新数据
读写一致性
使用一主多从架构时,由于主从同步需要一段时间开销,因此在这段时间窗口内数据会不一致性,表现出来的现象就是应用层读不到刚才写入的数据。
解决办法:强制读主
引入一个数据访问中间件,将主从同步时间窗口内的请求路由到主库

