@yexiaoqi
2023-06-07T06:57:29.000000Z
字数 6678
阅读 655
近期整理
面试
数据结构
MongoDB为啥用B树而不是B+树
- B-树所有节点都存储数据,因此在查询单条数据的时候,B树的查询效率不固定,最好的情况是O(1)。我们可以认为在做单一数据查询的时候,B树的平均性能更好,但不适合做一些数据遍历操作。
- B+树的数据只出现在叶子节点上,因此查询单条数据的时候,查询速度非常稳定,但是在单一数据查询上平均性能不如B树。因为叶子节点有指针相连,适合做范围查询
- MonogoDB是nosql,对遍历的需求没有关系型数据库强烈
网络
TCP 四次挥手过程,为什么是四次?
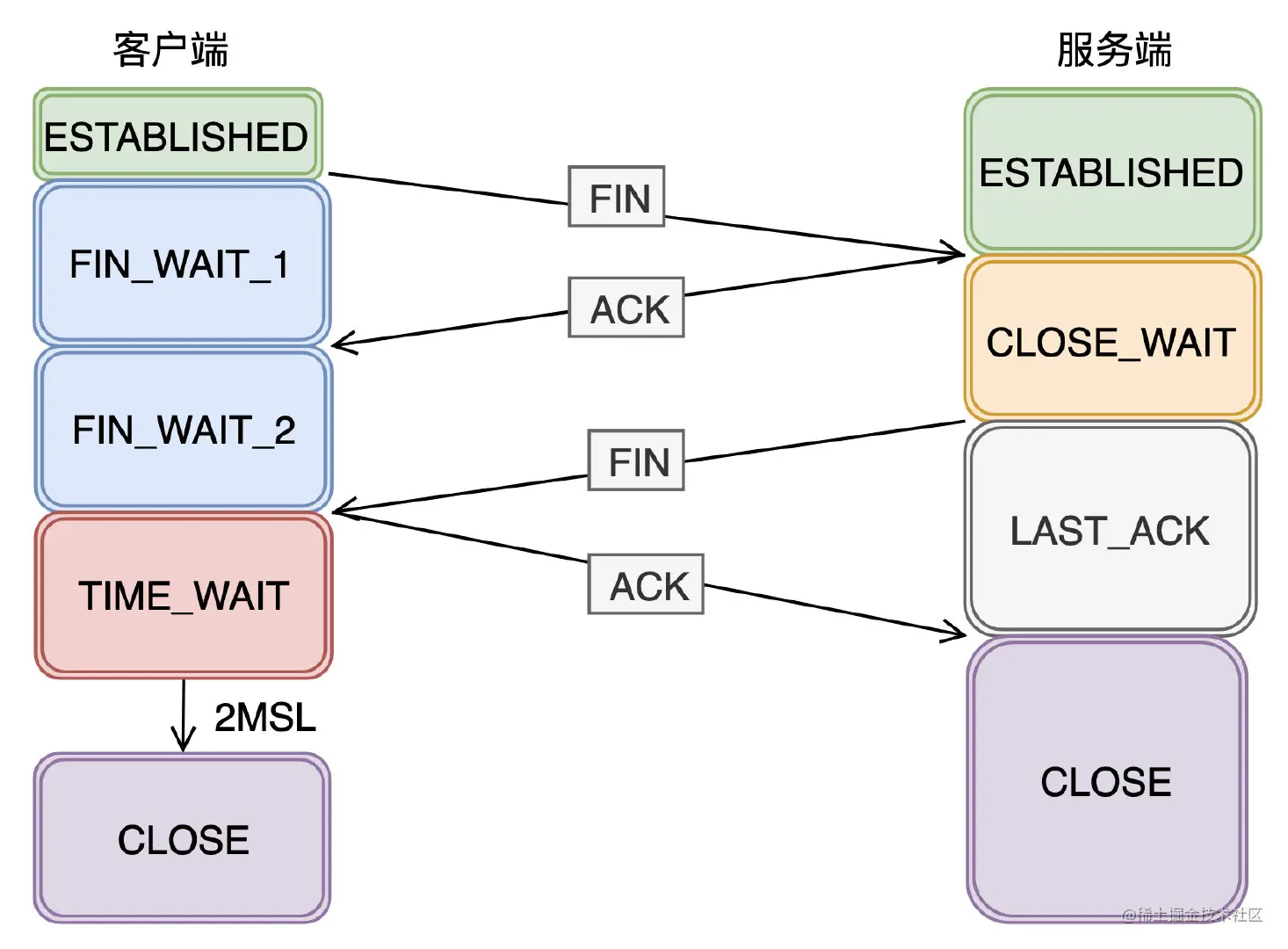
客户端第一次发送 FIN 报文之后,只是代表客户端不再发送数据给服务端,但此时客户端还是有接收数据的能力。服务端收到 FIN 报文的时候,可能还有数据要传输给客户端,所以只能先回复 ACK 给客户端。等到服务端不在有数据发送给客户端时,才发送 FIN 报文给客户端,表示可以关闭了。
四次挥手中有TIME_WAIT和CLOSE_WAIT状态,是出现在哪一方的?
TIME_WAIT:主动断开连接方
CLOSE_WAIT:被动断开连接方
假设 TIME_WAIT 状态过多会有什么危害,怎么解决?
危害:占用内存资源和端口,可以通过修改 Linux 内核参数解决。
TCP建立连接就是交换双方的状态
为什么TCP4次挥手时等待为2MSL?
第一个MSL是为了等自己发出去的最后一个ACK从网络中消失,而第二MSL是为了等在对端收到ACK之前的一刹那可能重传的FIN报文从网络中消失。等待2MSL时间,A就可以放心地释放TCP占用的资源、端口号,此时可以使用该端口号连接任何服务器。
如果不等,释放的端口可能会重连刚断开的服务器端口,这样依然存活在网络里的老的TCP报文可能与新TCP连接报文冲突,造成数据冲突,为避免此种情况,需要耐心等待网络老的TCP连接的活跃报文全部死翘翘,2MSL时间可以满足这个需求
nginx是四层负载还是七层负载?
- 二层负载均衡(数据链路层mac):虚拟mac地址,外部对虚拟mac地址请求,负载均衡后分配给对应的mac地址响应
- 三层负载均衡(网络层ip):虚拟IP地址的方式,外部对虚拟的IP地址请求,负载均衡后分配给实际的mac地址响应
- 四层负载均衡(传输层tcp):在三层负载均衡的基础上,用ip+port接收请求,再转发到对应的机器
- 七层负载均衡(应用层http):根据虚拟的ip+port、主机名接受请求,在转给响应的处理服务器
四层负载均衡(基于IP+端口的负载均衡)
在三层负载均衡基础上,通过发布的VIP,然后加上四层的端口号,来决定哪些流量需要做负载均衡,对需要的流量进行NAT处理,转发给后台服务器,并记录下这个TCP/UDP的流量是由哪台服务器处理的,后续这个连接的所有流量转发到同一台服务器。
四层负载均衡的实现有:
- F5:硬件负载均衡器,性能强大,成本高
- LVS:重量级四层负载均衡软件
- Haproxy:模拟四层、七层转发,较灵活
七层负载均衡(基于虚拟的URL或主机IP的负载均衡)
主要通过报文中真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择策略,决定最终的内部服务器。在四层负载均衡基础上,再考虑应用层特征,比如同一个Web服务器的负载均衡可以根据 IP+端口、url、浏览器类别、语言来决定是否要进行负载均衡。
先代理最终服务器与客户端三次握手后,才可能接触到真正的应用层报文。这种情况下类似于一个代理服务器,负载均衡和前端客户端、后端服务器会分别建立TCP连接。因此七层负载均衡明显对设备要求更高,更灵活,吞吐量低于四层。
七层负载均衡实现:
- Haproxy:全面支持四层、七层会话代理,会话保持,标记,路径转移
- nginx:只在http和mail协议上功能比较好,性能与haproxy相当
为什么常用的端口最大65535?
系统通过一个四元组{local ip, local port, remote ip, remote port}来唯一标识一条TCP连接。对于IPv4,系统理论上最多管理2^(32+16+32+16) -> 2^96个连接,如果考虑协议号,则是五元组。
TCP协议中 port 大小为 16bit,所以不能超过 2^16-1=65565
IO
IO模型
- 阻塞式I/O:应用进程被阻塞,直到数据复制到应用进程中缓冲区中才返回
- 非阻塞式I/O:应用进程执行系统调用后,内核返回一个错误码。应用进程可以继续执行,但需要不断轮询来获知 I/O 是否完成
- I/O 多路复用:一个线程可以监视多个文件描述符,此过程会被阻塞。一旦某个就绪,通知应用程序读写
- 信号驱动式 I/O:向内核发送一个信号
SIGIO,然后应用程序立即返回。当内核数据准备号后,再通过SIGIO信号通知应用进程。应用进程收到信号后使用recvfrom去读取数据(数据复制到应用缓冲区期间,进程阻塞) - 异步 I/O:应用进程发出系统调用后立即返回,等内核准备好数据,将数据拷贝到应用进程缓冲区,发送信号通知应用进程IO操作完毕
数据库
MySQL锁
在 InnoDB 引擎下,按照锁的粒度,可以简单分为行锁和表锁。
行锁是作用在索引上的,SQL命中了索引,锁住的就是命中条件内的索引节点(行锁)。如果没有命中索引,那锁住的就是整个索引树(表锁)。
行锁可以简单分为读锁和写锁。读锁是共享的,多个事务可以读取同一个资源,但不允许其他事务修改。写锁是排他的,写锁会阻塞其他的写锁和读锁。
事务的四大特性
- 原子性:由 undo log 保证(回滚日志,用于记录数据被修改前的信息)
- 持久性:由 redo log 保证(重做日志,记录的是事务执行过程中数据页的修改情况)
- 隔离性:由数据库隔离级别提供
- 一致性:是事务的目的,由应用程序保证
MySQL隔离级别
- 读未提交:读不加锁,会有脏读、重复度、幻读的问题
- 读已提交:MVCC(多版本并发控制)提高读写性能,避免脏读。MVCC通过生成数据快照,思想是每一次查询都会产生一个新的Read View副本,等到其他事务提交后,才会读取最新的已提交的版本号数据。通过“版本”概念解决脏读问题,会有重复读和幻读的问题
- 可重复度:是事务级别的快照,每次读取的都是当前事务的版本。会有幻读的问题
- 串行化:事务之间是串行的,效率最低,安全性最高
MVCC原理
- 获取事务自己的版本号,即事务ID
- 获取 Read View
- 查询到的数据,然后 Read View 中的事务版本号进行比较
- 如果不符合 Read View 的可见性规则,就需要 undo log 中历史快照
- 最后返回符合规则的数据
Java基础
面向对象三大特性
继承、封装、多态
Object类常用方法,equals & hashcode,在hashmap里哪里用到了
hashcode方法是为了加快比较效率,如果hashcode相同再用equals比较。同一个对象hashCode必须相同,hashCode相同不一定是同一个对象。
如果重写equals的时候没有重写hashCode,会违反Object.hashCode的通用约定,导致该类无法结合所有基于散列的集合一起工作,包括HashMap、HashSet、HashTable等。
wait、notify等方法为什么定义在Object中而不是Thread类中?
- wait、notify是线程间的通信机制,如果不能通过Java关键字实现此通信机制,又要确保每个对象可用,则Object类是合理的位置。
- 线程为了访问临界资源,需要获得锁并等待锁可用,他们并不需要知道哪个线程持有锁,只需要知道临界资源是否被占用,是否可以获得锁。
synchronized 锁升级过程
synchronized 有三种使用方式:
- 修饰静态方法:锁住当前 class,作用于该 class 的所有实例
- 修饰非静态方法:只锁当前 class 的实例
- 修饰代码块:锁住该参数对象
Java 对象结构分为 对象头、对象体、对齐字节。对象头包含三部分:
- Mark Word:存储自身运行数据(当前对象线程锁状态及 GC 标志)
- class 指针:指向方法区中该 class 的对象,JVM 通过此字段判断当前对象事哪个类的实例
- 数组长度:只有是数组时才会用到
锁升级过程按照无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁方向升级,无法进行锁降级。
- 线程A在进入同步代码块前,先检查 MarkWord 中的线程 ID 是否与当前线程 ID 一致,如果一致,则直接无需通过 CAS 来加锁、解锁
- 如果不一致,再检查是否为偏向锁,如果不是,自适应自旋等待锁释放
- 如果是,在检查对应线程是否存在,如果不在,则设置线程 ID 为线程 A 的 ID,还是偏向锁
- 如果在,撤销偏向锁,升级为轻量级锁。线程 A 自旋等待锁释放
- 如果自旋到了阈值,锁还没释放,又有一个线程来竞争锁,此时升级为重量级锁。其他竞争线程都被阻塞,防止CPU空转
- 锁被释放,唤醒所有阻塞线程,重新竞争锁
线程池中线程抛异常了,如何处理?
public class ThreadPoolException {public static void main(String[] args) {//创建一个线程池ExecutorService executorService=Executors.newFixedThreadPool(1);//当线程池抛出异常后submit无提示,其他线程继续执行executorService.submit(new task());//当线程池抛出异常后execute抛出异常,其他线程继续执行新任务executorService.execute(new task());}}//任务类class task implements Runnable{@Overridepublic void run() {System.out.println("进入了task方法!!!");int i=1/0;}}
任务提交方式中,execute会打印异常信息,submit不打印异常,要想获取异常信息就必须使用get()
//当线程池抛出异常后submit无提示,其他线程继续执行Future<?> submit = executorService.submit(new task());submit.get();
方案一:使用try-catch
方案二:使用Thread.setDefaultUncaughtExceptionHandler方法捕获异常。
重写线程工厂方法,在线程工厂创建线程的时候,赋予UncaughtExceptionHandler处理器对象
方案三:重写afterExecute进行异常处理
public class ThreadPoolException3 {public static void main(String[] args) throws InterruptedException,ExecutionException {//1.创建一个自己定义的线程池ExecutorService executorService = new ThreadPoolExecutor(2,3,0,TimeUnit.MILLISECONDS,new LinkedBlockingQueue(10)) {//重写afterExecute方法@Overrideprotected void afterExecute(Runnable r, Throwable t) {//这个是excute提交的时候if (t != null) {System.out.println("获取到excute提交的异常信息,处理异常"+t.getMessage());}//如果r的实际类型是FutureTask那么是submit提交的,所以可以在里面get到异常if (r instanceof FutureTask) {try {Future<?> future = (Future<?>) r;//get获取异常future.get();} catch (Exception e) {System.out.println("获取到submit提交的异常信息,处理异常" + e);}}}};//当线程池抛出异常后executeexecutorService.execute(new task());//当线程池抛出异常后submitexecutorService.submit(new task());}}class task3 implements Runnable {@Overridepublic void run() {System.out.println("进入了task方法!!!");int i = 1 / 0;}}
JVM
jvm加载类的时候的阶段、static成员变量在各个阶段中发生了什么变化
源码到代码执行过程:编译 -> 加载 -> 解释 -> 执行
编译阶段:语法分析 -> 语义分析 -> 注解处理 -> class文件
加载阶段:装载 -> 连接 -> 初始化
装载阶段:查找并加载类的二进制数据,在 JVM 堆中创建一个 java.lang.Class类的对象,并将类相关的信息存储在 JVM 方法区中。
连接阶段:对 class 的信息进行验证、为类变量分配内存空间并对其赋默认值
1. 验证:验证类是否符合 java 规范和 JVM 规范
2. 准备:为类的静态变量分配内存,初始化为系统默认值
3. 解析:将符号引用转为直接引用
初始化:为类的静态变量赋予正确的初始值
解释阶段:把字节码转换为操作系统识别的指令
JVM 会检测热点代码,超过阈值会触发即时编译,生成机器码保存起来,下次直接执行
执行阶段:调用操作系统执行指令
框架
SpringBoot中如何定义一个starter
- 新建两个模块,命名规范:xxx-spring-boot-starter
- xxx-spring-boot-autoconfigure:自定配置核心代码
- xxx-spring-boot-starter:管理依赖
- 在 xxx-spring-boot-autoconfigure 项目中
- 引入 maven 依赖
- 创建自定义的 XXXProperties 类:类中的属性要出现在配置文件中
- 创建自定义类,实现自定义功能
- 创建自定义的 XXXAutoConfigure 类:用于自动配置时的一些逻辑,需将上方自定义类进行 Bean 对象创建,同时让 XXXProperties 类生效
- 创建自定义的
spring.factories文件:在resource/META-INF创建一个spring.factories文件和spring-configuration-metadata.json,分别用于导入自动配置类(必须有)、用于在填写配置文件时的智能提示(可以没有)。
- 在 xxx-spring-boot-starter 项目中引入 xxx-spring-boot-autoconfigure 依赖,其他项目使用时只需依赖 xxx-spring-boot-starter 即可
分布式
redis分布式锁
RedLock算法是 Redis 官方支持的分布式锁算法。
- 互斥(只能由一个客户端获取锁)
- 不能死锁
- 容错(只要大部分 Redis 节点创建了这把锁就可以)
最普通的实现方式,是使用SET key value [EX seconds|PX milliseconds] NX创建一个key,就算加锁成功
EX seconds:设置key的过期时间。seconds秒后锁自动释放,被人创建的时候发现已经有了就不能加锁了PX milliseconds:设置key的过期时间,精确到毫秒级NX:只有key不存在的时候才会设置成功,如果存在这个key,则会设置失败
释放锁一般可以用lua脚本删除:
-- 删除锁的时候,找到key对应的value,与传过去的value做比较,如果是一样的才删除if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])elsereturn 0end
考虑到 Redis 单实例会出现单点故障风险;或者普通主从异步复制,如果主节点挂了,key 还没有同步到从节点,此时从节点切换为主节点,别人就可以 set key,从而拿到锁。
RedLock 算法
假设有一个 Redis cluster,有5个 Redis master 实例。然后执行如下步骤获取一把锁:
1. 获取当前的时间戳,单位是毫秒
2. 轮流尝试在每个 master 节点创建锁,超时时间较短(客户端为了获取锁使用的超时时间比自动释放锁的总时间要小)
3. 尝试在大多数节点上建立一个锁,比如5个节点就要求3个节点
4. 客户端计算加锁的时间,如果建立锁的时间小于超时时间,就算建立成功了
5. 要是加锁失败,就依次之前建立过的锁删除
6. 只要别人建立了一把分布式锁,你就地不断轮询去尝试获取锁
