@xdx24
2017-03-09T00:24:10.000000Z
字数 3670
阅读 524
GAN overview
gan surf
Our project
Since our goal is Image Completion(similar to Image Synthesis or Image-to-Image Translation), generator is the key part of this project because we want sharp, realistic and natural image output. There is a paper introduced a common framework to generate image from both computer vision (many-to-one) and graphics (one-to-many) problem. And we would like to modify the framwork with different structures and models (listed below). And since they used conditional Adversarial Networks, we could handle the problem differently by applying unsupervised learning which is also an advantage of using GAN.

Figure 1 Intuitive explanation of GAN (photo taken from there)
Mechanism behind Generator
As an example, consider an image classifier D designed to identify a series of images depicting various animals. Now consider an adversary (G) with the mission to fool D using carefully crafted images that look almost right but not quite. This is done by picking a legitimate sample randomly from training set (latent space) and synthesizing a new image by randomly altering its features (by adding random noise). As an example, G can fetch the image of a cat and can add an extra eye to the image converting it to a false sample. The result is an image very similar to a normal cat with the exception of the number of eye.
During training, D is presented with a random mix of legitimate images from training data as well as fake images generated by G. Its task is to identify correct and fake inputs. Based on the outcome, both machines try to fine-tune their parameters and become better in what they do. If D makes the right prediction, G updates its parameters in order to generate better fake samples to fool D. If D's prediction is incorrect, it tries to learn from its mistake to avoid similar mistakes in the future. The reward for net D is the number of right predictions and the reward for G is the number D's errors. This process continues until an equilibrium is established and D's training is optimized.
Math
The main idea of a generator(G) is to learn a probability distribution (density )from latent space and generate the counterfeit data to discriminator, Normally, we will define a parametric family of densities and find the one that maximized the likelihood on our data, then asympototically minimizing Kullback-Leibler divergence (FYI something like ).
The objective of conditional GAN through maximum likelihoood approach
tries to minimize this objective against an adversarial that tries to maximize it, i.e.
Testing the result and compare with related work
For quantitative evaluation of generative models, FCN-8s architecture for semantic segmentation will be used. This classifier is used to measure the discriminability of the generated images as a pseudo-metric. The intuition behind is if the generated images are realistic, classifiers trained on real images will be able to classify the completed images correctly as well.
There are different methods to test accuracy of GANs, but intuition behind is similar. See reference.
Anticipated Outcome

Maybe we will fill the background as well.
Possible structures and models can be used in our project (need further explore)
It may seem a lot, but with tensorflow, scikit, numpy, etc. testing time can be tremendously reduced. However, maths behind the methods is another story.
- EBGAN
- DCGAN (deep convolutionary GANs) This is also really interesting to combine dNN and GAN
- ReLU
- U-net
* Markov Chains - WGAN
- GCGAN
- LSTM
- PixelGAN
- PatchGans
- ImageGANs
CNN architecture:
- all convolutional net
- eliminate fully connected layers on top of convolutional features
- batch normalization (stabilizaes learning)
* cGAN(conditional GAN)
* classification with rebalancing
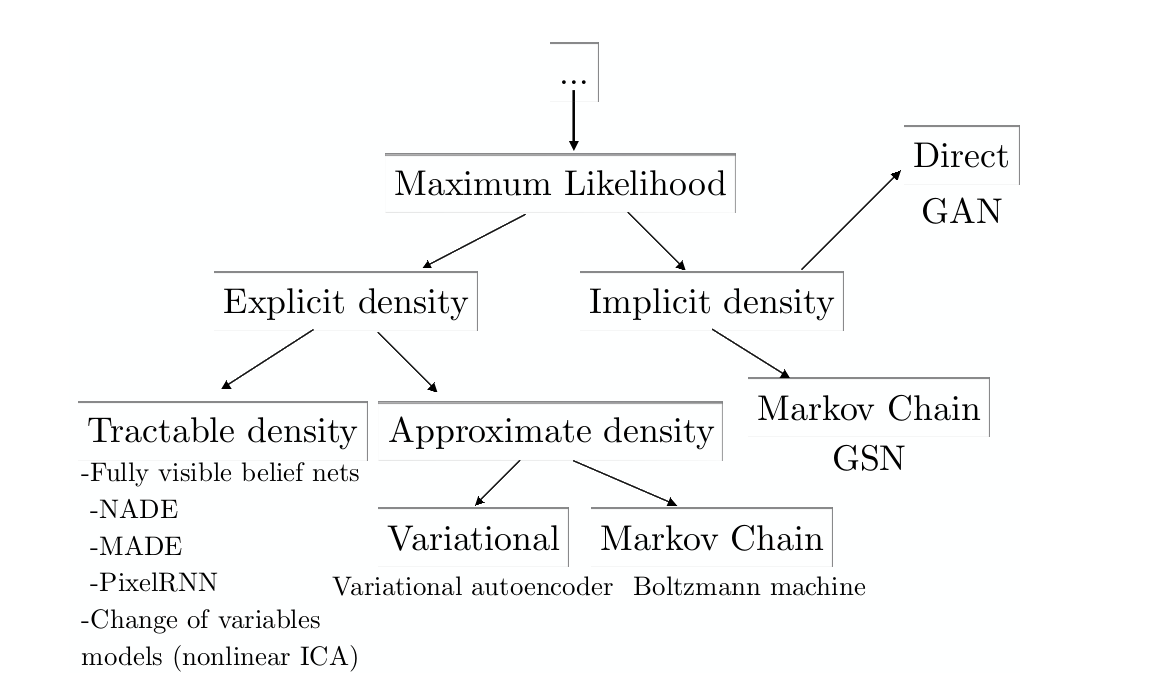
Figure 3 DCGAN model
Conclusion
As Linus Torvalds once said Talk is cheap. Show me the code, without combing practical experiment and theoretical basis, we are unable to know why algorithm works on a real machine and how should we improve it. Thus, I hope we can start to do the project now and see the result.
