@w568w
2020-08-04T07:24:43.000000Z
字数 2671
阅读 1955
笔记:基于LSTM(Long Short-Term Memory)的股票预测
网络结构
采用LSTM*3 + Full-connected为网络。
每次输入16天数据,输出接下来1天的收盘价格。
训练时使用Keras作为框架,数据均已归一化。
训练过程
以600001(浦发银行)近14年数据为训练集和验证集。
使用Geforce GTX 1650显卡、CUDA 10.1环境,在与上轮流训练,总用时约 20 分钟。
训练结果
经过若干轮训练,训练集上的Loss稳定在左右,测试集上的Loss稳定在左右,符合精度要求。
在随机抽取的两支股票中获取近14年数据,抽样验证,结果如下:
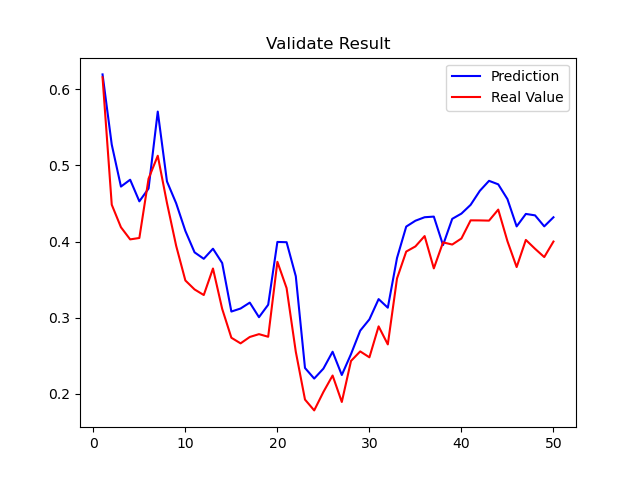
Figure 1:000998(隆平高科)
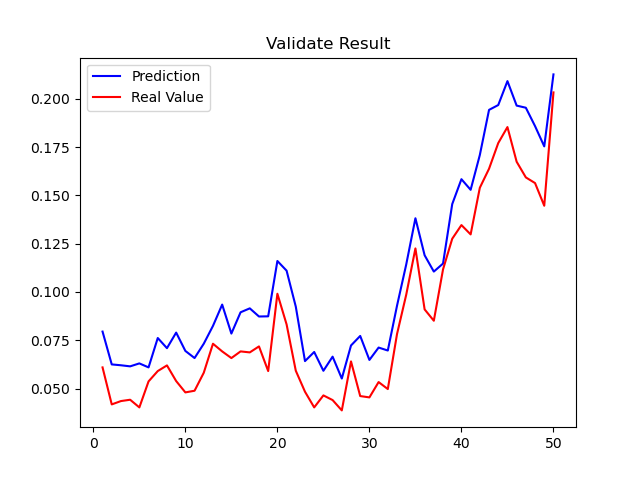
Figure 2: 600435(北方导航)
代码
import osfrom typing import List, Anyos.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'from numpy.core._multiarray_umath import ndarrayfrom tensorflow.keras.layers import Denseimport csvimport numpy as npimport matplotlib.pyplot as pltfrom tensorflow.python.keras import Sequentialfrom tensorflow.python.keras.layers import LSTM, Dropoutdef train(m: Sequential):for i in range(0, 5):m.fit(Train_X, Train_Y, batch_size=BATCH_SIZE, epochs=EPOCHES,validation_split=1 / 3)m.fit(Train_X, Train_Y, batch_size=BATCH_SIZE, epochs=EPOCHES)m.save_weights("lstm.mw")def validate(m: Sequential, num=50):plt.title("Validate Result")plt.plot(range(1, num + 1), m.predict(Train_X[0:num]).flatten(order='C'), 'blue',label='Prediction')plt.plot(range(1, num + 1), Train_Y[0:num].flatten(order='C'), 'red', label='Real Value')plt.legend()plt.show()def normalization(arr: ndarray):return (arr - arr.min()) / (arr.max() - arr.min())BATCH_SIZE = 5TIME_STEP = 16DATA_FRAME_NUM = 4OUTPUT_NUM = 1EPOCHES = 5Train_X: ndarray = np.empty([1, 3, 2], dtype=float)Train_Y = np.empty([], dtype=float)with open('history_A_stock_k_test_data.csv', 'r') as f:data_list: List[Any] = list(csv.reader(f))Train_X = np.empty([0, TIME_STEP, DATA_FRAME_NUM], dtype=float)Train_Y = np.empty([0, OUTPUT_NUM], dtype=float)time_step_array: ndarray = np.empty([1, TIME_STEP, DATA_FRAME_NUM], dtype=float)for i in range(1, len(data_list)):time_step_array[0][i % TIME_STEP - 1] = data_list[i][1:5]if i < TIME_STEP:continueif i % TIME_STEP == 0:Train_X = np.append(Train_X, time_step_array, axis=0)elif i % TIME_STEP == 1:Train_Y = np.append(Train_Y,np.expand_dims(np.asarray(data_list[i][4:5], dtype=float), axis=0),axis=0)Train_X = normalization(Train_X)Train_Y = normalization(Train_Y)model: Sequential = Sequential()model.add(LSTM(128, return_sequences=True,input_shape=(TIME_STEP, DATA_FRAME_NUM)))model.add(LSTM(128, return_sequences=True))model.add(LSTM(128))model.add(Dropout(0.2))model.add(Dense(OUTPUT_NUM, activation="linear"))model.compile(loss='mse', optimizer='rmsprop')model.load_weights("lstm.mw")# 训练他妈的股票预测模型train(model)
反思
经过又一次将近 30 分钟的训练,达到了如下精度:
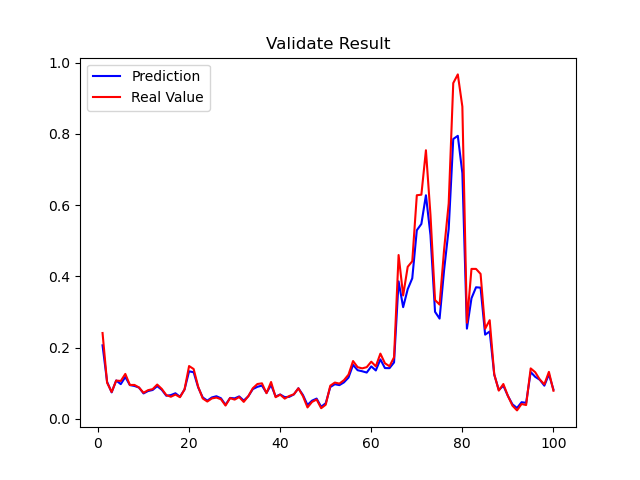
Figure 3: 300059(东方财富)
事实证明,在一定误差范围、一定时期内,股票的走向或许是可预测的。
当然这个模型非常烂,没有考虑外界因素(政策变化、市场走向等等),并且只是简单运用了LSTM的预测能力。
PS:就我所知,股票预测是很多大学人工智能课程的入门教学示范...
这样的模型有很多人做过,我不是第一个,也肯定不是最后一个。
尽管我不懂炒股,但就我浅薄的经济学知识来看,股票真正难搞的不是走向,而是常常出现的、猝不及防的黑天鹅事件。而这一点,在相当程度内,都是机器学习无法预知的。
真指望用这个炒股还是算了...
0202年了,不会还有人炒股吧 不会吧不会吧
